








基于深度学习的目标检测和语义分割算法综述
0 引言
目标检测一直是计算机视觉领域的研究热点,无论是在日常生活,还是在工业生产领域都有广泛的应用,近年来取得了许多进展。
本文从一个新颖的角度归类综述了近些年目标检测领域的经典算法。在将其分为基于候选区域和基于回归两大类的前提下,对基于候选区域的目标检测算法,介绍R-CNN系列算法的发展史后,根据对不同模块的改进研究进行归类综述:特征提取网络、ROI Pooling 层、区域提取网络RPN、非极大值抑制(Non Maximum Suppression,NMS[1])。对基于回归的目标检测算法,介绍YOLO系列和SSD算法后,对基于SSD算法的改进研究进行细分论述:基于Anchor-based的改进研究和基于Anchor-free的改进研究。
图像语义分割技术是指根据图像的灰度、色彩、纹理等特征,为图像中的每个像素分配单独的类别标签,使图像被分割成若干视觉意义上的特定的、具有独特性质的区。随着智能化生活的推进,语义分割技术在无人驾驶、医学图像处理、视频监控,甚至是虚拟交互、增强现实等领域都发挥着日益重要的作用。
随着硬件性能的升级和深度学习的兴起,深度卷积神经网络强大的分析与处理能力日益突出,基于深度学习的语义分割方法成为主流。
本文系统性地总结了近些年来基于深度学习的目标检测和语义分割算法研究,并根据不同的侧重点将这些算法进行归类综述,同时分析相关算法的优缺点,梳理算法的发展脉络,然后再详细介绍了目标检测领域流行的常用数据集,最后预测了目标检测和语义分割领域未来的热点发展方向。如图1所示为本文主要内容的逻辑框架。
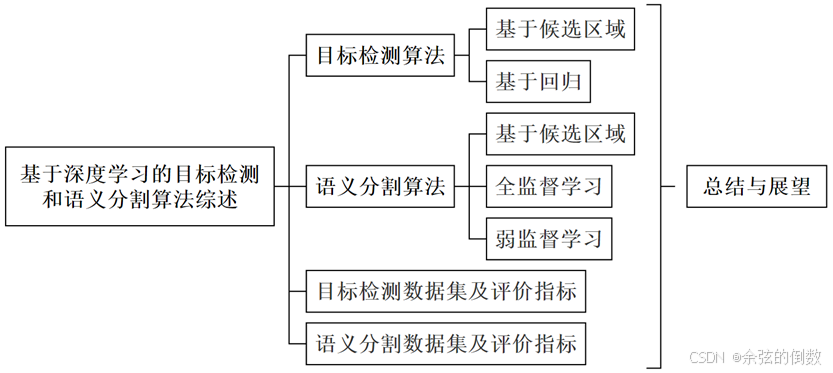
图1 全文逻辑框架
1 目标检测算法综述
目标检测算法因卷积神经网络的加入而注入活力,如图2所示为经典目标检测算法的发展脉络图。
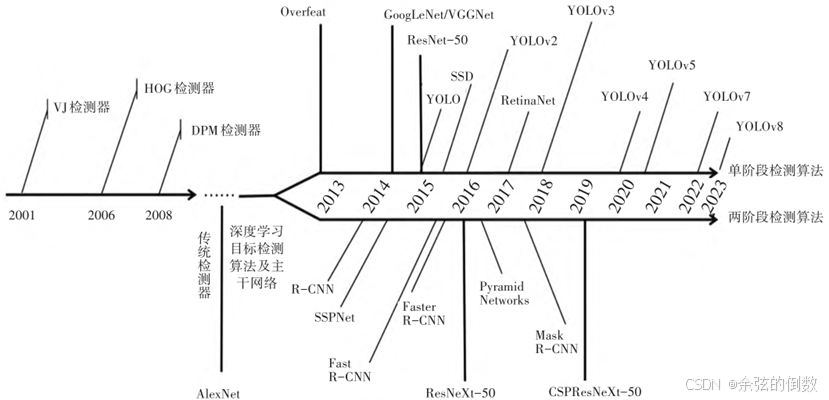
图2 经典目标检测算法的发展脉络图
1.1 基于候选区域的目标检测算法
本节主要将近年来基于候选区域的目标检测算法分为五个部分进行综述,首先介绍了Faster R-CNN[2]框架的发展历程,然后综述了对Faster R-CNN算法的四个重要组成部分(特征提取网络、ROI Pooling层、RPN、NMS算法)的改进研究。
1.1.1 R-CNN系列框架的发展现状
自从2012年卷积神经网络(Convolutional Neural Networks,CNN)[32]在图像分类任务中取得突破性的进展,研究者们开始将卷积神经网络迁移到目标检测领域,2014年,Girshick等人[3]成功将CNN运用在目标检测领域中,提出了R-CNN模型,它将AlexNet与选择性搜索(Selective Search)算法相结合,开启了目标检测领域的新篇章。
R-CNN算法将目标检测任务分解为若干个独立的步骤(如图3所示),包括:1)候选区域的提取,利用选择性搜索算法从每张待检测图像中提取2000个可能包含目标的候选区域。2)候选区域大小归一化,将所有提取的候选区域缩放成固定大小,用来作为模型中卷积神经网络的输入。3)候选区域的特征提取,通过在ImageNet数据集上预训练过的卷积神经网络提取候选区域的图像特征。4)特征的分类与区域的回归,利用SVM对提取到的区域特征进行分类识别,同时用线性回归来微调检测框的位置与大小,每个类别需要单独训练一个分类器和一个边界框回归器。
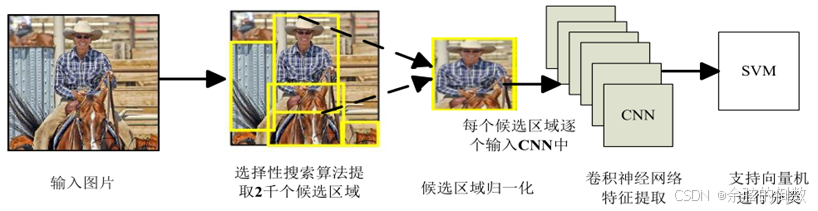
图3 R-CNN算法
R-CNN[3]算法在PASCAL VOC2007数据集上的检测精度达到了58.5%,相较于传统的目标检测算法取得了跨越性的进展。但还存在非常多的改进空间,如:对于单张图像提取的2000个候选区域需要逐个输入CNN中,导致计算开销十分巨大,严重影响了检测速度;而且候选区域输入CNN前,必须剪裁或缩放至固定大小,这会使候选区域发生形变且丢失较多的信息,导致网络检测精度下降。
2014年He等人[4]提出了SPP-Net检测算法,它在CNN最后一层卷积层和全连接层之间加入SPP层(如图4所示),使得网络能够输入任意尺度的候选区域,从而每张输入图片只需一次CNN运算,就能得到所有候选区域的特征,这使得计算量大大减少。SPP-Net的检测速率比R-CNN快了24~102倍,并打破了固定尺寸输入的束缚。
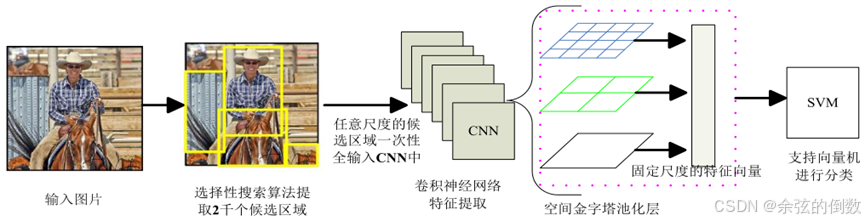
图4 空间金字塔网络结构
Girshick等人受到了SPP-Net算法的启发,在2015年提出了Fast R-CNN[5]算法(如图5所示),首先通过感兴趣区域映射得到每个候选区域的特征,然后通过感兴趣区域池化(ROI Pooling)层以统一候选区域特征的大小,与SPP层不同的是,ROI Pooling使用单尺度对候选区域进行划分和池化,简化了网络结构。最后将全连接层的输出作奇异值分解(Singular Value Decomposition,SVD),得到两个输出向量:softmax的分类得分以及边界框(Bounding Box)的位置坐标偏移量。相较于R-CNN和 SPP-Net,Fast R-CNN提出了多任务损失函数思想,将分类损失和边界框回归损失结合统一训练学习,使得分类和定位任务不仅可以共享卷积特征,还可以相互促进提升检测效果。
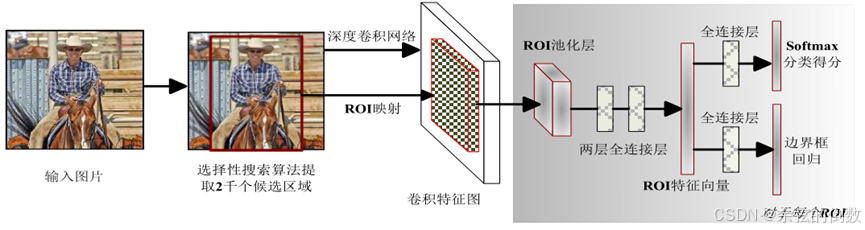
图5 Fast R-CNN算法
虽然Fast R-CNN有效地加快了检测速率,但依旧采用选择性搜索算法来产生候选区域,这极大限制了模型的检测效率。因此,2015年Ren等人[6]提出了Faster R-CNN算法框架(结构如图6所示),设计了辅助生成样本的RPN取代选择性搜索算法。RPN是一种全卷积神经网络(Fully Convolutional Network,FCN)结构,它将任意大小的特征图作为输入,并通过卷积操作生成大量的目标可能存在的候选区域,使算法实现了端到端的训练,极大提高了检测速度。
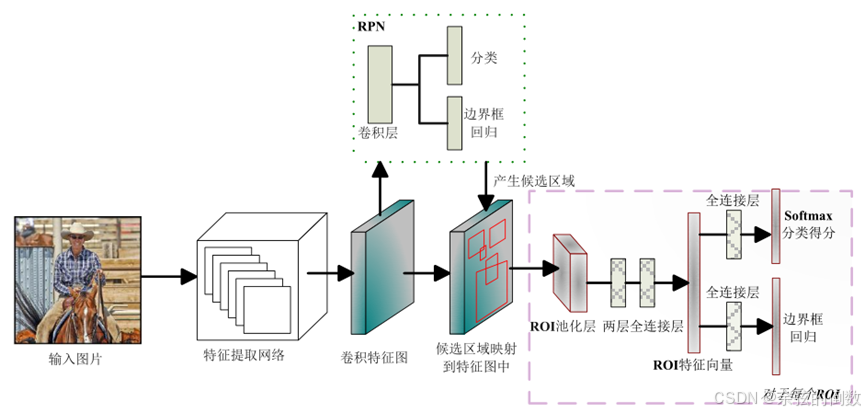
图6 Faster R-CNN算法
1.1.2 基于Faster R-CNN特征提取网络的改进研究
2016年Kong等人[7]提出了超网络(HyperNet),通过融合多层卷积层的特征图,得到具有多尺度信息的超特征(Hyper Feature)。超特征结合了卷积层高层的强语义信息、中层的辅助信息以及浅层的几何信息,从而提高了小物体检测的准确率。图7给出了HyerNet的结构。
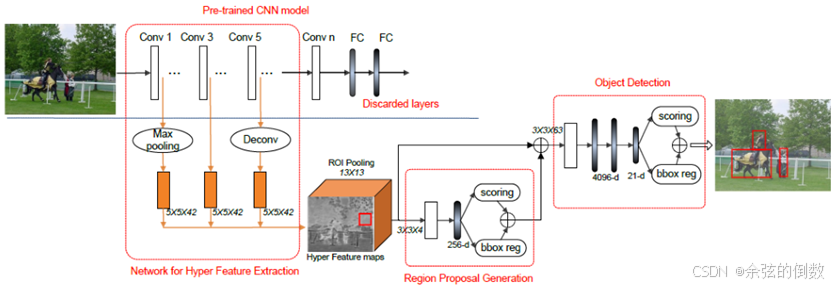
图7 HyerNet的结构
2017年Tsung-Yi Lin等人[8]提出了特征金字塔网络(Feature Pyramid Network, FPN),它使用了ResNet101作为特征提取网络,在此基础上构造了一种自顶向下带有横向连接的层次结构,来产生各个尺度的高层语义特征,并对各个尺度的特征进行单独的预测。
2018年Bharat等人[9]提出了图像金字塔的尺度归一化方法(Scale Normalization for Image Pyramids,SNIP)用于提高小目标检测性能。如图8所示,他们借鉴了多尺度训练思想,使用图像金字塔网络将图像生成三种不同分辨率的输入图像,高分辨率图像只用于小目标检测,中等分辨率图像只进行中等目标检测,低分辨率图像只进行大目标检测。
图8 SNIP网络结构
1.1.3 基于Faster R-CNN感兴趣区域池化层的改进研究
