







文章启发点:
PV2BEV基于深度估计的开山之作,在cam2BEV中作者展望说如何将深度信息引入模型,LSS放弃了IPM,但是又没有像cam2BEV的消融实验那样只采用神经网络输入输出都是图片,而是在输入神经网络前设计了输入数据的表示,直接将待估计的深度与图片特征信息结合,将原有数据提升了一个维度,所以叫lift。
Abstract
自主车辆感知的目标是从多个传感器中提取语义表示,并将这些表示融合到单个“鸟瞰”坐标框架中,以供运动规划使用。文章提出了一种新的端到端架构,它可以直接从任意数量的摄像机中提取场景给定图像数据的鸟瞰表示。方法的核心思想是将每个图像特征分别“提升”为一个截锥体,然后将所有截锥体压平为鸟瞰网。为了实现学习运动规划,通过将模板轨迹“映射”到我们的网络输出的鸟瞰成本图中,模型推断能够实现可解释的端到端运动规划。
Related work
单目相机目标检测
传统的是在图像平面中应用成熟的2D对象检测器,然后训练第二个网络将2D框回归为3D框
然后出现了一种架构训练标准2d检测器,以使用一种损失来预测深度,该损失旨在将由于不正确的深度而导致的误差与由于不正确边界框而导致的错误分离开来。最经典的是 一个网络进行单独的深度预测,另一个网络进行鸟瞰图检测。这种也被称作为激光雷达。
还有一种是逆向思维,通过现实世界的体素空间根据相机的内外参数透视变换到图像抓取图像上的特征作为该体素空间的特征,这样大部分体素都会有语义信息,然后训练一个3D目标检测网络进行目标检测。(我觉得这种方法很有意思,在体素中再融合雷达信息会不会有收获,这篇文章叫Mono3D,有时间可以读一下,这和鸟瞰图一样,可以融合各种传感器吧,突然有反应过来,这个好像是oft的思路啊,沿着一条射线的好多体素会抓取相同的图片特征信息,啧。。。)
在鸟瞰图中进行推理预测
MonoLayout,FISHING Net,Pyramid Occupancy Networks 可做了解
Method
模型的输入:
n张图片信息![]()
n个相机的内、外参数矩阵![]()
![]()
相机内外惨要与图片相对应,每个内外参数矩阵都定义了从参考坐标(x,y,z)到局部像素坐标(h,w,d)的映射。
Lift操作
目的:将每个图像从局部二维坐标系(基于单部相机视角的坐标)“提升”到所有摄像机共享(基于汽车的坐标)的三维帧。
