







内容总览

前面的Data setup及floorplan是非常重要的,且手动要操作的地方很多,后面从placement到chip finish的内容手动操作会少一些,但同样重要;

本节的学习目标:前面三节内容是新的,后面两节内容是以前讲过的,其实PR最主要的就是congestion及timing,后端遇到的问题,越早发现就越好解决;
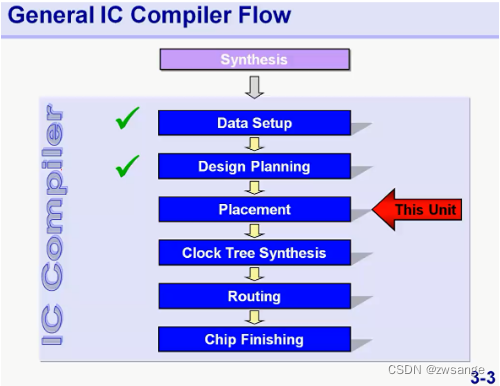
Placement这一步,主要就是根据前面Re-Synthesis后的结果,再进行std cell 的placement;
Design Status Prior To Placement

在进行placement之前,需要进行一些check,如:
①Design planning已经完成;
②Re-Synthesis已经完成;
③Re-Synthesis后的Second Data setup已经完成;
④Second Data setup后导入Floorplan的DEF文件,然后确保FLoorplan中的一些流程已经完成,如IO pad、macro cell、blockage、PNS,其中由于在保存DEF文件时将std cell placement移除了,因此这一步一开始是没有std cell placement的,我们这一步的目的就是做这个;
ICC placement Flow
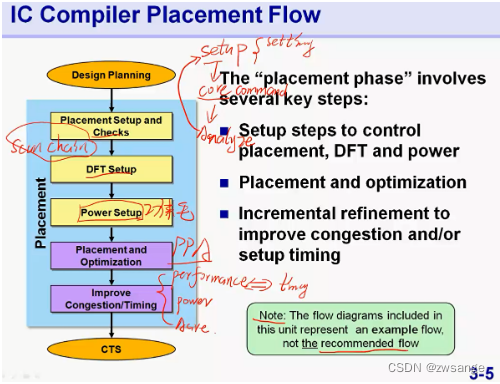
如图为ICC placement的flow,整个过程可分为三大部分:setup/setting、core command/placement OPT、improvement;
注意,这里的Placement OPT也有好几步,其中第一步就是我们前面做的Virtual Flat Placement,将std cell进行初步放置,然后在对一些不同path进行不同的优化;
(问:为什么在FP中的Virtual Flat Placement不直接进行placement OPT呢?因为FP中我们只是做布图规划,只需要一个粗略的placement用来评估congestion及timing即可,同时还要兼顾runtime,因此不需要精细的placement信息)
Placement setup and checks
"FIx" all macro cell placements

首先,我们导入floorplan后的文件,
然后再source一遍时需优化tcl;
再fix一下all macro cell placement,以防万一;
Verify layer and placement constraints

check上述的几项有没有重新loading,如果没有的话就重新apply一遍;
主要是导出DEF文件时不包含在内的两类信息及PNS后的PG相关blockage信息;
Non-Default Clock Routing

前面23课提过,如果Sig线和clk 离得比较近,由于Cross-Talk串扰电容的影响,在clk跳变时,会对旁边的sig电位产生影响,这种影响如果使点位变化达到50%以上,就会影响逻辑功能了,解决方案有几种:
①让工具在sig net上加一个buffer,增大net的驱动能力,降低串扰电容的影响,该方法是23课中提到的,在本节课一般不这样用;
②Non-Default Clock Routing-NDR,即clk非常规绕线规则,采用非常规的线宽、线距、中心距pitch等,以解决cross-talk串扰电容及EM电迁移的影响;一般常用的NDR Rule为双倍线距、双倍线宽及采用屏蔽线的方法等;在clk频率>1GHz / <40nm制程中一般都采用NDR规则,但会占用更多的绕线资源;
双倍线距可以有效的避免串扰电容的影响,线距越大越好,但会占用过多的绕线资源,仿真结果表明,从单倍线距到双倍线距的改善最明显,三倍相对于两倍变化不大;
双倍线宽可以有效改善EM电迁移;
Shielding屏蔽线就是在clk net两侧加两根屏蔽线,如VSS;这种方案对串扰电容的解决效果最佳,但最占用绕线资源,常在高频clk芯片的设计中使用;
为什么要进行NDR设置:设置了NDR rule后,将clk的congestion考虑进来了,因此做congestion分析会更加准确;

举例说明怎么设置NDR Rule;
Check placement Readiness

check_physical_design的一些文件有没有正确的导入;
check_physical_constraints有没有一些违反约束的error存在,如cell放在了hard blockage中、RC值变化过大等;这一步有error是必须要直接解决的;
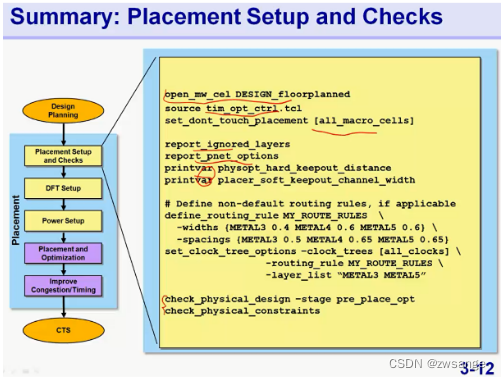
Summary: Placement setup and checks
DFT Setup

在逻辑综合DC阶段插入DFT的scan chain,DC工具一般都是根据字母数字的排列顺序插入的;但是在进行placement时,工具是根据逻辑功能、timing及congestion来进行placement的,不会考虑到DFT的scan chain,那么就会导致在placement后的scan chain顺序非常混乱,这无疑又会占用更多的绕线资源;
SCANDEF-Based Chain reordering