ROI Pooling,即感兴趣区域池化是将感兴趣区域对应的特征图划分成固定数量的空间小块,再对每个空间小块进行最大池化或者平均池化操作,这样就实现了不同尺度的感兴趣区域能够输出同样大小的特征图。近年来的改进研究旨在更好保留或融合空间位置信息到感兴趣区域池化操作中,以提高检测效果。
2016年Dai等人[10]提出了基于区域的全卷积神经网络(Region-based Fully Convolutional Network,RFCN)目标检测算法,提出了位置敏感分数图模块(position sensitive score map),编码每个感兴趣区域的相对空间位置信息,在此基础上进行感兴趣区域池化,使得特征具有了对位置的敏感性,从而提高了检测网络的定位准确度。在此基础上,Zhu等人[11]提出了CoupleNet算法,它将RPN产生的候选区域送入两个分支组成的耦合模块中,一个分支采用位置敏感ROI池化操作获取对象的局部信息,另一分支则使用两个ROI池化操作分别获取对象的全局信息和上下文信息,然后有效的结合候选区域的局部信息、全局信息和上下文信息进行检测。
1.1.4 基于Faster R-CNN区域提取网络的改进研究
区域提取网络(Region Proposals Network,RPN)是Faster R-CNN算法的主要创新点,它将特征提取网络提取到的图像特征作为输入,然后基于Anchor机制输出一系列候选矩形目标区域。
2016年,Yang等人[12]提出了CRAFT算法。他们认为RPN 会产生大量属于背景的候选区域,从而导致误定位和误分类问题,所以在RPN后面添加了一个二类检测网络Fast R-CNN来区分真实物体和背景,对RPN输出的一系列候选区域进行筛选,留下一些优质的候选区域,从而提高检测性能。
2018年,Chen等人[13]提出了Context Refinement方法,在RPN阶段引入上下文信息对候选区域进行微调。对于每个候选区域,挑选其附近的具有有益上下文信息的区域特征作为其上下文特征。然后结合候选区域的卷积特征和它的上下文特征来微调候选区域的位置,从而有效提高了网络检测性能。
RPN 网络中的Anchor 机制需要预先人工设定尺度大小和长宽比等超参数。针对这个问题,2019年,Wang 等人[14]提出了Guided-Anchoring方法,旨在通过图像特征来指导Anchor的生成。
1.1.5 基于Faster R-CNN的NMS的改进研究
在目标检测任务中,非极大值抑制算法[15]是必不可少的一部分,它的作用是去除冗余的检测框。首先人工设定一个IOU阈值,将同一类的所有检测框按照分类置信度排序,选取分类置信度得分最高的检测结果,去除那些与之IOU值超过阈值的相邻结果,使网络模型在召回率和精度之间取得较好的平衡。
2018年,Jiang等人提出了IOU-guided NMS[16]方法。他们将预测的检测框与真值间的IOU值作为定位置信度,每一类根据定位置信度进行排序,去除那些与最高定位置信度检测框的IOU值大于阈值的检测框,同时将这些重叠检测框的最高分类置信度值作为未删除检测框的分类置信度,从而改进了NMS过程,保留了定位更准确的检测框。
1.2 基于回归的目标检测算法综述
基于回归的目标检测算法不需要候选区域生成分支,直接将检测问题转换成回归问题,即给定输入图像,直接在图像的多个位置回归出目标的候选框和类别。本章将分成两大系列来综述基于回归的目标检测算法: YOLO[17]系列和SSD[18]系列。
1.2.1 YOLO系列目标检测算法
2015 年 Redmon等人[17]提出了YOLO算法,延续了OverFeat算法思想,将分类、定位、检测功能融合在一个网络当中,输入图像只需要经过一次网络计算,就可以直接得到图像中目标的边界框和类别概率。如图9所示为YOLO算法结构图。
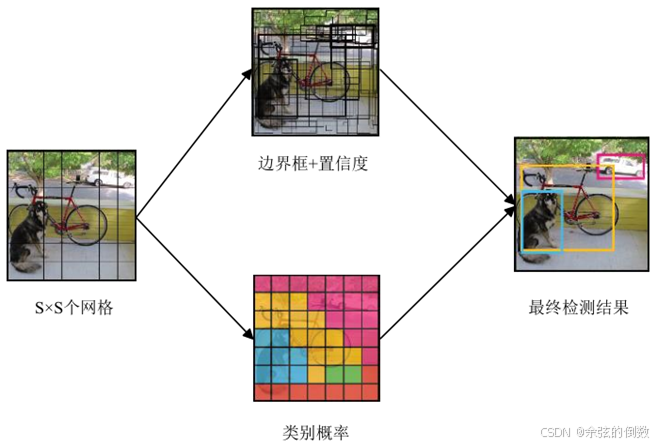
图9 YOLO算法结构
YOLO算法完全舍弃了候选区域生成步骤,极大提高了检测速率,达到了45FPS,能满足实时目标检测的速度要求,但由于其网络设计比较粗糙,在 Pascal VOC2007数据集上的检测精度只有63.4%,达不到实时目标检测的精度要求,而且YOLO算法存在目标不能精准定位、容易漏检、小目标和多目标检测效果不好等问题。
2017年 Redmon等人[19]提出了YOLOv2算法,对YOLO算法进行了一系列改进,重点解决召回率低和定位精度差的问题。YOLOv2借鉴了Faster R-CNN算法的RPN 网络,移除了网络中的全连接层,使用卷积层预测检测框的位置偏移量和类别信息,使得网络对不同尺度图像具有更好的鲁棒性。
2018年Redmon等人提出了YOLOv3算法[20],它在 YOLO系列算法基础上引入了一些提升网络性能的方案,在保持检测速度优势的前提下,提升检测精度,并且提高了对小目标的检测能力。为了处理多尺度目标,YOLOv3采用了3种不同尺度的特征图来进行目标检测,每个特征图都是高层与浅层特征图融合所得。
文献[21]在2020年对YOLOv3进行改进,提出了YOLOv4。该算法将框架分为输入端、Back-bone,Neck 和 Head 四部分,Neck部分采用SPP和PAN模块进行特征融合,使用CutMix和Mosaic数据增强以及DropBlock正则化,减少过拟合问题,提高泛化能力,引入缩放系数,提高了准确率,优化不同目标尺度的Anchor,采用CIoU定位损失。
文献[22]提出了YOLOv5,输入端使用Mosaic数据增强,同时减少GPU的使用个数,采用自适应缩放将图片的大小统一固定为一个合适的尺寸, Backbone部分采用New CSP-Darknet53模型,Neck部分采用了FPN和 PAN模块,两者结合增强了多尺度的语言表达和强定位信息,Prediction部分定位损失采用了GIoU_Loss损失函数。该算法在检测速度方面有了很大的提升,是YOLOv4 的2倍多﹐体积也小,比YOLOv4小了90%左右。
文献[23]在2021年提出了YOLOX,其输入部分是采用Mosaic和 Mixup进行数据增强,Neck部分采用FPN进行特征融合,Prediction部分采用3个Decoupled Head 提高精度和加快收敛速度,采用Anchor-free 减少参数量,进行标签分配时,首先根据中心点和目标框进行初步筛选正样本操作,再用SimOTA进行精细化筛选,使用损失函数计算目标框和正样本预测框之间的误差。
1.2.2 SSD系列目标检测算法
1.2.2.1 SSD算法
2016年Liu等人[18]提出了SSD算法,在YOLO算法回归思想的基础上,有效结合多尺度检测的思想,提取多个不同尺度的特征图进行检测,遵循较大的特征图用来检测相对较小的目标,较小的特征图检测较大目标的策略,显著提高了对大目标的检测效果。如图10所示,SSD网络是基于全卷积网络结构,它将基础网络VGG的全连接层替换为了卷积层,同时在VGG16网络末端添加了几个使特征图尺寸逐渐减小的辅助性卷积层, 用于提取不同尺度的特征图,并直接采用卷积操作对不同尺度的特征图进行检测。
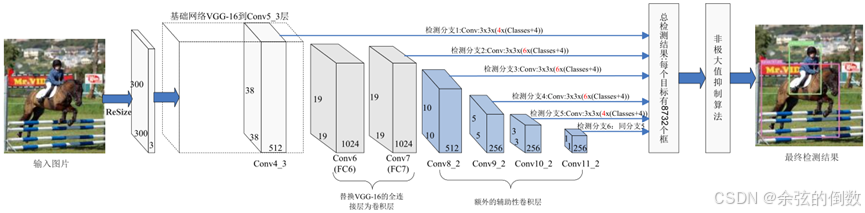
图10 SSD算法网络结构
1.2.2.2 基于Anchor-based方式的改进
2017年Jisoo Jeong 等人[24]提出了RSSD算法,其在SSD 算法的基础上,对提取的不同尺度的特征采用了特殊的特征融合方式:对于每个特定的尺度特征,分别将比其大的尺度特征进行池化操作,比其小的尺度特征进行反卷积操作,然后将这些特征进行串接融合形成新的特定尺度特征。这种融合方式使得每个尺度的特征都具有其他尺度的信息,增加了不同层特征图之间的联系,避免了同一目标重复检测的问题。
