







 本文介绍了双向RNN如何通过同时考虑序列的过去和未来信息来增强模型性能。它在自然语言处理、语音识别等领域表现出色,但也存在计算成本增加和实时处理限制。作者提供了双向LSTM的Python实现并探讨了其优缺点及应用案例。
本文介绍了双向RNN如何通过同时考虑序列的过去和未来信息来增强模型性能。它在自然语言处理、语音识别等领域表现出色,但也存在计算成本增加和实时处理限制。作者提供了双向LSTM的Python实现并探讨了其优缺点及应用案例。
目录
1. 引言与背景
循环神经网络(Recurrent Neural Network, RNN)以其对序列数据的强大建模能力,在自然语言处理(NLP)、语音识别、时间序列预测等领域取得了显著成果。然而,标准RNN仅能利用前向传播的信息,即每个时刻的隐藏状态仅依赖于过去的输入。这限制了其对序列中未来信息的捕获,尤其在处理含有长期依赖和复杂上下文关系的问题时,可能导致性能瓶颈。为克服这一局限,Schuster和Paliwal于1997年提出了双向循环神经网络(Bi-directional Recurrent Neural Network, Bi-RNN),巧妙地融合了过去与未来的上下文信息,极大地提升了模型的表达力和预测准确性。
2. 双向RNN定理
双向RNN的核心定理在于其通过同时引入正向和逆向两个独立的RNN分支,分别沿时间轴向前和向后传播信息。这两个分支共享相同的权重,但分别从序列的两端开始处理输入,直至在中间相遇。这样,每个时刻的隐藏状态不仅包含了过去的输入信息,还整合了未来输入的影响,实现了对整个序列全局上下文的全面捕捉。
3. 算法原理
(1)正向RNN:沿时间轴正向传播,隐藏状态由当前时刻输入
与前一时刻隐藏状态
共同决定:
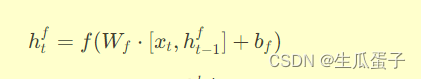
(2)逆向RNN:沿时间轴逆向传播,隐藏状态由当前时刻输入
与后一时刻隐藏状态
共同决定:
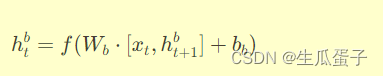
其中,f为激活函数(如tanh或ReLU),、
分别为正向和逆向RNN的权重矩阵,
、
为相应的偏置项。最终,双向RNN在每个时刻的综合隐藏状态
由正向和逆向隐藏状态拼接而成:
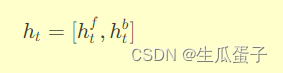
4. 算法实现
在Python中,我们可以使用深度学习框架如TensorFlow或PyTorch来实现双向循环神经网络(Bi-directional Recurrent Neural Network, Bi-RNN)。以下是一个使用PyTorch实现的双向LSTM(Long Short-Term Memory)模型示例,以及代码讲解:
Python
import torch
import torch.nn as nn
class BiDirectionalLSTM(nn.Module):
def __init__(self, input_size, hidden_size, num_layers=1, bidirectional=True, dropout=0.5):
super(BiDirectionalLSTM, self).__init__()
self.rnn = nn.LSTM(input_size=input_size,
hidden_size=hidden_size,
num_layers=num_layers,
bidirectional=bidirectional,
batch_first=True,
dropout=dropout)
self.fc = nn.Linear(hidden_size * 2 if bidirectional else hidden_size, # 乘以2是因为双向的输出是正向和逆向两部分的拼接
output_size)
def forward(self, x):
# x shape: (batch_size, sequence_length, input_size)
outputs, (hidden, cell) = self.rnn(x)
# outputs shape: (batch_size, sequence_length, hidden_size * 2 if bidirectional else hidden_size)
# hidden shape: (num_layers * num_directions, batch_size, hidden_size)
# cell shape: (num_layers * num_directions, batch_size, hidden_size)
# 取最后一个时间步的输出作为最终的序列表示
last_output = outputs[:, -1, :] # shape: (batch_size, hidden_size * 2 if bidirectional else hidden_size)
# 通过全连接层得到最终的分类结果
predictions = self.fc(last_output)
return predictions代码讲解:
-
定义BiDirectionalLSTM类:继承自
torch.nn.Module基类,这是PyTorch中自定义神经网络模块的基础。 -
初始化函数:
input_size:输入特征维度,如词嵌入的维度。hidden_size:LSTM隐藏层的单元数。num_layers(默认为1):LSTM的层数。bidirectional(默认为True):是否启用双向LSTM。dropout(默认为0.5):LSTM层的丢弃比例,用于正则化。
-
定义LSTM层:使用
nn.LSTM类创建一个LSTM层,设置好相关参数。batch_first=True表示输入数据的形状为(batch_size, sequence_length, input_size),便于处理批量数据。 -
定义全连接层:使用
nn.Linear创建一个全连接层,将LSTM最后一层输出(即双向LSTM的拼接输出或单向LSTM的输出)映射到所需输出维度。 -
forward函数:定义模型的前向传播逻辑。-
输入
x:形状为(batch_size, sequence_length, input_size)的输入序列。 -
调用