Scan chain information可以通过两种方式导入到ICC中:①因为DFT scan chain都是在DC插入的,因此直接将DC后的.ddc文件导入到ICC中,其中就包含了scandef文件;②单独将scandef文件加载到ICC中;
在ICC中导入scan chain information后,ICC在进行placement时,会进行”Reordering“,利用lockup latch & MUX将scan chain分成多个reordering bucket块,再在每个块中重新进行scan chain排布;
Re-ordering Chains within same "Partion"
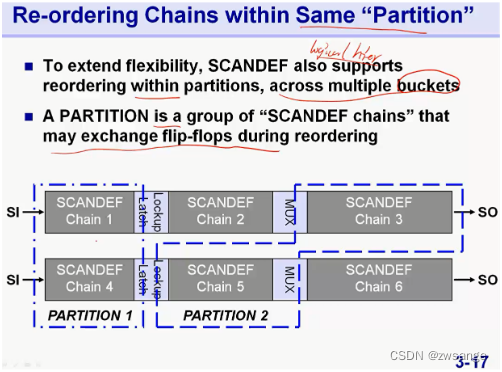
此外,Re-ordering chain还可以将几个bucket组合到一起,得到group,称为”Partition”,同一个partition内的FF都是等价的,可以任意re-ordering;
Example scandef from synthesis with DFT
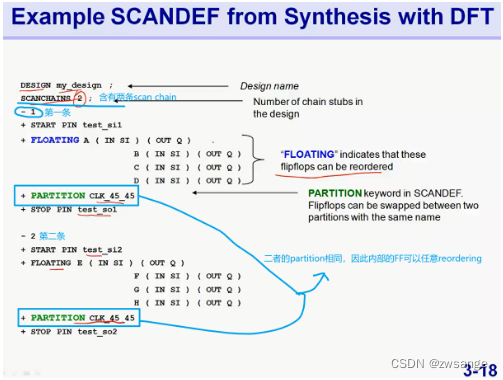
举例说明了partition的结构与内容;
Example2: 注意看图
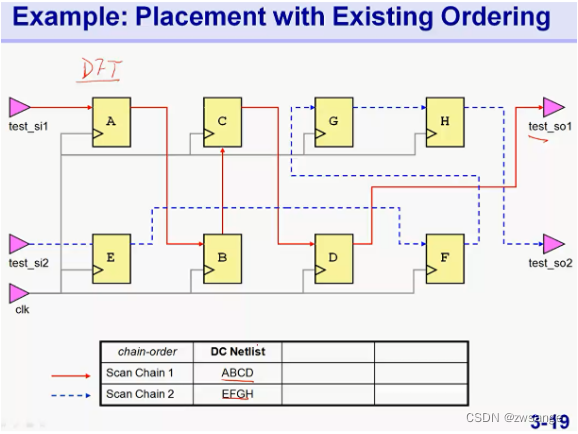
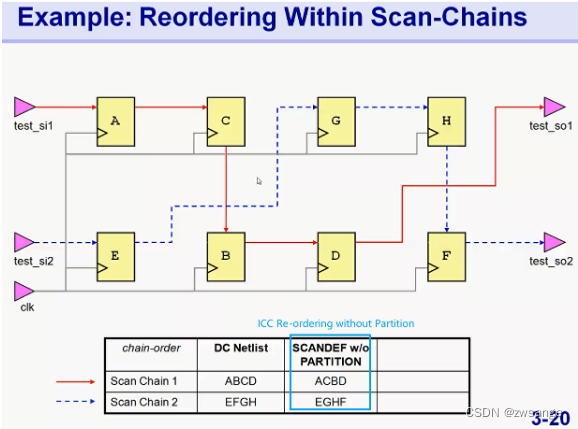
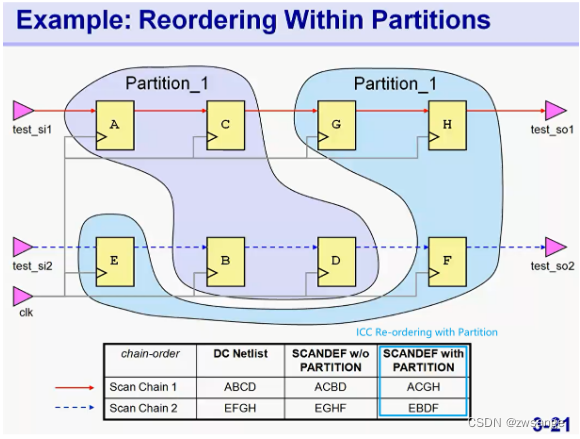
如上三张图显示的三种scan chain排列,明显最后一种re-ordering with partition最节省绕线资源;
Example3:Placement-Based scan chain Re-ordering
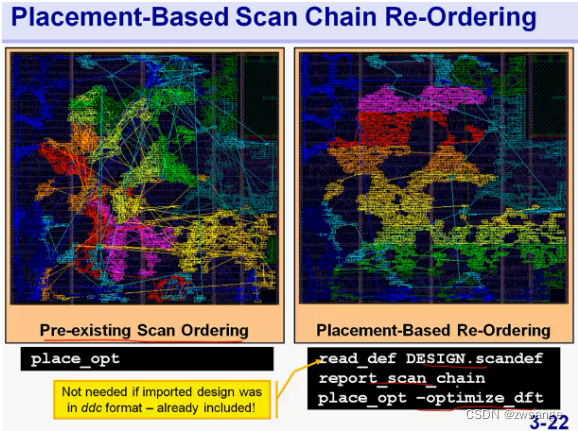
由图可知,作图为DC后的默认scan chain分布,右图为re-ordering后的手残chain;
Summary:DFT setup
Power Setup
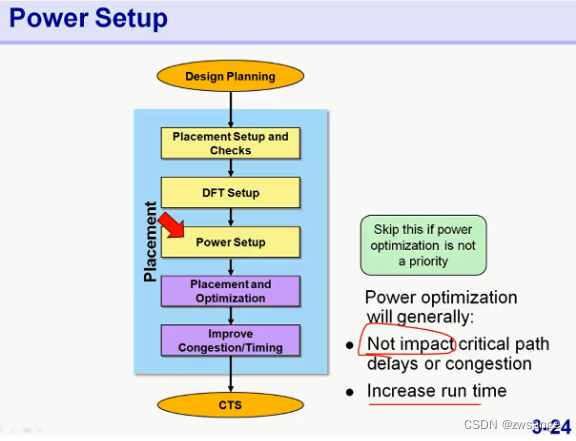
