








PR Flow内容总览

在整个PR阶段,我们要做的主要可以分为三大部分:
①data setup部分,就类似于我们一般的Creat new project创建新项目的阶段,此阶段我们主要就是导入各种文件;Technology file=TF文件=工艺文件,规定了线宽线距等DRC规则;
②检查各种文件是否正确;要check的主要有三个部分:各种libs & RC模型参数 & 约束和时序文件;
③执行Flow;
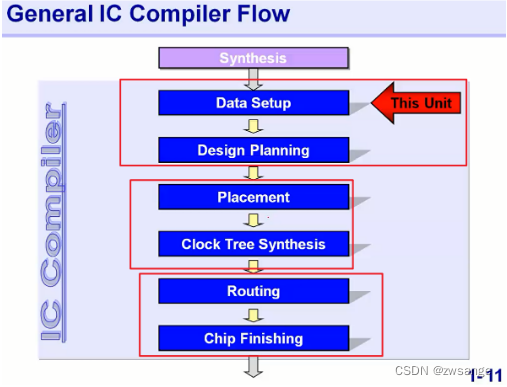
Design planning=Floorplan,即设计规划的意思;
Data setup
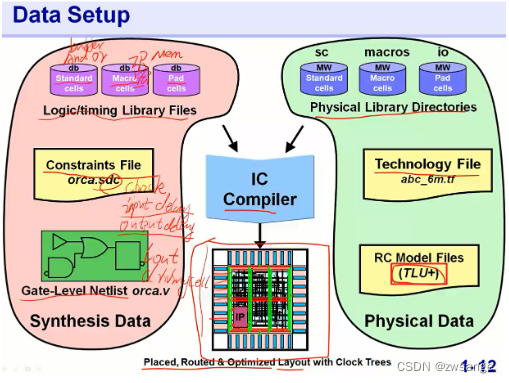
逻辑库包含了Standard & Macro & PAD cell,简单介绍一下其中的一些名词:
Standard cell:就是标准的各种gate cell;
Macro cell:指一些IP cell,多为memory等期间,我们一般指的都是物理cell,也有soft cell;
Pad cell:压焊块,用来描述Pad与芯片内部的连接;
TLU+:指RC model file,一般都说TLU+;
Logical Lib

逻辑库的作用:提供各种库文件及约束文件等;
在此,我们的Target lib一般指的就是Standard cell lib,在DC中目标库也是指的工艺库,此处其实就是叫法不同;此处设置目标库的目的是为了opt优化过程,在PR中会有多步优化,当某步优化出问题时,就会返回上一步,这时候就需要目标库来告诉工具哪个cell是什么功能和含义;
Link Lib包含了所有要用到的库文件,工具有需要会自己去里面找;
Physical Lib
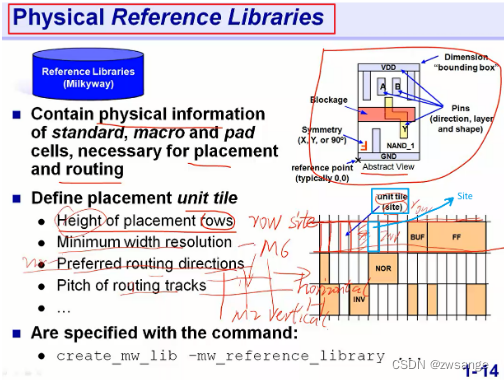
物理库中主要就是物理信息,包括芯片的概要图,最小单元site的定义等;
site:芯片中的最小单元,因此,所有的标准cell的大小都是site的整数倍,芯片的面积也是site面积的整数倍;
Height of placement rows: site的高度,可以看出,不同cell由不同个数的site组成,但大家的高度都是相同的;
Minium width resolution: site的宽度;
Preferred routing direction:参考金属走线方向;现在的芯片上面都有多层金属层,一般我们以M1金属走线方向作为参考方向,如果M1是横向horizatal,那么该方向就是Preferred routing direction;那么,M2就是纵向vertical,叫做Non-Preferred这样纵横交织堆叠;
Pitch of routing tracks:布线通道,不同层金属在走线时,不是乱走的,有一个走线通道;
Milkyway structure of 物理库
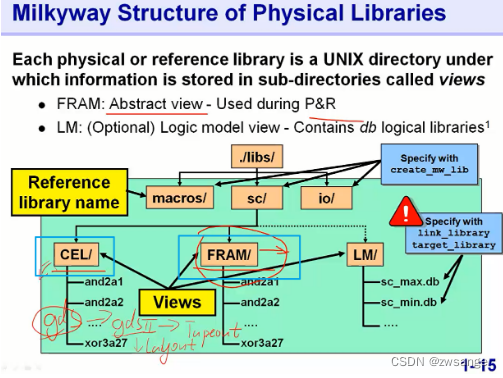
物理库的结构信息,主要了解两个views: FRAM view & CEL view,二者都是描述的SC(standard cell)中最基本的布局布线信息,FRAM是一个概括的视图,CEL view存储的信息更全面,最后在到导出GDSII文件时,用的就是CEL view;
Data Setup Flow细分
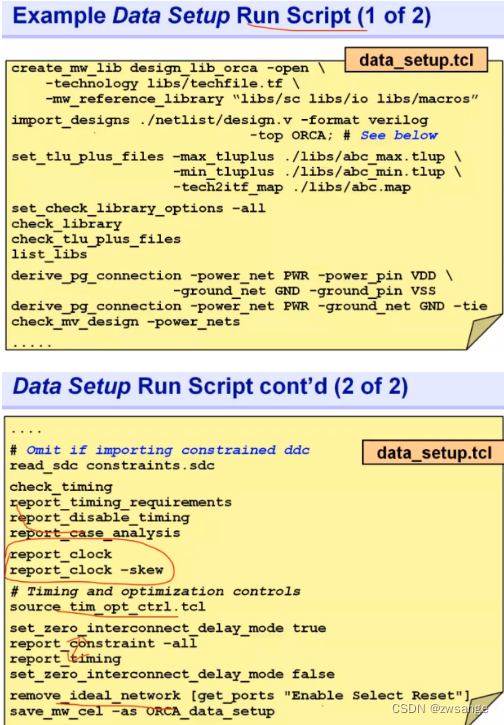
逻辑库的设置

