







ChangeCLIP:多模态遥感变化检测视觉语言表征学习
论文发表期刊、作者及发表年份:isprs
Sijun Dong , Libo Wang , Bo Du , Xiaoliang Meng
2024
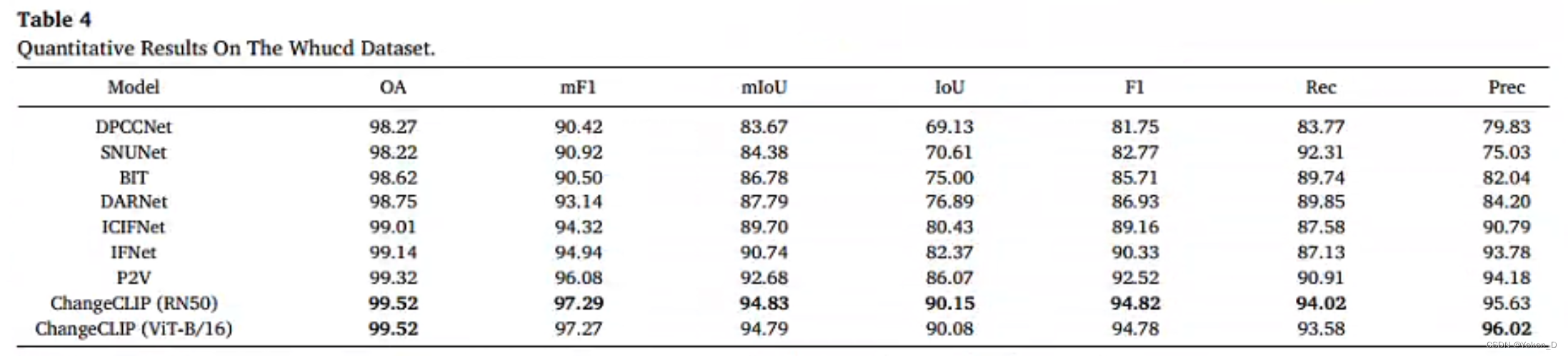
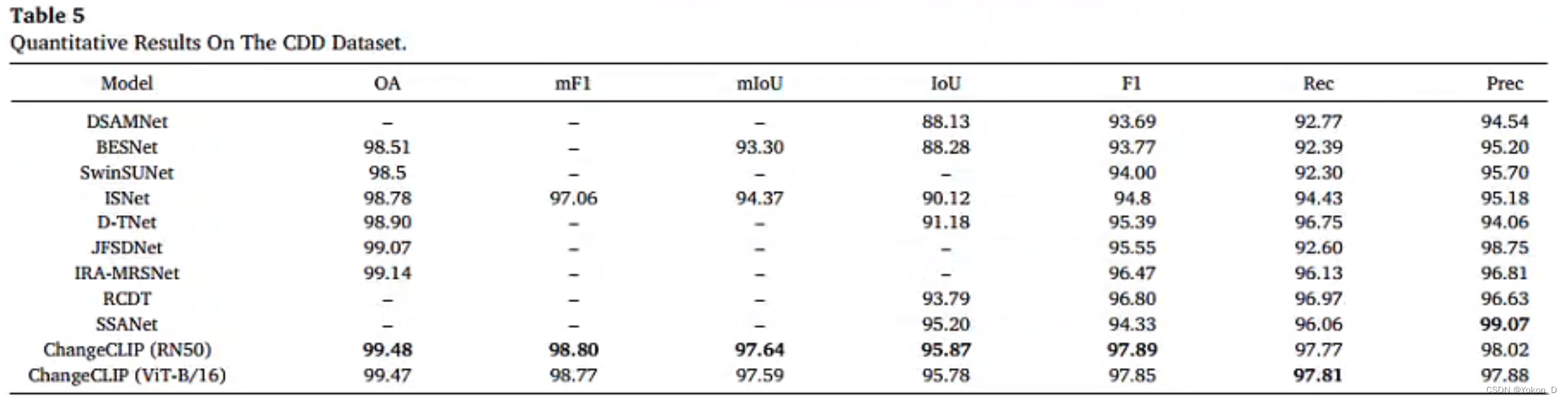
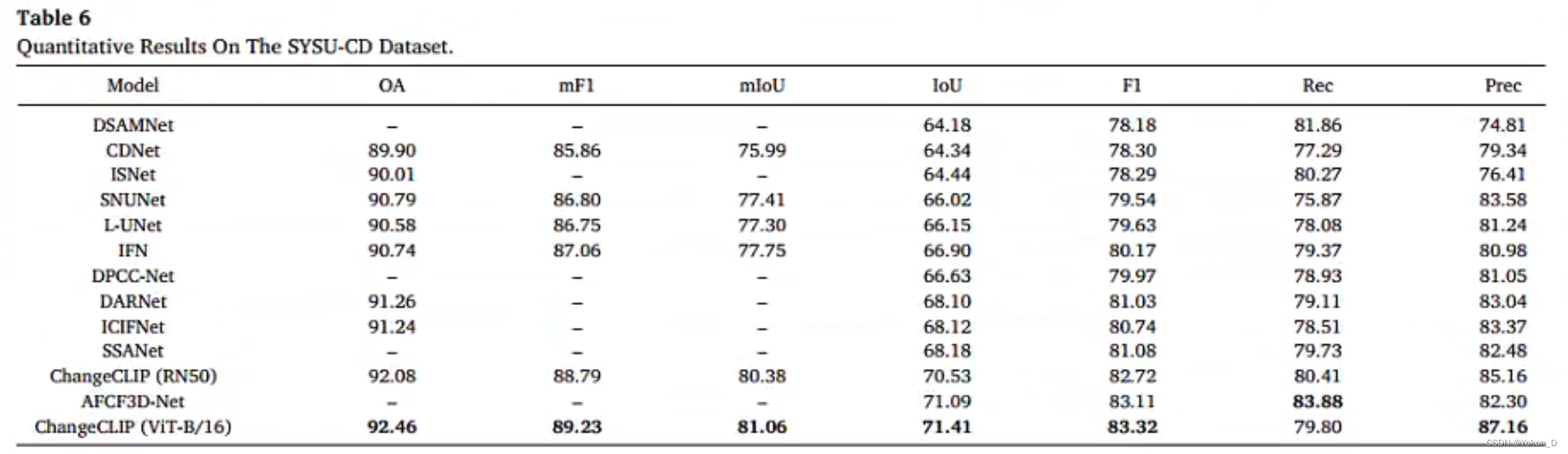
论文摘要:遥感变化检测(RSCD)旨在从双时相图像中识别地表变化,在环境保护和灾害监测等许多应用中具有重要意义。近十年来,在人工智能浪潮的推动下,出现了许多基于深度学习的变化检测方法,并取得了重大突破。然而,这些方法更多地关注视觉表征学习,而忽略了多模态数据的潜力。最近,基础视觉语言模型,即CLIP为多模式人工智能提供了一个新的范例,在下游任务上展示了令人印象深刻的性能。顺应这一趋势,在本研究中,我们引入了ChangeCLIP,这是一个利用图像-文本对的鲁棒语义信息的新框架,专门为遥感变化检测(RSCD)量身定制。具体而言,我们对原始CLIP进行重构以提取双时相特征,并提出了一种新的差分特征补偿模块来捕获它们之间的详细语义变化。