







本节主要讲了Self-Attention的原理以及在Transformer上的应用。
1.1 RNN的缺点
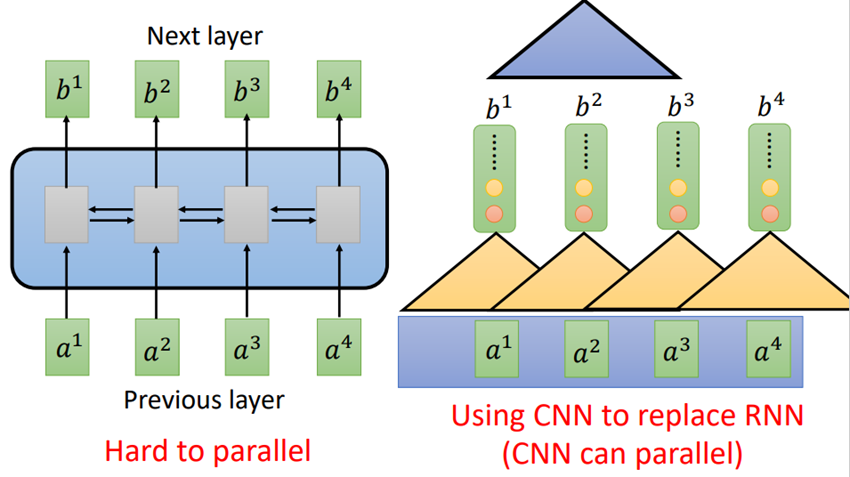
RNN的缺点就是无法并行计算参数,就比如要计算b4,就要计算出a1-a4。有人提出用CNN代替RNN:
优点:可以并行处理参数;
缺点:单层的CNN只能考虑非常有限的内容,若要考虑更多的内容就需要叠加很多层。
1.2 Self-Attention
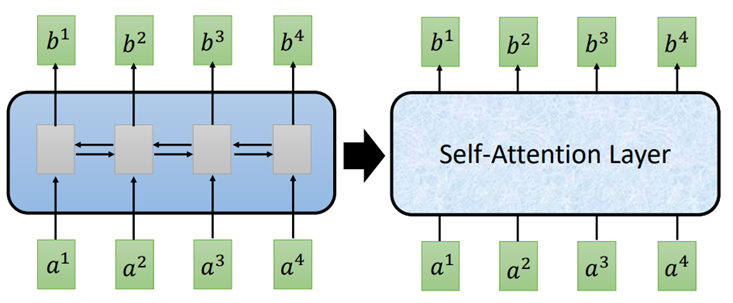
Self-Attention的输入输出与RNN一样,都是sequence。它和双向RNN有同样的能力,每一个输出都是看过整个input sequence,区别就在于b1-b4可以并行计算。
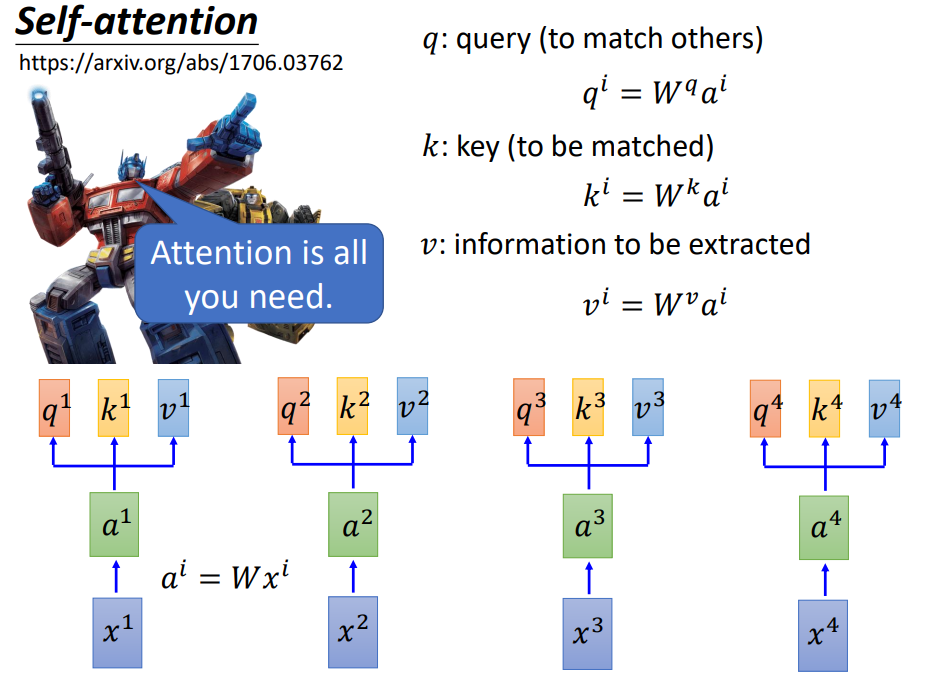
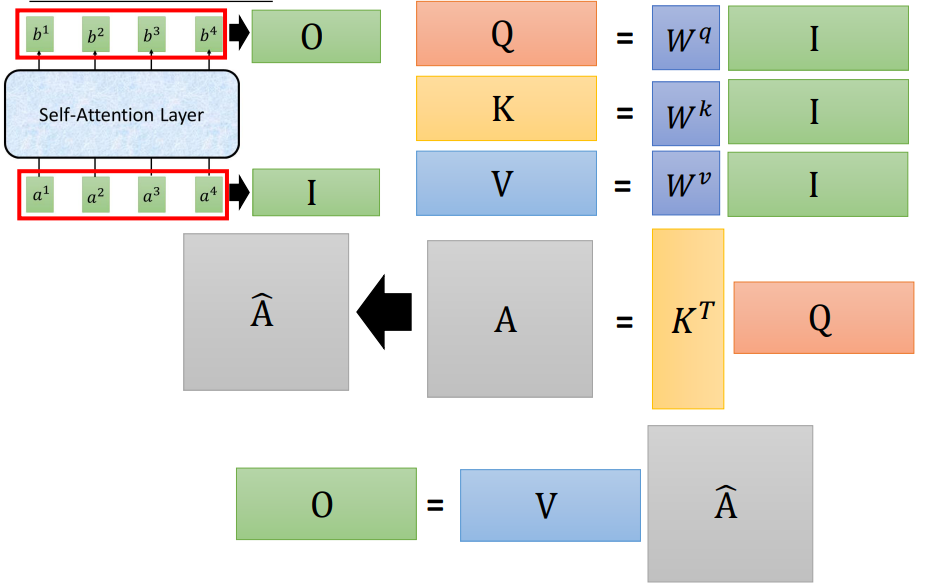
先将输入x(sequence)通过矩阵W,转换成a(embedding),然后用a乘上三个不同的矩阵得到三个向量q、k、v。