关于逻辑库的设置,我们可以和DC一样,在隐藏的de.setup文件中设置,当然也可以自己写成一个setup脚本,到时候加载进去即可;
PR中库文件设置时,需要考虑max库(setup)和min(hold)都要设置;
简单解释一下为什么setup / hold=max / min:
Tsetup在计算时,slack=Require - arrived,其中arrived是我们真实的延时,当slack>0收敛时,我们考虑最worse的情况,那么就需要arrived最大;
Thold在计算时,slack=arrived - require,arrived是我们真实的延时,当slack>0收敛时,我们考虑最worse的情况,那么就需要arrived最小;
.synopsys_dc.setup
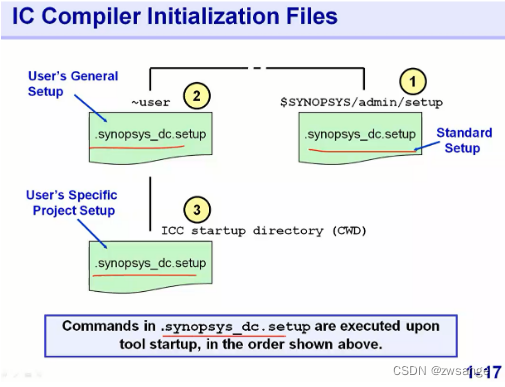
.synopsys_dc.setup文件在上述三个地方都会存在,优先级最高的是3级,当同时存在时,优先级高的会覆盖低的;
物理库的设置
创建Design lib in Milkyway
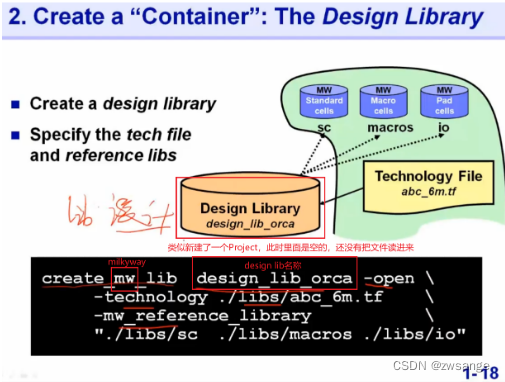
通过create_mw_lib命令创建一个design_lib,并指定了工艺文件和ref lib,类似于创建了一个新的项目,不过此时一些相关的文件还没有读进来;
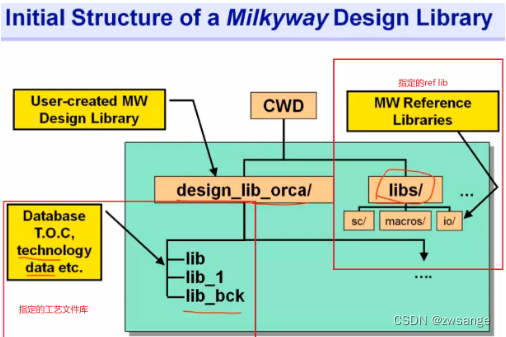
创建好design lib后,整体的结构如上图所示;
将netlist读进design_lib
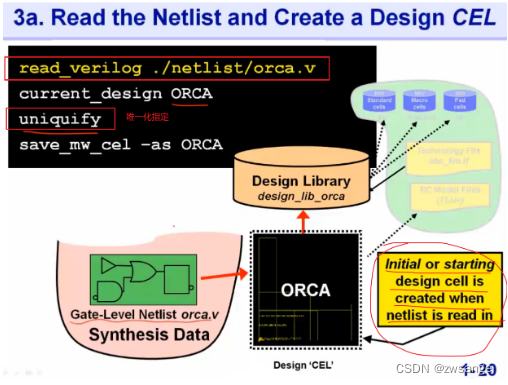
当我们把综合后得到的netlist读进design_lib后,工具就会自动生成初始的design cell;读取netlist的命令和综合中一样,然后需要指定顶层,在进行唯一化指定;
uniquify设定
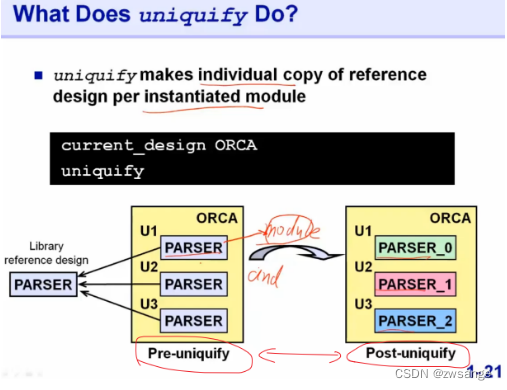
何为unquify设定?举个例子,我们的设计中使用了某个成熟模块的设计,该模块的相关内容放在了ref lib中,在我们的设计中多处调用了该模块,如上图,在没有进行uniquify前,每处调用的该模块名称都是一样的,而进行unquify后,工具会帮我们对多处调用进行命名区分;
save_mw_cel
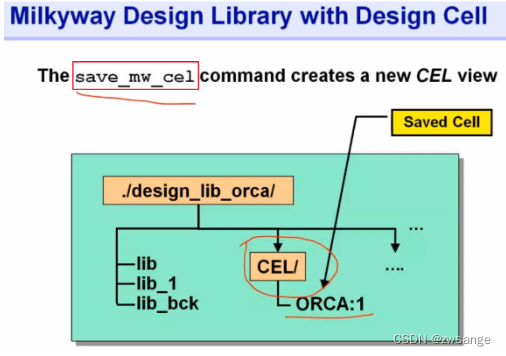
当我们save_mw_cel后,我们前面生成的design_cell就保存下来了,并在design_lib下面得到CEL view;
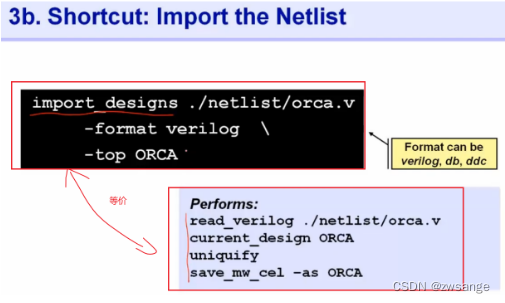
等价操作,更加简洁;
Technology File

