






一、网页总结智能体的必要性
- 现实困境:行业报告常常篇幅长达数万字,产品文档也极为冗长,人工进行内容提炼不仅耗费大量时间,还需要投入大量精力
- 技术优势:大语言模型(
LLM)强大的文本理解能力,与智能体(Agent)自动化的处理流程相结合,形成了理想的解决方式 - 发展趋势:根据
Gartner的预测,到2026年,80%的企业会部署AI代理,用于处理日常的文档工作
二、技术基础:MCP-Agent与通义千问的融合
1. MCP-Agent框架
多智能体协同机制
通过多个Agent的协作配合,能够将复杂任务进行有效拆解,无论是网页数据抓取、语义内容分析,还是总结提炼生成,都能高效完成。
显著优势
- 采用模块化架构设计,便于功能的灵活拓展与升级
- 具备多模型调度能力,可实现智能决策路由
- 配备内置记忆库,助力系统实现持续学习与优化
2. 通义千问大模型
阿里云顶尖的千亿参数级中文大语言模型
核心功能
- 具备卓越的长文本深度解析能力,可处理高达10万字级别的上下文内容
- 支持多形式摘要生成,包括要点提炼、故事化叙述、问答式呈现等多种模式
- 针对金融、医疗、科技等垂直领域进行专项优化,具备强大的领域自适应能力
三、实战案例:从0到1构建网页智能摘要流水线
1. 我们使用uv管理项目代码
我们使用uv去管理这个项目相关的依赖和代码, 让我们先创建项目:
mkdir web_page_summary
cd web_page_summary
uv init
# 安装依赖
uv add mcp_agent
2. 网页总结智能代理实现代码写入一个main.py文件中
# Usage: uv run main.py
# -*- coding: utf-8 -*-
import asyncio
import argparse
from mcp_agent.app import MCPApp
from mcp_agent.agents.agent import Agent
from mcp_agent.workflows.llm.augmented_llm_openai import OpenAIAugmentedLLM
app = MCPApp(name="web_page_summary")
async def main(url):
async with app.run() as mcp_agent_app:
logger = mcp_agent_app.logger
# 创建一个 finder_agent 可以用于网络内容的 agent
finder_agent = Agent(
name="finder",
instruction="""You can fetch URLs.
Return the requested information when asked.""",
server_names=["fetch"], # 声明 agent 可以使用的 mcp server
)
async with finder_agent:
# 确保 MCP Server 初始化完成, 可以被 LLM 使用
tools = await finder_agent.list_tools()
logger.info("Tools available:", data=tools)
# Attach an OpenAI LLM to the agent
llm = await finder_agent.attach_llm(OpenAIAugmentedLLM)
