







TimeXer 模型解析
模型目的与特点
背景
TimeXer 是一种专门用于时间序列预测的 Transformer 模型,特别适合处理带有外生变量(exogenous variables)的时间序列问题。在时间序列预测中,外生变量为辅助变量,与目标时间序列无直接依赖关系,但可以提升预测的准确性。传统的时间序列模型难以高效地处理此类外生变量,而 TimeXer 模型通过设计特殊的嵌入和注意力机制,成功捕获了内生变量和外生变量间的相关性。
特点
TimeXer 模型的核心创新在于引入了跨变量注意力层,允许模型在预测过程中有效整合外生信息。这一设计能够在不显著增加计算复杂度的前提下提升预测精度。此外,TimeXer 模型使用了非重叠的时间片段嵌入方式,使得内生时间序列的特征能够更清晰地展现。
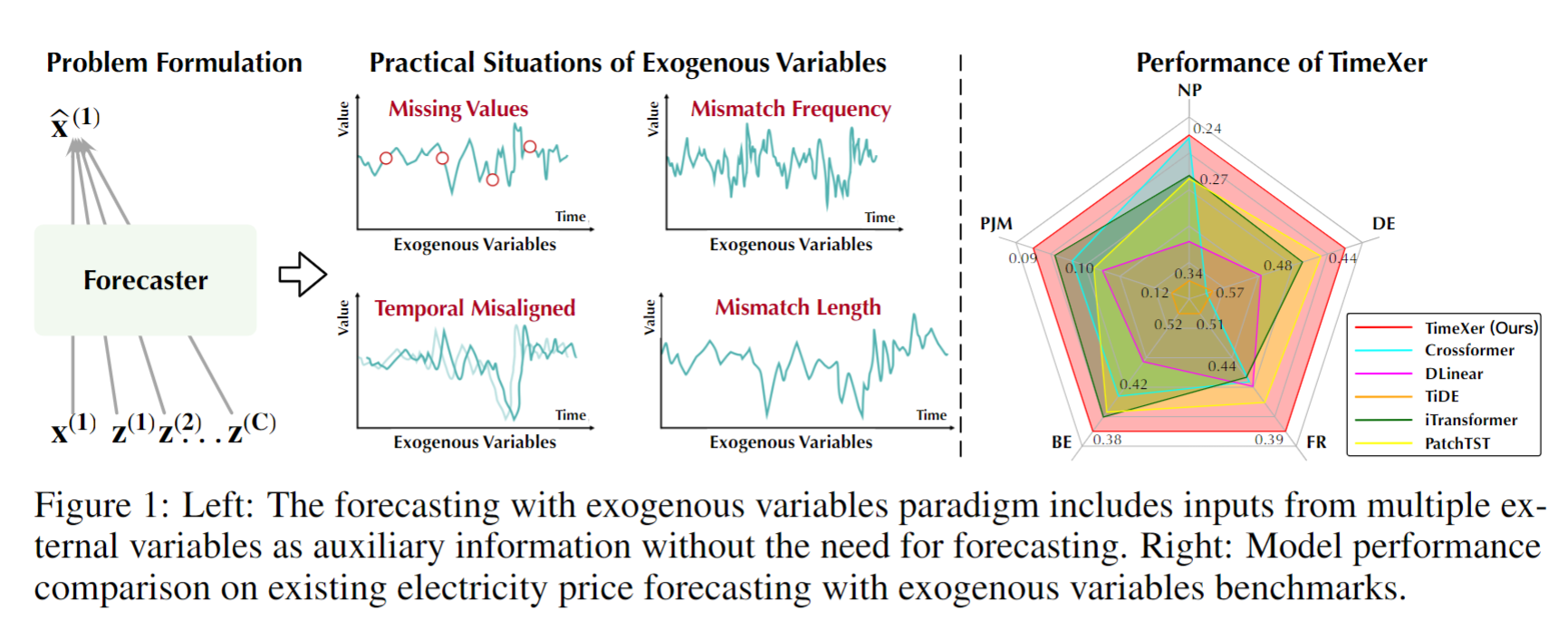
图1: TimeXer模型架构总览
其实就是多变量预测Mutiple - Single (MS) 常规的做法M输入,模型输出也是M,只是在最后预测部分单独把标签列索引出来,而本篇文章则是非标签变量最终不参与预测。
模型结构概述:从正向传播数据流的视角
TimeXer 模型的整体结构可以划分为以下几个关键模块:
- 内生变量嵌入模块:将内生时间序列划分为非重叠时间片段,生成时间片段级别的嵌入。
- 外生变量嵌入模块:将外生变量处理成变量级别的表示,以低计算复杂度方式引入模型。(itransformer的思想)
- 内生自注意力机制:在时间片段上执行自注意力,捕获内生变量的短期时间依赖关系。
- 内生-外生跨注意力机制:将外生变量的信息通过跨注意力机制注入到内生变量的全局表示中。
- 预测输出层:整合最终的内生表示,通过线性映射得到预测结果。
下面将对各个模块进行详细的解释,并包含正向传播过程中的数据形状变化,以展示数据在模型中的流动路径。
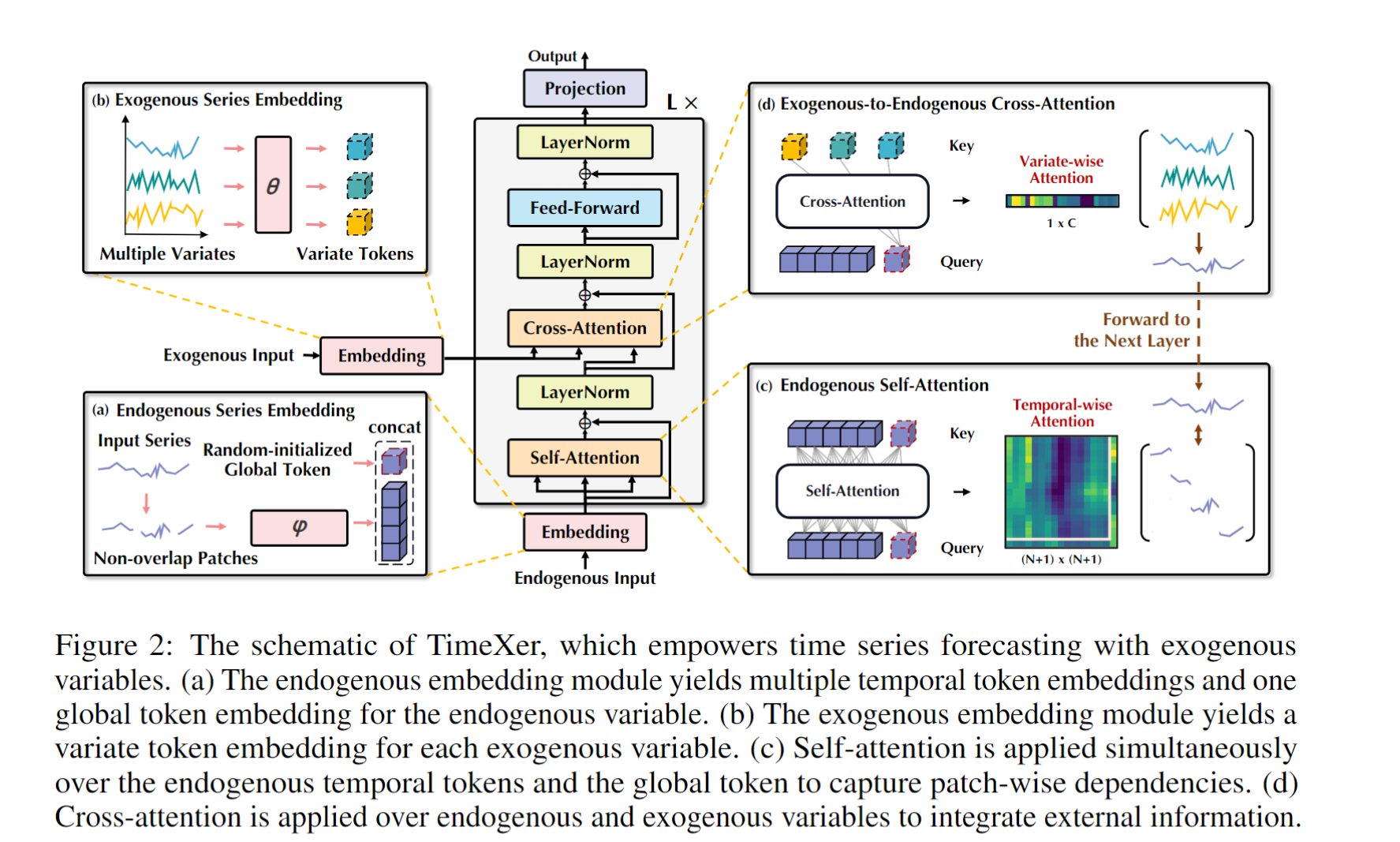
图2: TimeXer模型数据流向图
1. 内生变量嵌入:时间片段分割与嵌入
数据流与处理过程
