







(学生党凭自己理解写的,可能存在一定错误,欢迎指正,如果侵权我就删了,图片均来自原文)
Introduction部分
从机载激光扫描(airborne laser scanning,ALS)点云中提取建筑物屋顶轮廓对于许多应用都是至关重要的,在城市重建中,三维模型的精度很大程度上依赖整个流程初始阶段提取的建筑轮廓。
本文研究了如何从ALS点云中自动获取建筑的内外轮廓。文章的重点是从ALS点云中提取2.5d的建筑轮廓线,并根据轮廓线构建LoD(level of detail)1等级的点云
相关工作
轮廓提取可分为图像轮廓提取和点云轮廓提取。
图像轮廓提取技术
传统轮廓提取技术
传统方法有Canny,Roberts,Sobel等。这些方法简单高效,但存在易受遮挡,低对比度和视角不利等要素影响的问题。
基于DSM的轮廓提取
数字地表模型(Digital Surface Model,缩写DSM)是指包含了地表建筑物、桥梁和树木等高度的地面高程模型。和DEM相比,DEM只包含了地形的高程信息,并未包含其它地表信息,DSM是在DEM的基础上,进一步涵盖了除地面以外的其它地表信息的高程。在一些对建筑物高度有需求的领域,该模型得到了很大程度的重视。
点云轮廓提取技术
几何计算工具技术(Computing Geometry Tools)
为了克服基于图像的轮廓算法的缺点,其他计算几何算法,如凸包、alpha shape、基于delau-nay的雕刻算法及其变体,在过去经常被用于从点云近似物体轮廓。凸包如字面意思般只能检测突出的点,不能检测孔洞类内部轮廓的结构;alpha shape可以检测有内部轮廓的建筑;Peethamba-ran和Muthuganapathy提出了一种基于delaunay的滤波算法,用于从点云逼近二维边界。但轮廓点之间的拓扑关系(如顺时针逆时针排列顺序等)无法获取,且获得的轮廓由于细节过多很容易受噪声或异常值影响。因此不适合做建筑轮廓的紧凑表示。
基于拓扑的轮廓提取技术(Topologically Correct Contouring)
这类算法侧重于生成具有正确拓扑的建筑轮廓的方法,例如轮廓点之间的顺序关系,每个轮廓的闭合,单个轮廓实体无自交,不同轮廓实体之间无交,包含关系。例如:Awrangjeb提出了一种通过分析三角形的相邻关系来识别建筑轮廓,并通过从树结构中搜索潜在循环来恢复轮廓点之间的拓扑结构的方法。
施加正确约束来提取轮廓的技术(Imposing Regularity Constraints)
许多轮廓技术使用规则约束与优化相结合来生成轻量级和曼哈顿风格的建筑轮廓(偏方块的轮廓)。这些方法中硬约束的大量设置是其主要的问题。
基于能量优化的隐式约束轮廓提取(Implicit Constraints for Energy Optimization)
在建筑轮廓上明确施加硬约束有其自身的局限性,它难以捕捉复杂形状建筑的描述。这种建筑形状难以设计出一种能通过一系列硬约束定义的特征。因此通过能量优化算法(就是求最优值的算法,简单来说就是打分并求最大分数)来进行隐式约束,这为复杂形状的建筑轮廓描述提供了一种更加灵活的方式。
