






摘要
Mamba 是一种具有类似 RNN 的状态空间模型令牌混合器 (SSM) 的架构,最近被引入以解决注意力机制的二次复杂度,随后应用于视觉任务。然而,与卷积和基于注意力的模型相比,Mamba 在视觉方面的性能往往不足。在本文中,我们深入研究了 Mamba 的本质,在概念上得出结论,Mamba 非常适合具有长序列和自回归特征的任务。对于视觉任务,由于图像分类与任一特征不一致,我们假设 Mamba 对这项任务不是必需的;检测和分割任务也不是自回归的,但它们坚持长序列特征,因此我们认为探索 Mamba 对这些任务的潜力仍然是值得的。为了实证验证我们的假设,我们通过在移除核心令牌混合器 SSM 的同时堆叠 Mamba 块来构建一系列名为 MambaOut 的模型。实验结果有力地支持了我们的假设。具体来说,我们的 MambaOut 模型在 ImageNet 图像分类上超过了所有视觉 Mamba 模型,这表明该任务确实没有必要 Mamba。至于检测和分割,MambaOut 无法与最先进的视觉 Mamba 模型的性能相匹配,展示了 Mamba 对长序列视觉任务的潜力。
一、Introduce
Transformer:
- Transformer已经成为各种任务的主流骨干,支持BERT、GPT系列和ViT等众多突出模型。
- Transformer 的令牌混合器注意力在序列长度方面产生了二次复杂度,这对长序列提出了重大挑战。
- 为了解决这个问题,引入了各种具有线性复杂度的令牌混合器,如动态卷积、Linformer、Longformer、Big Bird和Performer。
类RNN:
- 最近,出现了一种新的类似 RNN 的模型浪潮,因其可并行化训练和对长序列执行有效推理的能力而引起了社区的极大兴趣。
- 值得注意的是,RWKV和 Mamba等模型被证明对大型语言模型 (LLM) 的主干有效。
Mamba:
- 受类似 RNN 的模型有希望的能力的启发,各种研究工作试图将 Mamba引入视觉识别任务中,例如 Vision Mamba、VMamba、LocalMamba和 PlainMamba等的开创性工作。
- Mamba 的令牌混合器是结构化状态空间模型 (SSM) 。
- 然而,与最先进的卷积和基于注意力的模型相比,基于SSM的视觉模型导致性能不足。这就产生了一个研究问题:我们真的是否需要 Mamba 进行视觉?
曼巴非常适合具有两个关键特征的任务:长序列和自回归
- 没有多少视觉任务同时具备这两个特征
- ImageNet上的图像分类不符合这两者,而COCO上的对象检测与实例分割和ADE20K上的语义分割只符合长序列
