





摘要
现有LiDAR-摄像机3D物体检测方法有四个重要组成部分(LiDAR和摄像机候选对象、变换和融合输出),所有现有方法要么找到密集的候选对象,要么产生密集的场景表示。然而,考虑到物体只占据场景的一小部分,找到密集的候选对象和生成密集的表示会产生噪声和效率低下的问题。因此,我们提出了SparseFusion,一种新颖的多传感器3D检测方法,专门使用稀疏的候选对象和稀疏的表示。具体而言,SparseFusion利用LiDAR和摄像机模态的并行检测器的输出作为稀疏的融合候选对象。我们通过解耦物体表示将摄像机候选对象转换到LiDAR坐标空间中。然后,我们可以通过轻量级的自注意力模块将多模态候选对象在统一的3D空间中进行融合。为了减轻模态之间的负面转移,我们提出了新颖的语义和几何跨模态转移模块,在模态特定的检测器之前应用。
背景
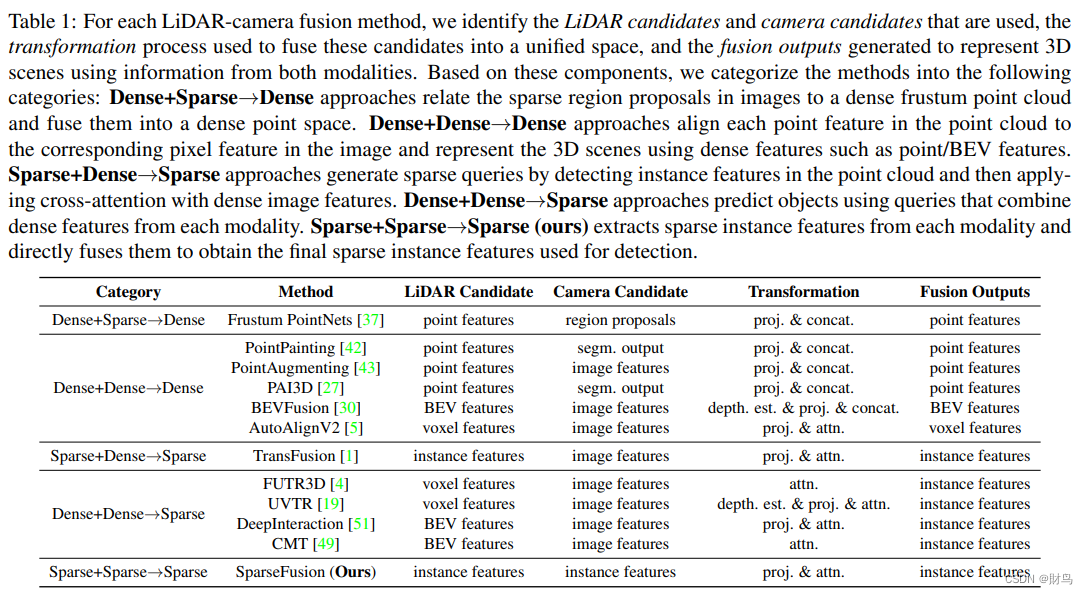
根据给出的描述,我们可以将LiDAR和相机融合方法分为以下几个类别:
Dense+Sparse→Dense:这种方法将图像中的稀疏区域提取为稀疏的区域建议,并将它们与密集的视锥点云融合到一个密集的点空间中。融合的输出可以是密集的点特征表示或者BEV(鸟瞰图)特征表示。
Dense+Dense→Dense:这种方法对齐点云中的每个点特征到图像中对应的像素特征,并使用密集的特征表示(如点特征或BEV特征)来表示3D场景。
Sparse+Dense→Sparse:这种方法在点云中检测实例特征并生成稀疏查询,然后将稀疏查询与密集的图像特征进行跨模态注意力融合,得到稀疏的实例特征用于物体检测。
Dense+Dense→Sparse:这种方法使用从每个模态中组合的密集特征来预测物体。
Sparse+Sparse→Sparse:这种方法从每个模态中提取稀疏实例特征,并直接融合它们以获取最终用于检测的稀疏实例特征。
主要工作
- 实例级稀疏特征融合
- 跨模态信息传递
Methods
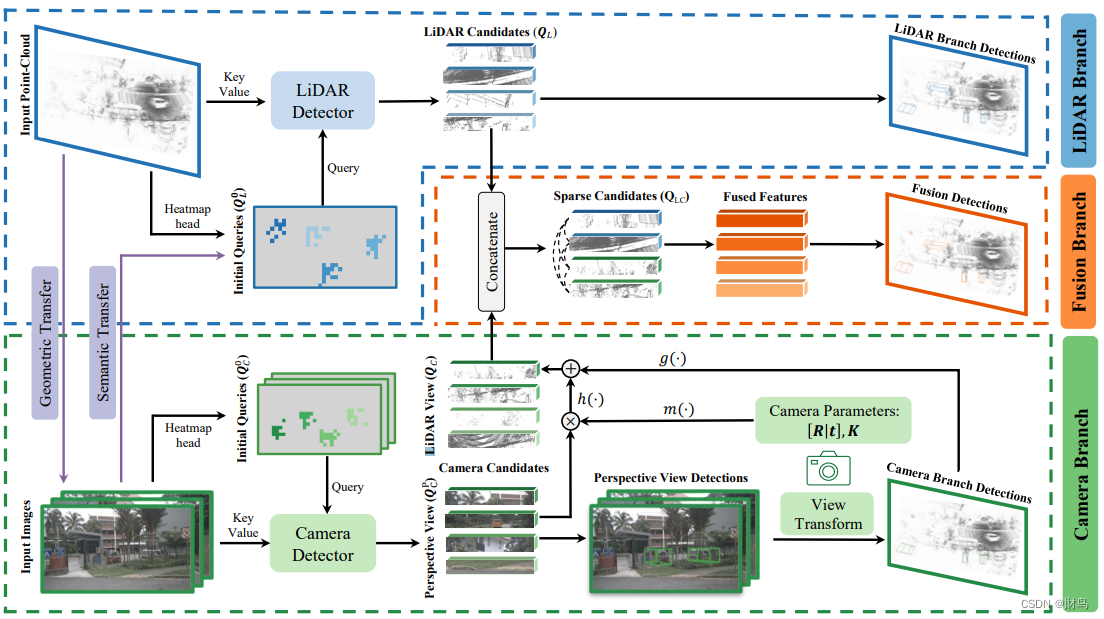
Sparse Representation Fusion-稀疏表示融合
- 获取两种模态的候选
- lidar candidates
- 先将lidar 点云转换到BEV视角,然后初始化 N L N_L NL个query Q l 0 = { q L , i 0 } i = 1 N L Q_l^0=\{q_{L,i}^0\}_{i=1}^{N_L} Ql0={qL,i0}i=1NL,并获得他们的参考点 P l 0 = { p L , i 0 } i = 1 N L P_l^0=\{p_{L,i}^0\}_{i=1}^{N_L} Pl0={pL,i0}i=1NL,( p L , i 0 p_{L,i}^0 pL,i0in the BEV plane.)这些query通过交叉注意力机制与BEV特征进行交互,不断更新query融合信息得到 Q l = { q L , i } i = 1 N L Q_l=\{q_{L,i}\}_{i=1}^{N_L} Ql={qL,i}i=1NL
- 这些更新后的查询 Q l Q_l Ql表示 LiDAR 模态中物体的实例级特征,我们将它们作为后续多模态融合模块中的 LiDAR 候选物体。此外,我们对每个查询应用一个预测头,用于在 LiDAR 坐标空间中对物体进行分类和边界框回归。