方法:为每个像素生成所有可能深度的表示。
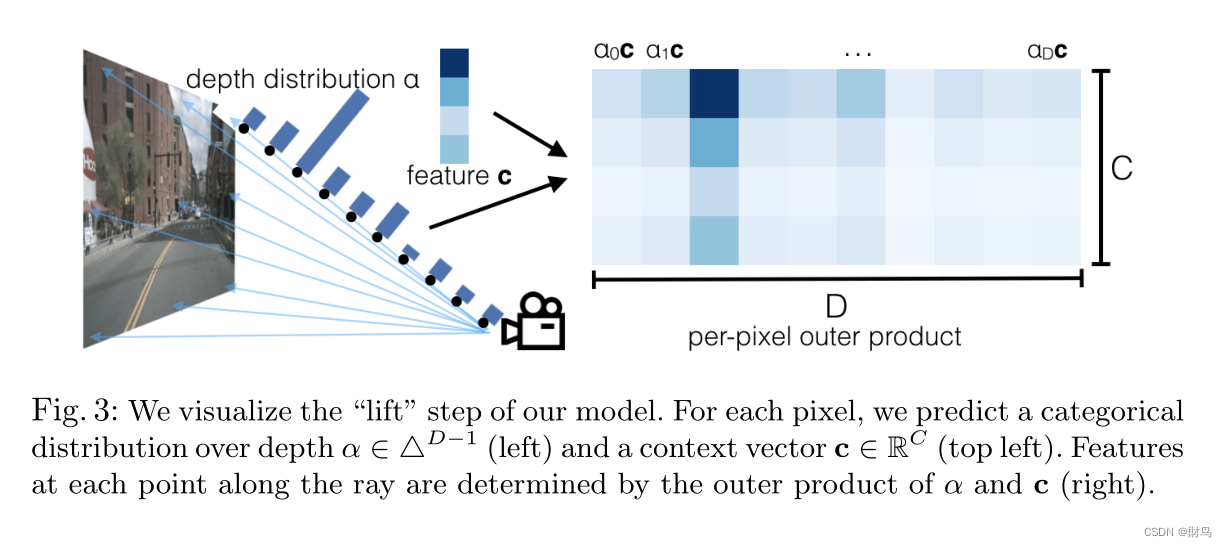
lift的全部操作就是上图(1)根据相机的内外参数矩阵,将图像中每个像素与空间中一条射线对应。将射线离散化D段,每一段都对应一个分布概率,然后为了像素点拥有周围语义信息又为每个像素分配了长度为C的特征向量,所以每个像素就对应一个特征矩阵C*D。此时就完成了升维操作。

Splat
就是为了提高计算效率,就是将竖直方向上栅格内的点求和作为该栅格的特征值,就是pillars原理。
shoot
主要是轨迹预测什么的,没太关注
代码实现过程
在代码实现的过程中利用了两个函数:
一个函数get_geometry()将图像划分网格对应到空间中,形成voxels,然后又利用相机内外参数将像素坐标转换到自车坐标中去,每个点都是(x,y,z),得到输出Y,shape为B*N*D*H*W*3(4*6*41*8*22*3)。
与此同时并行操作的是利用get_cam_feats()函数将图片进行初步的特征提取得到B*N*(D+C)*H*W,(4*6*(41+64)*8*22),在后在特征维划分为两部分,然后在利用广播机制给实现升维得到X,shape为B*N*D*H*W*C,(4*6*41*8*22*64)。
然后将上面两个输出输入到函数voxel_pooling,通过剔除界外和voxels内多余的点,得到池化后的X1,Y1,然后将利用二者的对映关系将X1特征值放到voxels内,输出为4*64*1*200*200(此处为1是因为在划分voxels时只在竖直方向上留了一个值),消除Z轴4*64*200*200,此时就得到了鸟瞰图的效果。
后面只需要在鸟瞰图上利用resnet进一步提取特征和分类就好了。
执行如图所示。

代码如下,作为新手小白,里面还有我不懂得的标注,大佬可以帮我回答一下非常感谢。
"""
Copyright (C) 2020 NVIDIA Corporation. All rights reserved.
Licensed under the NVIDIA Source Code License. See LICENSE at https://github.com/nv-tlabs/lift-splat-shoot.
