







<“VQ-HPS: HUMAN POSE AND SHAPE ESTIMATION IN A VECTOR-QUANTIZED LATENT SPACE” >

论文信息
| 标题 | “Vq-hps:矢量量化潜在空间中的人体姿态和形状估计” (Fiche 等, 2024, p. 1) |
摘要
“Human Pose and Shape Estimation”
以往的人体姿态和形状估计(HPSE)研究主要分为参数化和非参数化方法两大类。参数化技术利用低维统计人体模型获得逼真结果,而非参数化方法通过直接回归人体网格的3D坐标来实现更高的精度。本研究提出了一种新的范式来解决HPSE问题,涉及对人体网格的低维离散潜在表示,并把HPSE框架为分类任务。我们不是预测人体模型参数或3D顶点坐标,而是专注于预测所提出的离散潜在表示,它可以解码成注册的人体网格。这种创新范式提供了两个关键优势。首先,预测低维离散表示将我们的预测限制在即使训练数据很少时的人体姿态和形状空间内。其次,通过将问题框架为分类任务,我们可以利用神经网络固有的区分能力。所提出的模型VQ-HPS预测网格的离散潜在表示。实验结果表明,VQ-HPS在训练数据很少的情况下,超越了当前最先进的非参数化方法,并且当用少量数据训练时,其结果与参数化方法一样逼真。VQ-HPS在大规模数据集上训练时也显示出有希望的结果,突出了分类方法在HPSE中的重要潜力。
📊 研究背景
回归人体模型参数的方法面临着文献中记载的几个问题:
1)参数化方法在捕获详细的身体形状方面存在困难,并且偏向于平均形状
2)大多数人体模型使用沿运动树的旋转来表达姿势。除了神经网络难以预测外,当所有旋转同时预测时, 这种表示会导致误差积累
3)大多数回归方法从图像中提取全局特征向量作为输入,不包含细粒度的局部细节
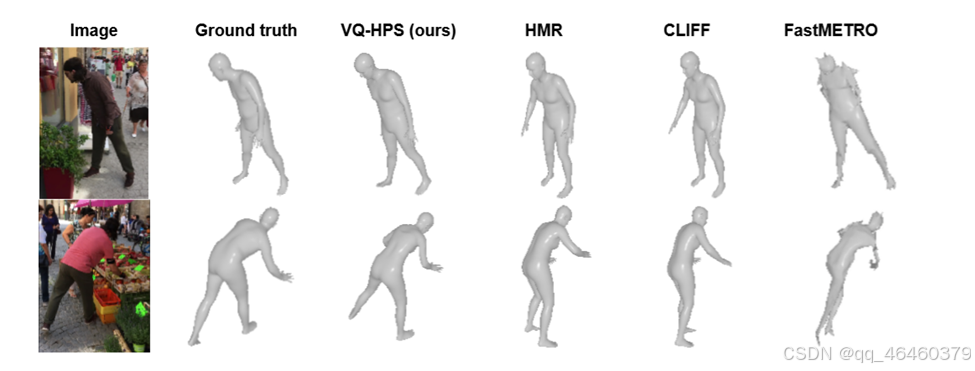
展示了VQ-HPS在野外条件和光照较差的两种具有挑战性的场景下的结果,并将其性能与HMR、CLIFF和FastMETRO-S在小数据训练下的性能进行了比较。
HMR是参数化人体网格恢复的基本架构,
CLIFF是参数化HPSE的SOTA
FastMETRO是非参数化 HPSE的SOTA
HMR(Hourglass Multi-stage Regression)
- 基本架构:HMR是一种参数化方法,它使用一个称为“Hourglass”的网络结构,通过多阶段的回归过程逐步精细化地预测人体的姿态和形状参数。
- 工作流程:它首先粗略估计人体的姿态和形状,然后逐步细化这些估计,以生成更精确的3D人体模型。
- 特点:HMR能够以端到端的方式从单张图像中恢复出详细的人体姿态和形状,是参数化方法中的基础架构之一。
CLIFF(Carrying Location Information in Full Frames)
