






参考来源:
汇总
MobileNetsV1特性:
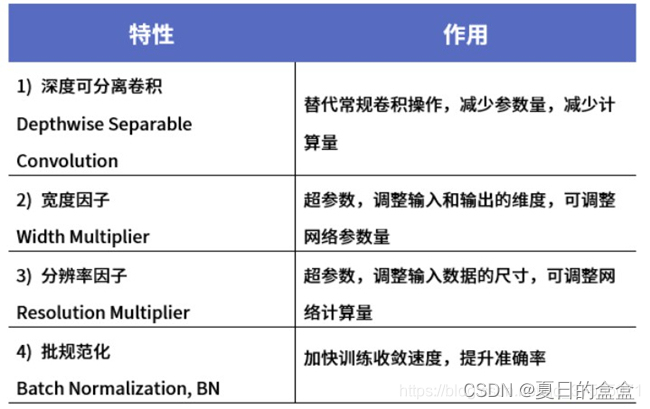
MobileNetsV2特性 :
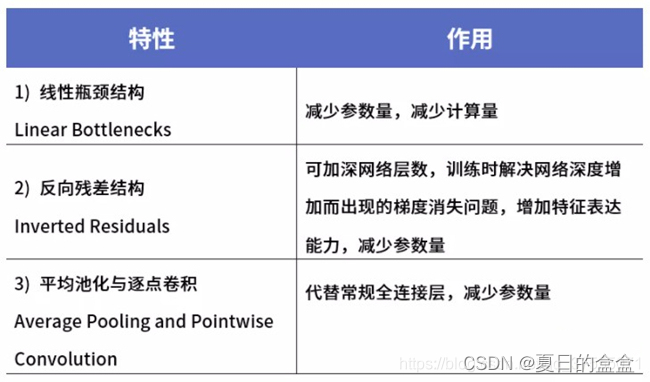
MobileNetsV3特性 :
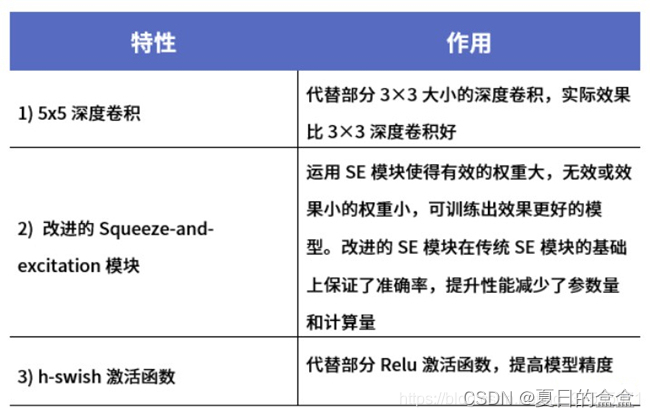
三者特性汇总:
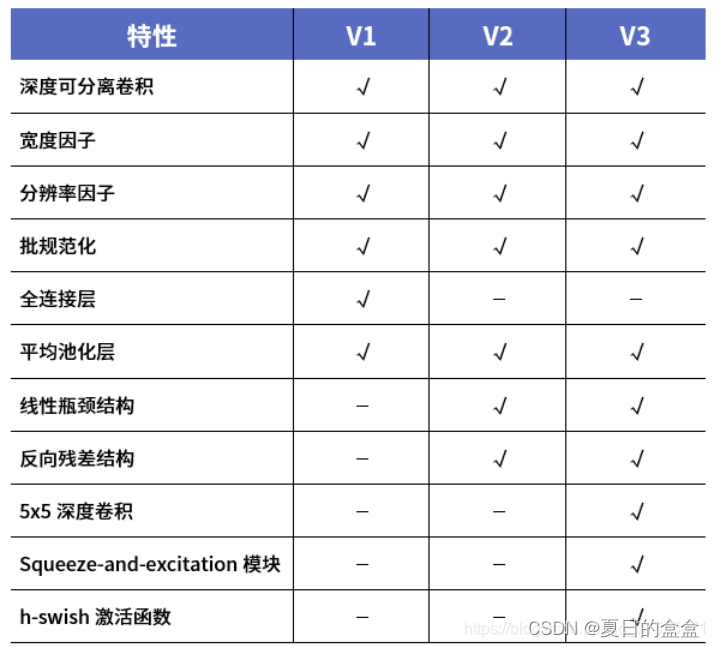
MobileNetsV1
MobileNet网络是由google团队在2017年提出的,专注于移动端或者嵌入式设备中的轻量级CNN网络。相比传统卷积神经网络,在准确率小幅降低的前提下大大减少模型参数与运算量。
主要贡献:
-
深度可分离卷积(Depthwise Separable Convolution):文章提出了使用深度可分离卷积作为构建轻量级CNN的核心。这种卷积将传统的卷积操作分解为深度卷积和点卷积两个步骤,大幅减少了计算量和模型大小。