对于常规的Flow来说,power分析是在时序收敛之后进行的,除非是设计对功耗的要求高,需要在前期就加入功耗优化;
power opt会产生一些负面的影响:会影响timing & congestion,以及增加run time;
插入:CMOS结构及工作原理
CMOS的工作原理
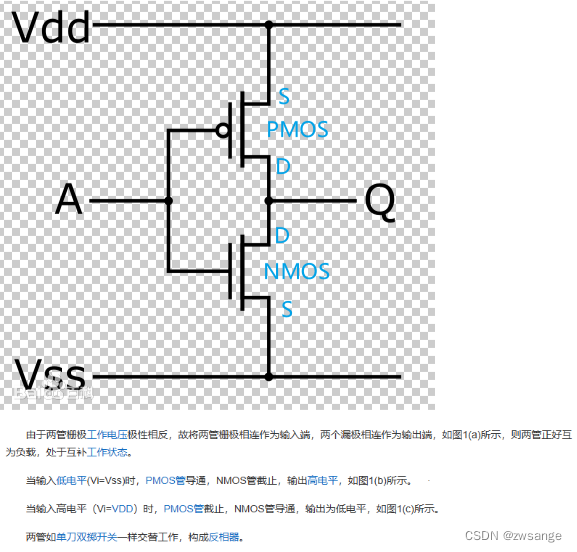
由图CMOS工作原理可知,coms由1*PMOS+1*NMOS组成,二者的漏极相连到一起接到输出端,栅极接到一起连到输入端,PMOS的源极接到Vdd,NMOS的源极接到Vss;
当在工作时,Vdd与Vss一直都是存在的,相当于cmos结构只是一个借用Vdd/Vss的结构,当输入端给高电平时,NMOS打开,输出端连到Vss,即输出为低电平;当输入端给低电平时,PMOS打开,输出端连到Vdd,即输出为高电平;
整个结构就像一个单刀双掷开关一样,二者互补打开,称CMOS反相器;
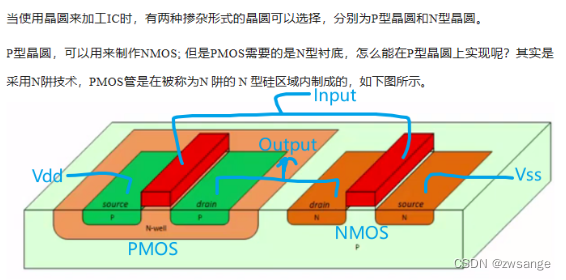
CMOS的物理结构
https://mp.weixin.qq.com/s?__biz=MzIwODc4NzE1OA==&mid=2247506483&idx=3&sn=7560ae58be36fcd3c61fb80b015d867e&chksm=977f598aa008d09c557bafedbceadea61e8b134abb18bc466f332c4ce2c8539c7eb5a2140f92&scene=27
如上图所示,物理上的CMOS结构和原理图也是很相似的;
功耗的来源
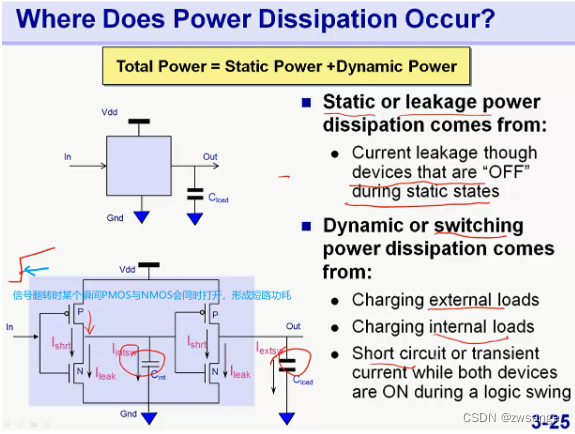
总功耗=Static power静态功耗+Dynamic power动态功耗;
静态功耗:又称为leakage power dissipation,主要来源于器件关闭时的漏电流产生的功耗;
动态功耗:主要来源与三个方面:①对外部负载的充放电;②对内部负载的充放电;③短路功耗/瞬态功耗,对于CMOS器件结构,由1*NMOS+1*PMOS组成,在发生信号翻转时,即对应不同的NMOS/PMOS开关状态,在翻转过程中的某个瞬间,会出现PMOS与NMOS同时打开的现象,此时为短路状态,形成短路功耗,虽然这个时间非常短暂;
静态功耗(Leakage)优化方法

