







一、两者区别
- Segmentation:常被认为是硬分割(Hard Segmentation),就是将图片中的像素分成多个类别,如果是前背景分割,那么就是分成两个类别,一个类别代表前景,一个类别代表背景。而分割的二值性(即0和1)导致前景边界周围出现严格边界,留下可见的不好效果,解决了部分透明度和前景问题,对第二帧的合成更有利,分割属于分类任务。
- Matting:也是一类前背景分割问题,但是matting不是硬分割,而是软分割(Soft Segmentation),像玻璃、头发这类前景,对应像素点的颜色不只是由前景本身的颜色决定,而是前背景颜色融合的结果,matting问题的目标就是,找出前背景颜色,以及它们之间的融合程度,以便于将前景合并到新的背景上,matting属于回归任务。
形象地来说,就像这样,就前景和背景的二分类来说,Segmentation的值只会是0和1,但是Matting的alpha值则是介于[0,1]之间,嗯,Matting就是为了求前景和背景的透明的alpha:
Matting GT

Segmentation GT
二、Matting模型调研
目前流行的抠图算法大致可以分为两类,一种是需要先验信息的Trimap-based的方法,宽泛的先验信息包括Trimap、粗糙mask、无人的背景图像、Pose信息等,网络使用先验信息与图片信息共同预测alpha;另一种则是Trimap-free的方法,仅根据图片信息预测alpha,对实际应用更友好,但效果普遍不如Trimap-based的方法。
Trimap-based matting: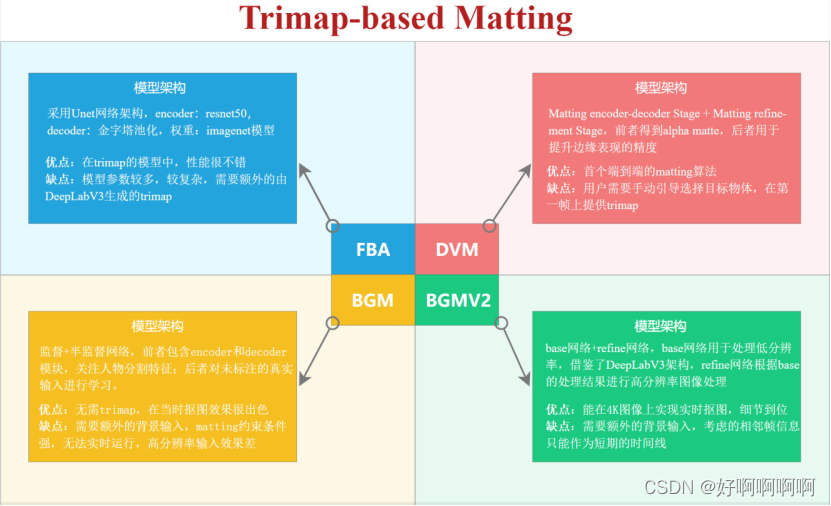
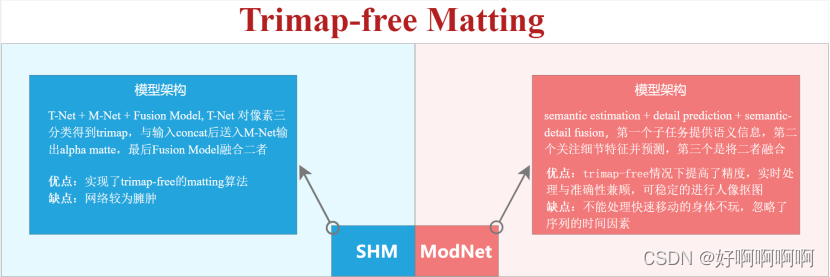
Trimap-free matting:
三、Segmentation模型调研
Segmentation研究的三个方向及经典算法
目前,CV 学术界在视频物体分割方面的研究主要分为三个方向:
-
半监督视频物体分割 (Semi-supervised video object segmentation)
半监督视频物体分割,又称为单一样本视频物体分割 (one-shot video object segmentation, 简称 (OSVOS)。在半监督视频物体分割中,给定用户感兴趣物体在视频第一帧图片上的分割区域,算法来获取在后续帧上的物体分割区域。物体可以是一个,也可以是多个。在视频中,存在物体和背景运动变化、光照变化、物体旋转变化、遮挡等,因此半监督视频物体分割算法研究的重点是算法如何自适应获取变化的物体表观信息。
目前半监督视频物体分割算法分为两大类:有在线学习、无在线学习。
在线学习的经典算法:Lucid data dreaming,OSVOS,PreMVOS 等。
优点:针对每个物体单独训练,因而分割正确率高
缺点:是深度学习的fine-tuning,需要耗费大量计算时间
无在线学习的经典算法:Lucid data dreaming,OSVOS,PreMVOS 等。
优点:事先训练好,不需要针对样本进行fine-tuning,具有更好的时效性。
半监督算法的缺点:需要第一帧物体区域的ground-truth,无法直接应用于实际应用。
-
交互式视频物体分割 (Interactive video object segmentation)