- SOTA(State-of-the-Art):CLIFF是参数化HPSE领域的最先进方法之一,它通过在特征提取过程中携带位置信息来改进人体姿态和形状的估计。
- 特点:CLIFF通过在网络的每个阶段都保持位置信息,能够更准确地预测人体的姿态和形状,尤其是在处理遮挡和复杂场景时。
非参数化方法
非参数化方法不依赖于预定义的参数化模型,而是直接从图像中学习并预测人体的3D姿态和形状。这些方法通常需要更多的数据来训练,因为它们需要从零开始学习人体的3D结构。
FastMETRO
- SOTA:FastMETRO是非参数化HPSE领域的最先进方法之一,它使用基于Transformer的架构来直接预测人体的3D顶点。
- 工作流程:FastMETRO通过分析图像特征和学习人体结构的全局模式,能够生成精确的3D人体网格,而不需要依赖于参数化模型。
- 特点:FastMETRO通过Transformer的自注意力机制,能够有效地捕捉图像中的长距离依赖关系,从而在没有预定义参数的情况下也能实现高精度的人体姿态和形状估计。
Mesh-VQ-VAE架构提供了3D网格的离散潜在表示。
HPSE问题的基于分类的公式,使用引入的人类网格的离散潜在表示。
VQ-HPS,一种基于变压器的编码器-解码器模型学习,利用交叉熵损失来解决所提出的HPSE分类问题。”
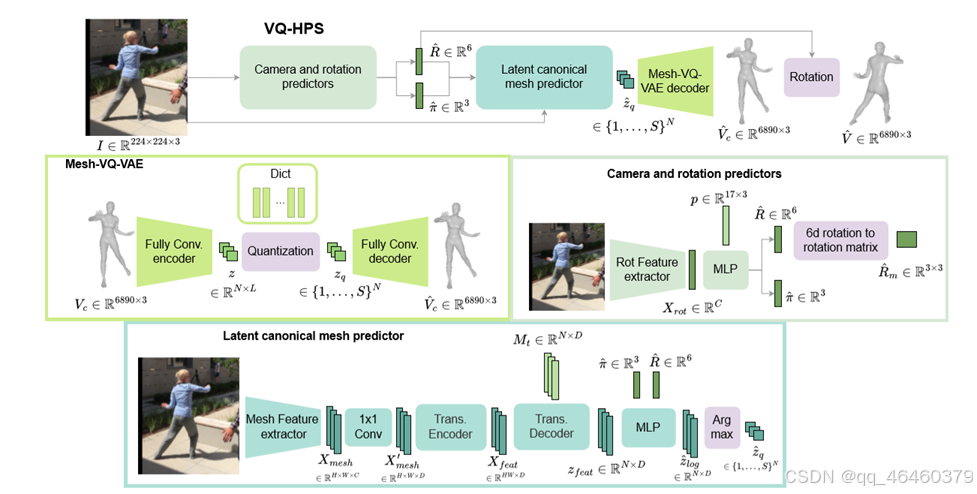
1. 潜在规范网格预测器(Latent canonical mesh predictor)
a. 特征提取
- 输入图像 I通过一系列卷积层进行处理,提取出图像的特征 Xfeat。这些特征包含了图像中人体的姿态和形状信息。
b. Transformer 编码器
- 编码器接收这些特征,并进一步处理它们以提取更深层次的特征表示。这些表示被用来预测人体的姿态和形状。
c. 预测离散潜在表示
- 通过 Transformer 编码器处理后的特征被送入一个多层感知器(MLP),这个 MLP 预测出一个离散的潜在表示 z^q。这里的 z^q是一个离散的编码,它代表了人体网格的一种可能配置。
2. Mesh-VQ-VAE 解码器
Mesh-VQ-VAE 解码器的作用是将预测的离散潜在表示 z^q 转换回一个具体的3D人体网格。这个过程包括:
a. 离散潜在表示的解码
- 给定的离散潜在表示 z^q 被送入解码器。解码器的任务是利用这个离散表示来重建一个3D人体网格。
b. 网格重建
- 解码器输出一个初步的3D人体网格 V^c,这个网格是在不考虑相机视角和旋转的情况下重建的。
3. z^q的作用
- z^q 是模型预测的离散潜在表示,它是通过量化连续潜在空间得到的。在 VQ-HPS 模型中,z^q是一个关键的中间输出,它直接影响最终的3D网格重建质量。
- 这个离散表示使得模型能够以一种更紧凑和离散的方式表示和处理复杂的3D人体姿态和形状信息。