- camera candidates
- 利用仅基于摄像头的3D检测器,使用不同视角的图像作为输入。具体而言,使用带有3D边界框回归头的deformable DETR进行扩展。我们还初始化 N C N_C NC个对象查询 Q C 0 = { q C , i 0 } i = 1 N C Q_C^0=\{q_{C,i}^0\}_{i=1}^{N_C} QC0={qC,i0}i=1NC和它们对应的参考点位置 P C 0 = { p C , i 0 } i = 1 N C P_C^0=\{p_{C,i}^0\}_{i=1}^{N_C} PC0={pC,i0}i=1NC,( p C , i 0 p_{C,i}^0 pC,i0in the image plane.)
- 对于每个视角 v,其图像上的查询通过使用一个可变形注意力层与相应的图像特征交互。所有视角的输出组成了更新后的查询 Q C P = { q C , i P } i = 1 N C Q_C^P=\{q_{C,i}^P\}_{i=1}^{N_C} QCP={qC,iP}i=1NC。我们将这些查询作为后续多模态融合模块中的摄像头候选物体。
- lidar candidates
- 视角转换
- 在获得来自每个模态的候选物体之后,我们的目标是将摄像头模态的candidates转换到LiDAR模态的candidates空间中。由于摄像头模态的候选物体是高维潜在特征,并且其分布与LiDAR模态的候选物体不同,因此简单的模态间坐标转换在这里不适用。为了解决这个问题,我们对摄像头候选物体的表示进行了解耦。从本质上讲,摄像头候选物体是实例特征,它是一个特定对象类别和3D边界框的表示。虽然对象的类别是视角无关的,但其3D边界框是视角相关的。这促使我们专注于转换高维的边界框表示。
- 首先将候选实例特征输入到摄像头分支的预测头中,将输出的边界框标记为 b P b^P bP。给定相应第 v 个摄像头的外参[Rv|tv] 和内参 Kv,边界框可以轻松投影到 LiDAR 坐标系中。将投影后的边界框表示为 b L b^L bL。
- 使用一个多层感知机(MLP)g(·)对投影后的边界框进行编码,得到一个高维的边界框嵌入。还使用另一个 MLP m(·) 对扁平化的摄像头参数进行编码,以获得摄像头嵌入。摄像头嵌入与原始实例特征进行乘积运算,然后将结果添加到边界框嵌入。
-
q
C
,
i
L
=
g
(
b
i
L
)
+
h
(
q
C
,
i
P
⋅
m
(
R
v
,
t
v
,
K
v
)
)
,
\mathbf{q}_{C, i}^L=g\left(\mathbf{b}_i^L\right)+h\left(\mathbf{q}_{C, i}^P \cdot m\left(\mathbf{R}_v, \mathbf{t}_v, \mathbf{K}_v\right)\right),
qC,iL=g(biL)+h(qC,iP⋅m(Rv,tv,Kv)),
h ( ⋅ ) h(\cdot) h(⋅) is an extra MLP to encode the query features in the perspective view.
h ( ⋅ ) h(\cdot) h(⋅) aims to preserve viewagnostic information while discarding view-specific information.