Technology File(TF file)的内容说明,主要就是命名,Design rule,电气特性等;
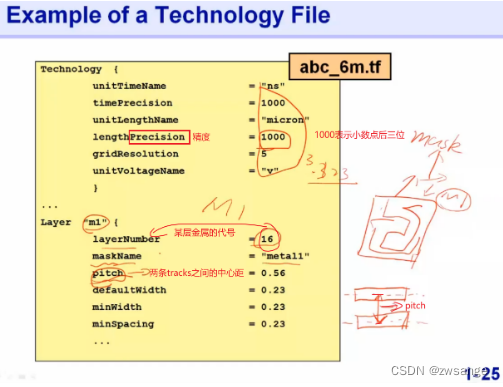
简单说明一下TF文件中的一些名词:
Precision:精度,1000就表示小数点后三位;
pitch:前面我们说过,tracks是布线时的走线通道,那么对于同一层金属来说,两条tracks中心之间的距离,就叫pitch;
TLU+ file
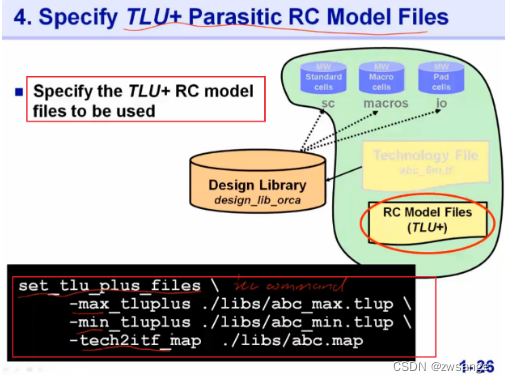
TLU+文件的设置用”set_tlu_plus_files”命令来设置,同样包含了max和min两部分,mapping file后面讲;
mapping file
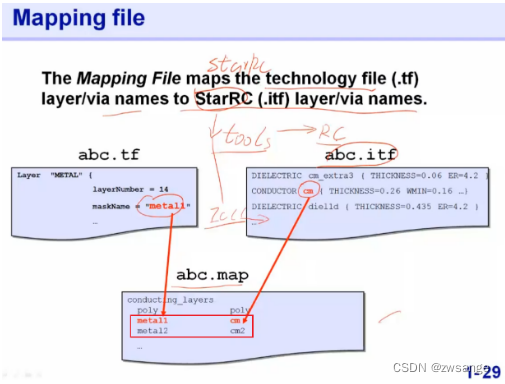
mapping file的目的就是为了将.tf文件中的名称与.rtf文件中的相对应,为了在进行RC模型建模时抽取.tf对应的StarRC.itf文件中的寄生参数;(简单理解就是,.tf文件中的metal寄生参数存储在另一个.itf文件中,但这两个文件中对同一matal的命名是不一样的,所以需要一个中间的mapping映射文件来告诉工具哪个对哪个)