-
全局超参数:引入了宽度乘数(width multiplier)和分辨率乘数(resolution multiplier)两个简单的全局超参数,允许模型构建者根据应用的资源限制(延迟、大小)灵活地选择合适大小的模型。
-
模型架构的简化:MobileNet的架构设计简化了网络结构,除了第一层使用全卷积外,其余层均采用深度可分离卷积,并通过批量归一化(batch normalization)和ReLU激活函数来提高效率。
拓展阅读:
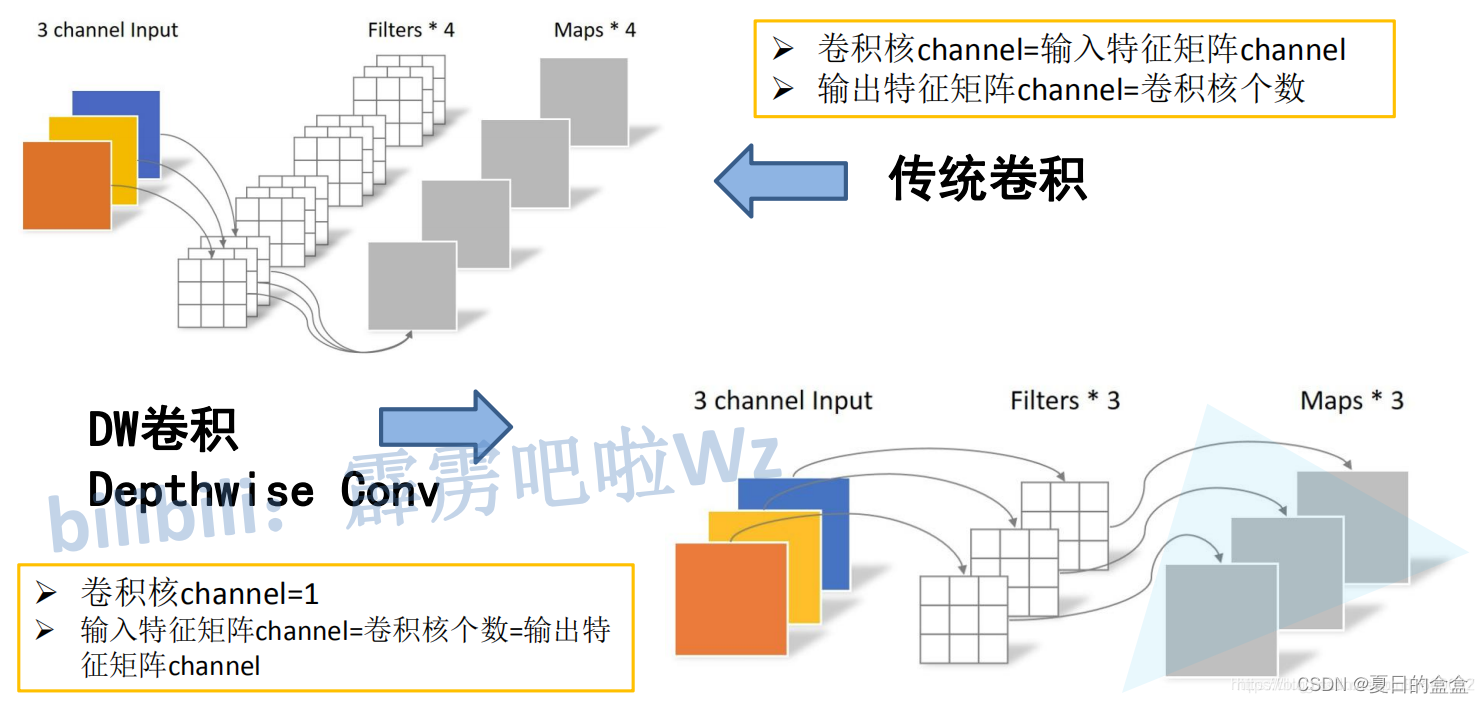
在传统卷积中,每个卷积核的channel与输入特征矩阵的channel相等(每个卷积核都会与输入特征矩阵的每一个维度进行卷积运算)。