Q C L = { q C , i L } \mathbf{Q}_C^L=\left\{\mathbf{q}_{C, i}^L\right\} QCL={qC,iL} 通过一个自注意力层聚合多个相机视角的信息对 查询 Q C \mathbf{Q}_C QC 进行更新,得到lidar坐标系下的相机模态实例特征。
- Sparse candidate fusion.
- 我们的并行模态特定物体检测提供了稀疏实例候选物体
Q
L
=
\mathbf{Q}_L=
QL=
{
q
L
,
i
}
i
=
1
N
L
\left\{\mathbf{q}_{L, i}\right\}_{i=1}^{N_L}
{qL,i}i=1NL and
Q
C
=
{
q
C
,
i
}
i
=
1
N
C
\mathbf{Q}_C=\left\{\mathbf{q}_{C, i}\right\}_{i=1}^{N_C}
QC={qC,i}i=1NC from the LiDAR and camera modalities respectively。两个模态的候选物体表示在相同的 LiDAR 坐标空间中的边界框,同时也表示视角无关的类别。现在,我们将候选物体进行拼接:
Q L C = { q L C , i } i = 1 N L + N C = { f L ( q L , i ) } i = 1 N L ∪ { f C ( q C , i ) } i = 1 N C \mathbf{Q}_{L C}=\left\{\mathbf{q}_{L C, i}\right\}_{i=1}^{N_L+N_C}=\left\{f_L\left(\mathbf{q}_{L, i}\right)\right\}_{i=1}^{N_L} \cup\left\{f_C\left(\mathbf{q}_{C, i}\right)\right\}_{i=1}^{N_C} QLC={qLC,i}i=1NL+NC={fL(qL,i)}i=1NL∪{fC(qC,i)}i=1NC - 其中,fL(·)和fC(·)是可学习的投影器。随后,我们利用自注意力模块来融合两个模态。尽管自注意力模块很简单,但其中隐含的直觉是新颖的:模态特定的检测器编码了各自输入的优势方面,而自注意力模块能够以高效的方式聚合和保留来自两个模态的信息。自注意力模块的输出用于最终的边界框分类和回归任务。
- 我们的并行模态特定物体检测提供了稀疏实例候选物体
Q
L
=
\mathbf{Q}_L=
QL=
{
q
L
,
i
}
i
=
1
N
L
\left\{\mathbf{q}_{L, i}\right\}_{i=1}^{N_L}
{qL,i}i=1NL and
Q
C
=
{
q
C
,
i
}
i
=
1
N
C
\mathbf{Q}_C=\left\{\mathbf{q}_{C, i}\right\}_{i=1}^{N_C}
QC={qC,i}i=1NC from the LiDAR and camera modalities respectively。两个模态的候选物体表示在相同的 LiDAR 坐标空间中的边界框,同时也表示视角无关的类别。现在,我们将候选物体进行拼接:
Cross-Modality Information Transfer-跨模态信息传输
- Geometric transfer from LiDAR to camera-雷达到相机的几何传输
- 将LiDAR点云输入中的每个点投影到多视角图像中,以生成稀疏的多视角深度图。这些多视角深度图被输入到一个共享的编码器中,以获得深度特征,然后将其与图像特征拼接在一起,形成深度感知的图像特征,弥补摄像头输入中缺少的几何信息。深度感知的图像特征被用作摄像头分支的输入。
- Semantic transfer from camera to LiDAR-相机到雷达的语义传输
- 将LiDAR点云输入中的点投影到图像输入上,得到稀疏的图像特征点。我们通过最大池化来聚合产生的多尺度特征,并将它们与BEV特征相加进行组合。拼接后的特征作为查询与多尺度图像特征通过可变形注意力进行交互。更新后的查询替换了BEV特征中的原始查询,从而得到语义感知的BEV特征,用于查询初始化。
Objective Function-目标函数
- 对于两种模态查询都利用Gaussian focal loss(高斯焦点损失函数)进行初始化。
L i n i t = L G F o c a l ( Y ^ l , Y L ) + L G F o c a l ( Y ^ C , Y C ) L_{init}=L_{GFocal}(\hat{Y}_l,Y_L)+L_{GFocal}(\hat{Y}_C,Y_C) Linit=LGFocal(Y^l,YL)+LGFocal(Y^C,YC)
Y ^ l \hat{Y}_l Y^l Y ^ C \hat{Y}_C Y^C分别是 LiDAR 和摄像头模态的密集类别热图预测, Y L Y_L YL, Y C Y_C YC是真实标签。 - 对LiDAR和摄像头模态的检测器、摄像头候选视角变换以及候选融合阶段应用损失函数。首先,每个模态特定的检测器的预测值使用匈牙利算法与真实标签进行独立匹配。对象分类优化使用焦点损失,三维边界框回归优化使用L1损失。对于摄像头模态的检测器,真实边界框位于单独的摄像头坐标中。对于所有其他检测器,真实边界框位于LiDAR坐标中。检测损失可以表示为:
L detect = γ L detect camera + L detect trans + L detect LiDAR + L detect fusion \mathcal{L}_{\text {detect }}=\gamma \mathcal{L}_{\text {detect }}^{\text {camera }}+\mathcal{L}_{\text {detect }}^{\text {trans }}+\mathcal{L}_{\text {detect }}^{\text {LiDAR }}+\mathcal{L}_{\text {detect }}^{\text {fusion }} Ldetect =γLdetect camera +Ldetect trans +Ldetect LiDAR +Ldetect fusion - 整个网络的损失函数如下:
L = α L init + \mathcal{L}=\alpha \mathcal{L}_{\text {init }}+ L=αLinit + β L detect \beta \mathcal{L}_{\text {detect }} βLdetect .