ICC在计算延时(这里所说的延时,主要是针对组合电路的延时计算,包括cell & wire delay)时,主要基于cell delay和Net delay,其中net delay主要就是一些RC寄生参数相关;
TLU+ Models--UDSM
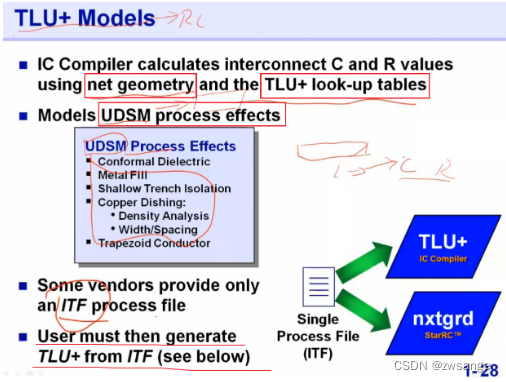
ICC在计算RC参数时,是根据net geometry和TLU+查找表来计算的;使用的TLU+模型为UDSM模型;一些供应商会提供.itf文件给用户,用户需要通过mapping file自行抽取RC参数;
Check Libraries
物理库check

Check lib主要就是让工具帮我们检查一些文件是否有缺失及失配,首先我们用”set_check_library_options -all”命令告诉工具检查所有要check的项目;其中,主要有两大类:
check_library: 检查逻辑库和物理库之间是否有missing /mismatched cell;这里要提一点,一般来说,在物理库中会包含一些纯物理的填充filler cell,这部分cell完全没有逻辑作用(在逻辑库中是不存在的),是纯填充作用,因此肯定会报missing cell;因为我们在layout中,肯定有些部分是空白的,但在制造过程中这些空白区域是不被允许的,所以就产生了filler cell,一般就是一些cap cell,来填充这些空白位置;
同时,也会检查物理库中的CEL & FRAM view是都有missing, 是否存在多次引用模块导致的重名(unquify设置);
check_tlu_plus_files: 用来检查TLU+相关文件和设置的完整性;
逻辑库check
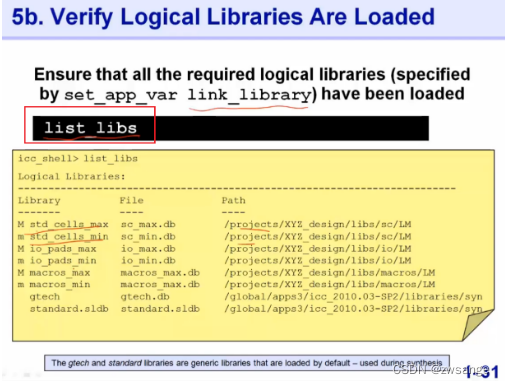
物理库check命名用”list_libs”,其实主要就是检查link_lib中的库文件是否齐全,工具会列出来所有link_lib中的库文件,我们自己进行检查;
Define Logical P/G connections
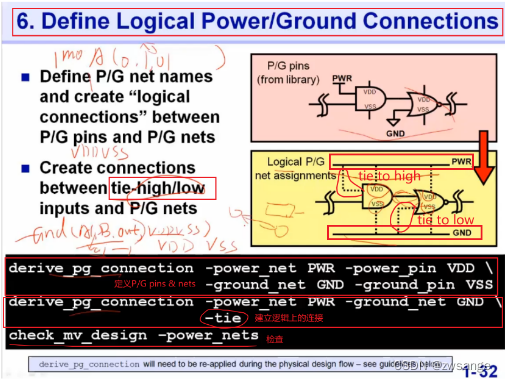
定义Power & Ground pin/net的名称及建立逻辑上的连接;如果仔细看过综合后的netlist我们就会发现,其中cell都是只有input/output的,并没有显示出PWR & GND,这是因为每个cell都需要连接pwr和gnd,所以工具省略了,但我们在做布线时就必须加上去,因此我们先用”derive_pg_connection”定义了Power & Ground pin/net的名称,然后再告诉工具建立逻辑上的P/G连接,如上图所示:
①将所有cell的PWR逻辑上连到一起,将所有的GND逻辑上连到一起;
②建立一些tie连接,tie连接就是有些cell的一些pin,是固定接高/低的,因为在数字电路中,input是绝不能floating的,因此对于一些固定接高/低的pin, 此时也需要建立逻辑上的P/G连接;
Check Timing constraints
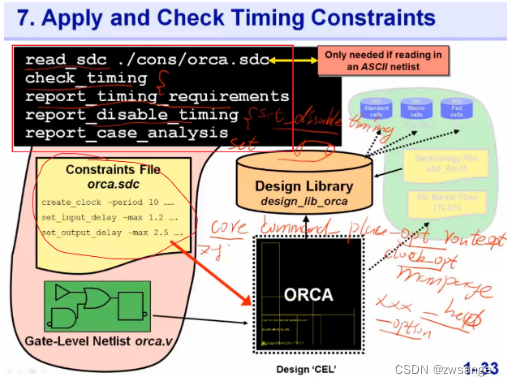
导入时序文件并进行检查,主要就是检查clock & input delay & output delay & translation & capaticity这五项;