此外,我们提出了一种视觉语言驱动的解码器,将图像-文本编码的结果与解码阶段的视觉特征相结合,从而增强图像的语义。ChangeCLIP在LEVIR-CD(85.20%)、LEVIR-CD+(75.63%)、WHUCD(90.15%)、CDD(95.87%)和SYSU-CD(71.41%) 5个著名的变化检测数据集上实现了最先进的IoU。ChangeCLIP的代码和预训练模型将在https://github.com/dyzy41/ChangeCLIP上公开提供。
论文面对的问题及问题原因
总体问题:论文面对的问题主要是如何有效地进行建筑物变化检测,以及如何从多模态数据中提取有意义的特征。问题原因主要有两个方面:一是现有的变化检测方法主要基于单模态数据,忽略了多模态数据中丰富的语义信息,这使得其性能受到限制;二是现有的特征提取方法难以提取稳健和有区别的特征,这使得变化检测的准确性和鲁棒性受到影响。
问题一:在ImageNet数据集上训练的预训练模型可能并不完全适合深度学习遥感图像任务,因为ImageNet本身的数据属性与遥感图像的数据属性不一致。遥感图像包含不同的特征,如建筑物、道路、植被、水体以及其他在ImageNet数据集中不存在的人造或自然物体。常用的基于ImageNet数据集的预训练模型不能充分捕捉遥感数据的独特特征。除了利用多模态预训练模型进行遥感特征学习外,我们还将多模态学习纳入RSCD。在这些自监督学习策略中,学习通常局限于从训练数据中充分捕获图像特征,这可能导致对遥感图像语义信息的理解有限。
问题二:很少有研究利用多模态学习来完成RSCD任务。一个原因是缺乏专门为遥感图像设计的多模态变化检测数据集。另一个原因是缺乏一个全面的多模态RSCD算法框架。
问题三:语义分割的目标具有一个或多个特定的语义。然而,遥感图像变化检测的目标变化面积是一个抽象的概念。换句话说,语义分割侧重于分割具有特定含义的对象,例如建筑物或道路。相比之下,RSCD旨在识别随时间变化的区域,而不知道是什么导致了变化。变化区域的抽象性质使得RSCD比语义分割更具挑战性。
问题四:当前的算法侧重于构建全局关注机制或提高特征提取器的表示能力,而不是侧重于增强差分特征的学习。它们忽略了差分特征表示在RSCD中的重要性,因此这些方法很难学习到不同类型的变化特征
针对性提出方法
方法总体概述:在本文中,我们将CLIP引入RSCD任务,并提出了一个多模态变化检测框架,即ChangeCLIP。在多模态变化检测任务的背景下,我们通常使用单一模态,主要是遥感图像,来识别变化。