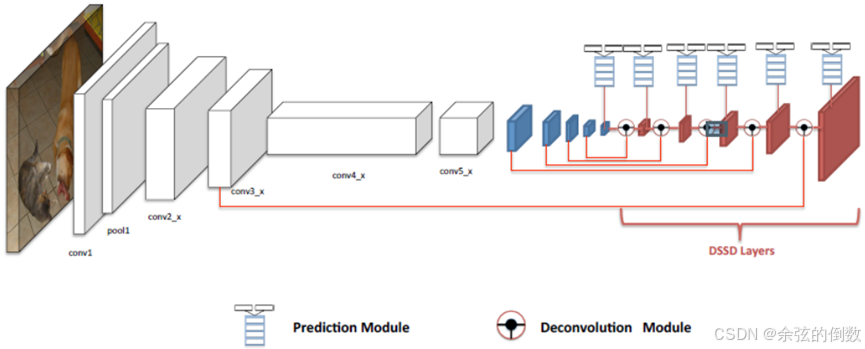
图11 DSSD算法结构
同年,Cheng等人[25]提出了DSSD算法(模型结构如图11所示),它将SSD算法的基础网络VGG16替换为了ResNet101,增强了网络特征提取能力,而且为了提升检测的精度,DSSD算法设计了两个特殊的模块:预测模块和反卷积模块。预测模块通过跳跃连接实现不同层特征之间的融合,从而提高特征的表征能力,DSSD算法在每个检测分支都使用预测模块,用于提升每个子网络的准确度,从而提升整个网络的准确度。但由于使用的ResNet101网络太深,并且增加了许多反卷积操作,加大了网络计算量,检测速度有较大牺牲。在此基础上,Lin等人[26]提出了RetinaNet算法,虽然网络的设计与 DSSD类似,都采用了FPN结构,但它针对SSD算法因密集采样导致的难易样本严重失衡问题,提出了Focal Loss,该损失函数是在交叉嫡损失函数的基础上添加了两个平衡因子,抑制了简单样本的梯度,将更多的注意力放在难分的样本上,大幅度提升了检测性能。
2018年Liu等人[27]提出了RFB-Net算法,通过模拟人类视觉感受野,设计了通用的感受野模块(Receptive Field Block,RFB),目的是增加网络的特征提取能力。RFB结构引入了三个不同扩张率的3×3扩张卷积层,从而有效地增大了卷积层的感受野,并且将这三个卷积的输出以串接方式进行特征融合。
1.2.2.3 基于Anchor-free方式的改进
2018年,Law等人[28]提出了CornerNet算法,直接通过预测物体的左上角点和右下角点来得到检测框。如图12所示,借鉴人体姿态估计任务中对关键点检测的 Bottom-Up思想,采用了Hourglass104网络作为特征提取网络,然后分别预测图像中所有目标左上角点和右下角点信息。为了利于角点的定位,设计了corner pooling操作:对每个通道,分别提取特征图对应位置处水平和垂直方向的最大值,然后进行求和,使得每个角点更聚焦于物体的边缘信息。
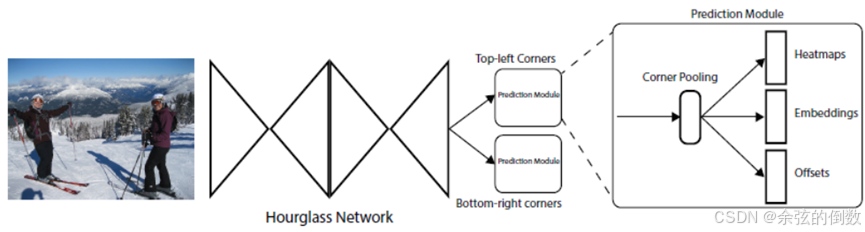
图12 CornerNet算法网络结构
在 CornerNet算法的基础上,2019年,Zhou等人[29]提出了ExtremeNet 算法,在关键点选取和关键点组合方式上做出了创新。ExtremeNet选取物体上下左右四个极值点和一个中心点作为关键点,更加直接关注物体边缘和内部信息,使得检测更加稳定。
2019年,Tian等人[30]提出了基于全卷积的一级目标检测器(Fully Convolutional One-Stage object detection,FCOS) ,借鉴语义分割任务的思想,采用逐像素预测方式解决目标检测问题,完全避免了与Anchor 相关的复杂计算和超参数设计, FCOS算法采用FPN结构实现多尺度目标的预测,而且每个预测分支中添加了中心点损失来抑制中心点偏差大的检测框,保证每个检测框尽可能靠近目标中心,提高了模型定位能力。
2 语义分割算法综述
目前,基于深度学习的图像语义分割方法有很多种,从方法特点上可分为3类:基于候选区域的图像语义分割方法、全监督学习图像语义分割方法和弱监督学习图像语义分割方法。
2.1 基于候选区域的图像语义分割方法
基于候选区域的图像语义分割法由Carrerira等人首次提出,该方法先是利用区域生成算法在图像中生成一系列自由格式的候选区域(其中的每个候选区域都有可能包含潜在的目标物体),并利用卷积神经网络(Convolutional Neural Network,CNN)对候选区域的图像特征和语义信息进行提取,再对这些区域进行分类,之后把关于分类区域的预测转化成关于像素的预测,像素得分最高的区域即可进行标签。
Carrerira等人运用CPMC ( Constrained Parametric Min Cut)[31]算法来生成候选区域,并计算候选区域属于某类标签的概率大小,从而得出分割结果。于此之上,Carrerira等人将SOP(Second-Order-Pooling)算法应用在了特征提取阶段(SOP算法能够将区域的局部特征进行聚合),进一步提高了分割精度。
之前的工作均是在RCNN网络的基础上进行的,鉴于RCNN有网络运算量大、产生的候选区域太多、生成速度慢以及生成的形状不统一等等不足,一些学者提出了Fast-RCNN算法[5]。Fast-RCNN网络将候选区域映射到卷积神经网络的特征图上,利用ROI池化层产生固定大小的特征图,候选区域的生成速度有了显著提升。Ren等人提出了Faster-RCNN网络[6],其利用区域建议网络(region proposal network,RPN)来快速生成候选区域,所产生的候选区域可以与检测网络共享卷积特征,对候选区域的产生速度和分割精度有了显著提升,缺点是对候选区域中的感兴趣区域不够敏感。Caesar等人(2016)以 Fast-RCNN为基础提出基于区域的端到端图像语义分割算法,着重考虑了候选区域的感兴趣区域,通过自由形式的池化层捕捉其前景特征,兼顾上下文语境信息和区域的自由表示,可以更鲁棒的处理分割任务。
总体来说,基于候选区域的图像语义分割方法具有以下优缺点。优点为:使用目标检测技术生成候选区域,可以同时完成目标检测任务和语义分割任务。缺点为:分割过程对候选区域过于依赖;不能充分地考虑图像中的全局语义信息,分割图像中的小物体或小面积区域时效果不理想。
2.2 全监督学习图像语义分割方法
基于深度学习的语义分割方法大多是全监督学习模型。全监督学习图像语义分割方法即采用人工提前标注过的像素作为训练样本,语义分割过程为:1)人工标注数据,即给图像的每个像素预先设定一个语义标签;2)运用已标注的数据训练神经网络;3)语义分割。人工标注的像素可以提供大量的细节语义信息和局部特征,以便高效精准地训练网络。全监督语义分割方法大多是在全卷积网络的基础上衍生出来的,可按照其改进特点分为下面几类,如表1所示。
表1 全监督学习语义分割方法

(1)FCN算法。Long等人(2015)[32]提出了全卷积网络(Fully Convolutional Network,FCN),它以全监督学习的方式分割图像,输入图像的大小不受限制,能够实现端到端的像素级预测任务。网络结构图如图13所示﹐FCN将VGG-16 (Visual Geometry Group 16-layer network)算法的全连接层替换为卷积层。一幅RGB图像输入卷积神经网络之后,进行一系列的卷积和池化操作提取特征图,再通过反卷积层对特征图进行上采样处理,最后进行像素分类并把粗粒度的分割结果转换成细粒度分割结果。FCN成功地将图像分类网络拓展为语义分割网络,可以在较抽象的特征中标记像素的类别,对图像语义分割领域做出了卓越贡献,但是仍面临着3方面的挑战:池化层会使得特征图的分辨率下降,也会导致某些像素的位置信息损失;上采样处理会使得结果模糊,不能很好地理解图像的细节信息;分割过程离散,不能充分地考虑像素上下文语义信息,故无论是局部特征还是全局特征利用率均不高。
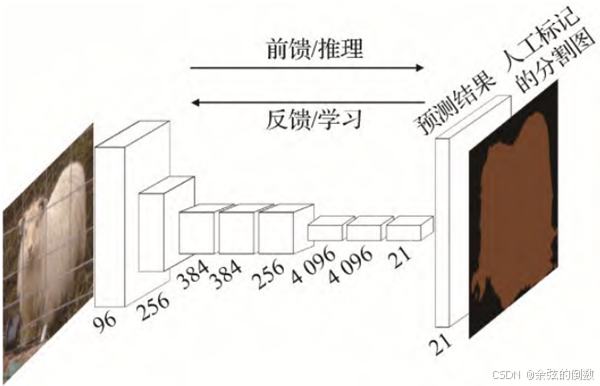
图13 FCN网络结构
(2)基于全卷积的扩张语义分割算法。由于全卷积网络存在上述问题,Google在2014年提出了扩张语义分割算法,其能够扩大感受野并且不增加参数量,代表算法有DeepLab-V1[33]、DeepLab-V2[34]、DeepLab-V3[35]和DeepLab-V3+[36]。