几个点需要注意一下:
①我们需要告诉ICC工具我们的时序要求是什么,所以需要导入时序约束文件;
②如果我们用的是综合后的ddc文件,那么就不需要再次导入约束文件了,ddc文件里面都包含了;
③如果用的不是ddc文件,那么就要导入.sdc文件,注意,这里的sdc文件必须和综合中用的保持一致;
Proper Model of CTS
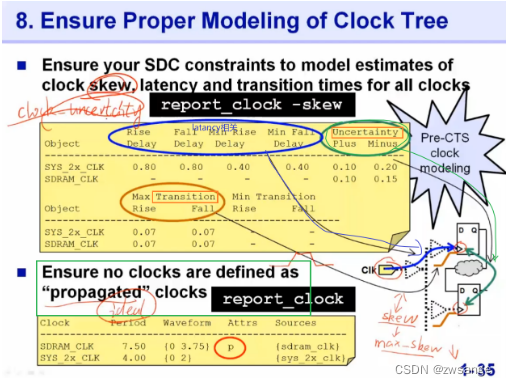
时钟树主要和uncert/transition/latency相关,也就是FF1--FF2之间的三种延时;
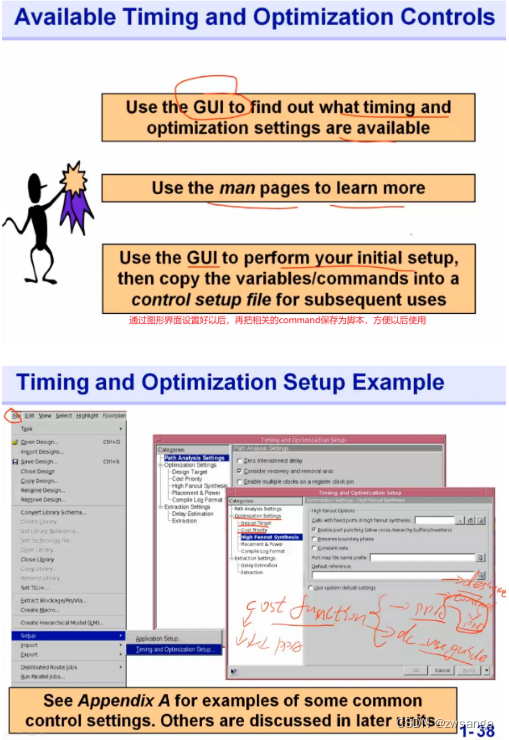
Timing and Optimization controls

上述举得这三个例子前面18/19/17课时都讲过:允许互斥时钟/直连引起assign语句,需要工具插入buffer解决/group path;这些设置一般都是通用的,因为相关的命令很多,我们可以用GUI界面来设置,然后把相关的command保存为一个脚本文件,每次使用时进行调用;
GUI界面举例;
Timing Sanity check时序完整性检查