为了结合基于文本的线索,我们使用CLIP模型根据56个常见土地覆盖类别的分类生成描述性提示,这些类别包含了遥感数据集中常见的大多数目标元素。为了便于参考,我们进一步将这56种类型分为更广泛的类别。我们以CLIP模型为基础,针对遥感图像的前景和背景特征设计了特定的提示。这种方法能够构建一个丰富了多模态先验的基本数据集,用于变化检测任务。在图像编码阶段,我们构建了暹罗神经网络,从双时遥感图像中提取图像特征。在文本编码阶段,我们应用变压器网络从文本提示符中提取文本特征。为了利用多模态特征学习的好处,我们在ChangeCLIP中有效地结合了视觉和文本特征。此外,我们提出了一种新的差分特征补偿(DFC)模块输出语义变化。
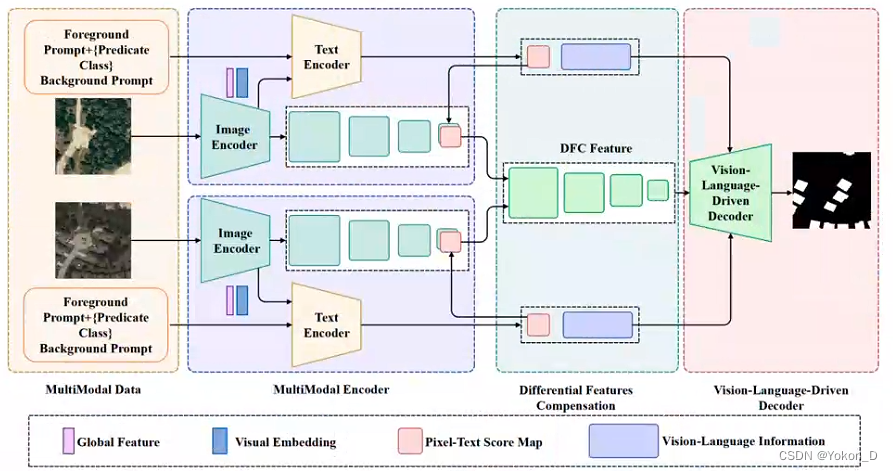
ChangeCLIP变更检测架构。全局特征是从图像中获得的具有识别目标能力的特征信息。视觉嵌入是作为图像嵌入的高级特征映射。像素-文本评分图是图像和文本提示符之间的相关性图。视觉语言信息意味着我们将图像特征和文本特征结合起来。
提出的ChangeCLIP是第一个将多模态视觉语言方案应用于RSCD任务的工作。
提出了一种新的差分特征补偿模块,以捕获双时图像特征的鲁棒语义变化。