Chen和Kokkinos(2014)把卷积神经网络与概率图级联而成了DeepLab-V1[33]网络,在全卷积网络的末端加入了FCCRF(Fully Connected Conditional Random Field),FCCRF可以对粗粒度分割图进行边界优化,同时加入了带孔卷积来增大特征图的感受野。图14为DeepLab-V1的处理流程。DeepLab-V1 网络在PASCAL VOC 2012数据集上的语义分割指标平均交并比(mean intersection over union,mloU)达到71.6%。
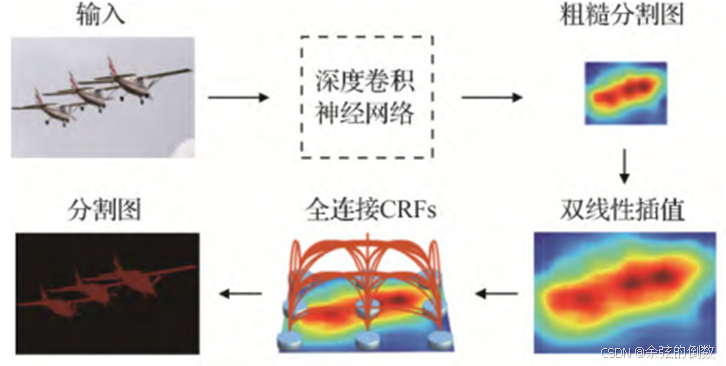
图14 DeepLab-V1的处理流程
Chen等人(2018a)改进了DeepLab-V1网络特征图分辨率下降﹑不能准确定位等问题,提出了DeepLab-V2网络[34]。该算法通过带孔卷积作为上采样滤波器用来提取特征,并且结合空间金字塔池化(Spatial Pyramid Pooling)提出ASPP (Atrous Spatial Pyramid Pooling),使得其可以更好地提取多尺度特征。DeepLab-V2网络扩大了感受野,语义分割精度有了显著提高,在PASCAL VOC 2012数据集上mloU指标达到了79.7%。
Chen等人(2018a)提出了DeepLab-V3算法[35],DeepLab-V3改变了ASPP的空间结构,先将4个带孔卷积并联成一个新的ASPP,再把多个带孔卷积和新的ASPP串联,组成一个端到端的分割网络,其可以捕捉多尺度的图像语义信息。DeepLab-V3在PASCAL VOC 2012数据集上mloU指标达到了85.7%
Chen等人(2018b)在DeepLab-V3网络结构中加入了编码—解码算法和Xception网络,从而提出了DeepLab-V3+语义分割网络[36]。其可以更好地保留分割的细粒度特征,更好地理解图像的上下文语义信息,也能够显著提升网络的分割准确度和运算速度。DeepLab-V3+网络在PASCAL VOC 2012数据集上mloU达到了89.0%。
(3)基于全卷积的对称语义分割算法。在图像语义分割领域,对称结构的语义分割网络是解决“池化处理会使得特征图分辨率会下降、部分像素空间位置语义信息缺失”问题的一类重要方法。对称结构的语义分割网络也叫做基于编码器—解码器的网络,该方法的原理是通过深度学习中的卷积、池化等步骤组成编码器来提取图像特征,然后通过反卷积、上池化等步骤组成解码器来恢复图像的一系列像素特征。
Noh等人(2015)提出的DeconvNet网络[37]为第1个对称语义分割模型,将VGG16的 softmax层换成了上池化和反卷积层,上池化能够进行目标的准确定位,并将特征图的大小还原到池化前的水平从而得到稀疏特征图,反卷积层又会把稀疏特征图转化为稠密特征图,但是该模型参数较多,运算复杂。
针对DeconvNet网络参数量太大的问题,Badri-narayanan等人(2017)提出了SegNet 网络[38]。SegNet网络的编码器部分与VGG16相同,由13个卷积层和5个池化层构成,解码器部分由9个上采样层、13个卷积层和1个softmax分类器组成。如图15所示。SegNet 网络运算简便,涉及的参数数量和占用的存储空间均较小,但是该网络是通过先验概率来进行像素点的分类,无法预测分割结果的置信度。
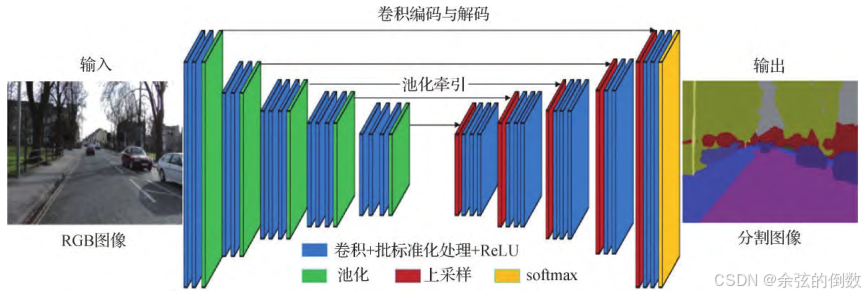
图15 SegNet网络结构
Ronneberger等人(2015)提出了专门适应生物医学图像语义分割的U-Net算法[39],该网络模型编码器部分进行下采样处理,逐渐降低特征图的分辨率,解码器部分进行上采样处理,还原图像细节信息。U-Net 网络可以通过图像切块扩充数据量,所以在训练图像较少的情况下同样具有较高的不变性和鲁棒性。U-Net网络的确有不错的分割效果,然而只适用于2D图像。
总体来说,基于全卷积的对称语义分割网络主要具有以下优缺点,优点为:还原图像的空间维度和像素的位置信息,解决池化操作后特征图分辨率降低的问题;缺点为:网络训练参数过多,计算量大,无法实现实时分割。
(4)基于特征融合的算法。特征融合的主要思想是兼顾考虑图像的高级特征、中级特征、低级特征以及全局特征﹑部分特征,通过对各层次﹑各区域特征的融合来更好地获取图像深层的上下文信息,其能够对图像的上下文信息进行整合加工,提高各种特征的利用效率,以解决之前算法运算量大,训练时间长的问题。
Liu等人(2015)首先将全局特征进行上池化处理,再将其融合到局部特征中得到图像的上下文信息。Ghiasi和 Fowlkes(2016)用拉普拉斯金字塔重构低层特征,提出了LRR (Laplacian pyramid reconstruction and refinement model)模型[40]。LRR模型将特征图表示为一组基函数的线性组合,并通过跨层方法引入边界特征,融合了低层高层特征,显著提高了分割精度。
Zhao等人(2017a)提出PSP(Pyramid Scene Parsing)网络[41],图像输入该网络之后先通过ResNet 网络和扩张网络进行预训练,预训练之后特征图的大小变为原来的1/8,再将其同时送入4个并行的池化层进行池化处理,融合4种不同尺寸的特征图,最后上采样还原特征图的大小。PSP网络处理流程如图16所示。PSP网络显著提高了语义分割精准度,其在PASCAL VOC 2012上的分割精度为85.4%。
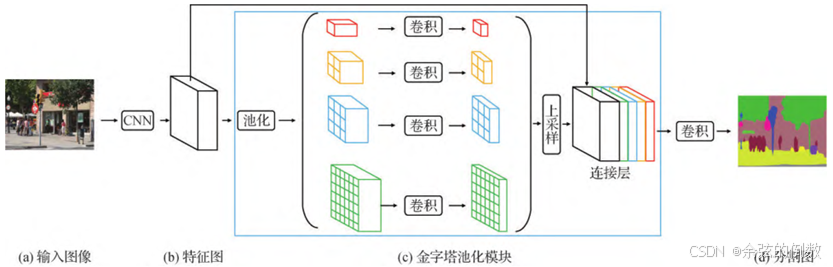
图16 PSP网络处理流程
PointRend(Kirillov等,2020)[42]是一种针对点渲染的神经网络,核心思想是将图像分割视为图像渲染,即在2D平面上表现3D物体。PointRend 网络由3个模块构成:第1个模块是关于有效点的选择,只选择物体边缘的点;第2个模块是关于点的特征表达,此模块会运用双线性插值算法推理被选点的特征;第3个模块是对点的特征进行预测。
除此之外,还有学者主张融合不同阶段提取的图像特征,例如将上一阶段提取的特征和下一阶段提取的特征进行融合。Raj等人提出了一种多尺度深度卷积神经网络,其首先将不同尺度的卷积层植入到VGG-16网络中,捕捉不同尺度的特征之后,融合上下两个阶段的特征。该网络能够捕捉到粗粒度和细粒度的特征。
(5)基于循环神经网络的算法。基于循环神经网络的语义分割模型,一般都是在卷积神经网络中加人了RNN layer,卷积层用于捕获图像的局部空间特征,RNN layer用于捕获有关像素序列的特征,很多方法用到了图像分块。图像首先通过卷积神经网络提取特征,然后将特征图传送到循环神经网络中捕获上下文信息,用RNN层序列化像素,分析像素之间的依赖关系后得到全局语义特征,最后通过反卷积上采样得到分割结果。
Visin等人( 2016)在图像分类网络ResNet的基础上,提出了ReSeg[43]语义分割体系。图像输入ReSeg网络后首先用第一层的VGG-16算法生成特征图,再将生成的特征图输入到一个或多个ResNet层进行微调,最后用基于反卷积的上采样层来恢复特征图的大小。
普通的循环神经网络序列在建模长期依赖关系时存在梯度爆炸或梯度消失的问题,于是有学者建立了长短期记忆网络(Long Short Term Memory,LSTM)[44]模型和GRUs技术来解决该问题。通过LSTM和GRUs处理图像时,保留图像的时间序列特征和高级语义信息,可以得到更好的分刮结果。Li等人(2016)同样受到ResNet网络架构的启发,提出了一种新的适应于场景标注的LSTM-CF模型,该方法使用了两个不同的数据源:RGB和depth。RGB管道依赖于DeepLab架构的一个变体,将3种不同尺度的特征连接起来丰富特征表示。