self.rnn(x)进行LSTM计算。返回值outputs是所有时间步的输出序列,形状为(batch_size, sequence_length, hidden_size * 2 if bidirectional else hidden_size);(hidden, cell)是最后一个时间步的隐藏状态和单元状态,分别包含正向和逆向(若启用)的信息。 -
选取
outputs的最后一项(最后一个时间步的输出)作为整个序列的表示,其形状为(batch_size, hidden_size * 2 if bidirectional else hidden_size)。 -
将该序列表示通过全连接层
self.fc得到最终的预测结果。
-
使用示例:
Python
model = BiDirectionalLSTM(input_size=100, hidden_size=256, output_size=10) # 假设输入维度为100,输出类别数为10
# 假设输入数据x为一批序列,形状为(batch_size, sequence_length, input_size)
predictions = model(x)以上代码实现了基于PyTorch的双向LSTM模型,适用于各类序列数据的处理任务,如文本分类、情感分析等。在实际应用中,可能还需要根据具体任务添加其他组件(如词嵌入层、Dropout层、BatchNorm层等)和调整模型参数。
5. 优缺点分析
优点:
- 全局上下文捕获:双向RNN同时利用过去和未来信息,显著提升对序列数据的建模能力。
- 性能提升:在诸如情感分析、命名实体识别、机器翻译等任务中,双向RNN通常优于单向RNN,尤其是在处理长距离依赖关系时。
缺点:
- 计算成本增加:由于需要同时运行两个RNN分支,双向RNN的计算复杂度和内存消耗约为单向RNN的两倍。
- 实时处理受限:对于实时或流式输入数据,由于无法提前获取未来信息,双向RNN的应用受到限制。
6. 案例应用
双向循环神经网络(Bi-directional Recurrent Neural Network, Bi-RNN)因其独特的结构设计,能够同时捕捉序列数据的过去和未来信息,从而在多个领域中展现出强大的应用价值。以下是对您所列举的几个典型应用领域的详细阐述:
自然语言处理
情感分析:在情感分析任务中,理解文本的情感倾向往往需要考虑整个句子甚至段落的上下文。例如,一个看似负面的词语可能在特定语境下表达积极情感。双向RNN能够同时兼顾句子前后信息,帮助模型准确判断情感极性。例如,对于句子“这部电影虽然情节平淡,但是演员演技出色”,仅依赖于前向信息可能会误判为负面评价,而双向RNN能结合后向信息(“但是演员演技出色”),得出更准确的情感判断。
命名实体识别(NER):在识别文本中的人名、地名、组织机构名等实体时,双向RNN能有效利用词汇的前后语境来确定实体边界和类别。例如,对于“我在哈佛大学读书”,双向RNN在识别“哈佛大学”时,不仅考虑“哈佛”前面的“我在”,还考虑后面紧跟的“读书”,结合前后文信息更准确地区分出“哈佛大学”是一个教育机构名称,而非人名或其他类型实体。
文本分类:无论是新闻分类、主题分类还是垃圾邮件检测等任务,双向RNN都能全面理解文本的整体意义,不受限于局部词汇的影响。例如,在判断一封邮件是否为垃圾邮件时,单凭某一句可能不足以做出准确判断,而双向RNN能综合全文的上下文线索,更准确地识别出垃圾邮件的特征。
机器翻译:在翻译过程中,正确理解源语言句子的完整含义并准确生成目标语言句子,需要对原文的前后文有深刻把握。双向RNN在编码阶段就能全面捕捉源语言句子的上下文信息,使得解码阶段生成的目标语言句子更连贯、准确。
语音识别
在语音识别系统的声学建模阶段,双向RNN能够捕捉语音信号中音素(phoneme)之间的复杂时间依赖关系。语音信号中,音素的发音并非孤立发生,而是受到前后音素的影响,如连读、重音转移等现象。双向RNN通过正向和逆向两个路径同时处理语音特征序列,能更好地理解这些时间依赖关系,从而提高声学模型对音素边界的识别精度,进而提升整个语音识别系统的准确率。
时间序列预测
尽管双向RNN在实时处理中受限(因为它需要看到完整的序列才能进行有效预测),但在某些历史与未来关联性强的预测任务中仍然有用武之地。例如:
电力负荷预测:在预测电网负荷时,不仅需要考虑历史用电数据(如过去一周、一个月的用电情况),也需要考虑未来可能影响负荷的因素,如天气预报、节假日安排等。双向RNN能同时利用这些历史数据和未来预测信息,提高电力负荷预测的准确性,有助于电网调度和能源管理。
股票价格分析:股票价格受到众多因素影响,包括历史价格走势、市场情绪、公司财务状况、宏观经济指标等。虽然实时交易中双向RNN的应用受限,但在离线分析或日内策略制定时,双向RNN能够结合历史价格数据和未来已知的市场信息(如即将发布的经济报告、公司公告等),对股票价格走势进行更精准的预测。
总结来说,双向RNN通过同时利用序列数据的前后信息,显著提升了模型在处理自然语言、语音信号以及时间序列数据时的性能,使其在多个领域中成为不可或缺的工具。尽管在实时性要求高的场景中有所局限,但在许多情况下,其带来的性能提升足以弥补这一不足。随着计算资源的不断提升和模型优化技术的进步,双向RNN在未来的应用前景将更加广阔。
7. 对比与其他算法
与单向RNN对比:双向RNN明显优于单向RNN,能更充分地利用序列上下文信息,尤其在处理长距离依赖问题上表现更佳。
与Transformer对比:虽然Transformer无需递归计算,通过自注意力机制也能捕获全局上下文,但双向RNN在计算资源有限或序列长度较短的场景下,仍具竞争力。此外,双向RNN结构相对简单,易于理解和实现。
8. 结论与展望
双向循环神经网络通过引入正向和逆向传播机制,成功克服了标准RNN对序列未来信息利用不足的问题,显著提升了对序列数据的建模能力。尽管面临计算成本增加、实时处理受限等挑战,其在自然语言处理、语音识别、时间序列预测等领域仍有着广泛且重要的应用。未来,随着计算资源的持续优化和新模型架构的涌现,双向RNN有望与自注意力机制、轻量级RNN变种等技术相结合,进一步提升序列建模性能,服务于更广泛的现实应用场景。

















 690
690

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