- 自回归特征要求每个令牌只从之前和当前令牌中聚合信息,这一概念被称为令牌混合的因果模式(见下图(a))。事实上,所有的视觉识别任务都属于理解领域,而不是生成领域,这意味着模型可以一次看到整个图像(完全可见模式)。因此,在视觉识别模型中对标记混合施加额外的因果约束可能会导致性能下降(参见下图(b))。虽然这个问题可以通过双向分支来缓解,但不可避免的是,这个问题在每个分支中都存在。
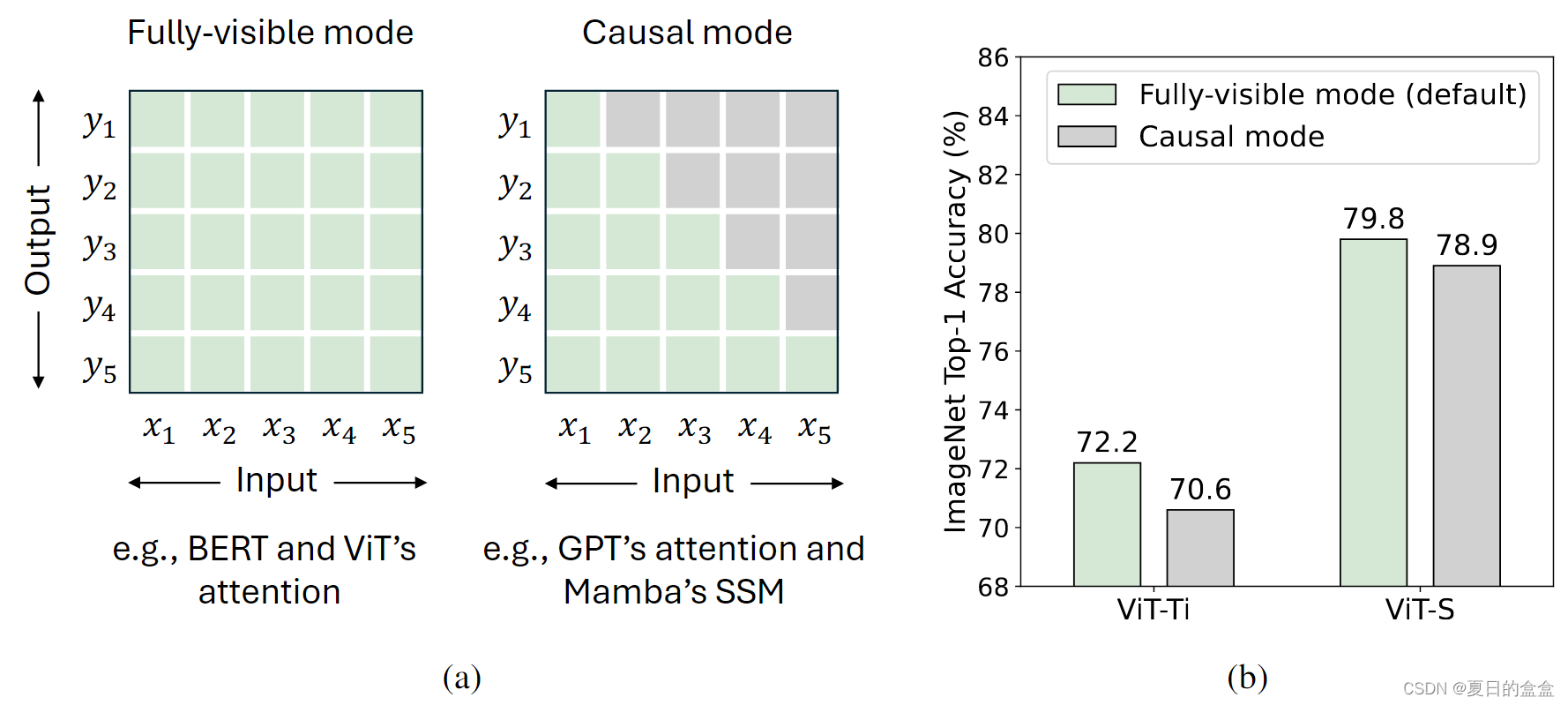
其中:
- (a)两种令牌混合模式。对于总共 T 个标记,完全可见模式允许标记 t 聚合来自所有标记的输入,即
,以计算其输出
。相比之下,因果模式将令牌 t 限制为仅聚合来自先前令牌和当前令牌
的输入。默认情况下,注意力以完全可见的方式运行,但可以通过因果注意掩码调整为因果模式。RNN 类模型,例如 Mamba 的 SSM,由于其循环性质,固有地以因果模式运行。
- (b) 我们从完全可见模式修改为因果模式来修改 ViT 的注意力,并观察到 ImageNet 的性能下降,这表明理解任务不需要因果混合。
文中提出两个假设:
- 假设1:SSM对于图像分类是不必要的,因为该任务既不符合长序列特征,也不符合自回归特征。
- 假设2:SSM可能对对象检测和实例分割以及语义分割有潜在的好处,因为它们遵循长序列特征,尽管它们不是自回归的。
二、概念讨论
2.1Mamba 适合哪些任务
令牌混频器是选择性SSM,它定义了四个与输入相关的参数(∆,A, B, C),并将它们转换为():
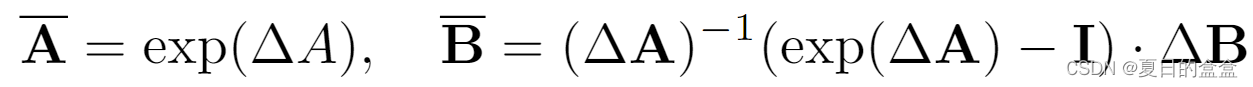
SSM的序列到序列变换可以表示为:
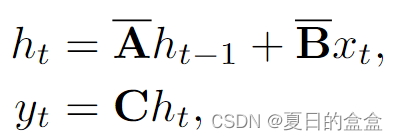
其中:
- t表示时间步长,
表示输入,
表示隐藏状态,
类rnn的SSM与因果注意区别:
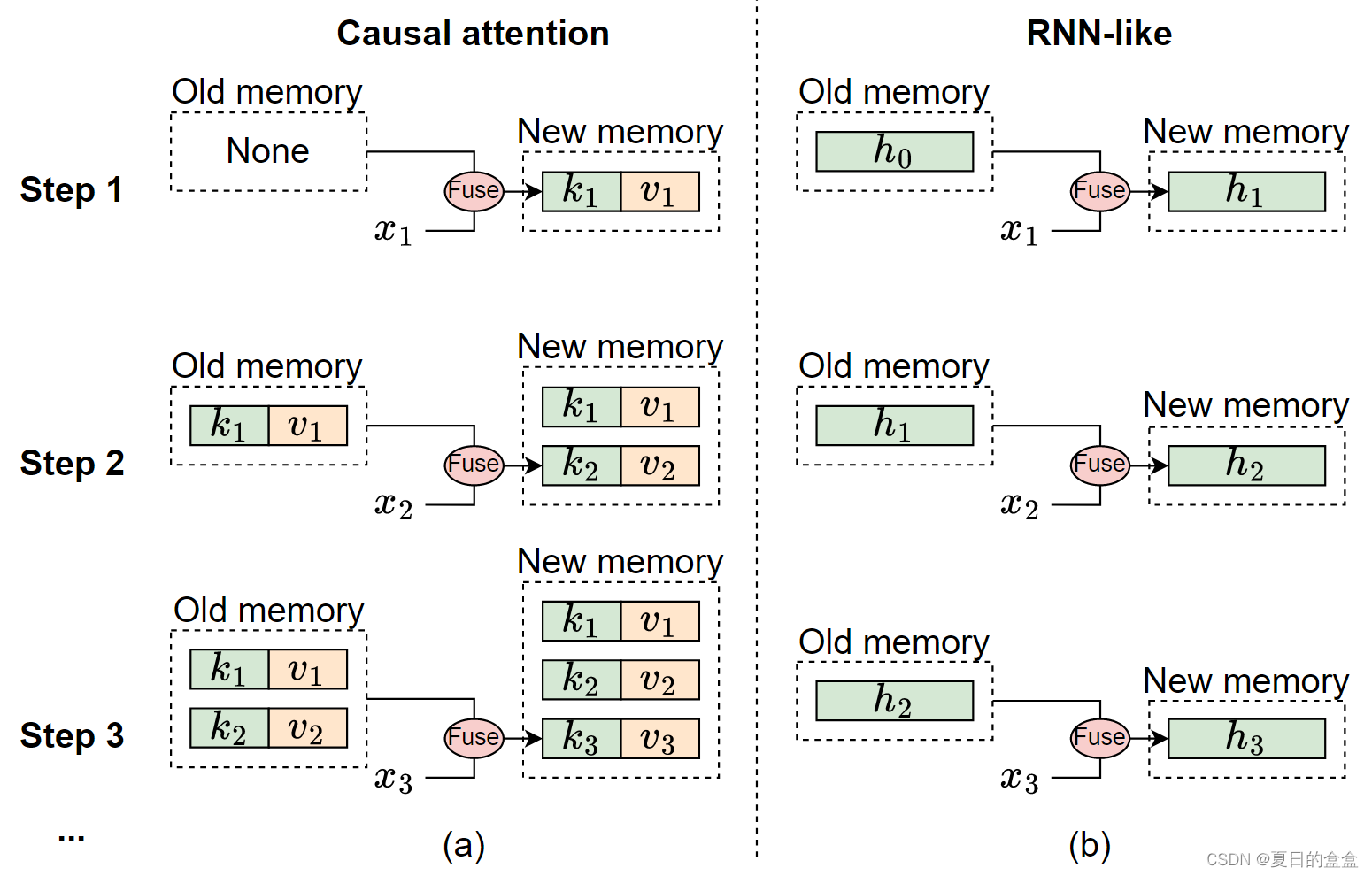
- (a)因果注意将所有先前令牌的键k和值v存储为内存。通过不断添加当前令牌的键和值来更新内存,因此内存是无损的,但缺点是,随着序列的延长,集成旧内存和当前令牌的计算复杂性会增加。因此,注意力可以有效地处理短序列,但在处理较长的序列时可能会遇到困难。
- (b)相比之下,类rnn模型将之前的令牌压缩成固定大小的隐藏状态h,作为内存。这种固定的大小意味着RNN记忆本质上是有损的,它不能直接与注意模型的无损记忆容量竞争。尽管如此,类rnn模型在处理长序列方面可以显示出明显的优势,因为无论序列长度如何,将旧内存与当前输入合并的复杂性保持不变。