时序完整性检查主要做两件事:
①在进行placement之前确保时序没有over-constrained,因为一但过约束了,那付出的代价可能就是面积增大,因此约束一定要和设计标准相匹配,比如我们的频率是1G,那就不要用1.1G来设置约束;
②进行”ZIC--zero interconnect check”检查,就是不考虑net-delay来检查设计的时序违规,如果没有加上net delay就已经存在严重的时序违规的话,那大概率是后端无法收敛的,直接打回上一层让设计修改代码/约束;具体的command如上,就是先打开ZIC模式,然后报告所有的时序违规,在关闭ZIC模式;
Remove unwanted HFN:High-Fanout-Net
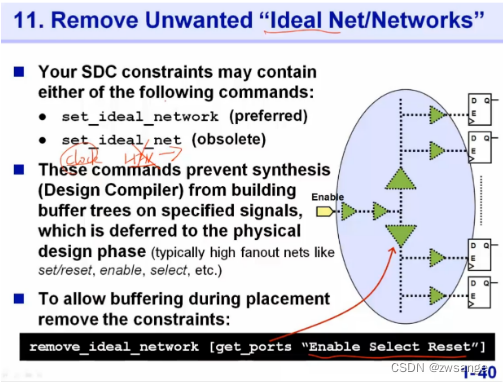
在DC中,我们是有理想设计的:对于clock和HFN(高扇出线)是不考虑net delay的,但是在ICC中,HFN我们是需要考虑net delay的;而HFN的地方一般就是select reset处,因此需要"remove_ideal_network [get_ports "Enable Select Reset"]";
Save and loading the Design
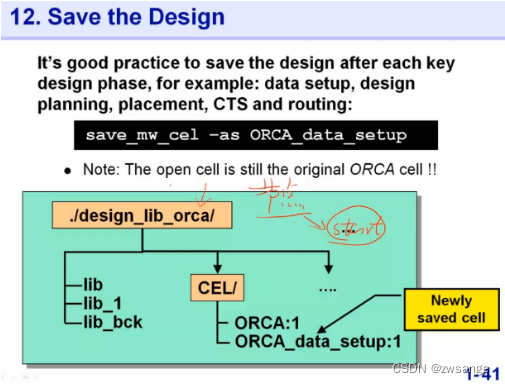
当我们设置好了上述1-12所有的Data setup步骤后,一定记住要进行存档,以便后面有更改时可以找回来;
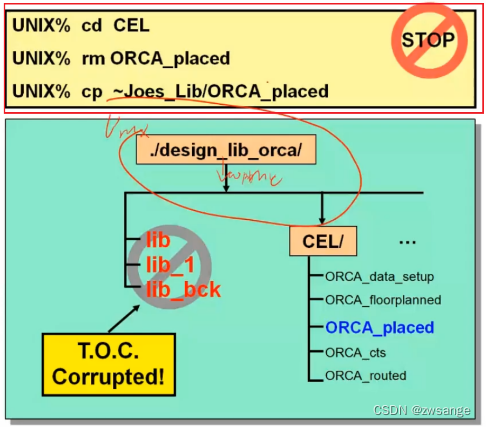
当我们要对design lib中的文件进行操作时,记住不要用linux的一些命令,而是要用ICC的一些命令!!
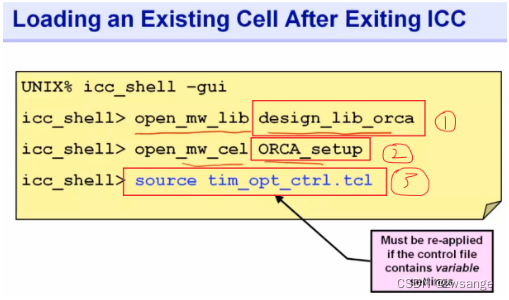
当我们重新启动ICC后,想再次打开我们的设计,分为三步:
①先打开design_lib;
②再打开保存的data_setup文件;
③每次重新打开设计时,都需要重新导入时序约束及优化相关设置文件;
Data Setup Flow总结
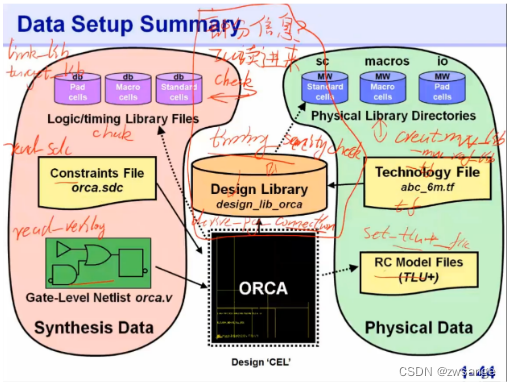
至此,data setup就设置完成了,我们需要掌握的是:上图这六大部分,每个部分的信息是什么,ICC怎么读进来的,是否check,重点关注时序完整性检查和derive_PG_connection两部分;
①Logic/timing lib file:包含了所有的逻辑库文件,通过隐藏的.dc_setup中的target & link lib读进来,读进来后需要和物理库文件一起进行check;
②.sdc file: 时序约束文件,通过read_sdc读进来,需要进行check_timing;
③门级网表:read_verilog;
④物理库文件:工艺制造相关的信息,在创建design lib in milkyway时就直接指定了;
⑤TF文件:design rule相关工艺信息,同④一起导入;
⑥RC model file:工艺对应的RC延时信息,通过set_tlu_plus_files命令导入,需要进行check;
部分命令总结