综上所述,目前所有的基于点云的方法主要从单一特征来计算轮廓,来满足特定的应用。因此,缺乏一种能综合所有特征来生成轮廓的框架,而最终的轮廓也有几何准确,拓扑准确,高度紧凑和规则的轮廓。而这是本文所解决的问题。
文章框架
本文的框架分为五步:建筑识别(building identification),轮廓检测(contour determination),轮廓分解(contour decomposition),轮廓规范化(contuor regulation),轮廓生成(contour generation)。
第一步:识别建筑物实体,从而简化后续步骤处理几何和拓扑的复杂性。
第二步:提出一种拓扑感知传播算法(topologically aware propagation algorithm) 来感知建筑初始轮廓。
第三步:通过能量共识将初始建筑轮廓分解为多个部分。
第四步:利用分层策略(hierarchical strategy)使各个部分在全局上更加规则。
第五步:依序连接锚点生成紧凑轮廓。
本文贡献
提出一种新的传播算法,以一种拓扑感知的方式从无向图中感知建筑初始轮廓(感知建筑初始轮廓的新方式)
提出一种新的全局优化算法,通过能量最小化的方式将建筑分解为多个部分(提出一种新的分解轮廓算法)
提出一种基于全局的规则化算法,分层地规则化建筑的轮廓。
原文流程图如下:
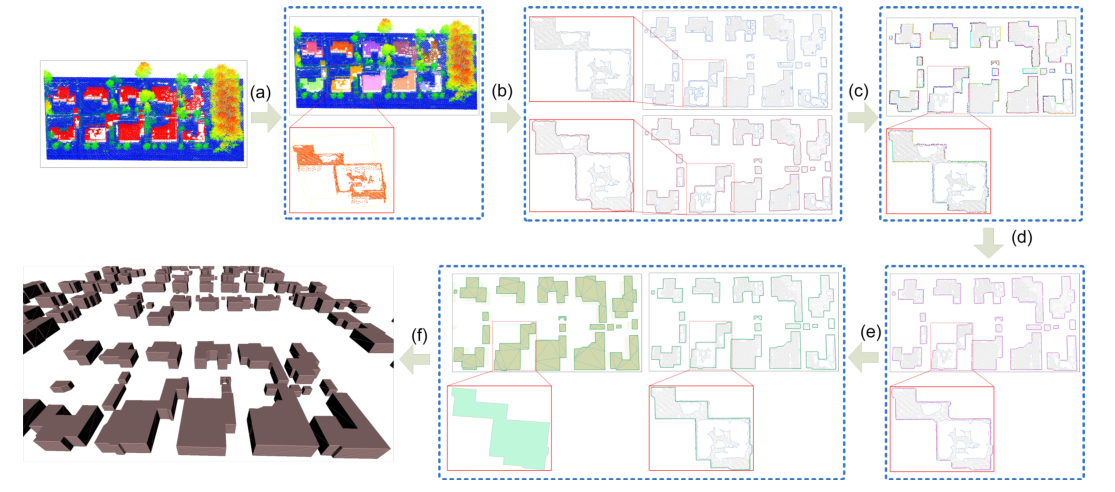
Methodology部分
该方法输入为一套大规模的,包含多个建筑的ALS点云,输出为LoD1等级的模型。
建筑检测 Building Identification
目的:通过标记聚类的方式,将建筑物群的点云分成一个个单独的建筑个体,以便后续处理。
这类算法的核心是基于同一栋建筑的点云在空间上分布较为集中这一原则实现的。之前的通过聚类来分割建筑群的算法多数是基于欧式距离的,而在这种方法框架下,在建筑群分布较为稠密的居民区和分布不均匀的建筑群点云上设定划分的阈值会比较困难。本文提出的方法基于DBSCAN聚类算法(有关DBSCAN可以看文章:DBSCAN详解_皮卡丘的情绪的博客-CSDN博客_dbscan,简单来说就是密度邻域聚类),并在此基础上做了改进。
改进1:在点云分布不均匀的情况下,使用当前点密度除以其邻域点密度计算出的点密度之比来重新定义当前点的密度。
改进2:点云中两点间的距离采用的不是传统欧几里得距离,而是曲率+距离的结合。如下图,假设点p是核心点,做点p的切平面(大概是根据点p的法向量得出的),获得点q在平面上的投影q'(注意图中的投影方式),并以pq'为距离标准。传统距离不变,曲率越大,投影距离越大。通过这种方式考虑局部点的变化趋势。这种方式是能更方便地区分稠密区的建筑。
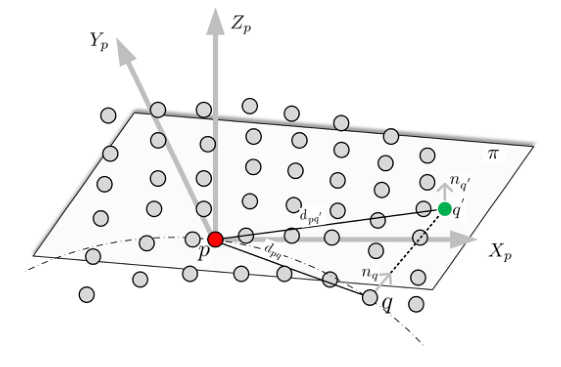
改进3:采用了kd树的空间管理结构加快了邻近点查询速度。
与传统DBSCAN的对比如下(左图为传统DBSCAN,右图为增强后的DBSCAN),可以看出一些稠密的建筑群也能被区分开。

初始轮廓确定Initial Contour Determination
使用AlphaShape算法确认建筑投影到2D点集后的外部/内部轮廓段。由于这个算法容易受到噪声和点云缺失等情况的影响,因此文章提出了一种基于用AlphaShape获得的轮廓的新的拓扑感知算法(aware propagation)。步骤如下:
