






论文摘要
论文提出了一种名为**Masked Diffusion Transformer (MDT)**的新模型,旨在增强扩散概率模型(DPMs)在图像合成中的上下文推理能力。通过引入掩码潜在建模方案,MDT能够显著提升DPMs在图像中对象部分之间关系的学习能力,从而加速学习过程。实验结果表明,MDTv2(MDT的改进版本)在ImageNet数据集上达到了新的最优FID分数1.58,并且学习速度比之前的最优模型快超过10倍。
拟解决的问题
现有的扩散概率模型在学习图像中对象部分之间的关系时存在困难,导致学习过程缓慢。具体而言,传统的DPMs往往独立地学习每个语义部分,忽视了它们之间的关联性,从而影响了生成图像的质量和效率。
创新之处
- 掩码潜在建模方案:MDT通过在潜在空间中掩码某些图像标记,显著增强了上下文学习能力。
- 不对称扩散变换器结构:设计了一种不对称的扩散变换器,能够在掩码输入的情况下进行生成过程,提升了模型的学习效率。
- MDTv2的改进:在MDT的基础上,MDTv2引入了更高效的宏网络结构和训练策略,进一步加快了学习速度。
方法
4.1 MDT v1
MDT通过引入掩码潜在建模方案,增强了DPMs对图像中对象语义部分之间关系的学习能力。这种方案通过在训练过程中掩码(即隐藏)某些图像标记,迫使模型从不完整的上下文中学习并预测这些被掩码的部分。

- 掩码潜在建模(Masked Latent Modeling):在潜在空间中对图像标记进行掩码操作,然后通过不对称的扩散变换器结构来预测这些被掩码的标记。
- 不对称扩散变换器(Asymmetric Diffusion Transformer):包含编码器、侧插值器和解码器。编码器和解码器被设计为位置感知的,以增强模型对标记之间位置关系的理解。侧插值器在训练时用于预测被掩码的标记,而在推理时则被移除。
训练过程:Noised Latent--->Patchfy--->Masking---->Encoder--->Side-Interp--->Decoder----->Latent<--->VAE encoder<---GT Image
推理过程:Noised Latent--->Patchfy--->Masking---->Encode--->Decoder----->Latent--->Generated Image
由此可知,训练阶段仅是为了学习到最下面的Pos. embed,也就是整个噪声图像的位置嵌入。训练阶段的监督对齐是在潜在空间进行对齐的,也就是利用VAE进行编码得来的潜在空间。
4.2 MDT v2
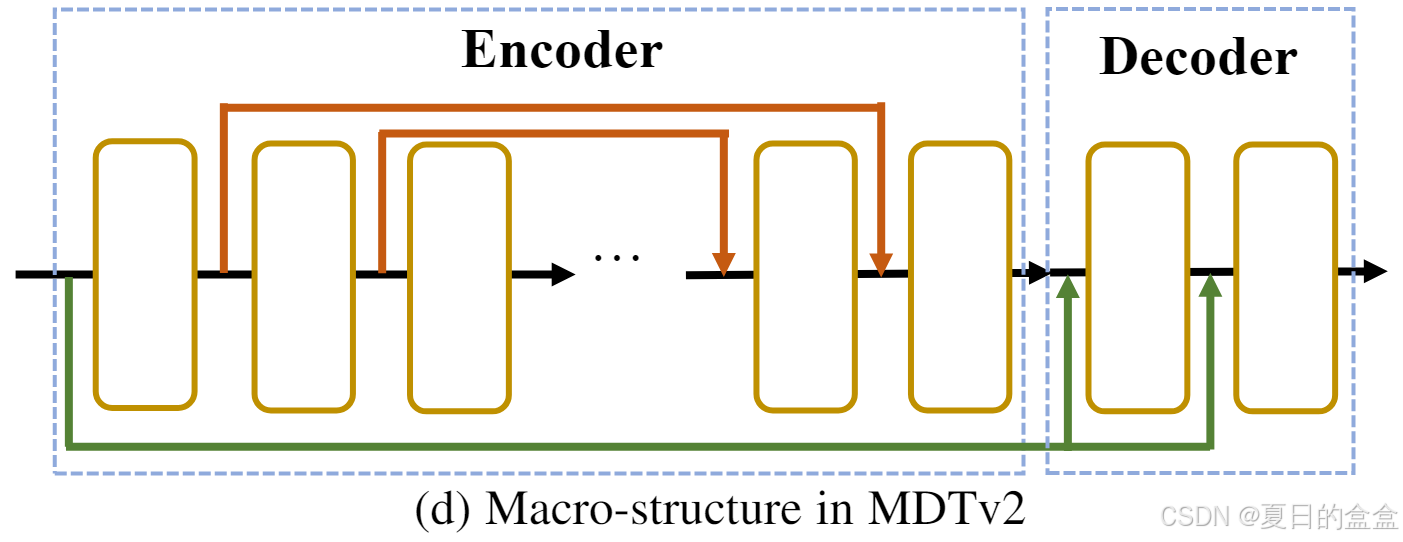
为了进一步加速扩散训练,MDTv2 结合了基于原始掩码扩散变换器架构的宏网络结构。虽然原始的MDT是基于DiT修改的,具有普通的网络结构,但MDTv2引入了具有增强快捷方式的宏观网络结构。这一进步显着加速了MDT的收敛速度。具体来说,MDTv2 在编码器中集成了类似 UNet 的长快捷方式和解码器中的密集输入快捷方式,进一步优化整体架构。

















 512
512

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