如上图所示,对于静态漏电功耗,Multi-Vth多阈值电压技术是最小化漏电功耗的关键;在PVT工艺中,存在三种不同阈值电压的cell,LVT & SVT & HVT,阈值电压越低,打开速度越快,但静态功耗越大,一般这种cell常用在关键路径上来满足时序要求;而HVT的打开速度慢,但漏电小,这种一般用在非时序关键路径上,来平衡静态功耗;
相应的优化command就是首先要在target & link lib中区分hvt与lvt 库,这一步操作在data setup时就要准备好,指定相应的库文件,最后用"set_power_options -leakage ture|false"来打开/关闭功耗优化;
Report Multi-Vth cells

我们可以用report_threehold_voltage_group命令来得到Multi-cell的使用情况;对于低功耗的移动端芯片而言,一般不用LVS;一般的设计LVS的比例控制在5-10%内 ,太大了表明时序有问题;一些高性能的设计,可以在25-30%;
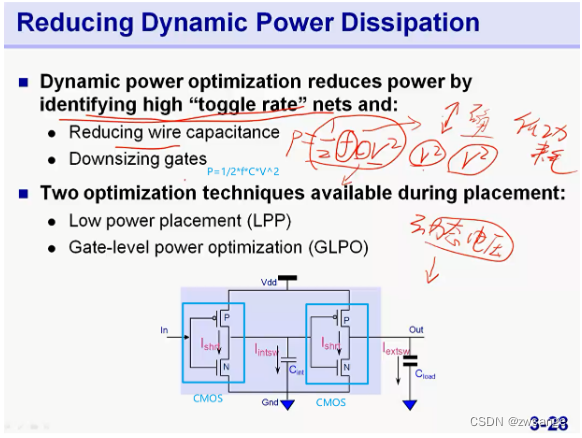
动态功耗优化方案
(注意,这里的方法是从后端角度出发的,前端设计/架构都有自己的方法,如门控时钟/多电压域设计等,此处仅讨论后端的方法)
根据动态功耗的公式:P=1/2*f*C*V^2,其中,”f“为频率,”C”为负载电容,”V^2”为电压的平方,做到这一步,频率/周期已经确定了,那么就通过降低负载电容及电压来控制功耗;
对于设计中“toggle rate”net,即翻转频率很大的net,对于这些net,我们可以减小他的负载电容,从而降低动态功耗;
在Placement阶段,我们有两种方法来降低功耗:LPP and GLPO,具体的后续说明;此外,前述的门控时钟也是后端降低功耗非常有效的方法;
翻转率相关几个概念
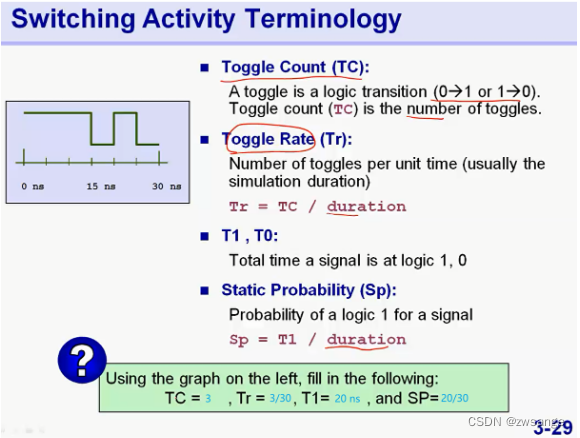
几个和翻转率相关的概念,比较容易理解:
TC:信号翻转的次数;Tr:一定时间内翻转的频率;T1/T0:logic 1/0持续的时间;Sp:logic 1/0在某个时间段内占的比例;
SAIF File provides switching activity
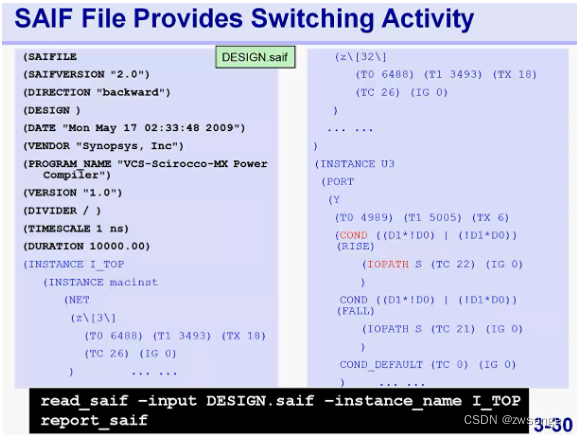
SAIF文件会提供翻转相关的一些信息,我们需要将文件导入到ICC中,该文件由功耗仿真的同事提供;

万一没有SAIF文件,我们可以自定义一些输入port的翻转率;
首先确定clk是合适的;对于一些不会翻转的signal,如reset/test_mode等,使用”set_case_ananlysis”来确定;对于其他已知翻转率的,我们可以在该路径的starting points设置翻转率,ICC会自动propagate,将翻转率传递下去;而不清楚翻转率的,就使用默认的翻转率;
LPP:动态功耗优化策略

Low power placement-LPP,如上图所示,当工具知道了一些net的翻转率后,会自动将翻转率高的net放置在离cell更近的位置,以降低负载电容,从而降低动态功耗;
默认情况下,LPP是关闭的,我们需要手动打开“set_power_options -low_power_placement true”;
GLPO:动态功耗优化策略