(1)将单个建筑利用AlphaShape获得的形状转为无向图。
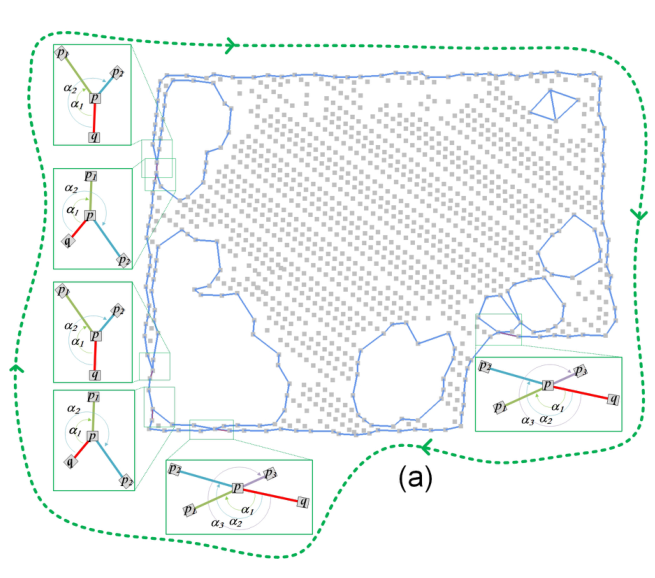
(2)从无向图中选择一个度数大于1的任意顶点P作为传播起点。
(3)以顺时针或逆时针为传播方向,若当前点p度数为2则选择下一个未连接过的点作为下一个点。若度数大于2,则按照传播方向找一个最小方位角对应的点p1作为下一个点。如下图,顺时针传播的情况下从q到p,然后下一个传播点是顺时针方位角最小的α1对应的点p1。此步骤递归执行直到自传播形成一个闭合环。
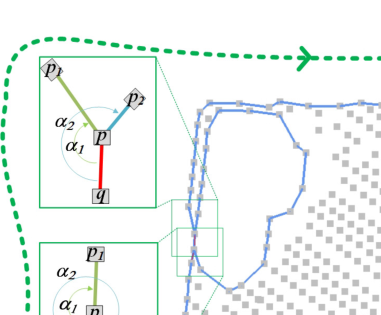
(4)使用暴力搜索算法重复步骤2-3,直到所有建筑都获得外部轮廓闭环。
(5)以剩余的未访问顶点为起点,重复步骤(2)-(4),直到所有的内闭环都被提取出来。
(6)采用形状指数(shape index,指的大概是固定的几种形状,通过判断该轮廓是否接近这些形状来判断是否为内轮廓)来区分内环是否代表建筑内部轮廓。
轮廓分解Contour Decomposition
目的:将上一步获得的基础轮廓分解为指定数目的线性原语(linear primitives,大概就是线段),每个线性原语需要和实际建筑轮廓保持一致。
更准确地说,所研究的问题可以明确地表述如下:给定任意轮廓Cini,最优m个线性原语L = {L1, L2,…Lm}期望通过最优标记过程f得到。任意线性原语Li由点集p1, p2,…组成(就是将轮廓分解成线性原语,并从中找到组合起来得分最优的m个线性原语组成轮廓)。
显然,这个问题是一个多标记问题,可以通过凸优化(convex optimization,不严格的说,凸优化就是在标准优化问题的范畴内,要求目标函数和约束函数是凸函数的一类优化问题。这种情况下找到的局部最优解就是全局最优解。参考文章见:凸优化(Convex Optimization)是什么?_caimouse的博客-CSDN博客_convex optimization)来解决。因此,首先需要定义一个由多个子能量项构成的能量函数,然后通过使这个能量函数最小来达到选出最优的数个边的目的。
能量函数由三个子项组成:对齐项(alignment term),平滑项(smoothness term),保真项(fidelity term)。两个参数被用于平衡能量。
![]()
对齐项(alignment)保证了分段线性原语尽可能接近它的精确轮廓。该项的计算方式综合考虑了距离和方向,其中distance项(3)负责保证点和其相关的线性原语的一致性,direction项(4)保证了当前轮廓的局部切线与线性原语方向一致。
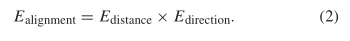
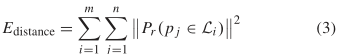

平滑项(smooth)保证了线性原语的同质性。由于每个轮廓的点的顺时针或逆时针拓扑都是显式的,因此平滑项的设计仅涉及到当前处理到的两个相邻点(即每次仅计算一对点的平滑度),设计如下,其中F代表了当前点所属线性原语的标签。
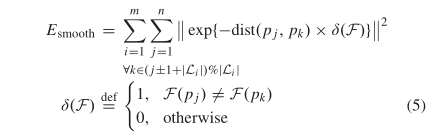