(6)基于注意力机制的算法。注意力(attention)机制主要用在自然语言处理领域(Natural Language Processing,NLP),但有研究者开始尝试将注意力机制用在语义分割上。把注意力机制融入语义分割算法,突出的贡献就是可以在大量的语义信息中捕获最关键的部分,更加高效的训练分割网络。自注意力机制模型的分割效果远远优于通道注意力机制模型。
DANet (Dual Attention Network) (Fu等,2019)[45]将ResNet(带有空洞卷积)作为主干网络,卷积后的特征图送入两个并行的自注意力网络(位置注意力网络和通道注意力网络)。位置注意力网络能够获取特征图上任意两点之间的空间依赖关系,通道注意力网络能够获取特征图上任意两个通道之间的通道依赖关系。再将经过注意力机制处理过的两幅特征图融合,最后进行分割。
HANet( Choi 等,2020)也是融入了自注意力机制的网络,其专门适应于城市场景(该类图像每行像素均含有显著差异的上下文信息)语义分割,能够捕获上下文信息,而且可以算出每行像素的注意权值。HANet也能够加入现有的分割网络。
2.3 弱监督学习图像语义分割方法
全监督学习的图像语义分割方法在图像语义分割领域占了很大的比例,卷积神经网络、全卷积网络等的应用也取得了不错的效果。但是制作像素级精确标签图像的过程成本很大,往往需要花费大量时间去进行人工标注。因此有一些学者开始研究基于弱监督学习的语义分割方法,该系列方法使用弱标注的图像训练分割模型。弱标注数据相较于像素级标注人工操作较少,比较容易获取。目前,主流的弱监督学习标注方法可分为以下4类:边界框标签、简笔标签、图像级标签和点标签。
(1)基于边界框标签的方法。边界框的标注过程需要的时间较少,该类方法的训练样本即为边框级标注图像,分割效果并不比全监督学习的语义分割方法差很多。
Dai等人(2015)以全卷积网络为基础,通过边框级标注图像训练分割器,提出了BoxSup算法[46]。该网络首先使用MGG算法候选出语义标注区域,再将语义标注区域设置为监督信息送入到全卷积网络中训练,训练之后全卷积网络会输出精度更高的标注区域,这些标注区域又会被送入全卷积网络再次训练,如此迭代至准确率收敛。Rajchl等人(2016)创立了DeepCut分割模型[47],同样用边框级标注数据集进行训练,不过是用卷积神经网络重复迭代。
(2)基于简笔标签的方法。基于简笔标注的方法,语义分割流程简洁明了,制作训练样本的成本也较低。简笔标注对图像中的不同语义画线标注即可,如图17所示。

图17 简笔标注示意图
Bearman等人提出了点监督方法,其使用随机简笔标注的点当成监督信息,并与卷积神经网络相结合,分割效果良好。Lin等人(2016a)创立了ScribbleSup网络[48],ScribbleSup能够分为两个过程:自动标记过程与图像训练过程。自动标记过程首先对图像简笔标注之后,图像训练过程再通过图模型对卷积神经网络进行训练,最后完成分割。
(3)基于图像级标签的方法。基于图像级标注的方法,其训练样本不用进行像素标注,制作成本非常低,故成为弱监督学习语义分割的主流方法。图像级标注的缺点是只标注了语义的种类信息,而对语义形状没有进行标注。
Pinheiro等人(2015)将多示例学习(Multiple Instance Learning,MIL)技术[49]引入了弱监督学习领域,MIL技术被用来构建像素语义与图像标签间的关系,其首先通过ImageNet图像级标注训练模型,然后通过卷积神经网络生成特征平面,后续处理阶段还用到了超像素和MCG等技术,显示了良好的分割结果。
Jin等人(2017)受其启发,同样通过图像标注进行监督训练,先训练浅层神经网络,之后再将不同的浅层网络合成为一个深度神经网络。其的工作在PASCAL VOC 2012数据集中进行了端到端测试,显示出良好的分割效果。
Hou等人(2017)在分割图像时将EM(Expectation Maximization)算法和卷积神经网络结合,显示出良好的分割效果。
(4)基于点标签的方法。图像级标签与点标签的不同之处仅在于点标签需要一个“点”大致标记出目标的中心位置,基于点标签的方法分割性能远远优于基于图像级标签的方法。点监督类激活图(Point Supervised Class Activation Maps, PCAM)算法(McEver等,2020)[50]通过点标签提升定位和分割能力,首先用ResNet50为基础的CNN处理点标签图像计算点监督类激活图,并生成类别标签,再对比点标签与输出的差异,更新PCAM网络的消耗。
3 目标检测数据集及评价指标
本节主要介绍在目标检测领域中具有代表性的检测数据集及评价指标。
3.1 目标检测数据集
当前通用目标检测任务中流行的数据集有:PASCAL VOC2007[51]、PASCAL VOC2012[52]、MS COCO[53]、ImageNet[54]、Open Images[55]、LIVS[56]等,其中 PASCAL VOC2007[51]、PASCAL VOC2012[52]和MS COCO[53]这三个数据集是使用最广泛的。
PASCAL VOC[51,52]数据集主要用于图像分类和目标检测任务,它包含了20个常见的类别,数据集中每张图片至少包含了一个待检测的目标,而且每张图片都有一个与之对应的XML文件标注了每个待检测目标的位置和类别。其主要流行的有PASCAL VOC2007数据集和PASCAL VOC2012数据集,前者包含了2501张训练图片、2510 张验证图片和4952张测试图片,后者包含了5717张训练图片、5823张验证图片和10991张测试图片。
MS COCO[53]数据集用于目标检测、语义分割、人体关键点检测和字幕生成等任务,对于目标检测任务,它是挑战性最大的数据集之一。该数据集中的目标大部分来自于自然场景,包含日常复杂场景的图像,而且在进行评估时使用更加严格的评估标准,要求算法具有更精确的定位能力。在MS COCO数据集中有82783张训练图片,40504张验证图片,81434张测试图片,共计超过了250万个实例。在目标检测任务中,MS COCO数据集使用JSON格式的标注文件给出每张图片中目标像素级别的分割信息,而且数据集中共包含80个对象类别的待检测目标,目标间的尺度变化大,具有较多的小目标物体。
ImageNet[54]数据集用于图像分类、目标定位、目标检测和场景分类等任务,它是根据WordNet层次结构组织的大型带标签图像数据集,包含约1420万张图片,2.2万个类别。对于目标检测任务,它是具有200个对象类别的重要数据集,每张图片的批注都以PASCAL VOC数据格式保存在XML文件中,由于ImageNet数据集规模巨大,所以不常用于评估目标检测算法的性能。
Open Images[55]数据集是具有900万张图像,并对图像分类、目标检测、视觉关系检测和实例分割等任务具有统一注释的单个数据集,对于目标检测任务,它总共包含190万张图片和针对600个对象类别的1600万个边界框,成为了具有对象位置注释的最大现有数据集。其在Open Images挑战赛中划分为170万张训练图片,41620张验证图片和125436张测试图片,并将500个常见类别用于评估检测算法性能,其中所有对象类别都具有至少100个的训练样本,70%的对象类别具有超过1000个的训练样本。