步骤 1: 输入图像
首先,我们有一张彩色图像 I,它的尺寸是 224x224 像素,这是一个标准的输入,用于后续的处理。
步骤 2: 特征提取
- 全卷积编码器:这个部分负责从输入图像中提取特征。它处理图像并生成一个特征映射 Xmesh,这些特征包含了图像中的空间信息和内容。
- 1x1 卷积:这是一个特殊的卷积操作,它不改变特征图的空间维度,但可以调整特征的深度,为后续的 Transformer 编码器准备合适的输入格式 Xmesh′。
步骤 3: 旋转和相机参数预测
- 旋转特征提取器:这个组件从图像中提取用于预测相机视角和人体旋转的特征。
- 多图层感知器 (MLP):这是一个神经网络模块,用于根据提取的特征预测相机参数 π^ 和旋转 R^。这些参数对于理解图像的拍摄条件和人体的3D姿态至关重要。
步骤 4: 潜在规范网格预测
- Transformer 编码器:编码器接收处理过的特征 Xmesh′并输出编码后的特征 Xfeat,这些特征包含了丰富的空间信息。
- 潜在规范网格预测器:这个部分使用 Transformer 解码器和一些预定义的网格标记 Mt 来预测人体的潜在表示 z^q。这个潜在表示是一个离散的编码,它将被用来重建3D网格。
步骤 5: 网格重建
- VAE 解码器:使用预测的离散潜在表示 z^q,VAE 解码器重建出一个规范的3D人体网格 V^c。这个网格是一个简化的模型,代表了人体的基本形状和姿态。
- 旋转矩阵转换:预测的旋转 R^ 被转换为一个3x3的旋转矩阵 R^m,这个矩阵将用于调整规范网格的方向,使其与图像中的实际姿态相匹配。
- 最终网格重建:最后,规范网格 V^c 根据旋转矩阵 R^m进行调整,生成最终的3D人体网格 V^。
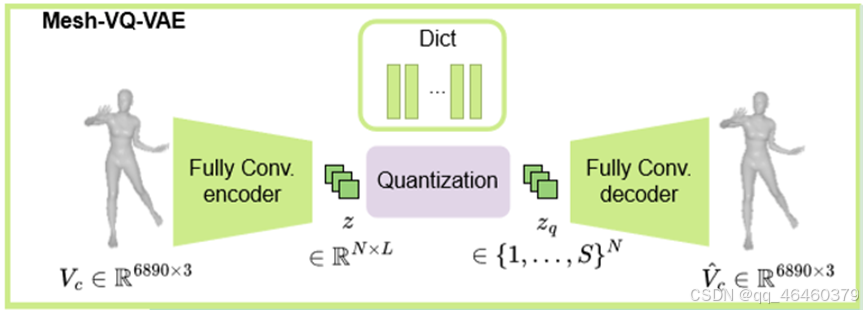
1. 输入的3D人体网格
- Vc∈R6890×3: 这是输入的3D人体网格,其中6890表示网格中的顶点数,每个顶点由3个坐标值(x, y, z)表示,构成了一个6890x3的矩阵。
2. 全卷积编码器
- Fully Conv. encoder: 这个组件使用全卷积网络来处理输入的3D人体网格。全卷积网络能够保持空间信息,这对于理解和编码复杂的3D结构非常重要。
- 作用: 编码器将3D网格数据转换成一个连续的潜在空间表示,这个表示捕捉了人体网格的关键特征。
3. 向量量化(Quantization)
- Dict: 这是向量量化过程中使用的“码本”(Dictionary),它包含了一组离散的潜在向量,每个向量代表潜在空间中的一个点。
- zq∈{1,…,S}N: 这是向量量化后的潜在表示,其中 S 是码本的大小, N 是潜在向量的维度。每个元素是码本中向量的索引,表示最接近原始连续潜在表示的向量。
4. 重建的3D人体网格