(个人猜测这一项计算的实质上是每个线性原语的首尾端点之间距离的反比总和。即倾向于使分割后的线性原语数量尽可能少(这也起到了一部分保真项的作用),且原语之间尽可能分隔地较为明显。)
保真项(fidelity)抑制了琐碎的线性原语的生成,该项用于减少琐碎的线性原语,且保证线性原语与原轮廓的的一致性。其计算公式如下。|Li|表示Li中的点数,pkCini表示某个轮廓中的任一点(后面的函数相当于表示现在这条线性原语是被隐藏了还是存在的),这个函数倾向于合并较小的线性原语(即每个线性原语中包含的点数较均衡),从而消除了冗余标签。
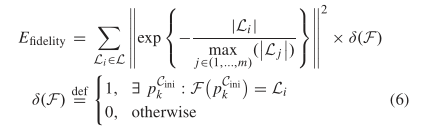
点集转为初始线性原语的过程主要参考了RANSAC算法,但由于RANSAC可能会产生大量偏离实际轮廓的伪原语,因此在此基础上做了改进。原文中改进的方法没看懂。
下一步则是根据能量函数优化的方式合并相邻的线性原语。这个地方文章提出了三种方式:模拟退火,信念传播和图切割。文中优化过程采用了图切割中最小割最大流问题的解决方案,更准确地说是采用了Gurobi solver中的alpha-expansion的方法(有点类似于模拟退火,就是不断合并扩张迭代看能量函数是否有下降的过程。有关最小割最大流问题可以参考文章:图像分割经典算法--《最小割最大流》(Minimum Cut——Max Flow)_我的她像朵花的博客-CSDN博客_最大流最小割算法,而alpha-expansion的转化过程可以参考文章:https://blog.csdn.net/nothinglefttosay/article/details/48554555)RANSAC获得的初始线性原语集和he优化后的de原语集合jih结果对比如下:
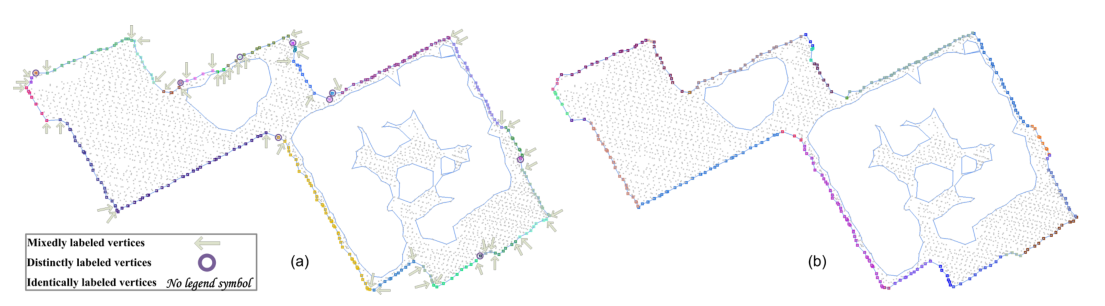
轮廓正则化Contour Regularization
原因:分解后得到的线性原语由于噪声和缺失数据产生的伪影(本不该出现的数据由于各种原因出现)而不能直接使用,因此需要进行正则化来细化结果。
策略:采用一种“分层”策略来防止不同的正则化操作之间冲突,减少开销。
大体步骤:首先对线性原语进行分组,每组的线性原语几乎都是相互平行的(并行性);其次,对每组进行评估,判断是否与真实建筑方向一致(同质性),并根据组间正交准则进行操作(正交性,这地方可能是假设建筑相隔两面墙之间是垂直的);最后,根据邻近准则确定每组线性原语是否共线(共线性)。整个方法需要给距离偏差容忍度d和方向偏差容忍度E设定阈值。
并行性判断两个先行源于是否平行。为了减少计算量和冲突关系,首先对所有线性原语进行简单的成对比较来提取初始平行组,然后通过传播的方式来聚合这些组。成对群中的线性原语可以合并到另一个群中,也可以分离到一个新的群中。判断公式如下:
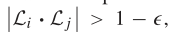
伪代码如下:

(代码解释和疑惑:大体能看懂第一步先进行全对比并分组;第二步以组为单位通过栈的数据结构进行传播融合操作,每次融合完更新下当前线性原语组拟合出的向量。直到所有组都被融合了一遍。但总觉得是不是少了个操作,在23行的if操作里是不是应该加个visited = true的操作,以及为啥while循环的单位是单个线性原语,融合时又以组为单位?)