在设置中,通常 γ = 1 \gamma=1 γ=1, α = 0.1 \alpha=0.1 α=0.1, β = 1 \beta=1 β=1来平衡损失函数各项。
experiments
dataset and metrics
implementation
实现基于MMDetection3D框架。对于摄像头分支,我们使用ResNet50 作为主干网络,并使用在nuImage 上预训练的Mask R-CNN 实例分割网络对其进行初始化。输入图像的分辨率为800×448。对于LiDAR分支,我们采用VoxelNet ,体素尺寸为(0.075m, 0.075m, 0.2m)。检测范围设置为XY轴为[-54m, 54m],Z轴为[-5m, 3m]。我们的LiDAR和摄像头模态的检测器都只包括1个解码器层。LiDAR和摄像头模态的查询数量设置为NL = NC = 200,因此我们的融合阶段每个场景最多可以检测400个物体。
由于我们的框架将摄像头检测器和LiDAR检测器解耦,我们可以方便地分别对LiDAR输入和摄像头输入进行数据增强。我们对LiDAR输入应用随机旋转、缩放、平移和翻转,对摄像头输入应用随机缩放和水平翻转。我们的训练流程遵循之前的工作[1, 30, 51]。我们首先训练TransFusion-L [1]作为我们的LiDAR基线模型,用于初始化LiDAR主干网络和LiDAR模态检测器。这个只使用LiDAR的基线模型训练了20个epochs。之后,我们冻结预训练的LiDAR组件,并训练整个融合框架6个epochs。对于这两个训练阶段,我们使用AdamW优化器和one-cycle学习率策略。初始学习率为10{-4},权重衰减为10{-2}。整个模型中除了主干网络外的隐藏层维度为128。在这两个训练阶段,我们采用CBGS 来平衡类别分布。我们使用四个NVIDIA A6000 GPU进行训练,批大小为16。
结果比较
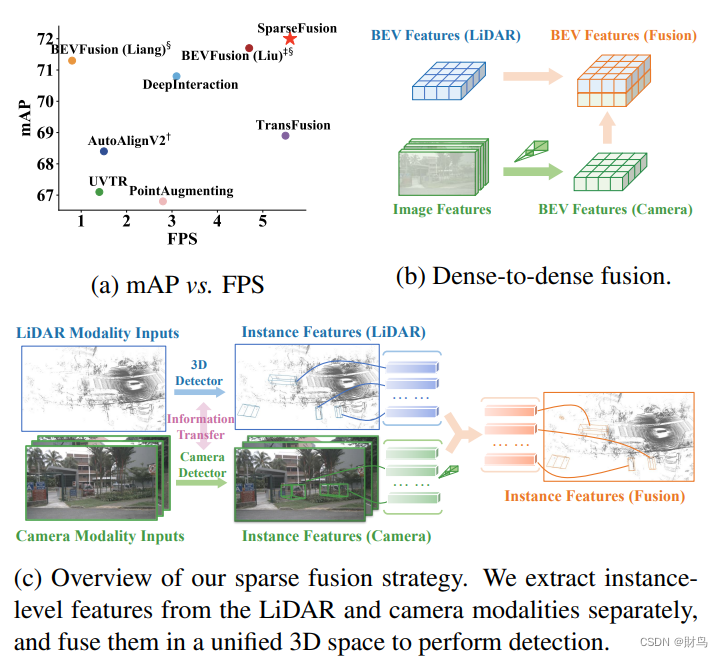
如表2所示,SparseFusion在测试集上相对于我们的只使用LiDAR的基线模型TransFusion-L [1],NDS提高了3.6%,mAP提高了6.3%,这得益于额外使用摄像头输入。更重要的是,SparseFusion在验证集和测试集上都达到了最新的技术水平,超过了包括使用更强骨干网络的之前的工作。值得注意的是,SparseFusion相对于最近的最先进方法[51]的NDS提升了0.4%,mAP提升了1.0%,同时还实现了1.8倍的加速(A6000 GPU上的5.6 FPS对比3.1 FPS)。从图1a可以看出,SparseFusion除了性能优越,还提供了最快的推理速度。我们还通过可视化一些定性结果在图7中展示了SparseFusion的性能。

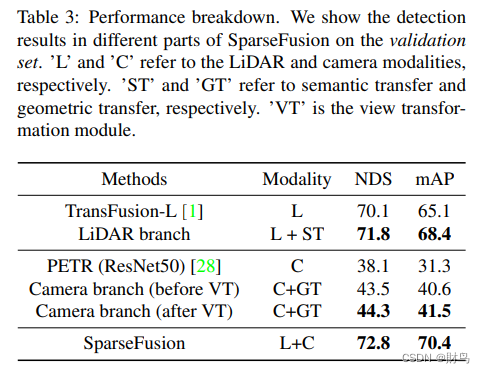
SparseFusion在LiDAR分支和摄像头分支分别进行3D物体检测。表3展示了SparseFusion不同部分(包括LiDAR分支、摄像头分支(视角转换前后)和融合分支)的检测性能。我们注意到,由于所提出的语义转换可以弥补点云输入的缺点,我们的LiDAR分支检测结果明显优于只使用LiDAR的基线模型TransFusion-L [1]。与最先进的单帧摄像头检测器PETR [28](六个解码器层)相比,我们的摄像头分支仅使用一个解码器层就实现了更好的性能,这要归功于所提出的几何转换中的深度感知特征。此外,我们的视角转换模块不仅将摄像头坐标空间中的实例特征转换为LiDAR坐标空间,还通过聚合多视角信息略微提高了摄像头分支的检测性能。凭借这种强大的性能,在每个分支中的模态特定检测器在融合过程中不会产生负面影响。