因为SSM的记忆本质上是有损的,所以它在逻辑上不符合注意力的无损记忆。因此,曼巴不能展示其优势,在处理短序列,一个领域的注意力表现良好与容易。然而,在涉及长序列的场景中,由于其二次复杂度,注意力将会动摇。在这种情况下,曼巴可以明显地突出其效率在合并内存与当前输入,从而管理长序列顺利。因此,曼巴是特别适合处理长序列。
Mamba的限制:只能从以前和当前的时间步访问信息,即为因果模式:
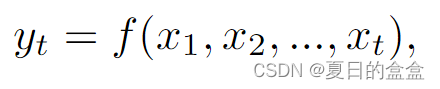
其中:
- 由于其因果性质,该模式非常适合自回归生成任务。
完全可见模式:每个令牌的输出取决于所有令牌的输入:
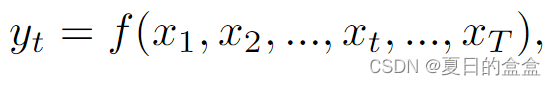
其中
- T表示令牌总数。
- 完全可见模式适合于理解任务,其中所有输入都可以被模型一次访问。
注意力在默认情况下是完全可见的模式,但它可以很容易地通过将因果掩码应用于注意力图转变为因果模式。由于其递归特性,类rnn模型本质上以因果模式运行,如曼巴公式(2)所示。由于这一固有特性,类rnn模型无法转换为全可见模式。尽管rnn可以使用双向分支近似于全可见模式,但每个分支仍然单独保持因果模式。因此,由于其循环属性的固有限制,Mamba非常适合需要因果token混合的任务。
曼巴非常适合显示以下特征的任务:
- 特征1:该任务涉及处理长序列。
- 特点2:任务需要因果令牌混合模式。
2.2视觉识别任务有很长的序列吗
考虑一个通用MLP比率为4的Transformer块;假设其输入令牌长度为L,通道(嵌入)维数为D,则该块的FLOPs可计算为:
![]()
由此,我们得到L中二次项与线性项的比值为:
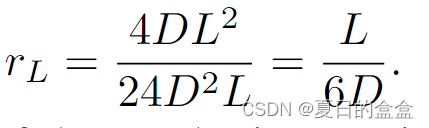
当L > 6D时,L中二次项的计算量超过线性项的计算量。这提供了一个简单的度量来确定任务是否涉及长序列。例如,ViT-S 中有384个通道时,阈值Tsmall = 6 × 384 = 2304, viti - b中有768个通道时,阈值Tbase = 6 × 768 = 4608。
对于ImageNet上的图像分类,典型的输入图像大小为,得到
= 196个令牌,patch大小为
。显然,196远远小于Tsmall和Tbase,这表明ImageNet上的图像分类不符合长序列任务的条件。