Dynamic power optimization-GLPO,动态功耗优化,通过优化逻辑连接来降低功耗,如上图四种方法:注意,GLPO优化策略默认也是关闭的,需要手动打开,可以和LPP一起用”set_power_options -dynamic true”;
①某个cell后的输出 translation time 过大,这说明两个问题:前级cell的驱动能力比较弱/负载电容较大,解决方案之一就是在后面加buffer,既能降低负载电容,又能优化时序;
②对于高翻转率的net,将前级cell的面积增加,增大驱动能力,同时将后级cell的面积减小,降低负载电容;
③将翻转率大的net接到负载电容小的pin上;
④在不影响logic功能前提下,将反相器等器件放在翻转率小的net上,降低负载电容;但在做这一步时,需要整体考虑一下,因为如果要想使得mux输出不变的话,要么在控制端加一个反相器,要么在输出端加反相器,这无疑都会增加面积与功耗,因此需要进行仿真分析是都有必要;
Summary:Power Optimization Flow
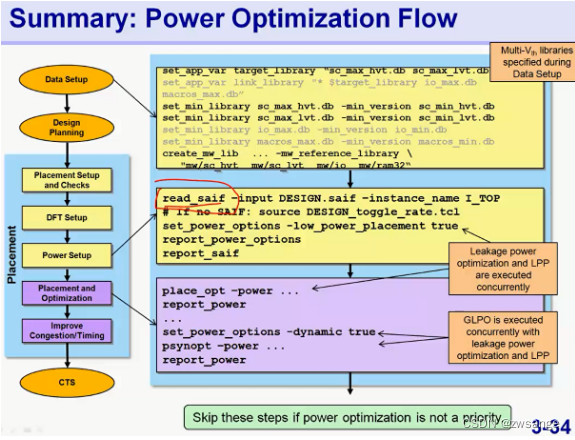
summary;
Placement and Optimization
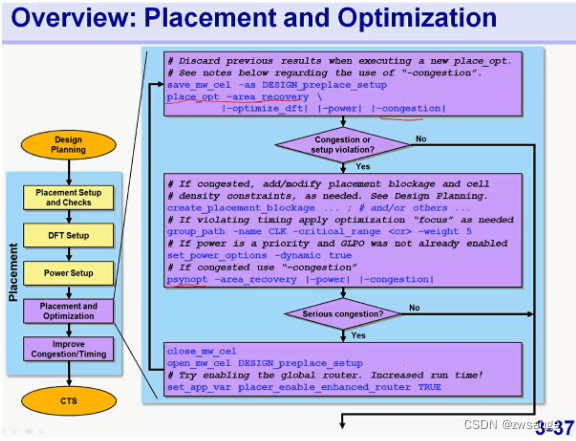
core command:place_opt
Placement and optimization

首先看下最核心的core command相关opt;

上图place_opt manpage说明了每个参数的作用及应用环境,在哪些情况下需要使用等,这种core command建议自己多看看manpage;
右上角的四个步骤是place_opt command的四步:
①corese placement就是粗略的placement,和我们在flooaplan中做的virtual fp中的placement是一样的;
②AHFS:high fanout net,前面data setup中提过,这一步就是解high fanout net的,解决方法就是通过build buffer;
③Logic opt:比如前面提到的动态功耗的逻辑优化等;
④Placement Legalization:cell位置的合法化,要保证每个cell都精准的放置在unit tile/site中;
-congestion的使用建议

在我们进行place -opt时,要慎用-congestion,因为在降低congestion的同时会影响timing,因此congestion没有大问题最好不要用;如果要使用,我们可以先跑一遍without congestion的,如果结果显示congestion有问题再加上;
如果有congestion问题,那么应该在design planning中就已经解决了,而不应该留到placement中!
Hold violation的修复建议

一般的设计而言,在CTS之前是不进行hold修复的,因为CTS还没有完成,hold violation数据不准确,修复hold可能会使设计恶化;另外,修复hold是比较简单的,只是加buffer/delay即可,因此建议在CTS之后进行hold修复;
当然,如果发现hold violation很严重,后续的步骤很难修复,那么也可以在placement阶段修复,这些都不是绝对的,只是一般建议怎么做;
Post-Placement 分析
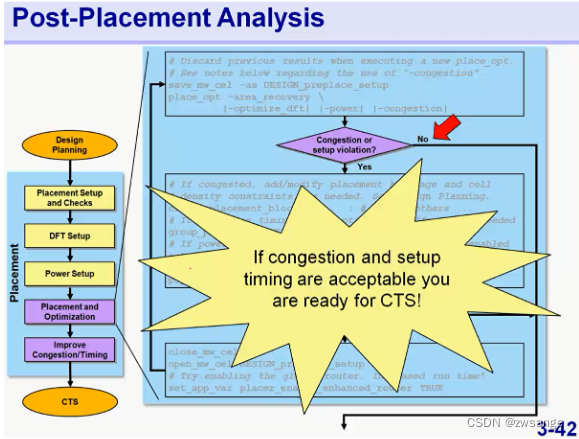
如果timing及congestion都满足要求,那就可以直接去做CTS啦!
当然,如果不满足,那就需要进一步分析了,如下图:
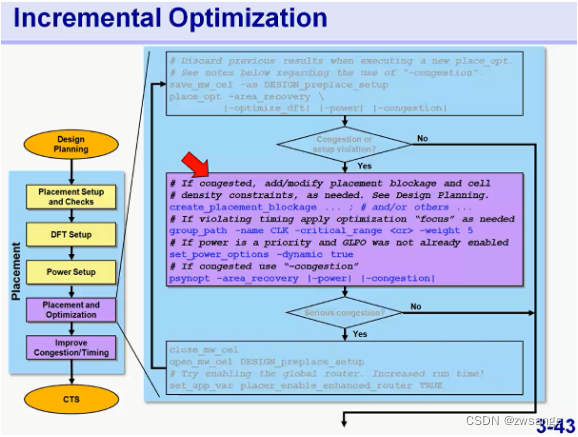
Congestion分析

如果congestion不满足,那就修正一下placenment blockage,或者休整一下cell density,具体的做法可以参考design planning中的;如果是design planning后的congestion是没问题的,但place后有问题了,那就检查一下上述的一些设置是否合理;
Timing violations分析--Path Group相关