同质性判断下当线性原语组的方向gi和建筑主导方向(建筑的朝向)候选中的一个满足如下条件时,算法会通过调整线性原语组的方向使两者强制平行。判断公式如下:注意,当与任意建筑主导方向候选都不符合时,线性原语的方向会保持原样。

原文中特别提及了两种建筑主导方向确定的方法:
(1)数据驱动的方法:获得建筑轮廓点的切线方向,建筑与地表交线方向,以及各个屋顶平面中的优势脊边方向,并根据数据构建直方图。直方图中每个局部最大值都是一个主导方向。这个方法用于处理主导方向较多的城市场景。
(2)混合方法:多数场景观察到的建筑具有如下特征::1)轮廓形状相对简单,这些住宅场景中的建筑大多只有两个正交的优势点;2)每个建筑的面积相对较小,有时会受到附近树木的严重遮挡。而这会给数据驱动方法带来较大误差。因此,在混合方法中,只假设建筑物只有两个主导方向,它们相互垂直或正交。
观察到建筑初始轮廓Cini在建筑主导方向及其正交主导方向上投影长度最小。因此,设计如下能量函数,通过循环迭代求解下列能量函数来得到这两个主导方向。函数中|Cini|表示轮廓总数,Si表示第i段的长度,θ∗为建筑主导方向的期望变量(Bdomi = θ∗)。通过高斯牛顿算法(GaussNewton's algorithm)迭代求解。
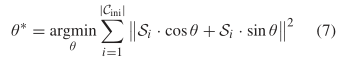
当一个主导建筑方向组确定时,会添加另外几个方向以形成完整的参考方向,即0◦(主导方向),45◦,135◦和180◦。
正交性保证了本应相互正交的两个线性原语在最终结果中是正交的。即假如两个线性原语组是几乎正交的(|gi·gj| <E),则通过算法使它们完全正交。
实现方式:综合了同质性中找到的建筑主导方向:首先算法找到了所有的成对正交群;对于每对正交线性原语,算法首先调整其中优势个体的方向,使其在满足同质性准则时与建筑的优势朝向一致。然后,该对的另一个相应地垂直于主导组。其伪代码如下:

共线性即当两个线性原语距离上非常接近时,表示它们共线且可合并。判断标准如下列公式。实现方法是在并行性获得的每个线性原语组内执行基于共线判断的传播算法,从而将每个组细分为更多的共线子组。
![]()
伪代码如下:

综上所述,上述四个程序具有以下程序目标:并行性,保证整个建筑的规律性;同质性,使建筑轮廓尽可能与它们的主要/正交的主要方向一致;正交性,保持建筑轮廓直角;共线性控制着建筑轮廓的不同抽象程度。
轮廓生成 Contour Generation
前面生成无向图的过程确定了线性原语组之间的邻接关系,从而保证了建筑轮廓的水密性。简单来说,就是相邻的两个线性原语组之间一定包含一个锚点,且该锚点位于线性原语组的两端。这些锚点连接两个原语并最终组成水密性的轮廓。
算法会逐个处理轮廓(外轮廓和内轮廓),并根据它们的包容关系将它们组织成ESRI4 shapefile格式(一种由点,线和多边形及对应的信息组成的格式文件,可包含地理数据等信息。是美国环境系统研究所(ESRI)开发的一种空间数据开放格式。该文件格式已经成为了地理信息软件界的一个开放标准。可参考百科百度百科-验证)。
结果