Authors: Jonah Philion and Sanja Fidler
"""
import torch
from torch import nn
from efficientnet_pytorch import EfficientNet
from torchvision.models.resnet import resnet18
from .tools import gen_dx_bx, cumsum_trick, QuickCumsum
class Up(nn.Module):
def __init__(self, in_channels, out_channels, scale_factor=2):
super().__init__()
self.up = nn.Upsample(scale_factor=scale_factor, mode='bilinear',
align_corners=True) # 上采样 BxCxHxW->BxCx2Hx2W
self.conv = nn.Sequential( # 两个3x3卷积
nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=1, bias=False),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True), # inplace=True使用原地操作,节省内存
nn.Conv2d(out_channels, out_channels, kernel_size=3, padding=1, bias=False),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True)
)
def forward(self, x1, x2):
x1 = self.up(x1) # 对x1进行上采样
x1 = torch.cat([x2, x1], dim=1) # 将x1和x2 concat 在一起
return self.conv(x1)
class CamEncode(nn.Module): # 提取图像特征进行图像编码
def __init__(self, D, C, downsample):
super(CamEncode, self).__init__()
self.D = D # 41
self.C = C # 64
self.trunk = EfficientNet.from_pretrained("efficientnet-b0") # 使用 efficientnet 提取特征
self.up1 = Up(320+112, 512) # 上采样模块,输入输出通道分别为320+112和512
self.depthnet = nn.Conv2d(512, self.D + self.C, kernel_size=1, padding=0) # 1x1卷积,变换维度
def get_depth_dist(self, x, eps=1e-20): # 对深度维进行softmax,得到每个像素不同深度的概率
return x.softmax(dim=1)
def get_depth_feat(self, x):
x = self.get_eff_depth(x) # 使用efficientnet提取特征 x: 24 x 512 x 8 x 22
# Depth
x = self.depthnet(x) # 1x1卷积变换维度 x: 24 x 105(C+D) x 8 x 22
depth = self.get_depth_dist(x[:, :self.D]) # 第二个维度的前D个作为深度维,进行softmax depth: 24 x 41 x 8 x 22
new_x = depth.unsqueeze(1) * x[:, self.D:(self.D + self.C)].unsqueeze(2) # 将特征通道维和通道维利用广播机制相乘 new_x: 24 x 64 x 41 x 8 x 22
return depth, new_x
def get_eff_depth(self, x): # 使用efficientnet提取特征
# adapted from https://github.com/lukemelas/EfficientNet-PyTorch/blob/master/efficientnet_pytorch/model.py#L231
endpoints = dict()
# Stem
x = self.trunk._swish(self.trunk._bn0(self.trunk._conv_stem(x))) # x: 24 x 32 x 64 x 176
prev_x = x
# Blocks
for idx, block in enumerate(self.trunk._blocks):
drop_connect_rate = self.trunk._global_params.drop_connect_rate
if drop_connect_rate:
drop_connect_rate *= float(idx) / len(self.trunk._blocks) # scale drop connect_rate
x = block(x, drop_connect_rate=drop_connect_rate)
if prev_x.size(2) > x.size(2):
endpoints['reduction_{}'.format(len(endpoints)+1)] = prev_x
prev_x = x
# Head
endpoints['reduction_{}'.format(len(endpoints)+1)] = x # x: 24 x 320 x 4 x 11
x = self.up1(endpoints['reduction_5'], endpoints['reduction_4']) # 先对endpoints[4]进行上采样,然后将 endpoints[5]和endpoints[4] concat 在一起
return x # x: 24 x 512 x 8 x 22
def forward(self, x):
depth, x = self.get_depth_feat(x) # depth: B*N x D x fH x fW(24 x 41 x 8 x 22) x: B*N x C x D x fH x fW(24 x 64 x 41 x 8 x 22)
return x
class BevEncode(nn.Module):
def __init__(self, inC, outC): # inC: 64 outC: 1
super(BevEncode, self).__init__()
# 使用resnet的前3个stage作为backbone
trunk = resnet18(pretrained=False, zero_init_residual=True)