而在DW卷积中,每个卷积核的channel都是等于1的(每个卷积核只负责输入特征矩阵的一个channel,故卷积核的个数必须等于输入特征矩阵的channel数,从而使得输出特征矩阵的channel数也等于输入特征矩阵的channel数)
深度可分离卷积:
在DW卷积之后,可以看到输入特征通道和输出特征通道一样,如果要改变输出通道数,可以在DW之后加一个1x1卷积,通道控制1x1卷积核数量来控制输出通道数,DW+PW称为深度可分离卷积。
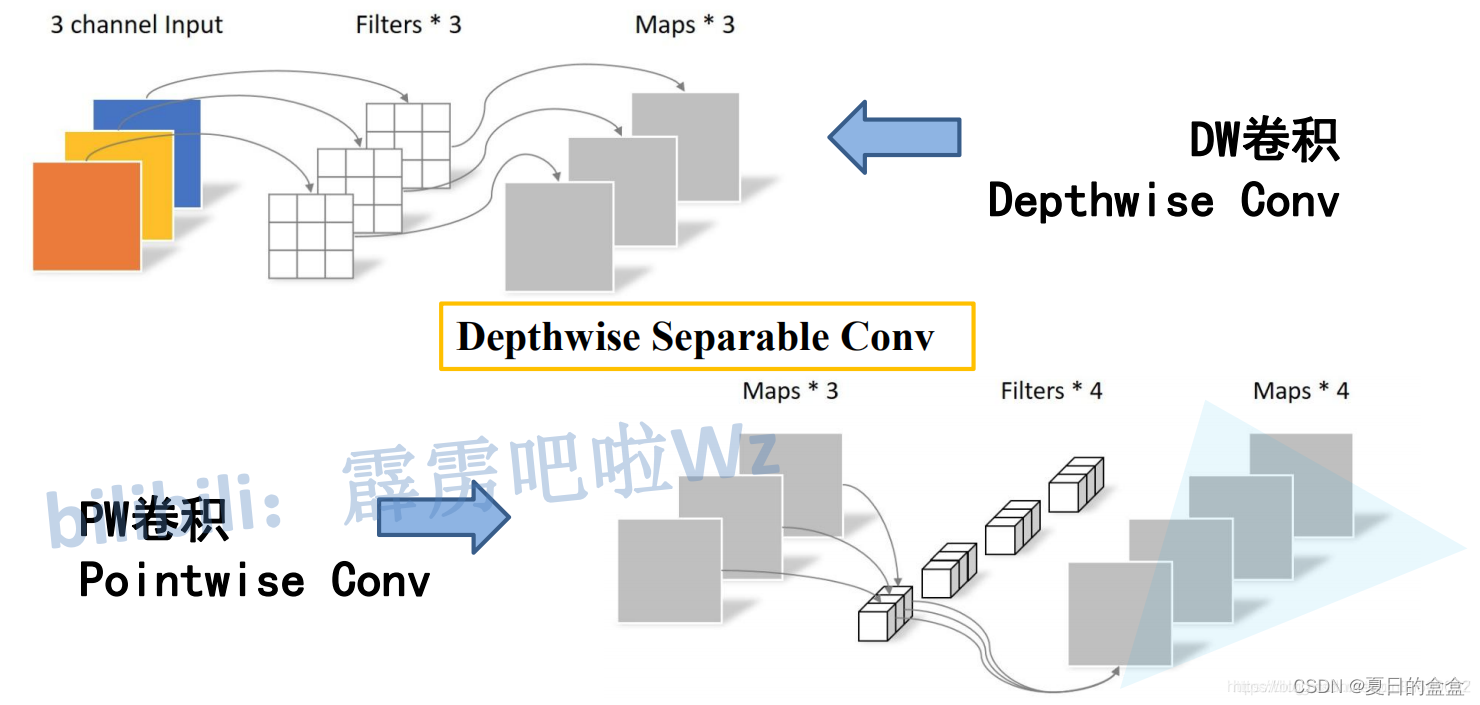
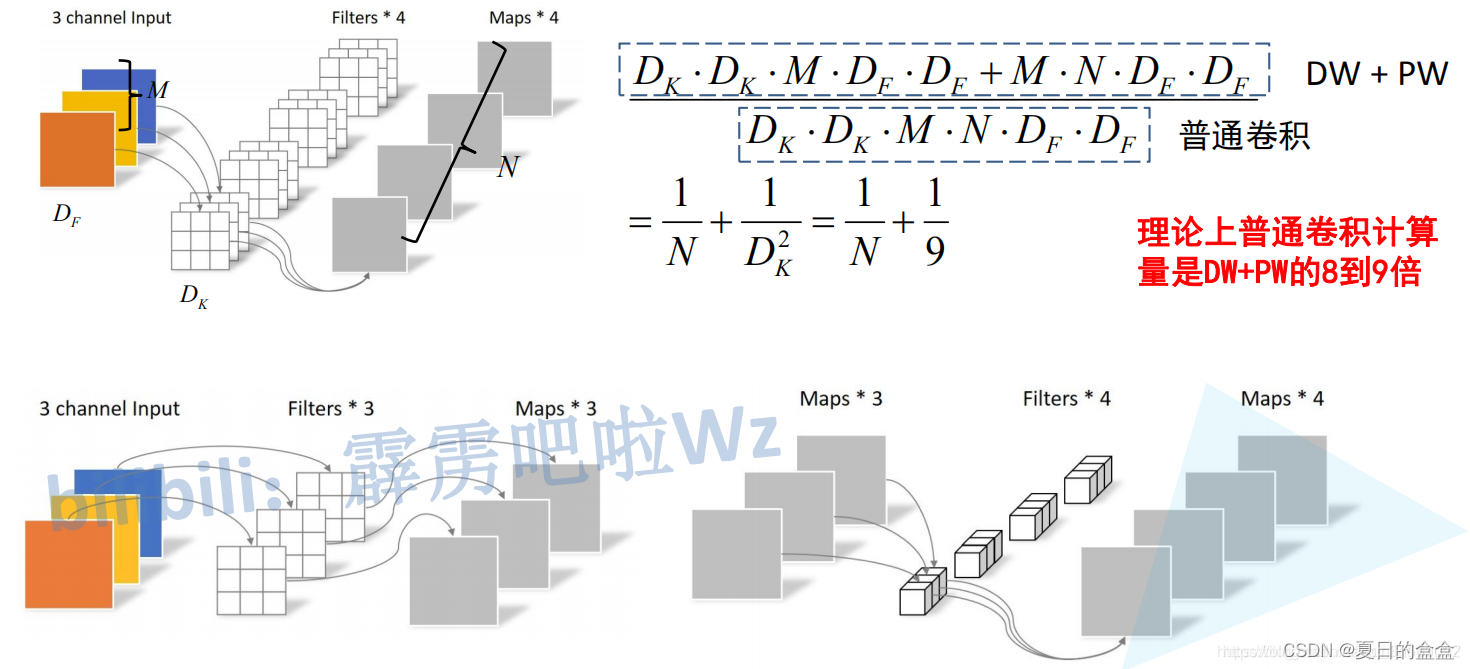
对比了传统卷积和深度可分离卷积这两个卷积方式的计算量,其中是输入特征矩阵的宽高(这里假设宽和高相等),
是卷积核的大小,M是输入特征矩阵的channel,N是输出特征矩阵的channel,卷积计算量近似等于卷积核的高 x 卷积核的宽 x 卷积核的channel x 输入特征矩阵的高 x 输入特征矩阵的宽(这里假设stride等于1),在我们mobilenet网络中DW卷积都是是使用3x3大小的卷积核。