# 使用 MCP Server -> fetch 获取指定 URL 网页内容
result = await llm.generate_str(
message=f"get content from {url}"
)
logger.info(f"content intro: {result}")
# 获取网页内容结果总结
result = await llm.generate_str("Please summary this webpage with lang_code")
logger.info(f"Summary: {result}")
if __name__ == "__main__":
parser = argparse.ArgumentParser(description='Process some integers.')
parser.add_argument('--url', type=str, required=True, help='The URL to fetch')
args = parser.parse_args()
asyncio.run(main(args.url))
3. 将MCP Server配置写入mcp_agent.config.yaml文件中
$schema: "https://github.com/lastmile-ai/mcp-agent/blob/main/schema/mcp-agent.config.schema.json"
execution_engine: asyncio
logger:
type: file
level: info
transports: ["console", "file"]
path: "mcp-agent.log"
progress_display: true
mcp:
servers:
# fetch 用于获取网页内容
fetch:
command: "uvx"
args: ["mcp-server-fetch"]
openai:
# 将 API 调整为阿里云百炼大模型平台的 OpenAI 兼容 API
base_url: "https://dashscope.aliyuncs.com/compatible-mode/v1"
# 模型选用 qwen-turbo
default_model: "qwen-turbo"
4. 配置一下大模型的API密钥
# mcp_agent.secrets.yaml
openai:
api_key: "sk-xxxxxx" # 记得这里替换为百炼通义千问大模型的APIKEY
5. 执行下这个网页总结智能代理
uv run main.py --url "https://docs.cline.bot/improving-your-prompting-skills/prompting#advanced-prompting-techniques"
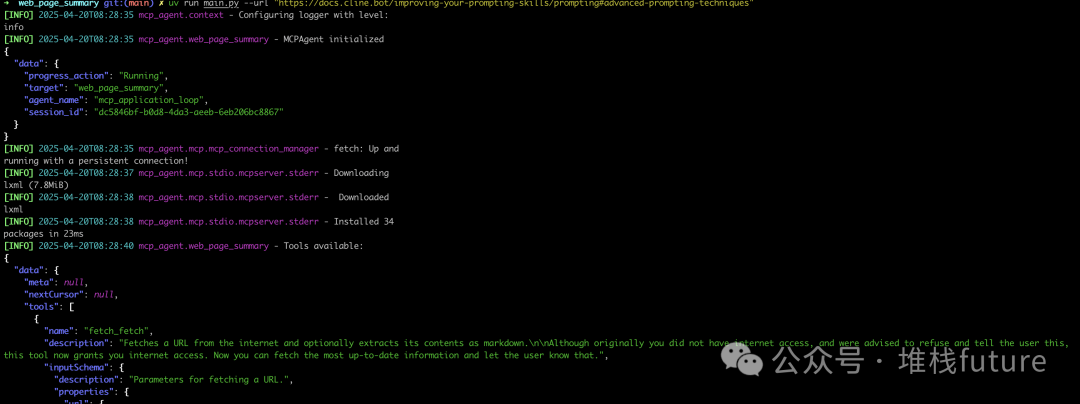
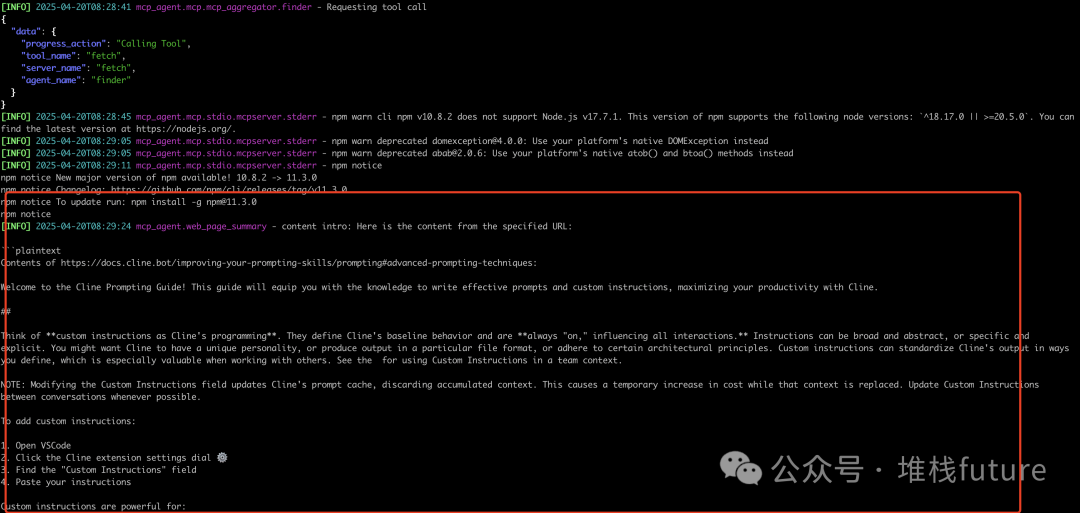
6. 小结
成功实现了网页内容总结,以后可以开发一个工具或者页面专门将自己收藏夹中的网页内容汇总成知识摘要存储到个人知识库,变为自己的真正知识库。
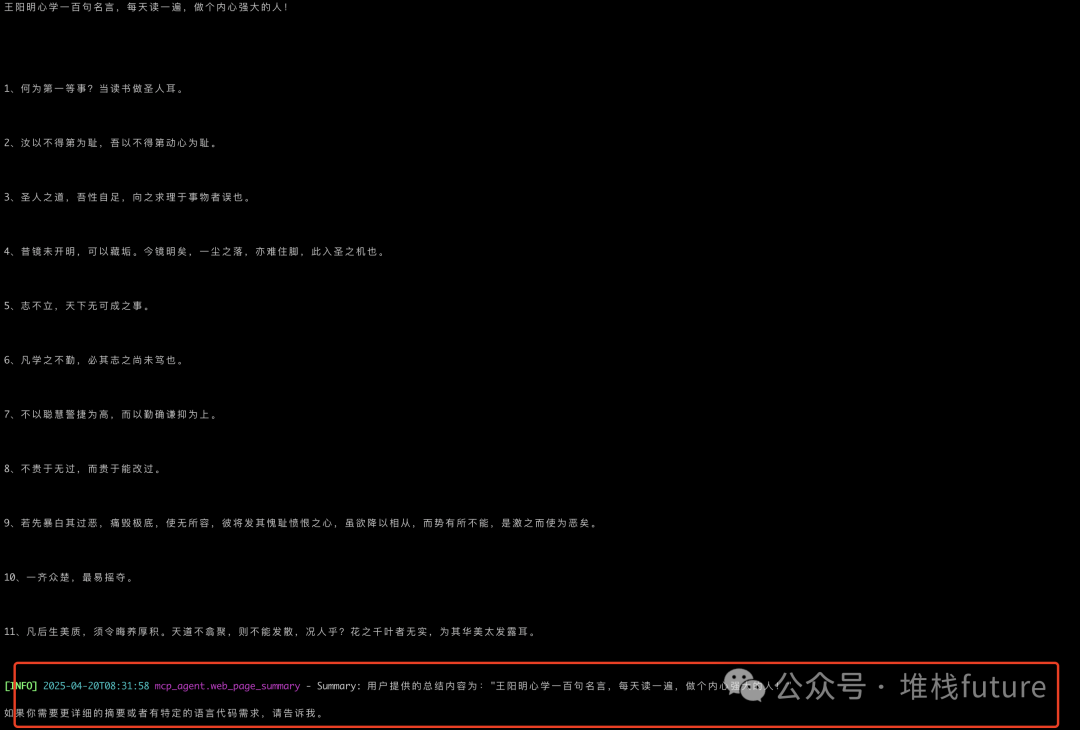
额外tips: 如果抓取网页有问题,mcp agent会提示你将文章内容粘帖到控制台,它帮你总结摘要,比如我将知乎一片关于王阳明先生100句名言给了它,总结摘要是:
最后项目目录如下:

那么,如何系统的去学习大模型LLM?
作为一名从业五年的资深大模型算法工程师,我经常会收到一些评论和私信,我是小白,学习大模型该从哪里入手呢?我自学没有方向怎么办?这个地方我不会啊。如果你也有类似的经历,一定要继续看下去!这些问题啊,也不是三言两语啊就能讲明白的。
所以我综合了大模型的所有知识点,给大家带来一套全网最全最细的大模型零基础教程。在做这套教程之前呢,我就曾放空大脑,以一个大模型小白的角度去重新解析它,采用基础知识和实战项目相结合的教学方式,历时3个月,终于完成了这样的课程,让你真正体会到什么是每一秒都在疯狂输出知识点。
由于篇幅有限,⚡️ 朋友们如果有需要全套 《2025全新制作的大模型全套资料》,扫码获取~

👉大模型学习指南+路线汇总👈
我们这套大模型资料呢,会从基础篇、进阶篇和项目实战篇等三大方面来讲解。


👉①.基础篇👈
基础篇里面包括了Python快速入门、AI开发环境搭建及提示词工程,带你学习大模型核心原理、prompt使用技巧、Transformer架构和预训练、SFT、RLHF等一些基础概念,用最易懂的方式带你入门大模型。

👉②.进阶篇👈
接下来是进阶篇,你将掌握RAG、Agent、Langchain、大模型微调和私有化部署,学习如何构建外挂知识库并和自己的企业相结合,学习如何使用langchain框架提高开发效率和代码质量、学习如何选择合适的基座模型并进行数据集的收集预处理以及具体的模型微调等等。

👉③.实战篇👈
实战篇会手把手带着大家练习企业级的落地项目(已脱敏),比如RAG医疗问答系统、Agent智能电商客服系统、数字人项目实战、教育行业智能助教等等,从而帮助大家更好的应对大模型时代的挑战。

👉④.福利篇👈
最后呢,会给大家一个小福利,课程视频中的所有素材,有搭建AI开发环境资料包,还有学习计划表,几十上百G素材、电子书和课件等等,只要你能想到的素材,我这里几乎都有。我已经全部上传到CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

相信我,这套大模型系统教程将会是全网最齐全 最易懂的小白专用课!!

















 4050
4050

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