self.conv1 = nn.Conv2d(inC, 64, kernel_size=7, stride=2, padding=3,
bias=False)
self.bn1 = trunk.bn1
self.relu = trunk.relu
self.layer1 = trunk.layer1
self.layer2 = trunk.layer2
self.layer3 = trunk.layer3
self.up1 = Up(64+256, 256, scale_factor=4)
self.up2 = nn.Sequential( # 2倍上采样->3x3卷积->1x1卷积
nn.Upsample(scale_factor=2, mode='bilinear',
align_corners=True),
nn.Conv2d(256, 128, kernel_size=3, padding=1, bias=False),
nn.BatchNorm2d(128),
nn.ReLU(inplace=True),
nn.Conv2d(128, outC, kernel_size=1, padding=0),
)
def forward(self, x): # x: 4 x 64 x 200 x 200
x = self.conv1(x) # x: 4 x 64 x 100 x 100
x = self.bn1(x)
x = self.relu(x)
x1 = self.layer1(x) # x1: 4 x 64 x 100 x 100
x = self.layer2(x1) # x: 4 x 128 x 50 x 50
x = self.layer3(x) # x: 4 x 256 x 25 x 25
x = self.up1(x, x1) # 给x进行4倍上采样然后和x1 concat 在一起 x: 4 x 256 x 100 x 100
x = self.up2(x) # 2倍上采样->3x3卷积->1x1卷积 x: 4 x 1 x 200 x 200
return x
class LiftSplatShoot(nn.Module):
def __init__(self, grid_conf, data_aug_conf, outC):
super(LiftSplatShoot, self).__init__()
self.grid_conf = grid_conf # 网格配置参数
self.data_aug_conf = data_aug_conf # 数据增强配置参数
dx, bx, nx = gen_dx_bx(self.grid_conf['xbound'],
self.grid_conf['ybound'],
self.grid_conf['zbound'],
) # 划分网格
self.dx = nn.Parameter(dx, requires_grad=False) # [0.5,0.5,20]三个轴上格子间距
self.bx = nn.Parameter(bx, requires_grad=False) # [-49.5,-49.5,0]三个轴上的起始坐标
self.nx = nn.Parameter(nx, requires_grad=False) # [200,200,1]三个轴上的格子数量
self.downsample = 16 # 下采样倍数
self.camC = 64 # 图像特征维度
self.frustum = self.create_frustum() # frustum: DxfHxfWx3(41x8x22x3)
self.D, _, _, _ = self.frustum.shape # D: 41
self.camencode = CamEncode(self.D, self.camC, self.downsample)
self.bevencode = BevEncode(inC=self.camC, outC=outC)
# toggle using QuickCumsum vs. autograd
self.use_quickcumsum = True
def create_frustum(self):
# make grid in image plane
ogfH, ogfW = self.data_aug_conf['final_dim'] # 原始图片大小 ogfH:128 ogfW:352
fH, fW = ogfH // self.downsample, ogfW // self.downsample # 下采样16倍后图像大小 fH: 8 fW: 22
ds = torch.arange(*self.grid_conf['dbound'], dtype=torch.float).view(-1, 1, 1).expand(-1, fH, fW) # 在深度方向上划分网格 ds: DxfHxfW(41x8x22)
D, _, _ = ds.shape # D: 41 表示深度方向上网格的数量
xs = torch.linspace(0, ogfW - 1, fW, dtype=torch.float).view(1, 1, fW).expand(D, fH, fW) # 在0到351上划分22个格子 xs: DxfHxfW(41x8x22)
ys = torch.linspace(0, ogfH - 1, fH, dtype=torch.float).view(1, fH, 1).expand(D, fH, fW) # 在0到127上划分8个格子 ys: DxfHxfW(41x8x22)
# D x H x W x 3
frustum = torch.stack((xs, ys, ds), -1) # 堆积起来形成网格坐标, frustum[i,j,k,0]就是(i,j)位置,深度为k的像素的宽度方向上的栅格坐标 frustum: DxfHxfWx3
return nn.Parameter(frustum, requires_grad=False)
def get_geometry(self, rots, trans, intrins, post_rots, post_trans):
"""Determine the (x,y,z) locations (in the ego frame)
of the points in the point cloud.
Returns B x N x D x H/downsample x W/downsample x 3
"""
B, N, _ = trans.shape # B:4(batchsize) N: 6(相机数目)
# undo post-transformation
# B x N x D x H x W x 3
#?????????????????????????????????????????????????????
