







 本文介绍了一种融合CNN与Transformer的双分支网络模型MDFF-Net,该模型利用ResNet提取局部特征,并借助Transformer捕捉全局特征,通过多层级特征融合提高乳腺癌病理图像分类准确性。
本文介绍了一种融合CNN与Transformer的双分支网络模型MDFF-Net,该模型利用ResNet提取局部特征,并借助Transformer捕捉全局特征,通过多层级特征融合提高乳腺癌病理图像分类准确性。
现有的乳腺癌病理图像深度学习分类研究多是依托卷积神经网络(convolutional neural networks,CNN),利用 CNN 强大特征提取能力来提升乳腺癌病理图像分类精度在研究工作早期,主要是将在大规模自然图像 数据集上的预训练 CNN 模型作为特征提取器来捕获病理图像深度特征,采用传统机器学习模型构造分类器对深度特征分类。其中,ZEROUAOUI等人探索了多个 CNN 模型和机器学习分类器的结合研究,结果表明使用预训练的DenseNet201 和多层感知器模型可获得最佳性能。考虑到两阶段深度学习方法割裂了图像特征与分类器间的连续性,研究者提出使用端对端 CNN 来实施乳腺癌病理图像分类,借鉴典型 CNN 架构与单元来构造模型,并使用有标 签的乳腺癌病理图像来训练模型,迁移学习技术也常被用来提高网络模型的稳定性和泛化性。
CNN 方法在乳腺癌病理图像分类任务上已取得较好成果,但也存在局部感受野受限的缺陷,缺乏对乳腺癌病理图像整体信息的更有效提取能力。
Transformer模型
Transformer模型通过自注意力机制来有效地挖掘序列间长距离依赖关系,体现出较强的全局建模能力。
DecT(deconv-transformer)
此模型用于乳腺癌组织病理学图像分类,所提出的模型主要使用Transformer架构替换卷积层更好地匹配颜色进行反卷积,并将训练过程分为两个阶段,为反卷积层找到更多的最优参数,使其能够更好地适应组织病理图像。
Transformer的自注意力机制能够有效捕捉图像的全局特征,但是需要在大规模数据集上训练才能更好地发挥作用。
多层级深度特征融合的双分支网络模型(MDFF-Net)
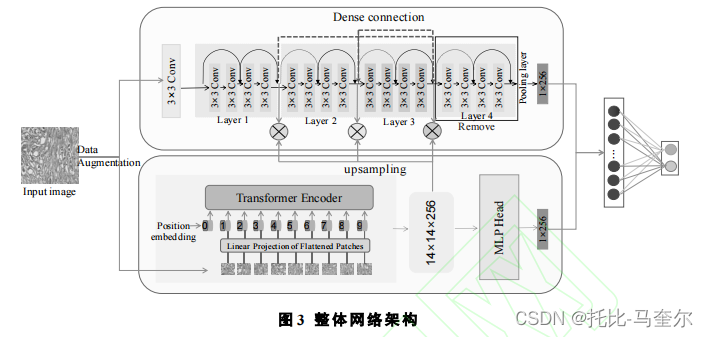
将CNN的局部特征提取能力和Transformer的全局特征建模优势充分结合;
一条支流采用具有残差结构的ResNet网络架构来提取病理图像的局部相应特征;
另一条支流则采用Transformer长距离依赖性来捕获病理图像的全局鲁棒特征表达。
模型在双分支的内部和外部均进行特征融合操作,此外还引入密集连接操作来更好保持融合特征的信息传输,从而以全局-局部相补充的方式来加强其判别性特征提取能力。
残差连接
随着网络层数的加深,模型容易产生梯度消失或梯度爆炸等问题。引入残差网络可以有效缓解网络退化,加速网络的收敛。ResNet最核心的思想是采用残差网络,通过残差结构的堆叠来保障加深网络层数的同时获取更多有效特征。
残差网络是指在网络结构中相邻层间增加了残差连接,从而解决随着网络层数增加可能引起的梯度问题。
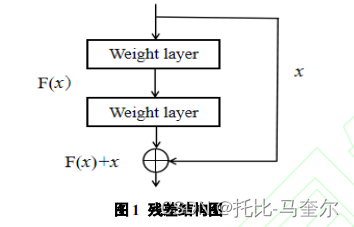
其中,F(x)为待学习的残差映射,当F(x)= 0时,即为恒等映射。“残差”相当于学习H(x)- x 部分,随着网络层次的加深,不断将残差结果逼近于0,使得层数增加的同时模型效果也越好。
残差连接主要以改善梯度问题为出发点来提升模型训练能力,它是建立在两个相邻卷积层间的连接。
密集连接
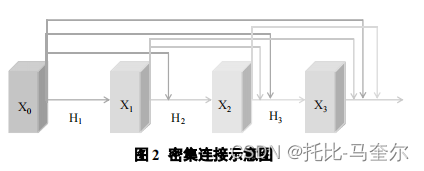
建立每一层网络与其他所有层间的特征交互,通过特征在通道维度上的连接实现特征重用,进而促进不同层间的信息交流。
网络包括 层,
是非线性转化函数,
表示的是第
层的输出,第
层接收到的是前面所有层的特征映射。