强大的图像主干网络:我们将更强大的SwinT [29]主干网络引入SparseFusion,以与一些先前的工作[23, 49]相匹配。表4比较了不同方法在nuScenes验证集上的性能。我们没有使用任何测试时的数据增强或模型集成。虽然多模态检测更依赖于LiDAR输入,但SparseFusion仍可以从更强大的图像主干网络中受益,并击败所有对手。
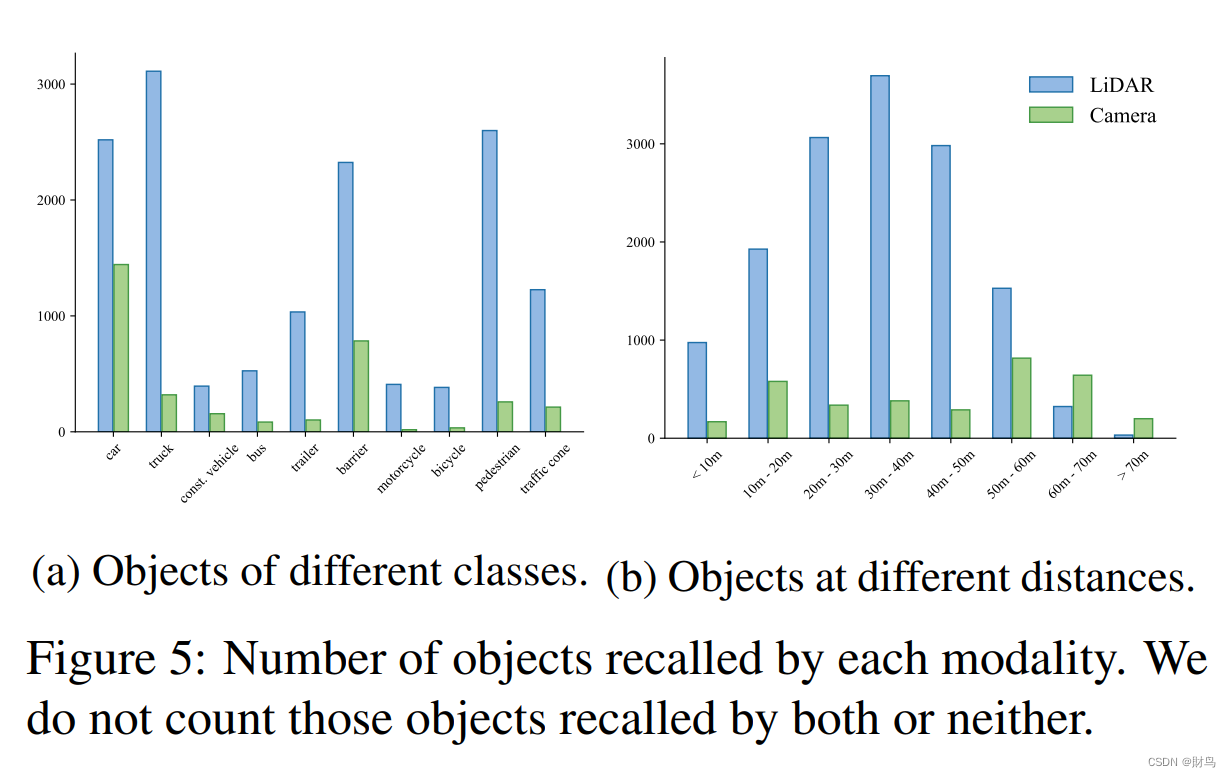
模态特定的物体召回:LiDAR分支和摄像头分支中的并行检测器使我们能够确定每个模态召回哪个物体。给定NL + NC个预测,我们知道前NL个实例来自LiDAR模态检测器,而最后NC个来自摄像头模态。如果在某个物体周围2米半径范围内预测到一个正确分类的边界框,则认为该物体被召回。在图5中,我们展示了nuScenes验证集中被确切地一个模态召回的物体数量。我们观察到每个模态都可以在一定程度上弥补另一个模态的缺点。尽管LiDAR模态通常更强大,但摄像头模态在检测汽车、工程车辆和障碍物等类别的物体时起着重要作用。此外,在点云稀疏的远距离处,摄像头模态对于检测物体非常有用。
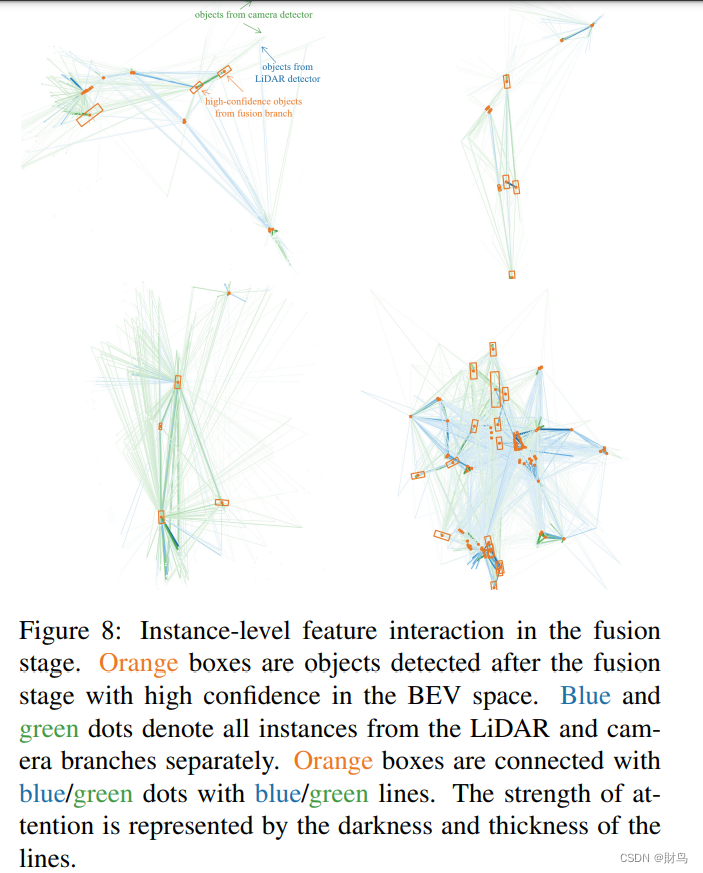
跨模态稀疏表示交互:图8可视化了稀疏融合阶段中实例特征之间的交互。线条的粗细和深浅反映了实例级特征之间的注意力强度。我们注意到大多数物体在融合过程中可以聚合多模态的实例级特征。尽管最强的交互主要存在于相邻实例之间,但有趣的是,摄像头模态的特征也能够与远处范围内的实例产生强烈的交互作用。这可能是图像中物体之间共享的语义结果。
消融实验
在这一部分中,我们研究了在SparseFusion中使用不同模块的替代方案的效果。在我们的消融研究中,我们在nuScenes训练集的1/5拆分上进行训练,并在完整的nuScenes验证集上进行评估。
稀疏融合策略
我们将我们在第3.1节中介绍的自注意力模块与其他融合方法进行了比较。除了自注意力模块之外,我们还考虑了另外三种替代方案:
1)直接将两个分支的实例级候选输入到一个多层感知器(MLP)中,没有进行任何跨实例聚合。
2)将LiDAR实例候选作为查询,摄像头实例候选作为键/值。然后使用交叉注意力模块来融合多模态实例特征。
3)我们在LiDAR-摄像头融合中使用了优化传输 [35]。我们提出通过优化传输从摄像头候选到LiDAR候选的分布转换。然后,我们可以通过沿着通道维度连接两个分支的候选来直接融合它们。
结果如下:
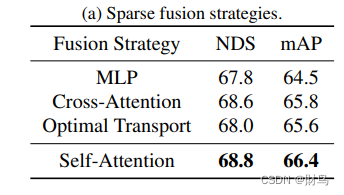
观察到cross-attention 过于依赖LiDAR分支的输出,摄像头分支没有充分利用来弥补LiDAR分支的缺点。MLP策略的性能有限,因为它不融合跨实例和跨模态信息。尽管最优传输在其他领域取得了令人印象深刻的进展,但它无法学习两种模态的实例特征之间的对应关系,因此性能有限。相比之下,自注意力简单、高效且有效。