对于COCO上的对象检测和实例分割,其推理图像大小为800 × 1280,对于ADE20K上的语义分割,其推理图像大小为512 × 2048,假设patch大小为,令牌数量约为4K。由于4K > Tsmall且4K≈Tbase,因此对COCO的检测和对ADE20K的分割都可以看作是长序列任务。
2.3视觉识别任务是否需要因果令牌混合模式
如第 2.1 节所述,如下图(a)所示,完全可见的令牌混合模式允许不受限制的混合范围,而因果模式将当前令牌限制为仅访问来自先前令牌的信息。视觉识别被归类为理解任务,其中模型一次可以下看到整个图像,消除了对令牌混合的限制。对令牌混合施加额外的约束可能会降低模型性能。如图(b) 所示,当因果限制应用于 Vision Transformers (ViT)时,可以观察到性能的显着下降。一般来说,完全可见的模式适用于理解任务,而因果模式更适合自回归任务。这一主张也可以通过观察到 BERT和 ViT(BeiT和 MAE) 比 GPT-1/2和图像 GPT更多地用于理解任务来证实。因此,视觉识别任务不需要因果令牌混合模式。
2.4关于Mamba在视觉的必要性的假设
视觉识别任务引入 Mamba 的必要性的假设,如下所示:
- 假设 1:没有必要在 ImageNet 上引入 SSM 进行图像分类,因为此任务不满足特征 1 或特征 2。
- 假设 2:仍然值得进一步探索 SSM 在视觉检测和分割方面的潜力,因为这些任务与特征 1 一致,尽管不满足特征 2。
三、实验
省略
四、结论
在本文中,在概念上讨论了 Mamba 机制,并得出结论,它非常适合具有长序列和自回归特征的任务。我们根据这些标准分析常见的视觉任务,并认为为 ImageNet 图像分类引入 Mamba 是不必要的,因为它既不满足特征。然而,Mamba 在视觉检测和分割任务中的潜力,这与至少长序列特征一致,值得进一步探索。为了凭经验证实我们的主张,我们开发了 MambaOut 模型,该模型在没有核心令牌混合器 SSM 的情况下使用 Mamba 块。MambaOut 在 ImageNet 上超越了所有视觉 Mamba 模型,但与最先进的视觉 Mamba 模型相比,它表现出显着的性能差距,从而验证了我们的断言。由于计算资源的限制,本文只验证了视觉任务的 Mamba 概念。未来,我们可以进一步探索 Mamba 和 RNN 概念以及 RNN 和 Transformer 对大型语言模型 (LLM) 和大型多模态模型 (LMM) 的集成。















 297
297

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