- V^c∈R6890×3: 这是重建的3D人体网格,它由解码器根据量化后的潜在表示 zq 生成。重建的网格旨在尽可能地接近原始输入网格 Vc。
- 过程:
- 首先,编码器将输入的3D人体网格 Vc 编码成一个连续的潜在表示。
- 然后,通过查找码本中与连续潜在表示最接近的向量,进行向量量化,得到离散的潜在表示zq。
- 最后,解码器使用zq 和码本来重建出3D人体网格V^c。
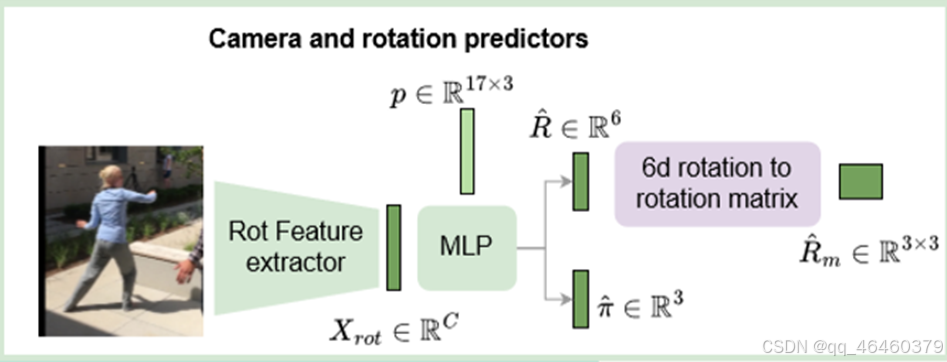
- 旋转特征提取器 (Rot Feature extractor)
- 输入:图像特征 Xrt∈RC,这些特征包含了有助于旋转预测的视觉信息。
- 输出:用于后续旋转预测的特征表示。
- 多图层感知器 (MLP)
- 功能:基于旋转特征,使用一个多层感知器来预测旋转向量 R^∈R6 和相机参数 π^∈R3。
- 旋转向量 R^:表示人体相对于相机的旋转,通常以6D旋转表示。
- 相机参数 π^:包括相机的位置、视角等信息,用于描述相机的配置。
- 6D旋转到旋转矩阵的转换
- 输入:6D旋转向量 R^∈R6。
- 输出:旋转矩阵 R^m∈R3×3。
- 功能:将6D旋转向量转换为旋转矩阵,用于后续的3D姿态和形状估计。
- 初始化的人体姿态 (p)
- 输入:一个初始的人体姿态 p∈R17×3,通常为T-Pse或其他标准姿态。
- 功能:作为旋转预测的参考点,帮助模型更好地理解和预测人体姿态的变化。
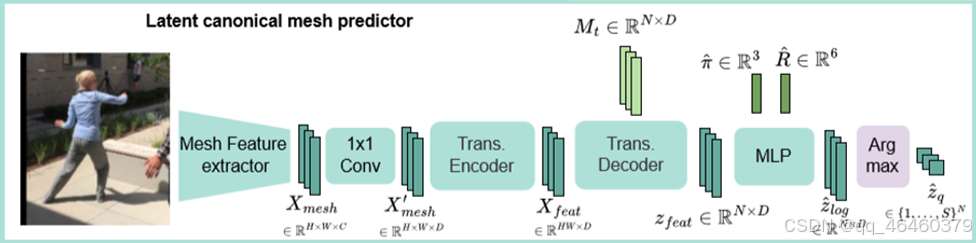
潜在规范网格预测器 (Latent canonical mesh predictor)
这一部分负责预测人体网格的离散潜在表示,这是将人体姿态和形状估计问题转化为分类任务的关键步骤。
- Transformer 编码器 (Trans. Encoder)
- 输入:图像特征或网格特征,这些特征包含了有助于预测人体姿态和形状的视觉信息。
- 输出:编码后的特征表示 zfeat∈RN×D,其中 N 是特征的维度,D 是特征向量的维度。
- 功能:Transfrmer 编码器处理输入特征,提取关键信息,并将其转换成适合后续处理的形式。
- 多层感知器 (MLP)
- 输入:来自 Transfrmer 编码器的特征 zfeat。
- 输出:处理后的特征,通常用于进一步的预测任务。
- 功能:MLP 对 Transfrmer 编码器的输出进行非线性变换,以提取更深层次的特征表示,为预测任务提供更丰富的信息。
- 输入特征
- Xfeat∈RHW×D: 这是从图像中提取的特征,其中 HW 表示特征的宽度乘以高度, D 是特征的维度。
- Transformer 解码器
- Mt∈RN×D: Transformer 解码器使用的网格标记,用于预测人体网格的离散潜在表示。
- 输出: zfeat∈RN×D,表示解码器处理后的特征。
- 多层感知器 (MLP)