信息传递
我们消去了LiDAR和摄像头模态之间的几何和语义传递。表5b中的结果显示,融合性能从这两种传递中受益。这也验证了两种模态的缺点导致了负向传递,而我们提出的信息传递模块确实有效地缓解了这个问题。特别是语义传递模块改善了最终的性能,因为它弥补了LiDAR模态缺乏的关键的语义信息,这对于3D检测至关重要。

视角变换。
如第3.1节所述,我们将两种模态的稀疏表示转换为一个统一的空间。为了验证这种方法的有效性,我们消除了将摄像头候选转换为LiDAR坐标空间的视角变换。这将导致更简单的方法,我们只需获得两种模态的预测结果,并直接使用自注意力进行融合。
消除视角变换将性能从66.4%的mAP和68.8%的NDS分别降至65.6%的mAP和68.3%的NDS。这表明视角变换对整体性能确实是有帮助的。
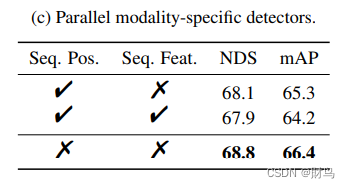
并行检测器
除了针对提出的流程中各个模块的消融研究外,我们还研究了流程结构的替代方案。SparseFusion在LiDAR和摄像头模态上使用独立的3D物体检测器并行提取实例级特征,以解决跨模态域差异的问题。作为替代方案,我们考虑了一个顺序的流程,在LiDAR检测器之后运行摄像头检测器。摄像头模态检测器继承自LiDAR检测器的输出查询。我们考虑了两种继承的变体:1)使用3D位置和实例特征作为摄像头模态初始查询;2)使用3D位置,但从对应的图像特征初始化实例特征。摄像头检测器遵循PETR [28]解码器的结构(一层)。表5c显示,这两种顺序结构的性能明显较差,这证实了我们使用并行的模态特定检测器的合理性。
附录
A:额外实验结果.实验细节
B:模型架构
A.1
在表6中,我们报告了SparseFusion和我们的仅使用LiDAR的基准线[1]在nuScenes验证集中每个目标类别上的性能。SparseFusion在所有的目标类别上都取得了显著的性能提升。特别是,引入摄像头输入有助于区分外形相似的物体,比如摩托车和自行车.

A.3 实验细节
Cross-Modality Sparse Representation Interaction:
在图8中,我们提供了更多的细节。橙色框表示融合分支检测到的高置信度物体。蓝色和绿色的点分别表示LiDAR和摄像头分支中的所有实例,即使它们只有很低的置信度。蓝色/绿色的线分别连接橙色框和蓝色/绿色的点。我们只可视化了融合分支中检测到的高置信度物体(橙色)的注意力分布。关系的强度(即注意力值)由线的深浅和粗细表示。
Optimal Transport for Sparse Fusion

B.1 网络架构
LiDAR Detector
采用了基于Transformer的LiDAR检测器,遵循TransFusion-L [1] 的方法。初始的LiDAR查询Q0L(详见B.3节)通过自注意力模块进行处理,然后使用来自LiDAR主干网络的BEV特征进行交叉注意力计算。输出的查询结果被馈送到前馈网络中,生成LiDAR候选物体QL。在自注意力和交叉注意力模块中,我们为所有的查询、键和值添加位置编码。与固定的正弦位置嵌入[41]不同的是,我们将查询、键和值在BEV平面上的2D XY位置输入到MLP编码器中,以获得学习到的嵌入。我们还附加了一个LiDAR视角预测头部(详见B.2节)到LiDAR候选物体QL上,用于获取物体的类别和LiDAR坐标系下的3D边界框信息。