交互式视频物体分割是从2018开始兴起的、更贴近实用的视频物体分割方法。在交互式视频物体分割中,输入不是第一帧物体的 ground-truth,而是视频任意一帧中物体的用户交互信息。交互信息可以是物体 bounding box、物体区域的划线(scribble)、外边缘的极值点等。
交互式分割的优点:屏蔽了半监督的缺点,只需要用户的简单交互,非常容易达到;可通过多次交互纠正,达到非常搞得发那个正确率,提高更好的用户体验,满足用户需求。
交互式分割的缺点:不能满足部分市场需求,需要用户动手提供交互,而并非喜闻乐见的end-to-end方法。
-
无监督视频物体分割(Un-supervised video object segmentation)
无监督视频物体分割是全自动的视频物体,除了 RGB 视频,没有其他任何输入。其目的是分割出视频中显著性的物体区域。在上述三个方向中,无监督视频物体分割是较新的研究方向。
无监督的经典算法:
Mask Track R-CNN:图像实例分割算法Mask R-CNN进行实例特征的提取+外部memory模型存储多帧实例特征
Maskprop:在Mask Track R-CNN基础上增加Mask propagation模块提升分割mask的生成和关联的质量(即对当前帧进行周围传播),方法较为复杂,速度慢
Stem-seg:实例的区分+类被的预测,两个模块组成,前者通过像素的的embedding特征进行聚类实现不同物体的分割,后者提供像素类别预测信息。
上述三者的缺点:本质为单帧提取和多帧关联,处理速度慢且不利于发挥视频的时序连续性。
DeepLabV3:Deeplab网络是一个专门用来处理语义分割的模型,该系列一共有三篇文章,分别对应Deeplabv1, Deeplabv2和Deeplabv3。因为之前的语义分割网络存在池化导致丢失了信息,并且没有利用标签之间的概率关系,所以Deeplab系列使用空洞卷积来避免池化带来的信息损失,为解决多尺度物体问题给出四种方案。它使用空洞卷积来提取密集特征图并捕获远程上下文,提出了multi-grid,改进了级联网络的性能,改进了ASPP模块
优点:模型泛化能力强,能够得到更精细的结果
缺点:模型较为复杂,多次下采样带来的边界效果不理想,忽略了浅层特征
VisTR:模型的融合,将实例的检测、分割和跟踪统一到一个框架下实现,更好的挖掘视频整体的空间和时序信息,速度较快。算法思想:借助NLP任务的思想,将序列级别的视频建模成一个Seq2Seq的任务;视频的实例分割=实例分割+目标跟踪,但本质都是像素特征之间相似度的学习,因为可进行统一;采用NLP中的transformer模型适合对长序列建模,其中的自注意力模块可根据两两之间的相似度来及逆行特征得学习和更新。模型核心实现:CNN进行初始图像特得提取,将多帧的特征结合作为特征序列输入transformer进行建模,实现序列的输入和输出。
优点:创造性的引用了NLP中的transformer,且显示出了替代CNN的能力;直接进行端到端的并行序列解码问题,表现SOTA,性能非常高。
参考链接:
(17 封私信 / 80 条消息) 目前抠图(Image Matting)的主流算法有哪些? - 知乎 (zhihu.com)
转载请注明出处,阿里嘎多。

















 7522
7522

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