假设输入的内生时间序列为 x ∈ R T × n v a r s x \in \mathbb{R}^{T \times nvars} x∈RT×nvars,其中 T T T为时间步长度, n v a r s nvars nvars为内生变量特征维度。首先,TimeXer 将时间序列划分为不重叠的片段,每个片段包含 P P P个时间步长。
- 将序列 x x x划分为 N = ⌊ T / P ⌋ N = \lfloor T / P \rfloor N=⌊T/P⌋个片段 { s 1 , s 2 , … , s N } \{s_1, s_2, \dots, s_N\} { s1,s2,…,sN},每个片段 s i ∈ R P × n v a r s s_i \in \mathbb{R}^{P \times nvars} si∈RP×nvars。
- 生成一个全局令牌
global_token其维度是nn.Parameter(torch.randn(1, nvars, 1, d_model))然后通过repeat函数生成与输入对应的批次维度B。** ## 注意,内生变量嵌入层输入的维度是**$(B,nvars,T) $**需要首先对输入序列的时间维度和特征维度进行转置。## ** - 每个片段通过线性变换将输入$x $映射到 d m o d e l d_{model} dmodel维度的向量空间:
s i ′ = Linear ( s i ) + PosEnc ( i ) s_i' = \text{Linear}(s_i) + \text{PosEnc}(i) si′=Linear(si)+PosEnc(i)
其中 s i ′ ∈ R d m o d e l s_i' \in \mathbb{R}^{d_{model}} si′∈Rdmodel表示时间片段级别的内生嵌入, d m o d e l d_{model} dmodel为嵌入维度。其具体维度是 ( B , n v a r s , p a t c h _ n u m , d m o d e l ) (B,nvars,patch\_num,d_{model}) (B,nvars,patch_num,dmodel),这个步骤其实就是PatchTST中的PatchEmbedding,我这里贴心的post出了该步骤的完整代码及其详细维度注释。
class PatchEmbedding(nn.Module):
def __init__(self, d_model, patch_len, stride, padding, dropout):
super(PatchEmbedding, self).__init__()
# Patching
self.patch_len = patch_len # patch的长度
self.stride = stride # patch的步长
self.padding_patch_layer = nn.ReplicationPad1d((0, padding)) # 使用ReplicationPad1d进行填充
nn.ReplicationPad1d()
# Backbone, Input encoding: projection of feature vectors onto a d-dim vector space
self.value_embedding = nn.Linear(patch_len, d_model, bias=False) # 将patch映射到d_model维度的线性层
# Positional embedding
self.position_embedding = PositionalEmbedding(d_model) # 位置嵌入
# Residual dropout
self.dropout = nn.Dropout(dropout) # dropout层
def forward(self, x):
# do patching
n_vars = x.shape[1] # 获取变量数量
x  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 5518
5518

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