所以理论上普通卷积计算量是DW+PW卷积的8到9倍:
MobileNetsV2
MobileNet v2网络是由google团队在2018年提出的,相比MobileNet V1网络,准确率更高,模型更小。
主要贡献:
-
倒置残差结构(Inverted Residual and Linear Bottleneck):MobileNetV2引入了一种新的层结构,其中1x1的扩展卷积位于深度卷积之前,这与传统的残差网络结构相反。这种设计允许网络在保持计算效率的同时增加非线性。
-
线性瓶颈:在倒置残差结构中,输入和输出的维度较低,而中间层扩展到更高维度,这有助于减少计算量并保持特征的表达能力。
-
轻量级深度卷积:在倒置残差结构中使用轻量级的3x3深度卷积,作为非线性的来源,以提高特征的表达能力。
左侧是ResNet网络中的残差结构,右侧就是MobileNet v2中的到残差结构。在残差结构中是1x1卷积降维->3x3卷积->1x1卷积升维,在倒残差结构中正好相反,是1x1卷积升维->3x3DW卷积->1x1卷积降维。为什么要这样做,原文的解释是高维信息通过ReLU激活函数后丢失的信息更少(注意倒残差结构中基本使用的都是ReLU6激活函数,但是最后一个1x1的卷积层使用的是线性激活函数)。
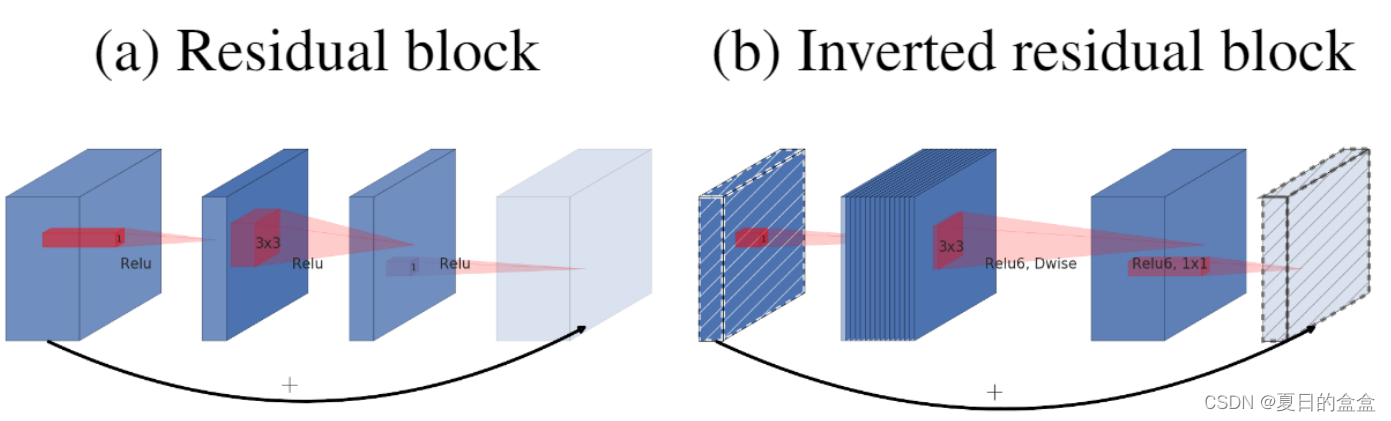
V1 V2卷积块对比:
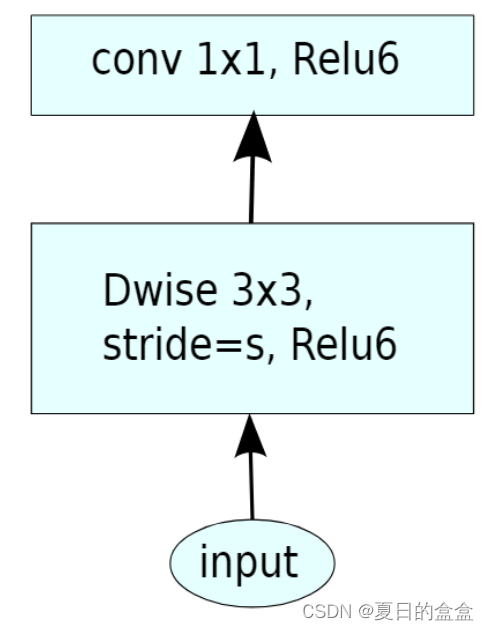
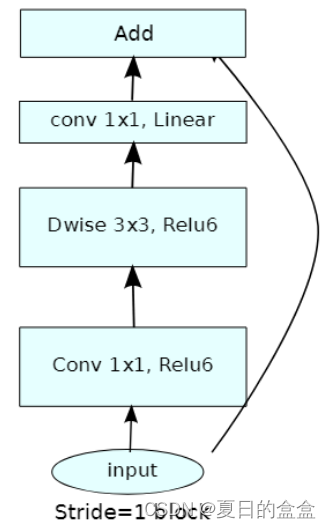
MobileNetsV3
MobileNetV3是Google团队开发的最新一代针对移动设备的高效卷积神经网络。
主要贡献:
-