如果place_opt后出现了timing violation,就需要分析是什么路径上出现的violation,这一点前面第17课DC优化技术讲过,主要就是input/output路径影响FF1--FF2路径及次关键路径的优化问题,下面再次进行简述;
Path group说明
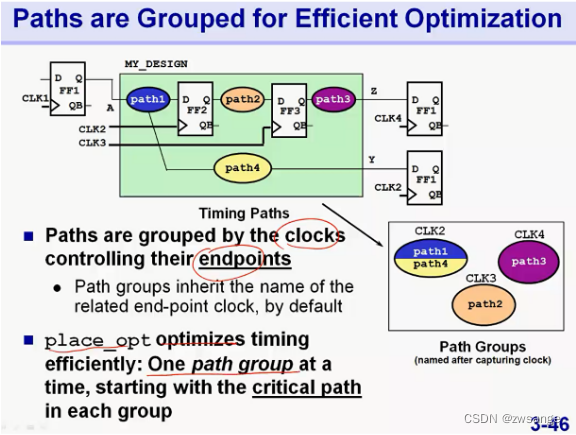
如果没有人为指定,那么工具默认是根据clk路径来将path进行group的,根据clk的end point将不同的path分为不同的group,如上图;place_opt在优化时,每次只优化一个path group,且只会优化每个path group的最关键路径;
次关键路径的优化问题 & FF1--FF2路径优化问题
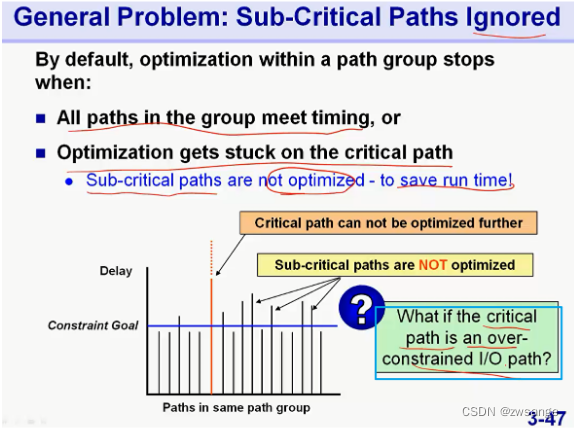
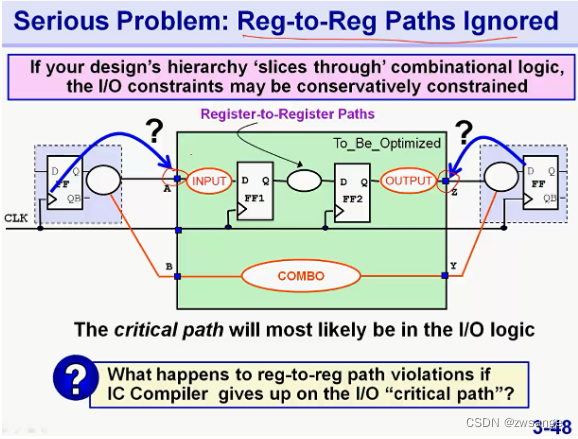
上面说的,工具只会优化每个group中的最关键路径,而如果这个最关键路径是我们over-stress的IO path,那么就不会优化我们真正关注的FF path/次关键路径;
解决方法1:将不同路径的path人为进行group;
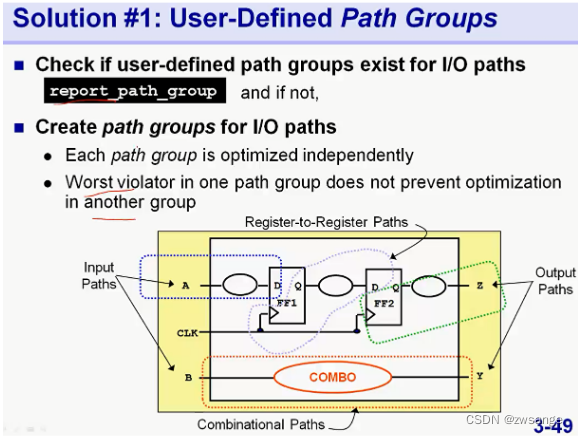
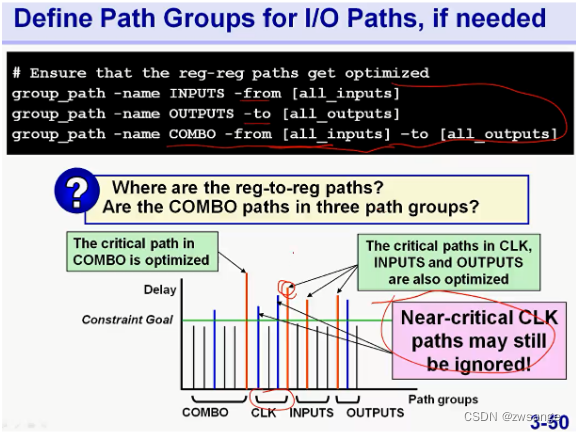
在我们进行了人为分组,将FF1-FF2 path分出来以后,可以使得FF1--FF2我们最关心的path group得到优化;但是工具也只会对该path group中的最关键路径进行优化,不会对次关键路径优化,因此,还需要下一步;
解决方法2:应用Critical range

除了上述的方法1以外,我们还可以设置一个critical range,最大不能超过clk的10%,否则会大大增加run time,critical range可以有效地解决次关键路径的优化问题,而次关键路劲的优化对最关键路径的优化是有利的;
解决方法3:设置path group权重