LIVS[56]数据集是2019年提出的大型实例分割数据集,包含了1000多个类别,164000张图像,220万个高质量的实例分割掩码,这是即将应用于目标检测领域的全新数据集,而且LIVS数据集中每个对象类别的训练样本很少,旨在用于目标检测在低样本数量条件下的研究。
3.2 目标检测评价指标
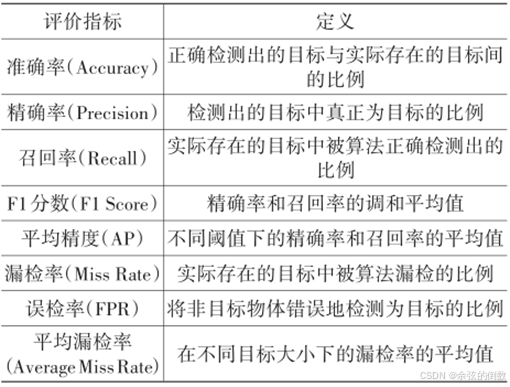
传统检测器在行人检测的应用研究中,以每个窗口的漏检率与误报率(False Positive Per Window,FPPW)作为检测器性能的度量标准。卷积神经网络的应用和检测器检测方法改变后,以平均检测精度(Average Precision,AP)作为同类检测准确性的评价指标,以类平均检测精度(mean Average Precision,mAP)作为不同类别间的平均AP,以表现目标检测算法检测精度的综合性能,并引入交并比( Intersection over Union,loU)来描述目标检测算法的定位准确性。通过IoU阈值的设定判断对象是否成功定位,例如,loU大于0.5时判定为定位准确,loU为1时判定为预测对象位置完全正确。同时,以单位时间检测图像的数量表征目标检测的速度。
针对不同应用场景,评价指标可能各有侧重,表2所示为目标检测任务中常用的评价指标。
表2 目标检测常用评价指标
4 语义分割数据集及评价指标
4.1 语义分割数据集
图像语义分割的研究主要集中在二维图像上。较为常用的数据集如下:
(1)PASCAL VOC[51,52]。PASCAL VOC是国际著名的计算机视觉挑战赛,其开源的RGB数据集均带有标签,可用于5种不同的比赛:分类、检测、分割、动作分割和人员布局。VOC 2012是最常用的数据集,有21个类别,训练集和验证集共包括11 530幅图像。
(2)PASCAL Context[57]。PASCAL Context是由PASCAL VOC 2010数据集扩展而来的,包含所有训练图像的像素级标签(10103),该数据集共有540个语义类别,但是通常选择由59个语义类别组成的子集进行训练研究,而将其余语义类别标记为背景。
(3)PASCAL Part[58]。该数据集同样是PASCAL VOC 2010的扩展,PASCAL VOC的原始类被保留,但是将原始类划分得更细,例如,将自行车分解为车把、前轮、后轮、链轮和鞍座。PASCAL Part分为训练集、验证集和测试集,每幅图像都有像素级标注,可以提供精细的语义信息。
(4)COCO (Microsoft Common Objects in Context)[53]。该数据集是微软公司开源的用于图像识别、语义分割的大型数据集。COCO包含80多个类别,训练集有82783幅图像,验证集有40 504幅图像,测试集超过80 000幅图像。特别地,测试集又划分为4个不同的子集:test-dev、test-standard、test-challenge和l test-reserve,每个子集有具体的功能。
(5)Cityscapes[59]。Cityscapes是一个专注于城市街景语义理解的大型数据集,该数据集分为8个大类,30个子类,提供了语义、实例和密集的像素标注。具有5 000多幅精细标注图像和20 000幅粗标注图像。其最初是作为视频录制的,采集了50个城市几个月的情景,有大量的动态对象和场景布局。
(6)CamVid[60]。CamVid也是一个适应于驾驶领域的道路场景理解数据集,利用仪表盘上的摄像机采样出701帧图像,共有32个类。
(7)KITTI (Karlsruhe Institute of Technology and Toyota Technological Institute at Chicago )[61]。KITTI是用于机器人和自动驾驶领域的最著名数据集之一,包含了由3种传感器(高分辨率RGB、灰度立体摄像机和3D激光扫描仪)记录的几个小时的交通场景,最初该数据集是没有标注的,后来由多个研究者进行了标注。
4.2 语义分割评价指标
在图像语义分割领域,分割性能评价指标有7种:平均精度(Average Precision,AP)、平均精度均值( mean Average Precision, mAP)、平均准确率Mean Accuracy , MA)、平均召回率(Average Recall,AR)、平均交并比(mIoU)、像素准确率(Pixel Accuracy,PA)和频率加权交并比(Frequency Weighted Intersection over Union, FWIoU),比较常用的有两种:平均准确率、平均交并比。
5 总结
5.1 目标检测总结与未来展望
由于传统目标检测算法的过程过于繁琐,且在处理复杂场景时效果差,与深度学习相结合的目标检测逐渐成为研究热点,其在精度和速度方面有了很大的提升。本文分析了目标检测的发展历程,尤其对基于深度学习的目标检测算法进行了深度剖析。虽然此领域发展迅速,但是仍有很多方向值得探讨和研究。
(1)多领域数据集:现有数据集在单一领域完善性比较好,但是相对来说,目标类别数少,对于新场景出现的目标只能检测出少类目标,或出现错检﹑漏检等问题,对于建立一个多领域多场景多元化目标数据集是一个迫切需要解决的问题,同时也是一个重要的研究方向。
(2)自动标注数据集技术:当前的目标检测数据集是人工进行标注,这一过程需要大量的时间和精力,成本高,容易出现错标、漏标等问题,可以考虑使用迁移学习技术,将其他已标注数据集迁移使用,再训练少量项目所需数据集,或者研究一种自动标注技术,使用网络直接实现目标标注。
(3)小目标检测:随着卷积神经网络的进一步完善,基于深度学习的目标检测方法成为主流,但是小目标的特征存在于浅层语义中,深度学习模型往往更擅长提取深层次的语义特征,因此,对于小目标检测效果较差,可以尝试改进网络结构使其更好地利用浅层语义特征。
(4)基于GAN的目标检测:对于目标检测需要大量数据集进行训练,由于数据采集成本,时间限制及特殊场景等因素,会出现数据不足的问题,可以考虑使用GAN系列网络,使用一部分真实场景数据生成部分虚拟数据,扩大数据集,使其覆盖更多不同的场景,可以提高检测效果。
(5)多任务学习:在传统的单任务学习中,需要为每个任务训练一个独立的模型,为降低时间复杂度,可以考虑将目标检测、语义分割以及实例分割等任务融合到一个网络,实现同时兼顾速度与精度的目的。
5.2 语义分割总结与未来展望
本文主要针对当前深度学习语义分割技术的发展情况,从技术差异的角度归纳分类并进行了较为详细的分析和总结。随着深度卷积神经网络的不断推进,在模型分割精确度、运行速度和复杂性方面仍需大量的研究工作。结合当前语义分割研究现状,提出下述值得挑战和深人研究的方向:
(1)如何更好地理解语义分割模型
尽管深度语义分割模型在特征提取方面体现了较好的性能,但深度模型到底在学习什么?研究者如何解释学习到的特征?虽然存在相关技术能够可视化模型提取的特征,但尚未有相关研究针对语义分割模型底层特征学习方式进行表述。对模型理论方面的理解,可以更好地开发和改进泛化性强的语义分割模型。
(2)如何获得高质量的语义分割数据集
语义分割模型性能与数据集质量成正相关。现有算法大都依赖人工标记的数据集,费时费力,且数据集规模较小。虽然当前很多研究者提出基于半监督和弱监督的分割方法,以弱注释方式进行深度网络学习,但准确性较全监督学习方法相差甚远。因此获得高质量的语义分割数据集仍是值得深入研究的方向。
(3)如何平衡语义分割的精确度和速度
实时语义分割在机器人交互、自动驾驶等领域发挥着重要作用.而基于深度学习的语义分割更注重于分割精确度而不是速度。当前主流的实时语义分割方法仍然缺乏较高的精度,需要更好的方法和途径平衡精确度和速度。