- 功能:对 Transformer 解码器的输出进行进一步的非线性变换,以提取更深层次的特征表示。
- 向量量化 (Vector Quantization)
- z^q∈{1,…,S}N: 向量量化后的潜在表示,其中 S 是码本大小,N 是潜在向量的维度。每个元素是码本中最接近的向量的索引。
- 相机和旋转参数
- π^∈R3: 预测的相机参数,可能包括相机的位置、视角等信息。
- R^∈R6: 预测的旋转参数,表示人体相对于相机的旋转。
- Argmax 操作
- 功能:在向量量化过程中,用于选择与连续潜在表示最接近的离散潜在表示。
2 相关工作
2.1 参数化方法
2.2 非参数化方法
2.3 人体姿态和形状的量化
3 背景
3.1 SMPL模型
3.2 全卷积网格自动编码器
3.3 向量量化变分自动编码器
全卷积网格自动编码器
全卷积网格自动编码器是专门为处理3D网格数据设计的自动编码器。它的关键特性包括:
- 全局共享权重和局部变化系数的卷积算子:
- 这种设计允许模型在保持权重共享的同时,能够适应不同网格结构的局部变化。这对于处理不规则网格连接的复杂细节至关重要。
- 局部化的潜在代码:
- 全卷积架构的一个主要优点是其潜在表示是局部化的,这意味着潜在空间能够保留网格的空间结构。这种特性对于后续的网格重建和处理非常重要。
- 潜在表示的形式:
- 潜在表示位于 RN×L,其中 N 是潜在向量的个数,L 是潜在向量的维度。这种表示形式使得模型能够有效地编码和解码复杂的3D网格数据。
矢量量化变分自编码器 (VQ-VAE)
VQ-VAE 是一种具有离散化潜在空间的编码器-解码器模型,其工作原理如下:
- 联合学习编码器、潜在码字典和解码器:
- 模型不仅学习如何编码输入数据 x 到潜在变量z∈RN×L,还学习一个潜在码的字典,用于离散化这些潜在变量。
- 离散化过程:
- 潜在变量 z 通过与码本中的潜在代码进行最近邻匹配来离散化,生成离散的潜在表示 zd∈RN×L 或 zq∈{1,…,S}N。这种离散化是 VQ-VAE 的核心特性,它使得模型能够以一种更紧凑和离散的方式表示数据。
- 重建过程:
- 解码器使用离散的潜在表示和码本信息来重建输入数据 x。这种重建过程不仅要求模型能够准确地捕捉数据的关键特征,还要求它能够在离散的潜在空间中有效地操作。
4 方法
4.1 提出的HPSE方法
4.2 训练VQ-HPS
“在VQ-HPS训练过程中,我们使用了预训练和冻结的Mesh-VQ-VAE模型” 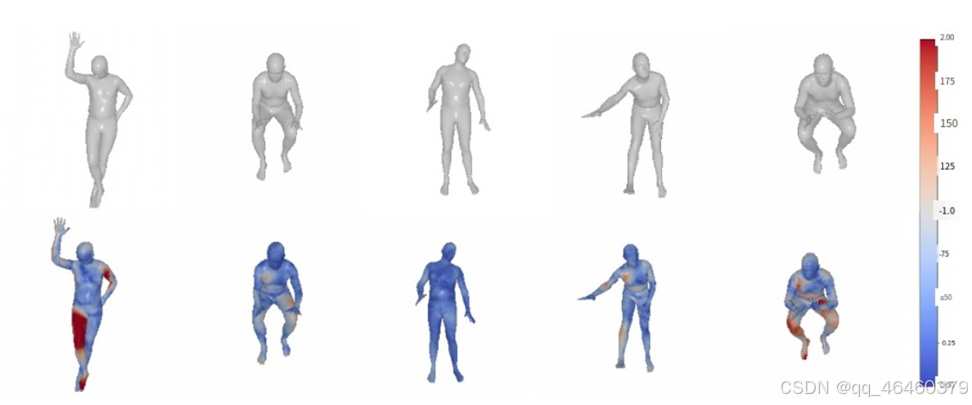
Mesh-VQ-VAE在AMASS数据集上进行训练,并在3DPW[30]训练集上进行微调。为了简化具有有限索引的网格离散表示的学习,我们使用非定向网格转换为原点(规范网格)来训练Mesh-VQ-VAE。 最终重建误差为4.7 mm。这个重构误差是一个重要的参数,因为它对应于我们可以得到的最小的每顶点误差。3DPW定性重建结果如图3所示。” 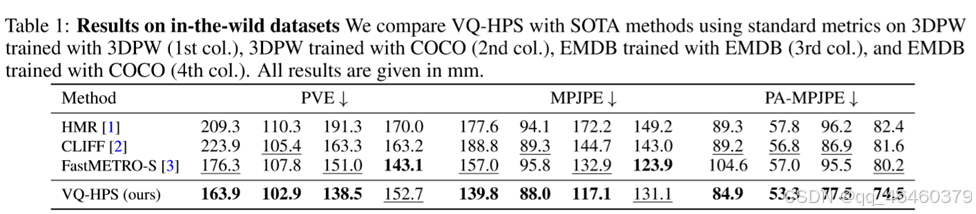