camear detector
我们将Deformable-DETR [58] 扩展到了3D目标检测任务中。初始的摄像头查询Q0C(详见B.3节)经过自注意力模块处理,然后通过变形注意力与图像特征进行交互,我们通过变形注意力从FPN [25] 聚合多尺度的图像特征。在变形注意力中,每个查询仅与其对应的单视角图像特征进行交互。输出的查询结果被馈送到前馈网络中,生成透视视角的摄像头候选物体QPC。与LiDAR检测器一样,我们为所有的查询、键和值添加了位置嵌入,表示其在相应视角图像上的2D位置。我们还附加了一个透视视角预测头部(详见B.2节)到透视视角的摄像头候选物体QPC上,用于获取物体的类别以及相机坐标系下的3D边界框信息。
View Transformation(重点)
视角转换模块由两个部分组成:特征投影和多视角聚合。特征投影已经在公式1中描述过,它==使用两个MLP对相机参数和投影框进行编码,并将它们与原始实例特征结合起来。==多视角聚合基于自注意力模块。属于所有不同视角的输出实例特征被放在一起,表示为
Q
C
L
=
{
q
C
,
i
L
}
i
=
1
N
C
Q_C^L=\{ q_{C,i}^L \}_{i=1}^{N_C}
QCL={qC,iL}i=1NC。它们被馈送到自注意力模块和前馈层中。对于添加到每个实例特征的位置嵌入,我们考虑了相机检测器预测的图像上的框中心和经过边界框坐标变换后的BEV平面上的框中心。4维输入通过一个MLP,为每个实例特征获取位置嵌入。更新后的查询用作摄像头候选物体
Q
C
=
{
q
C
,
i
}
i
=
1
N
C
Q_C=\{ q_{C,i}\}_{i=1}^{N_C}
QC={qC,i}i=1NC。我们还附加了一个LiDAR视角预测头部到候选物体,用于预测LiDAR坐标系中的物体类别和3D边界框。
Fusion Branch
我们使用两个独立模块fL(·)和fC(·)分别处理LiDAR候选物体QL = {qL,i}NL i=1和摄像头候选物体QC = {qC,i}NC i=1。每个模块由一个全连接层和层归一化组成。然后,我们将候选物体连接起来,得到QLC = {qLC,i}NL+NC i=1。随后,QLC被输入到一个自注意力模块和前馈网络中,以获得最终融合的实例特征QF。
在自注意力模块中,我们还通过使用MLP对BEV平面上的框中心进行编码,为实例特征添加了一个学习到的位置嵌入。最后,我们将一个LiDAR视角预测头部附加到QF上,用于预测物体的类别和LiDAR视角下的3D边界框作为最终结果。
Geometric Transfer

Semantic Transfer
语义传输主要是利用图像修饰激光雷达点云,更确切地说是修饰激光雷达的BEV特征图。在激光雷达坐标系下的BEV特征图不是每一个网格都有雷达点的,因此只选择那些有雷达点覆盖的网格,选择该BEV Grid对应的pillar内的所有点高度的中位数作为该Grid的高度,然后将该点投影到多个相机视角去获取语义信息。通常采用的是deformable attention,也就是原lidar BEV特征作为query去与图像交互,交互的过程中会对该图像的多尺度信息(应该是图像的多个尺度特征图分别交互)都进行采集并利用max pooling来聚合多尺度信息。接着,由于一个点可能会出现在多个相机视图中,因此在对其max pooling来获取当前BEV Grid的最终特征。