在前面两种方法完成了对寄存器path及次关键路径的优化后,紧接着我们可以对不同的path group设置权重,从而让工具对我们最关心的path进行最大程度的优化;一般而言,对于最关键的FF1-FF2路径我们可以把权重设置为5,其次可以设置为2,默认的为1;
举例说明权重的目的:
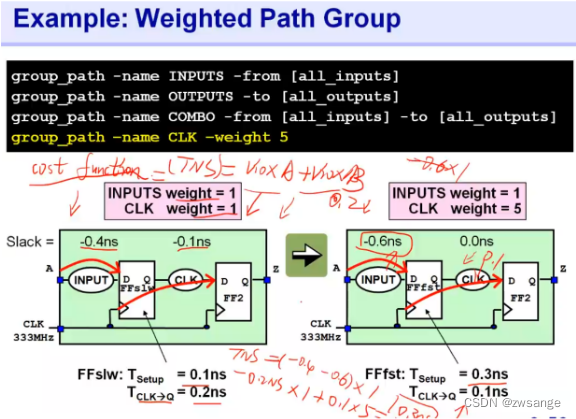
这里说两种理解形式:
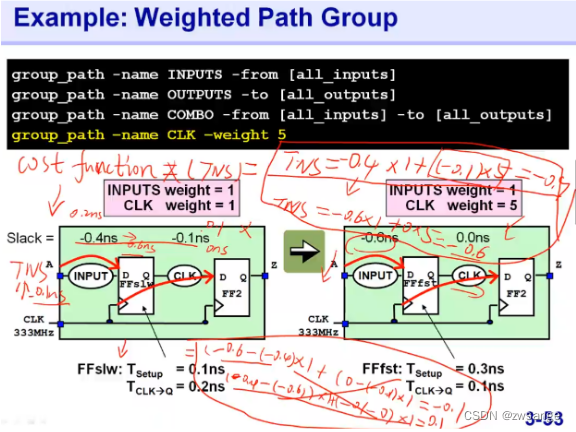
①参照第17课中的理解方式:工具会给权重高group更高的优化优先级,此处给FF1--FF2 path group设置了最高的优先级,我们知道,FF1的Tsetup时间是影响前一级的,而Tck(clk→Q)则是影响后一级的时序,当大家的优先级都是默认1时,工具在工艺库中选择寄存器时,会给FF1寄存器匹配一个比较慢的寄存器(Tsetup小,Tclk大)来均衡前后两边的时序,这就导致CLK path group存在-0.1ns的时序违规;而当我们把CLK group优先级设置为5时,工具会给FF1寄存器匹配一个比较快的cell(Tsetup大,Tck小),这样的话会优先保证CLK group满足时序要求(-0.1→0.0ns),即使前一级的时序变得更worse(-0.4→-0.6ns);
②引入一个概念:cost function损失函数TNS,工具在优化时是如何判断优化有效的呢?就是根据cost function的值进行判断的,cost function=violation*weight,只要能使得CF降低,那么优化就是有效的;下面我们来算一下权重设置前后的CF,加权重前:CFpre=-0.4*1+(-0.1*1)=-0.5;如果不给FF group增加权重,那么后面对应的CFno-weight=-0.6*1+0*1=-0.6,CF是增加的,显然工具是不会这么进行优化的;
现在我们给FF group设置权重为5,那么加权重前:CFpre=-0.4*1+(-0.1*5)=-0.9;加权重后CFpost=-0.6*1+(0*5)=-0.6;相比加权前CF降低,工具就会认为这一步优化是有效的,从而进行优化,将FFslw寄存器替换为FFfst;
Path group总结
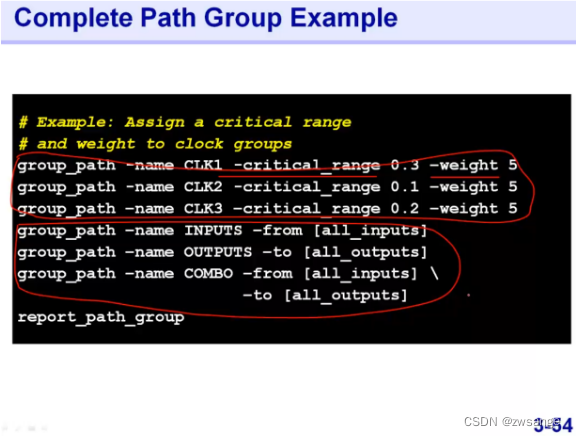
总结,一般在place之前,path group就已经创建好了,就像我们前面在DC优化阶段就已经做了这一步了;Group weight则可以在place后根据结果的好坏来确定是否要进行设置,因为在某个group权重增加后,肯定会影响其他的group的优化结果,需要根据结果进行取舍;
Incremental logic optimization: psynopt

此处就是place_opt后的进一步优化过程,这一步如果timing有问题就可以优化timing,如果congestion/power有问题就优化congestion/power,可以调用前面提到的LPP/GLPO来优化power;
Summary:Incremental optimization

概括一下,对症下药,有什么问题就采用什么优化手段;
如果还是有很严重的congestion...
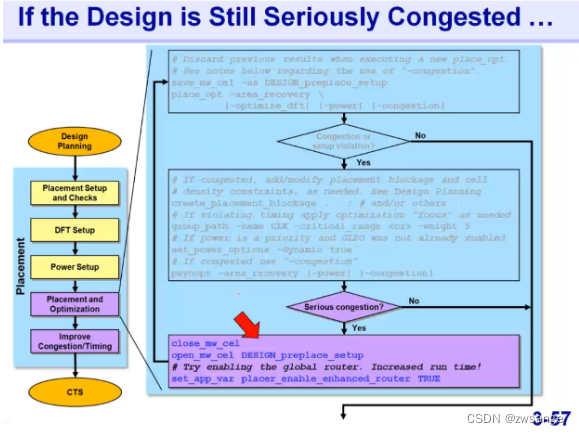