5 结果
5.1 数据集
AMASS。Mesh-VQ-VAE在SMPL[9]格式的大型人体运动数据库AMASS上进行训练。它包含超过11000个动作和300个受试者,这使得它能够代表各种各样的身体姿势和形状。
3DPW。这个数据集由60个野外RGB视频组成,具有人体的3D地面真相。我们使用预定义的分割进行训练、 验证和测试。请注意,当在混合数据集上进行训练时,我们不会在3DPW上微调模型来评估泛化。 我们还在3DPW- occ上评估了VQ-HPS, 3DPW- occ是中提出的一个基准,包含有遮挡的3DPW视频。
EMDB。EMDB包含81个室内和室外视频,具有地面真实SMPL体。我们使用EMDB1,它由17个最具挑战性的序列组成,用于测试,并在数据集的其余部分([31]中称为EMDB2)上进行训练。
COCO。COCO是一个用2D关键点标注的图像数据集。为了训练人类网格预测器,我们遵循[2,33]并使用伪地 面真实网格。我们使用与[2]相同的注释,使用28k的图像。
5.2 指标
5.3 有限数据上的训练
5.4 大规模数据集上的训练
5.5 消融研究
6 结论
补充材料
A 实现细节
B 额外的定性结果
C 训练过程中的预测可视化
D 误差分析
E 失败案例
F 估计身体形状
G 可视化Mesh-VQ-VAE
研究方法
该篇文章的研究目的
本研究旨在提出一种新的人体姿态和形状估计(HPSE)方法,该方法通过使用低维离散潜在表示,将HPSE问题转化为分类任务,以提高估计的准确性和逼真度。研究的主要目的是解决现有参数化和非参数化方法在处理有限训练数据时的局限性,并利用神经网络的区分能力来预测更准确的人体姿态和形状。
2.该篇文章的研究方法
研究中提出了VQ-HPS模型,该模型基于向量量化变分自动编码器(VQ-VAE)框架,使用全卷积网格自动编码器来编码人体网格到一个低维离散潜在空间。VQ-HPS通过预测这个离散潜在表示,然后使用预训练的Mesh-VQ-VAE解码器来重建人体网格。此外,研究还采用了Transformer-based的编码器-解码器架构来处理图像特征,并预测人体的3D姿态和形状。
3该篇文章的研究内容
文章详细介绍了VQ-HPS模型的架构和训练过程,包括Mesh-VQ-VAE的构建、特征提取器的设计、旋转和相机参数的预测、以及最终的网格重建。此外,还探讨了在不同数据集上训练模型的性能,包括在有限数据和大规模数据集上的表现,并与其他现有方法进行了比较。
4该篇文章的最大创新点
文章的最大创新点在于将HPSE问题框架为一个分类任务,并通过预测离散潜在表示来解决。这种方法不仅在训练数据有限的情况下能够产生逼真的人体姿态和形状估计,而且还能有效利用大规模人体运动捕捉数据库进行预训练,从而减少对标注数据的依赖。此外,VQ-HPS模型在处理非典型姿态和形状时也显示出了较好的鲁棒性。