硬件感知网络架构搜索(NAS):MobileNetV3利用NAS技术为移动电话CPU优化网络结构,这是通过结合NetAdapt算法实现的,以进一步改善模型性能。
-
NetAdapt算法:这是一种针对特定硬件平台优化网络层内滤波器数量的方法,与NAS技术互为补充。
-
新型激活函数h-swish:为了解决原始swish激活函数在移动设备上计算成本高的问题,MobileNetV3引入了h-swish,这是一种更快速且更适合量化的激活函数。
-
大压缩比的squeeze-and-excite模块:在MobileNetV3中,squeeze-and-excite模块的大小被固定为扩展层通道数的1/4,这有助于提高准确性,同时保持参数数量和延迟成本的适度增加。
-
轻量级分割解码器LR-ASPP:为语义分割任务提出的新模块,通过改进的全局平均池化和1x1卷积,提高了分割性能和效率
网络架构:
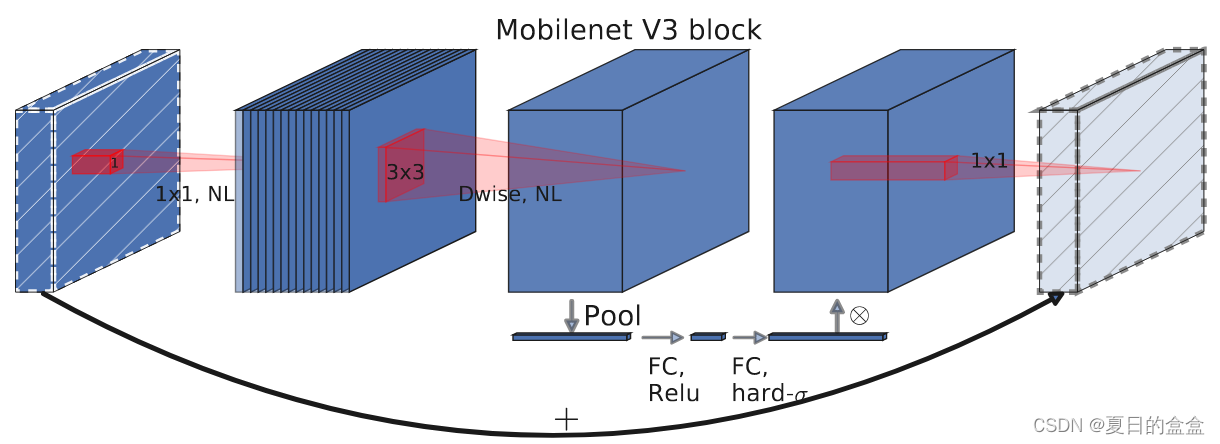