# 抵消数据增强及预处理对像素的变化.但是数据增强是如何影响视锥的呢,为什么是减去,不应该是视锥也做同样的增强与图片对应起来嘛,而且他俩维度也不一样啊,怎么相减,是利用了广播机制吗
points = self.frustum - post_trans.view(B, N, 1, 1, 1, 3)#减去数据增强时的平移变换
points = torch.inverse(post_rots).view(B, N, 1, 1, 1, 3, 3).matmul(points.unsqueeze(-1))#把图像转回去
# cam_to_ego
points = torch.cat((points[:, :, :, :, :, :2] * points[:, :, :, :, :, 2:3],
points[:, :, :, :, :, 2:3]
), 5) # 将像素坐标(u,v,d)变成齐次坐标(du,dv,d),我看了一下齐次坐标的定义,然后才明白,就是u,v,同时乘以d,然后在与d在拼接起来
# d[u,v,1]^T=intrins*rots^(-1)*([x,y,z]^T-trans),逆公式表达出x,y,z即可
# imgs: 图像数据
# rots: 相机坐标系到自车坐标系的旋转矩阵
# trans: 相机坐标系到自车坐标系的平移向量
# intrins: 相机内参
# post_rots: 数据增强的像素坐标旋转映射关系
# post_trans: 数据增强的像素坐标平移映射关系
# imgs: 4 x 5 x 3 x 128 x 352
# rots: 4 x 5 x 3 x 3]
# trans: 4 x 5 x 3
# intrins: 4 x 5 x 3 x 3
# post_rots: 4 x 5 x 3 x 3
# post_trans: 4 x 5 x 3
# binimgs: 4 x 1 x 200 x 200
combine = rots.matmul(torch.inverse(intrins))
points = combine.view(B, N, 1, 1, 1, 3, 3).matmul(points).squeeze(-1)
points += trans.view(B, N, 1, 1, 1, 3) # 将像素坐标d[u,v,1]^T转换到车体坐标系下的[x,y,z]^T
return points # B x N x D x H x W x 3 (4 x 6 x 41 x 8 x 22 x 3),此时最后一维度代表的就是车坐标下的下,x,y,z
def get_cam_feats(self, x):
"""Return B x N x D x H/downsample x W/downsample x C
"""
B, N, C, imH, imW = x.shape # B: 4 N: 6 C: 3 imH: 128 imW: 352
x = x.view(B*N, C, imH, imW) # B和N两个维度合起来 x: 24 x 3 x 128 x 352
x = self.camencode(x) # 进行图像编码 x: B*N x C x D x fH x fW(24 x 64 x 41 x 8 x 22)
#此处将前两维度拆开时能保证顺序和合并前一样吗,不然我总怀疑最后图片输入的特征及深度分布如何映射到根据相机内外参数得到的视锥栅格里的
x = x.view(B, N, self.camC, self.D, imH//self.downsample, imW//self.downsample) #将前两维拆开 x: B x N x C x D x fH x fW(4 x 6 x 64 x 41 x 8 x 22),
x = x.permute(0, 1, 3, 4, 5, 2) # x: B x N x D x fH x fW x C(4 x 6 x 41 x 8 x 22 x 64)
return x
def voxel_pooling(self, geom_feats, x):
# geom_feats: B x N x D x H x W x 3 (4 x 6 x 41 x 8 x 22 x 3)
# x: B x N x D x fH x fW x C(4 x 6 x 41 x 8 x 22 x 64)
B, N, D, H, W, C = x.shape # B: 4 N: 6 D: 41 H: 8 W: 22 C: 64
Nprime = B*N*D*H*W # Nprime: 173184
# flatten x
x = x.reshape(Nprime, C) # 将图像展平,一共有 B*N*D*H*W 个点
# flatten indices
geom_feats = ((geom_feats - (self.bx - self.dx/2.)) / self.dx).long() # 将[-50,50] [-10 10]的范围平移到[0,100] [0,20],计算栅格坐标并取整
geom_feats = geom_feats.view(Nprime, 3) # 将像素映射关系同样展平 geom_feats: B*N*D*H*W x 3 (173184 x 3)
batch_ix = torch.cat([torch.full([Nprime//B, 1], ix,
device=x.device, dtype=torch.long) for ix in range(B)]) # 每个点对应于哪个batch
geom_feats = torch.cat((geom_feats, batch_ix), 1) # geom_feats: B*N*D*H*W x 4(173184 x 4), geom_feats[:,3]表示batch_id
# filter out points that are outside box
# 过滤掉在边界线之外的点 x:0~199 y: 0~199 z: 0
kept = (geom_feats[:, 0] >= 0) & (geom_feats[:, 0] < self.nx[0])\
& (geom_feats[:, 1] >= 0) & (geom_feats[:, 1] < self.nx[1])\
& (geom_feats[:, 2] >= 0) & (geom_feats[:, 2] < self.nx[2])
x = x[kept] # x: 168648 x 64,这里x和geom_feats是如何对应起来的,是展平的形式一样,直接按展平的点的顺序对应起来的吗?