5该篇文章给我们的启发
这篇文章给我们的启发是,通过将复杂的回归问题转化为分类问题,可以有效地利用深度学习模型的区分能力来提高预测的准确性。此外,预训练和迁移学习策略可以显著提高模型在有限数据情况下的性能,这对于数据获取成本高或数据稀缺的应用场景尤其有价值。最后,研究还表明,通过创新的网络架构设计,可以更好地捕捉和利用人体姿态和形状的内在结构信息。
结果
- 图 1: VQ-HPS 将人体姿态和形状估计问题表述为向量量化潜在空间中的分类任务。我们在具有野外条件和照明不足的两个挑战性场景中展示了 VQ-HPS 的结果,并将其性能与少量数据训练时的 HMR、CLIFF 和 FastMETRO-S 进行了比较。
- 图 2: 给定图像预测网格的 VQ-HPS 全局过程。我们首先预测相机 ˆπ 和旋转 ˆR。然后,我们使用图像、预测的旋转和相机来预测规范网格的顶点 ˆVc。最后,根据 ˆR 旋转 ˆVc 以获得最终网格顶点 ˆV。
- 图 3: Mesh-VQ-VAE 重建误差。在 3DPW 测试集上的重建样本。误差以厘米为单位,对应于重建网格和相应顶点之间的欧几里得距离。
- 图 4: 定性结果 我们比较了在 3DPW 训练 3DPW(前三行)和 EMDB 训练 EMDB 时,我们的方法与 HMR、CLIFF 和 FastMETRO-S 的性能。
- 图 5: 消融研究。“3D 损失”消融的效果。我们可以看到,用 PVE 损失替换交叉熵会产生不自然的体态,这显示了基于分类的方法的优势。
- 图 6: 估计身体形状。我们在没有微调和微调后在 SSP-3D 上定性评估 VQ-HPS。
- 图 7: 在潜在空间交换身体部位。我们在潜在空间中交换两个网格的身体部位后手动识别负责每个身体部位的索引。色图显示了 M1 和重建之间的距离。
- 图 8: 在潜在空间交换躯干。我们在潜在空间中交换两个网格的躯干。
- 图 9: 在 Mesh-VQ-VAE 的潜在空间中进行插值。注意潜在空间包含了姿态和形状。
表例
- 表 1: 我们在 3DPW(第一列)、3DPW 训练 COCO(第二列)、EMDB 训练 EMDB(第三列)和 EMDB 训练 COCO(第四列)上使用标准指标比较 VQ-HPS 与 SOTA 方法的结果。所有结果均以毫米为单位。
- 表 2: 我们在不进行 3DPW 微调的情况下,将 VQ-HPS 与使用相同背景和相同数据集训练的 SOTA 模型在 3DPW 和 EMDB 上的标准指标进行比较。左侧部分的方法使用 ResNet-50 背景。右侧部分的模型使用 HRNet 背景,除了 TokenHMR 使用 ViT 背景和额外数据。所有结果均以毫米为单位。
- 表 3: 我们在 3DPW 数据集上对 VQ-HPS 架构和训练过程进行了几项消融研究。所有结果均以毫米为单位。