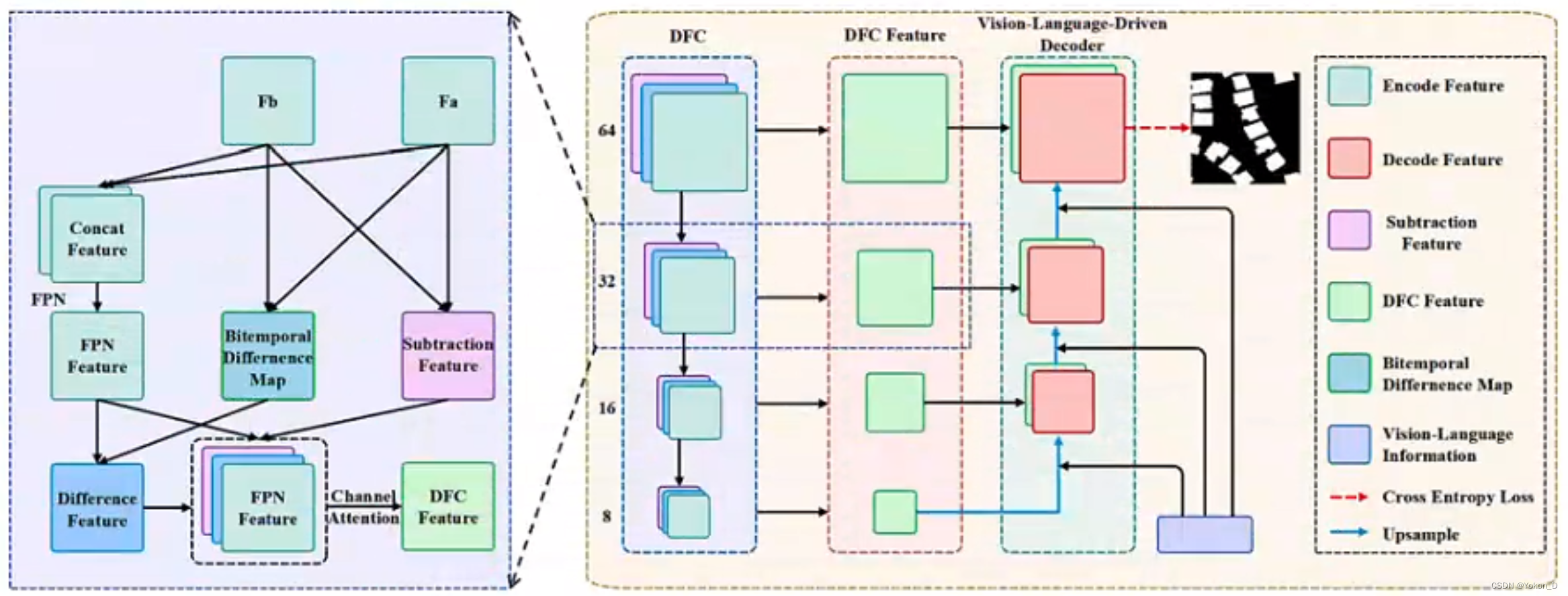
所提出的ChangeCLIP串联特征的差分特征补偿模块和解码结构是指在编码阶段对双时图像进行串联得到的特征映射。双时差分映射是指由余弦相似度计算得到的差分映射。减法特征是指对双时图像的特征映射进行减法。
设计了一种基于变换的多模态解码器,增强了图像-文本特征对之间的语义关系。
达到效果
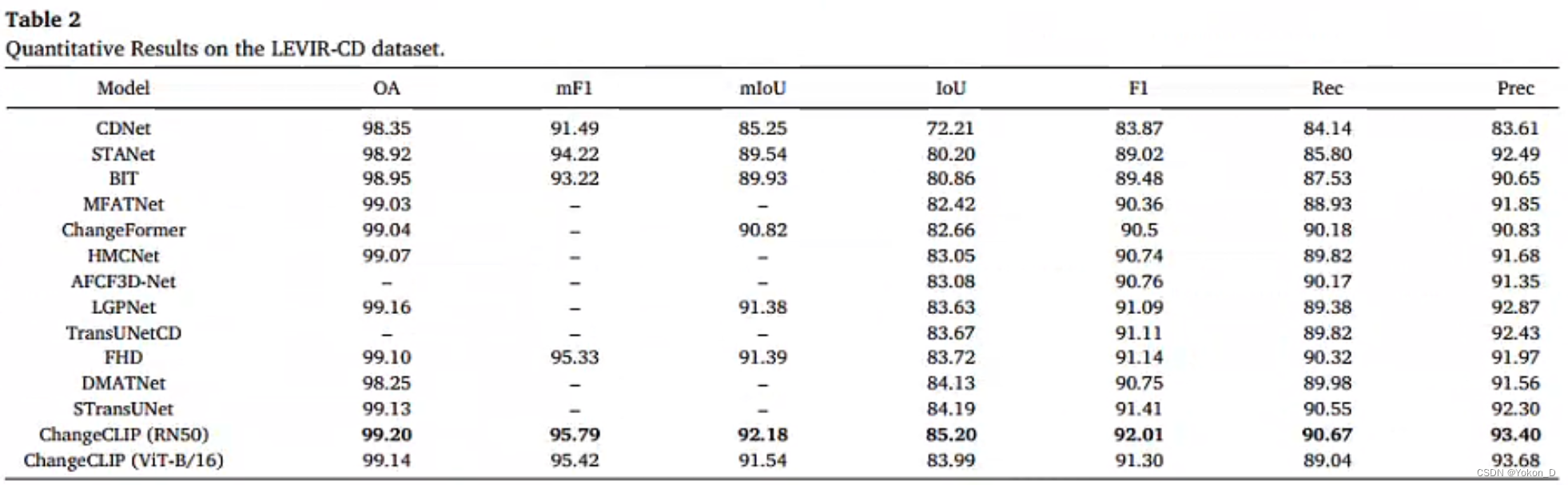
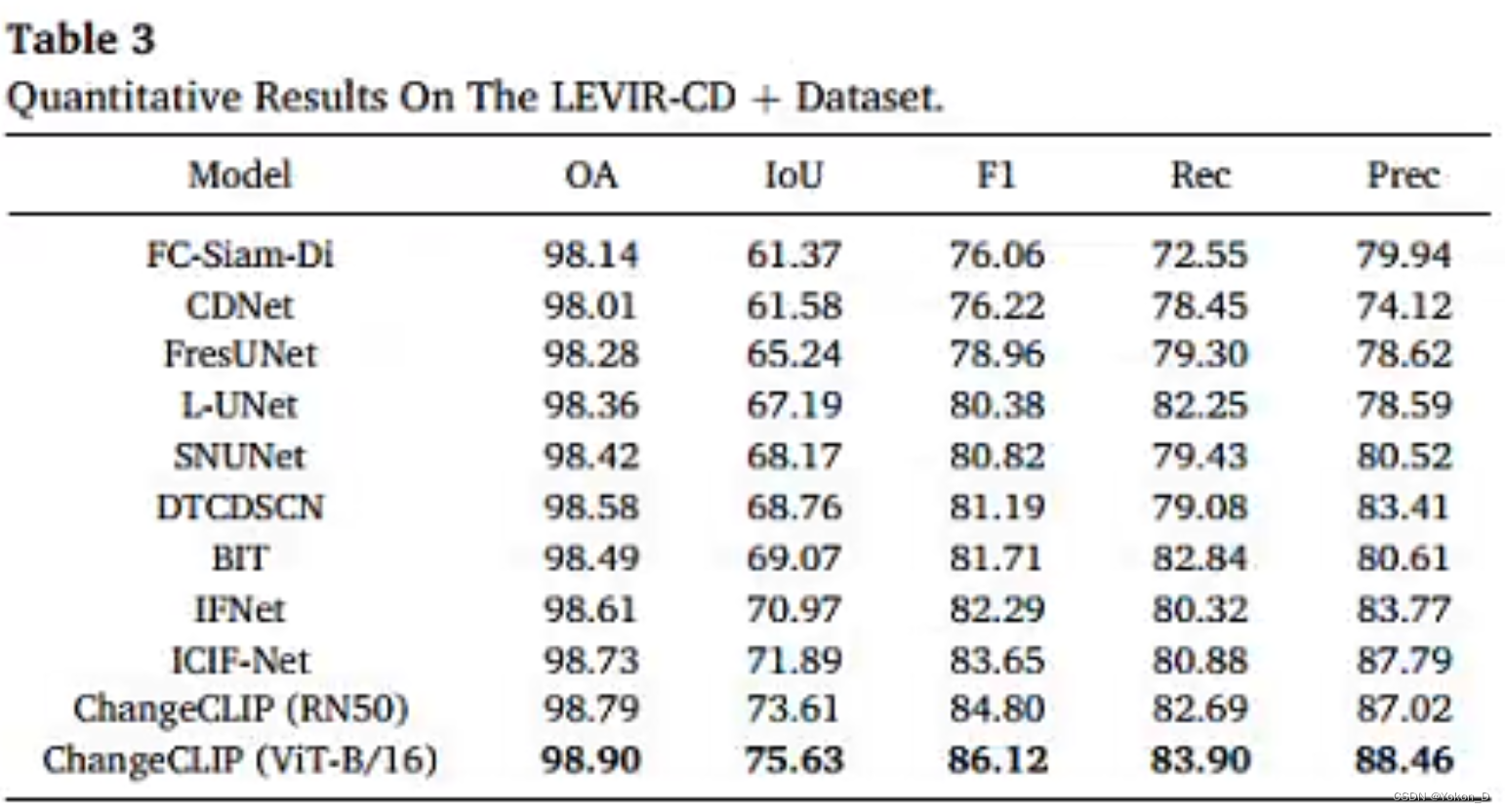
ChangeCLIP在LEVIR-CD、LEVIR-CD+、CDD、SYSU-CD和WHUCD数据集中实现了最先进的性能。
方法的未来工作及不足
数据质量:未来的工作需要更深入地研究如何处理低质量数据,包括噪声、缺失值和异常值等问题。这可能需要开发新的算法和技术,以便更有效地处理这些问题。
泛化能力:方法的泛化能力是一个关键问题。未来的研究需要关注如何提高模型的泛化能力,以使其能够更好地适应不同的数据集和应用场景。
可解释性:许多现代机器学习模型被认为是“黑箱”模型,因为它们的内部工作原理和决策过程很难解释。为了增强人们对这些模型的可信度,未来的工作需要更深入地研究如何提高模型的解释性。
可扩展性:随着数据集的规模不断增大,模型的计算成本和内存需求也越来越高。未来的工作需要更深入地研究如何提高模型的扩展性,以使其能够更好地处理大规模数据集。
引文格式
面对遥感变化检测(RSCD)领域中只考虑单模态数据而忽略多模态数据中丰富语义信息的问题,本文引入了 ChangeCLIP,这是一个新的框架,利用来自图像-文本对的强大语义信息,专门为遥感变化检测(RSCD)量身定制。ChangeCLIP 通过提取双时态特征,提出差分特征补偿模块来捕捉它们之间的详细语义变化,并利用视觉语言驱动的解码器增强图像语义。在 5 个著名的变化检测数据集上,ChangeCLIP 实现了最先进的 IoU,表明了其有效性。然而,本文也指出,尽管 ChangeCLIP 在 RSCD 方面取得了显著成果,但仍面临如何进一步提高性能、扩展到更大规模数据集以及实际应用等方面的挑战。因此,需要进一步研究和探索如何将多模态信息融入 RSCD 任务中,以推动该领域的发展。



















 732
732

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