geom_feats = geom_feats[kept]
# get tensors from the same voxel next to each other
#这个我好一会儿才反应过来,给x轴最高权重,然后y轴,z轴,最后batch,类似于十位,百位的感觉,同一个格子里的点坐标相同,rank相同
ranks = geom_feats[:, 0] * (self.nx[1] * self.nx[2] * B)\
+ geom_feats[:, 1] * (self.nx[2] * B)\
+ geom_feats[:, 2] * B\
+ geom_feats[:, 3] # 给每一个点一个rank值,rank相等的点在同一个batch,并且在在同一个格子里面
sorts = ranks.argsort()
x, geom_feats, ranks = x[sorts], geom_feats[sorts], ranks[sorts] # 按照rank排序,这样rank相近的点就在一起了
# x: 168648 x 64 geom_feats: 168648 x 4 ranks: 168648
# cumsum trick
if not self.use_quickcumsum:
x, geom_feats = cumsum_trick(x, geom_feats, ranks)#剔除了同一单元格里重复的点,并将其特征值累加起来
else:
x, geom_feats = QuickCumsum.apply(x, geom_feats, ranks) # 一个batch的一个格子里只留一个点 x: 29072 x 64 geom_feats: 29072 x 4
# griddify (B x C x Z x X x Y)
final = torch.zeros((B, C, self.nx[2], self.nx[0], self.nx[1]), device=x.device) # final: 4 x 64 x 1 x 200 x 200
#这句语义是理解的,只是这放的方式感觉怪怪的
final[geom_feats[:, 3], :, geom_feats[:, 2], geom_feats[:, 0], geom_feats[:, 1]] = x # 将x按照栅格坐标放到final中
# collapse Z
final = torch.cat(final.unbind(dim=2), 1) # 消除掉z维
return final # final: 4 x 64 x 200 x 200
def get_voxels(self, x, rots, trans, intrins, post_rots, post_trans):
geom = self.get_geometry(rots, trans, intrins, post_rots, post_trans) # 此处标定后就是固定的参数.像素坐标到自车中坐标的映射关系 geom: B x N x D x H x W x 3 (4 x 6 x 41 x 8 x 22 x 3)
x = self.get_cam_feats(x) # 提取图像特征并预测深度编码 x: B x N x D x fH x fW x C(4 x 6 x 41 x 8 x 22 x 64)
x = self.voxel_pooling(geom, x) # x: 4 x 64 x 200 x 200
return x
def forward(self, x, rots, trans, intrins, post_rots, post_trans):
# x:[4,6,3,128,352]
# rots: [4,6,3,3]
# trans: [4,6,3]
# intrins: [4,6,3,3]
# post_rots: [4,6,3,3]
# post_trans: [4,6,3]
x = self.get_voxels(x, rots, trans, intrins, post_rots, post_trans) # 将图像转换到BEV下,x: B x C x 200 x 200 (4 x 64 x 200 x 200)
x = self.bevencode(x) # 用resnet18提取特征 x: 4 x 1 x 200 x 200
return x
def compile_model(grid_conf, data_aug_conf, outC):
return LiftSplatShoot(grid_conf, data_aug_conf, outC)














 90
90











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