(算法结果验证这一部分太长了,此处直接放最终对比结果,其它部分包括需要设置的参数,精准度和时间效率,算法鲁棒性,拓扑结构分析,LoD分析,紧凑性和可伸缩性分析等,每一部分都非常详细,如果有需要我单独再写一个)
数据来自荷兰数据集AHN3,主要使用Riegl LMS-Q680i激光扫描传感器采集数据,有时使用Riegl VQ-780i。采集的高度在450-500m之间,该数据集免费提供。整个数据被分为1100个小矩形块,每个小矩形块南北方向面积6.25公里,东西方向面积5.0公里。从中挑选了站点1,2,3来评估轮廓算法。它们包含了很多不稳定的小型线性原语,其中站点3的点云还有高度缺失数据的污染。
本算法与其它三种经典轮廓算法进行了比较:alpha-shape轮廓算法,基于mst的轮廓算法,和Douglas-Peucker轮廓算法。算法对比结果见图(包含各特性对比结果和实际操作结果):

alphashape算法对于缺失数据很敏感;基于MST的轮廓算法可以通过跟踪边界点来获得轮廓拓扑结构,但是容易被噪声等异常情况破坏导致轮廓不完整;Douglas-Peucker算法旨在通过递归消除轮廓里的冗余点,从而保留基本的形状点,从而生成更紧凑的轮廓。但简化后的轮廓并不规则,且该算法要求输入轮廓有拓扑结构,这降低了其可用性。通过OE和CE比较,发现本文算法在各方面都更佳。
过程总结:本文提出了一种针对大规模ALS点云轮廓的勾画算法,从增强的DBSCAN算法开始划分建筑,然后通过传播过程提供外部和内部的精准建筑轮廓,然后通过一个能量公式及使其最小化的过程将轮廓分解为多个线性原语,又通过分层的正则化对线性原语进行优化。最后根据优化后的线性原语的连接关系组成最终的轮廓。
评估总结:通过实验评估证明了算法在面对三种不同建筑类型时的鲁棒性,且对点云质量的低敏感性(即有大量屋顶数据缺失时也有效)。算法也具有一定的可伸缩性(虽然有个建筑失败了)
算法存在的缺陷:
(1)DBSCAN是基于密度分类的概念,而在密度非常不均匀的情况下可能会发生过分割。
(2)轮廓的非线性部分只能通过多个线性原语近似表示。
(3)如何正确区分真实内轮廓和数据缺失造成的伪内轮廓也是一个很大的挑战。在本文中,算法只能通过形状索引来识别相对简单的内轮廓形状。因为如果数据缺失是由于屋顶雨水造成的,缺失点云的几何形状往往是不规则的。但有些特殊材料屋顶导致的镜面反射会在顶部造成规则的内部点云缺失,这种情况下很难区分内轮廓和点云缺失的区别。
(4)最后一个问题是关于正则化器,它目前是在单个实体级别上建立的。在现实世界中,建筑规律模式不仅存在于单个建筑中,也存在于局部区域内的多个建筑中。
算法的未来发展:
(1)计划引入深度学习框架识别单个建筑
(2)计划引入参数表示的非线性模型到全局优化和正则化框架中、
(3)为了获得真实的内部轮廓,计划使用语义分割来辅助内部轮廓的识别,以识别屋顶结构。
(4)为了进一步完善正则化器,考虑通过格式塔图(Gestalt diagram)探索局部组构建模式,并将这些先验信息集成到统一的正则化框架中,从而将正则化器从个体实体级扩展到组实体级。















 491
491











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