讨论
“估计体型”
“我们比较了在Bedlam上对VQ-HPS进行微调前后在SSP-3D (具有挑战性体型的真实图像数据集)上获得的结果。这一明显的改进表明,如果在适当的数据上进行训练, VQ-HPS可以用于体型估计。”
结论
从2D图像中恢复出3D的人体姿态和形状
创新点
局限性
Questions:
1. 为什么要研究这个问题?
- 人体姿态和形状估计(HPSE)是计算机视觉领域的基础任务,对于动画、体育分析等多个领域具有重要意义。
- 从单目RGB图像中准确估计3D人体姿态和形状是一个挑战,因为这是一个欠定问题。
- 现有的方法在处理有限训练数据时存在局限性,尤其是在捕获详细人体形状和姿态方面。
2. 学者们做了哪些研究来解决此问题?
- 参数化方法:使用低维统计人体模型,通过预测少量参数来重建3D人体网格。
- 非参数化方法:直接回归3D坐标,通过图卷积网络或Transformer模型预测人体网格的顶点。
- 混合方法:结合局部和全局特征,使用图卷积网络和Transformer的混合架构。
3. 这些解决方法还有什么不足?
- 参数化方法难以捕获详细的人体形状,且倾向于平均形状。
- 非参数化方法在训练数据有限时,输出的网格可能不平滑,且对训练和测试数据分布变化敏感。
- 现有方法在预测极端姿态时可能不准确。
4. 论文提出了什么解决方法?
- 提出了VQ-HPS模型,通过预测离散潜在表示来解决HPSE问题,并将问题转化为分类任务。
- 使用Mesh-VQ-VAE架构来提供3D网格的离散潜在表示。
- 利用Transformer-based的编码器-解码器模型来学习解决HPSE分类问题。
5. 论文的框架结构?
- 引言:介绍HPSE的重要性和现有方法的局限性。
- 相关工作:回顾参数化和非参数化方法。
- 方法:详细介绍VQ-HPS模型和Mesh-VQ-VAE架构。
- 实验:展示在不同数据集上的训练和测试结果。
- 结论:总结研究成果和潜在的应用。
二.研究方法
6. 论文采用了什么方法来达到自己的研究目的?
- 使用全卷积网格自动编码器来编码和解码人体网格。
- 采用向量量化技术来离散化潜在空间。
- 利用Transformer模型来预测离散潜在表示。
三.重要结论
7. 论文的核心结论是什么?
- VQ-HPS在有限训练数据的情况下,能够实现与参数化方法相媲美的逼真度,同时超越了现有的非参数化方法。
- VQ-HPS在大规模数据集上也显示出了优秀的性能。
8. 论文的创新点是什么?
- 将HPSE问题转化为分类任务,利用神经网络的分类能力。
- 提出了Mesh-VQ-VAE架构来学习3D网格的离散潜在表示。
- 证明了在少量训练数据下,分类方法的有效性和优越性。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