Prediction head
两个预测头,一个在相机透视图视角,一个在lidar视角:
perspective view
用了6个MLP进行预测:
- 预测种类,输出dimension数是种类数,值代表置信度。
- 预测每个目标的参考点位置投影到图像上后存在的偏移,包括XY两个dimension.
- 预测深度,dimension=1
- 回归目标尺度大小,dimension为3,XYZ
- 预测目标的偏向角,用sin和cos表示,dimension=2
- 预测速度,包括Vx,Vz.dimension=2
lidar view
同样用了6个MLP预测:
- 预测种类,输出dimension数是种类数,值代表置信度。
- 预测BEV下每个目标的参考点位置存在的偏移,包括XY两个dimension.
- 回归目标的高度信息。dimension=1
- 回归目标的尺寸信息,dimension=3,XYZ
- 预测目标的偏向角,用sin和cos表示,dimension=2
- 预测速度,包括Vx,Vz.dimension=2
query initialization
我们遵循CenterFormer [56]和TransFusion [1]的方法,使用热图来初始化我们的查询。这有助于加速收敛并减少查询的数量。
initialization for lidar detector
我们将边界框的中心在BEV上进行打散,并投影到一个类别感知的热图上。(We splatter the bounding box centers on the BEV onto a category-aware heatmap )
Y
∈
[
0
,
1
]
H
×
W
×
K
Y\in [0,1]^{H\times W\times K}
Y∈[0,1]H×W×K,k代表了种类数,y值用一个高斯函数生成
Y
x
,
y
,
k
i
=
\mathbf{Y}_{x, y, k_i}=
Yx,y,ki=
exp
[
(
x
−
c
x
,
i
L
)
2
+
(
y
−
c
y
,
i
L
)
2
2
σ
i
2
]
\exp \left[\frac{\left(x-c_{x, i}^L\right)^2+\left(y-c_{y, i}^L\right)^2}{2 \sigma_i^2}\right]
exp[2σi2(x−cx,iL)2+(y−cy,iL)2],
k
i
k_i
ki指某个种类的第i个目标,
c
x
,
i
,
c
y
,
i
c_{x,i},c_{y,i}
cx,i,cy,i是BEV Grid的中心,
σ
i
\sigma_i
σi是一个与物体尺度有关的标准差。
对于每个物体,我们分别计算热图,并通过在每个位置上选择最大值来合并多个物体的热图。我们将由3×3卷积组成的密集头连接到BEV特征
F
L
F_L
FL上,同时使用语义转移进行增强.

INITIALIZATION FOR CAMERA DETECTOR
















 132
132











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