(4)如何充分利用上下文特征信息提高模型准确性
有研究者利用CRF作为后处理,提出端到端的方法提高语义分割的准确性。也有研究者通过多尺度特征融合在准确性方面获得显著性的进展。图像包含丰富的上下文特征信息,如何更好的利用这些信息,仍需要更多的研究。
(5)如何更好的轻量化模型
当前主流分割模型在推理阶段仍需大量内存,许多研究者为了在提高精度的同时应用于特定设备上,利用模型压缩技术,或者训练一个复杂模型再用知识整理技术压缩,以减小体积更适用于移动设备。因此在保持精度的同时能轻量化模型体积,将会是未来基于深度卷积语义分割模型的发展方向。
3 参考文献
[1] NEUBECK A, and VAN GOOL L. Efficient non-maximum suppression[C]// Proceedings of the International Conference on Pattern Recognition, USA: IEEE, 2006, 850-855.
[2] REN S, HE K, GIRSHICK R, et al. Faster r-cnn: towards real-time object detection with region proposal networks[J]. IEEE Trans Pattern Anal Mach Intell, 2015, 39(6): 1137-1149.
[3] GIRSHICK R, DONAHUE J, DARRELL T, et al. Rich feature hierarchies for accurate object detection and semantic segmentation[C]// IEEE Conference on Computer Vision and Pattern Recognition. USA: IEEE, 2014, 580-587.
[4] HE K, ZHANG X, REN S, et al. Spatial pyramid pooling in deep convolutional networks for visual recognition[C]// European Conference on Computer Vision. Switzerland: IEEE, 2014, 346-361.
[5] GIRSHICK R. Fast r-cnn[C]// Proceedings of IEEE International Conference on Computer Vision. USA: IEEE, 2015, 1440-1448.
[6] REN S, HE K, GIRSHICK R, et al. Faster r-cnn: towards real-time object detection with region proposal networks[J]. IEEE Trans Pattern Anal Mach Intell, 2015, 39(6): 1137-1149.
[7] KONG T, YAO A, CHEN Y, et al. Hypernet: towards accurate region proposal generation and joint object detection[C]// Computer Vision and Pattern Recognition. USA: IEEE, 2016, 845- 853.
[8] LIN T Y, DOLLAR P, GIRSHICK R, et al. Feature pyramid networks for object detection[C]// Proceedings of IEEE Conference on Computer Vision and Pattern Recognition. USA: IEEE, 2017, 936-944.
[9] SINGH B, DAVIS, L. S. An analysis of scale invariance in object detection - SNIP[C]// IEEE Conference on Computer Vision and Pattern Recognition. USA: IEEE, 2018, 3578-3587.
[10] DAI J, LI Y, HE K, et al. R-FCN: object detection via region-based fully convolutional networks[C]// Neural Information Processing Systems. SPAIN: NIPS Foundation, 2016, 379- 387.
[11] ZHU Y, ZHAO C, WANG J, et al. Couplenet: coupling global structure with local parts for object detection[C]// the IEEE International Conference on Computer Vision. Italy: IEEE, 2017, 4146-4154.
[12] YANG B, YAN J, LEI Z, et al… CRAFT Objects from Images[C]// Computer Vision and Pattern Recognition. USA: IEEE, 2016, 6043-6051.
[13] CHEN Z, HUANG S, and TAO D. Context Refinement for Object Detection[C]// Proceedings of the European Conference on Computer Vision. Germany: IEEE, 2018, 6154-6162.
[14] WANG J, CHEN K, YANG S, et al… Region Proposal by Guided Anchoring[C]// Computer Vision and Pattern Recognition. California: IEEE, 2019, 2965-2974.
[15] NEUBECK A, and VAN GOOL L. Efficient non-maximum suppression[C]// Proceedings of the International Conference on Pattern Recognition, USA: IEEE, 2006, 850-855.
[16] JIANG B, LUO R, MAO J, et al… Acquisition of Localization Condence for Accurate Object Detection[C]// European Conference on Computer Vision. Germany: IEEE, 2018, 816-832.
[17] REDMON J, DIVVALA S, GIRSHICK R, et al. You only look once: unified, real-Time object detection[C]//IEEE Conference on Computer Vision and Pattern Recognition. USA: IEEE, 2016, 779-778.