如果在前面的incremental opt后还是有很严重的congestion,那么就只能采用actual global router实际绕线引擎,而不是虚拟引擎来进行place了,如果进行了这一步,那么前面做的place_opt结果是不会保存的,后面需要我们在做一次place_opt;
Summary:Placement and opt
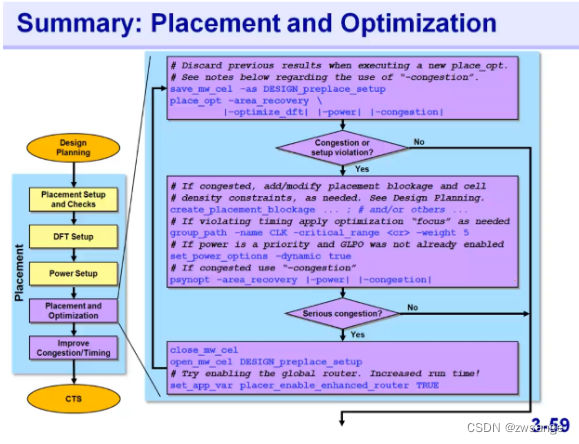
summary;
Improving congestion and setup timing
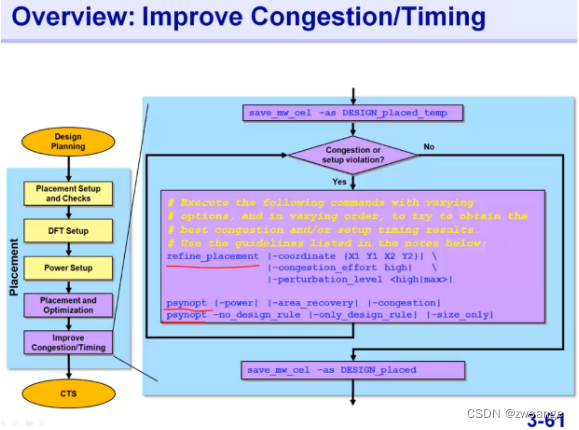
如果到这一步还是有congestion/timinge问题,那么到这里还有以哦那个方法让工具还优化,但说实在的,如果前面没解决的问题,这里大概率也解决不了;
主要的command是”refine_placement“,后面可以跟着psynopt;
refine_placement and psynopt


refine_placement执行的是一种渐进式的placement来优化congestion,但同时可能会degrade timing;因此后面一般跟一步psynopt命令来优化一下时序;
Psynopt命令也是渐进式的优化timing,不用取消前面的结果,可以多次使用,同时也可以加一些其他的参数来实现额外的效果;
Summay:imprrove congestion and setup timing
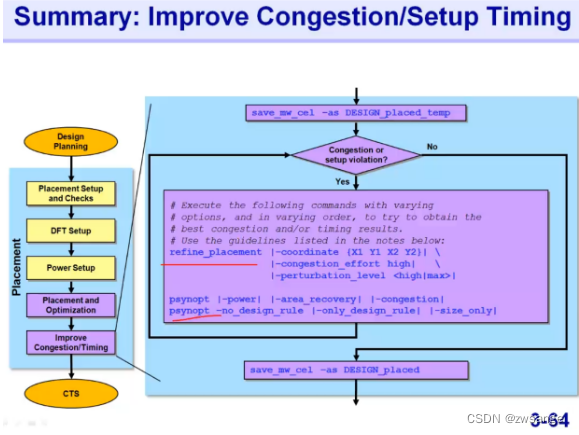
summary;
更多自定义控制设置
Buffer trees

自定义Buffer Trees设置

前面提过,工具在解决AHFS时使用的办法就是加buffe,但这些buffer tree可能插的并不好,在place_opt后我们可以分析一下buffer tree,如果工具自己做的不好,我们可以先移除,然后创建自定义的buffe tree;另外,也可以向下面的方法创建;
Build skew-optimized buffe trees

AHFS的buffer tree,我们可以在做place之前,先将network设置为ideal状态,不考虑其延时;然后进行place_opt;完成后,在把ideal状态移除,在进行compile_clock_tree -HFN;
Relative placemeent

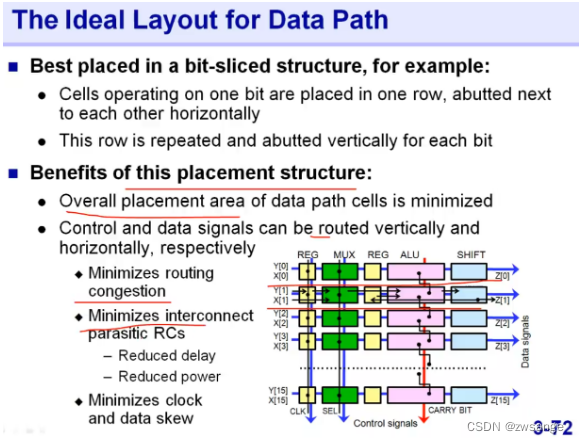
对于一些很规整的计算单元结构,如上图的data path电路,可以使用Relative placemeent方法来进行placement,可以降低congestion/RCs/data skew等;
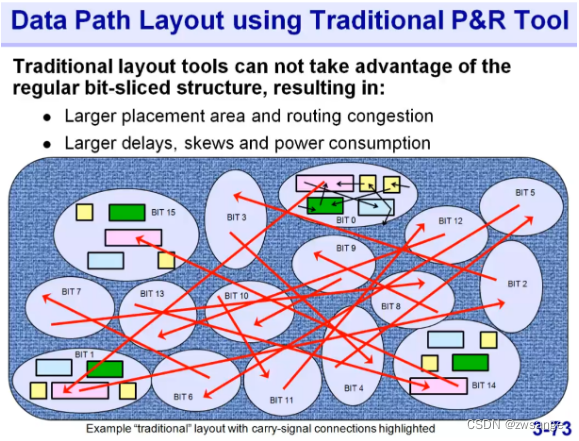
传统的PR tool在摆放的时候是很杂乱无章的;
传统的解决方法:

针对上述的问题,传统的解决方案基本就是当作hard macro,然后人工进行place,需要消耗大量的时间;
ICC解决方法:Relative placement

ICC工具在摆放时,可以将相关的data path定义为多个relative placement group--RP,然后ICC就会摆放的很规整;这一步需要在TCL的约束中加进去;
RP的特点与优势

RP可以和std cell一起进行place,对多方面均有优势,如上图;
RP的适用范围

使用范围通常是一些纯计算的data path/RAM/FIFO等,如上图;

一些参考文献;
全章总结
















 1087
1087











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