ICC Flow简介
Design Planning
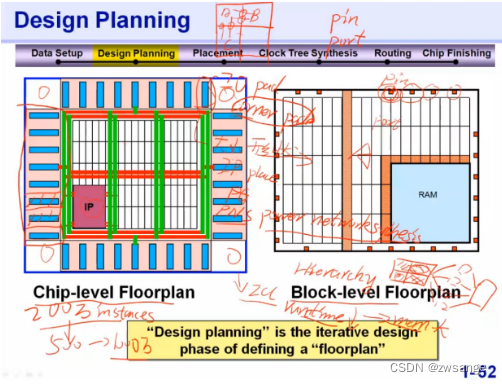
前面提过,Design planning又叫Floorplan,,即布图规划;在这一步中,可以分为两部分:Chip-level 和Block-level,对于ICC而言,一般简单的芯片可以chip-level直接做,但是当芯片比较复杂,cell过多时,直接做runtime太久了,因此通过hierarchy层次化设计,将芯片分成多个block分开来进行ICC,最后再拼接起来;
在Floorplan阶段,ICC主要做的事情有两件:
①IO/Pad place并规划芯片的大小及形状,上图中,对于芯片四个角位置的空白区域,无法放置正常的pad,因此引入了corner pad的概念,属于纯物理pad,没有任何逻辑功能;
②IP place & PNS--Power Network-Sythesis,将IP和电源网络放置好;
对于floorplan这一步做完后,可以用"write_def"保存一个.def格式的文件,用来记录layout相关的物理信息,后面我们可以直接读取该def文件;
Placement
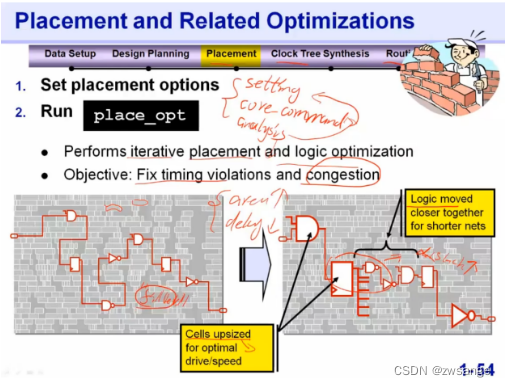
后面对比后可以发现,Placement / CTS / Routing这三大步做的流程其实是一样的,都是先setting,再运行core command,最后analysis,如果分析结果没有达到要求,就返回到第一步setting进行修改,直至达到要求;
Placement主要做的事情:
①对cell进行放置和逻辑优化;
②修复时序违规及布线阻塞congestion(通过增大cell面积及位置移动来优化setup时序);
CTS

基本流程和前面的placement类似,主要做的事情就是上述的几条,其中注意的是,在CTS之前我们是不考虑Thold违规的,在CTS之后加上了net delay,在考虑修复hold违规;
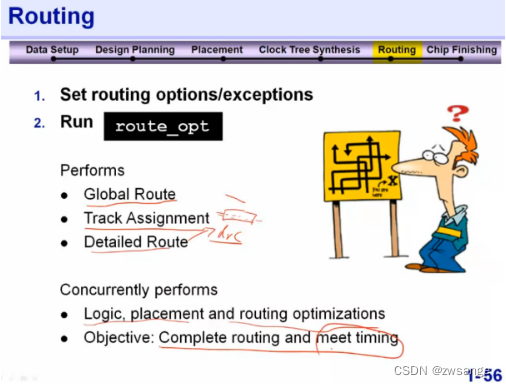
Routing
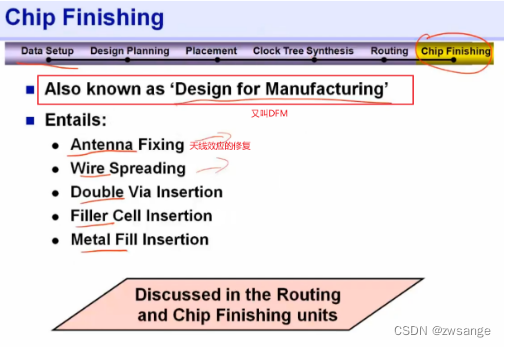
Chip Finishing/DFM
Analysis内容及常用的命令