轻量级注意力:
即SE模块
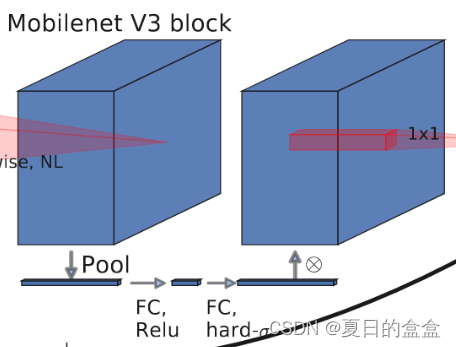
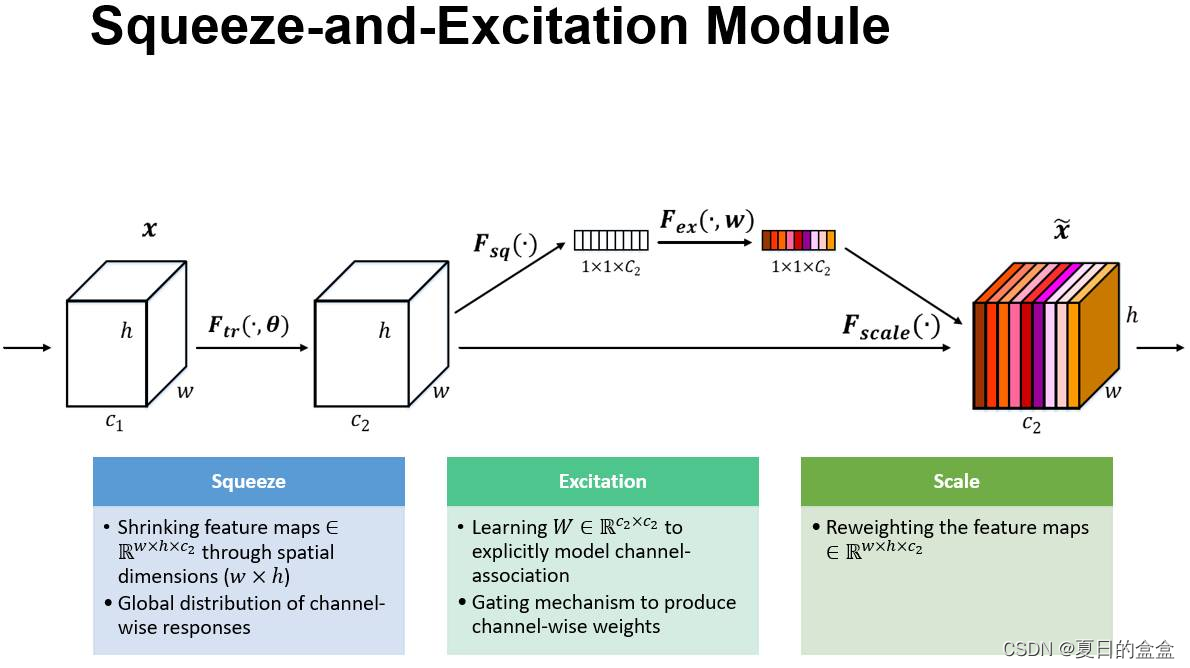
新型激活函数h-swish:
在结构中使用了h-swishj激活函数,代替swish函数,减少运算量,提高性能。

最后一个阶段:
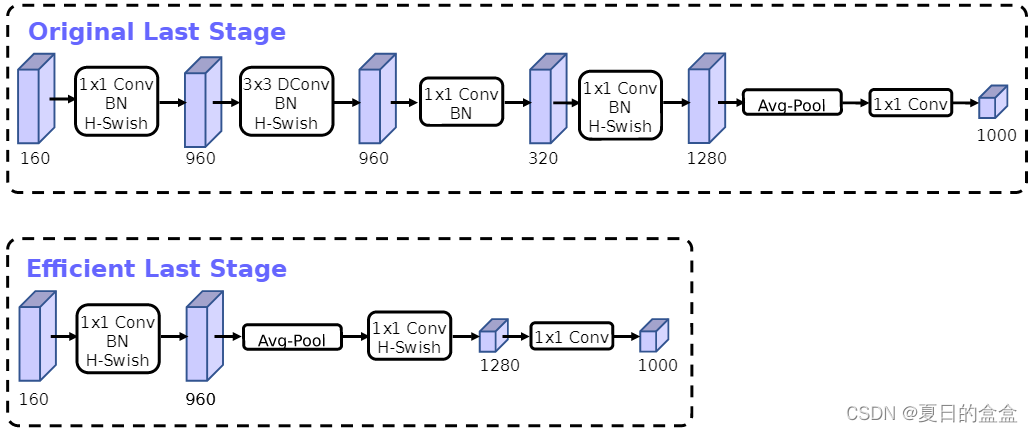
这种更有效的最后一个阶段能够在网络末尾删除三个昂贵的层,而不会损失准确性。
模型变体:
- MobileNetV3-Large:针对高资源使用场景优化。
- MobileNetV3-Small:针对低资源使用场景优化。

















 4773
4773

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