指的是从第0层到第
层产生特征映射的连接。密集连接不仅缓解了梯度消失问题,还能够加强特征传播,鼓励特征重用。通过当前层与网络中每一层特征进行交互的方式丰富了模型提取的信息,加速网络训练的同时进一步促进了模型提取辨别性特征的能力,有助于提升后续图像分类等任务的实验结果。
Transformer
Transformer支流采用的是Deit-B模型结构。首先,由于图像具有二维信息,而Transformer的输入维度为一维,对于给定的图像输入,需要先将其进行切片操作,以获取N个小的不重叠补丁图像。将这些小的补丁图像作为视觉标记,通过线性编码函数映射为一维的序列送入到以Transformer思想为核心的预训练微调模型 Deit-B 中。同时引入类似 ViT 中的可学习类标志并用于后续的分类。
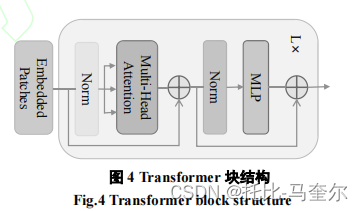
Deit-B网络包括了多头注意力和多层感知机模块(multilayer perceptron, MLP),多头自注意力用于获取输入序列的全局信息,MLP包含两个完全连接层,并在第一个全连接层之后采用非线性激活函数。Transformer块分别在每个多头注意力模块前后应用归一化操作和残差连接。
Deit-B模型是由包含L个Transformer块的编码模块组成的,块的堆叠使得送入Transformer支流的图像特征能够被有效捕获,对后续的图像分类任务起到了重要作用。
特征融合
CNN支流采用具有残差结构的ResNet-18作为基础模型,并移除最后一个残差模块对其进行微调以应用于后续的融合。两条支流末端均输出具有相同空间分辨率(14*14)的特征图,再分别对两条支流的输出采用池化操作和MLP(多层感知机)头操作获得相同的通道数(256),最终通过Concat操作融合CNN与Transformer的输出向量以获得全局特征表示。
ResNet-18中每一个残差块的输出均与Transformer的输出向量进行二次融合,通过及时将Transformer编码模块的输出信息反馈到 ResNet 中间层来增强CNN支流提取特征的辨别能力,促进两条支流的信息交互。MDFF-Net 结构还对ResNet的每一个残差块进行密集连接,通过密集连接的方式来获取ResNet每一层与其他层之间的信息交互,促使当前层提取到全部前馈特征信息。
评价指标
图像级识别率是从图像角度判断所有图像中分类正确的图片所占比例,但是图像级识别率忽略了患者信息的因素。为了考虑患者间的差异性(医疗图像特有的评价指标),患者级分类识别率计算公式
其中,表示为测试集中命名为p的患者乳腺癌组织病理图像的总数,
为将其正确分类的样本数,N为患者总数。
自注意力机制
在特征提取过程中,自注意力机制能够聚合输入特征的全局信息来更新序列的每个视觉标记,从而获取具有远距离依赖性的全局响应特征。
使用维度为S的输入向量X,根据每个特征值的上下文信息进行编码:
、
、
其中,X是输入的特征图,是三个独立线性投影层的可学习权重,D是投影维度。通过内积计算获取的矩阵 A 代表 QK 之间的成对相似度矩阵,同时对V进行加权平均得到QV之间信息交互
自注意力的输出:
在SA中,矩阵A可以匹配输入向量的接近程度,softmax操作则对所有计算关系进行归一化,从而获得注意力分数。最终序列中的各个元素均包含所有特征向量的加权和,其中权重从注意力分数中获得。
自注意力模型可以看作为在一个线性投影空间内以不同形式构建输入向量的交互关系
多头注意力就是在多个不同的投影空间中建立不同的投影信息。 具体而言,包含 h 个独立自注意力的多头自注意力机制首先连接所有 SA,然后投影它们得到最终输出:
其中是投影矩阵,d是D/h是MSA中SA的维数

















 1857
1857

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