analysis分析时要注意的内容:
面积利用率:用STD cell/Chip area,算出面积利用率;
时序Slack;
cell place的合理性,有没有放在site里面;
Design rule:此处的design rule指的是fanout/cap/translation;
命令flow汇总脚本
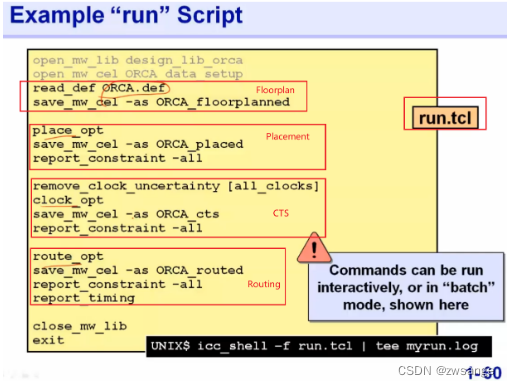
Appendix

Multiple clocks per register

第十八课互斥时钟部分有讲;
Constant propagation
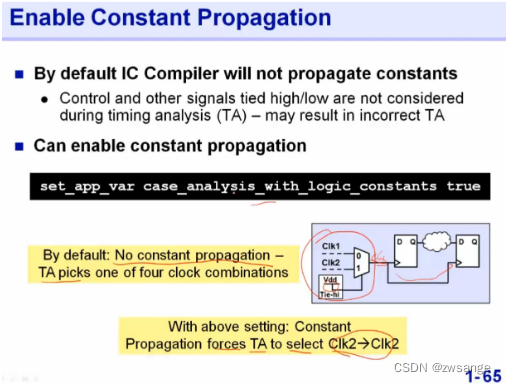
在ICC中,常值是不会传播的,当我们在此处设置了允许常量传播后,该mux就只会选择clk2来使用了;
Multiple port Net buffering
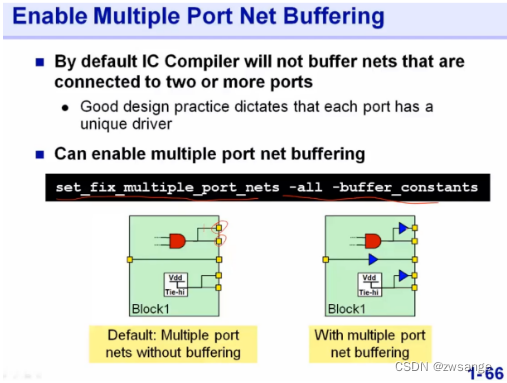
第十九课中assign语句有提到;
串扰电容的影响
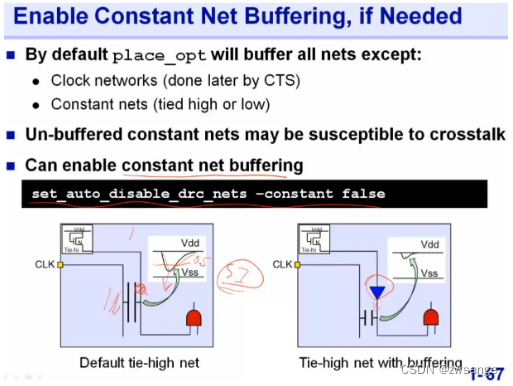
对于某些常量net而言,如果和clk net离得比较近,由于串扰电容的影响,在clk跳变时,会对旁边的常量net的电位产生影响,这种影响如果使点位变化达到50%以上,就会影响逻辑功能了,解决方案就是让工具在常量net上加一个buffer,增大net的驱动能力,降低串扰电容的影响;
Cell使用的选择

保留spare/unloaded cell

保留一些冗余的cell,以便后面进行ECO改版使用;工具会默认删除unload cell,需要人为关闭;
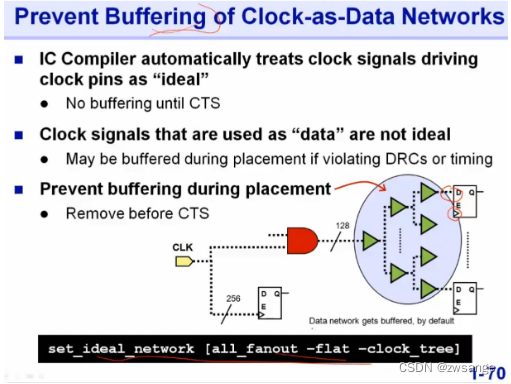
防止clk通过buffer连到data
设置优化优先级

ICC优化时默认的优先级如上图,可以人为设置优化优先级;
带reset的寄存器时序分析

设置面积约束

将面积设置为0,让工具尽可能的去优化;
设置关键路径范围

对关键路径设置一个范围,让工具除了对最worse的路径进行优化外,对该范围内的其他次关键路径都进行优化,和DC中的概念是一样的;















 1283
1283











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