[18] LIU W, ANGUELOV D, ERHAN D, et al. Ssd: single shot multibox detector[C]// European Conference on Computer Vision, Amsterdam. Netherlands: IEEE, 2016, 21-37.
[19] REDMON J and FARHADI A. Yolo9000: Better, Faster, Stronger[C]// Computer Vision and Pattern Recognition, Hawaii. USA: IEEE, 2017, 6517-6525.
[20] REDMON J and FARHADI A. YOLOv3: An Incremental Improvement[C]// Computer Vision and Pattern Recognition. Salt Lake City, Utah, USA: IEEE, 2018, 3523-3541.
[21] BOCHKOVSKIY A , WANG C Y , LIAO H Y M.YOLOv4 : optimal speed and accuracy of object detection[C]∥Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2020: 1544-1552.
[22] JOCHER G. YOLOV5[EB/OL]. (2020-05-09)[2022-09-16]. https:∥github.com / ultralytics/yolov5.
[23] GEZ, LIUS, WANGF, et al. YOLOX: exceedingYO-LOseriesin2021[C]∥Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Online : IEEE , 2021 : 8001-8010.
[24] JEONG J, PARK H, and KWAK N. Enhancement of SSD by concatenating feature maps for object detection[C]//British Machine Vision Conference. London, UK: BMVC 2017.
[25] FU Chengyang, LIU Wei, RANGA A, et al… DSSD : Deconvolutional Single Shot Detector [OL]. http://arxiv.org/abs/1701.06659, 2017.
[26] LIN T-Y, GOYAL P, GIRSHICK R, et al. Focal loss for dense object detection[C]// International Conference on Computer Vision. Venice, Italy: IEEE, 2017, 2999-3007.
[27] LIU S, HUANG D, and WANG Y. Receptive Field Block Net for Accurate and Fast Object Detection[C]// European Conference on Computer Vision. Germany: IEEE, 2018, 404-419.
[28] LAW H and DENG J. CornerNet: Detecting Objects as Paired Keypoints[C]// European Conference on Computer Vision. Munich, Germany: IEEE, 2018, 765-781.
[29] ZHOU Xingyi, ZHUO Jiacheng, and KRAHENBUHL P. Bottom-up Object Detection by Grouping Extreme and Center Points [OL]. http://dblp.org/abs/1901.08043, 2019.
[30] TIAN Zhi, SHEN Chun hua, CHEN Hao, et al… FCOS: Fully Convolutional One-Stage Object Detection [OL]. http://dblp.org/abs/1904.01355, 2019.
[31] Carreira J and Sminchisescu C. 2012b. CPMC:Automatic object segmentation using constrained parametric min-cuts.IEEE Transactions on Pattern Analysis & Machine Intelligence,IEEE: 34(7):1312-1328
[32] Long J,Shelhamer E and Darrell T. 2015. Fully convolutional networks for semantic segmentation//Proceedings of 2015 IEEE Conference on Computer Vision and Pattern Recognition. Boston, USA: IEEE: 3431-3440 [DOI: 10.1109/CVPR.2015.7298965.
[33] Liang-Chieh C, Papandreou G, Kokkinos I, et al. Semantic Image Segmentation with Deep Convolutional Nets and Fully Connected CRFs[C].International Conference on Learning Representations(ICLR). 2015.
[34] Chen L C, Papandreou G, Kokkinos I, et al. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs[J]. IEEE transactions on pattern analysis and machine intelligence, 2017, 40(4): 834-848.
[35] Chen L C, Papandreou G, Schroff F, et al. Rethinking atrous convolution for semantic image segmentation[J]. arXiv preprint arXiv:1706.05587, 2017.
[36] Chen L C, Zhu Y, Papandreou G, et al. Encoder-decoder with atrous separable convolution for semantic image segmentation[C]. Proceedings of the European Conference on Computer Vision (ECCV). 2018: 801-818.
[37] Noh H, Hong S, Han B. Learning deconvolution network for semantic segmentation[C]//Proceedings of the IEEE international conference on computer vision. 2015: 1520-1528.
[38] Badrinarayanan V, Kendall A, Cipolla R. Segnet: A deep convolutional encoder-decoder architecture for image segmentation[J]. IEEE transactions on pattern analysis and machine intelligence, 2017, 39(12): 2481-2495.
[39] Ronneberger O, Fischer P, Brox T. U-net: Convolutional networks for biomedical image segmentation[C]//Medical image computing and computer-assisted intervention–MICCAI 2015: 18th international conference, Munich, Germany, October 5-9, 2015, proceedings, part III 18. Springer International Publishing, 2015: 234-241.
[40] Ghiasi G, Fowlkes C C. Laplacian pyramid reconstruction and refinement for semantic segmentation[C]//Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, October 11-14, 2016, Proceedings, Part III 14. Springer International Publishing, 2016: 519-534.
[41] Zhao H, Shi J, Qi X, et al. Pyramid scene parsing network[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2017: 2881-2890.
[42] Kirillov A, Wu Y, He K, et al. Pointrend: Image segmentation as rendering[C]//Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2020: 9799-9808.
[43] Visin F, Ciccone M, Romero A, et al. Reseg: A recurrent neural network-based model for semantic segmentation[C]//Proceedings of the IEEE conference on computer vision and pattern recognition workshops. 2016: 41-48.
[44] Graves A, Graves A. Long short-term memory[J]. Supervised sequence labelling with recurrent neural networks, 2012: 37-45.
[45] Fu J, Liu J, Tian H, et al. Dual attention network for scene segmentation[C]//Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2019: 3146-3154.
[46] Dai J, He K, Sun J. Boxsup: Exploiting bounding boxes to supervise convolutional networks for semantic segmentation[C]//Proceedings of the IEEE international conference on computer vision. 2015: 1635-1643.
[47] Rajchl M, Lee M C H, Oktay O, et al. Deepcut: Object segmentation from bounding box annotations using convolutional neural networks[J]. IEEE transactions on medical imaging, 2016, 36(2): 674-683.
[48] Lin D, Dai J, Jia J, et al. Scribblesup: Scribble-supervised convolutional networks for semantic segmentation[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2016: 3159-3167.
[49] Carbonneau M A, Cheplygina V, Granger E, et al. Multiple instance learning: A survey of problem characteristics and applications[J]. Pattern Recognition, 2018, 77: 329-353.
[50] Sun K, Shi H, Zhang Z, et al. Ecs-net: Improving weakly supervised semantic segmentation by using connections between class activation maps[C]//Proceedings of the IEEE/CVF international conference on computer vision. 2021: 7283-7292.
[51] EVERINGHAM M, VAN GOOL L, WILLIAMS C K, et al… The PASCAL visual object classes challenge 2007 (VOC2007) results [J]. 2007.
[52] SHETTY S. Application of convolutional neural network for image classification on pascalvoc challenge 2012 dataset[C]// Computer Vision and Pattern Recognition. USA: IEEE, 2016.
[53] LIN T, MAIRE M, BELONGIE S J, et al. Microsoft coco: common objects in context[C]// European Conference on Computer Vision. Switzerland: IEEE, 2014, 740-755.
[54]RUSSAKOVSKY O, DENG J, SU H, et al… Imagenet large scale visual recognition challenge [J]. International journal of computer vision, 2015, 115(3): 211-252.
[55]KUZNETSOVA A, ROM H, ALLDRIN N, et al… The open images dataset v4: Unified image classification, object detection, and visual relationship detection at scale[OL].
http://dblp.org/abs/1811.00982, 2018.
[56]GUPTA A, DOLLAR P, and GIRSHICK R. LVIS: A Dataset for Large Vocabulary Instance Segmentation[C]// Computer Vision and Pattern Recognition, California. USA: IEEE, 2019,
5356-5364.
[57] H. Zhang, K. Dana, J. Shi, Z. Zhang, X. Wang, A. Tyagi, and A. Agrawal. Context encoding for semantic segmentation. In CVPR, 2018.
[58] Chen X, Mottaghi R, Liu X, et al. Detect what you can: Detecting and representing objects using holistic models and body parts[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2014: 1971-1978.
[59] Cordts M, Omran M, Ramos S, et al. The cityscapes dataset for semantic urban scene understanding[C]. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2016: 3213-3223.
[60] Brostow G J, Fauqueur J, Cipolla R. Semantic object classes in video: A high-definition ground truth database[J]. Pattern Recognition Letters, 2009, 30(2): 88-97.
[61] Geiger A, Lenz P, Urtasun R. Are we ready for autonomous driving? the kitti vision benchmark suite[C]//2012 IEEE conference on computer vision and pattern recognition. IEEE, 2012: 3354-3361.


















 1243
1243

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