先将输入x(sequence)通过矩阵W,转换成a(embedding),然后用a乘上三个不同的矩阵得到三个向量q、k、v。
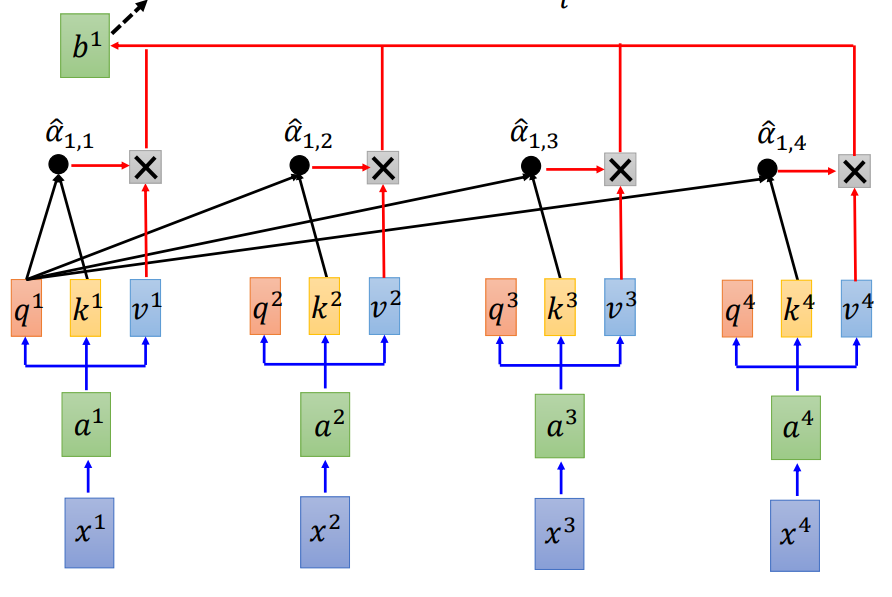
然后用每个q去对每个k进行attention运算,得到![]() -
-![]() ,再进行soft-max处理得到对应的
,再进行soft-max处理得到对应的![]() 。
。

将![]() 与v相乘加权得到b。
与v相乘加权得到b。
上述过程可以用矩阵运算表示,就可以并行处理。
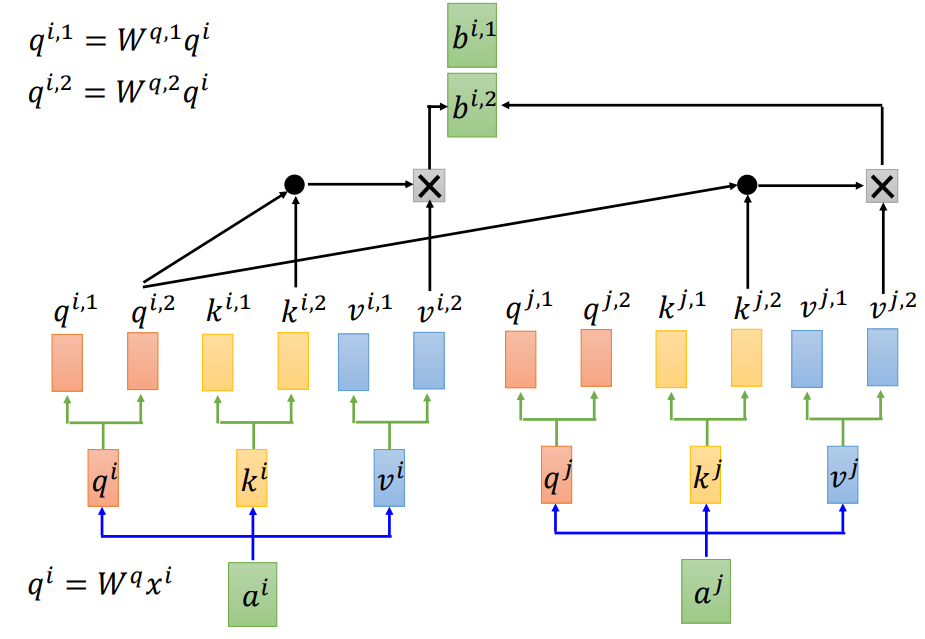
- Multi-head Self-attention
以两个head为例,就是把q、k、v分成两个单独的向量,最后得到的输出向量b也是两个,可以乘上一个矩阵![]() 进行降维得到b。这样做的好处就是,不同head的注意点不同,一个head的关注范围是全局,另一个是局部。
进行降维得到b。这样做的好处就是,不同head的注意点不同,一个head的关注范围是全局,另一个是局部。
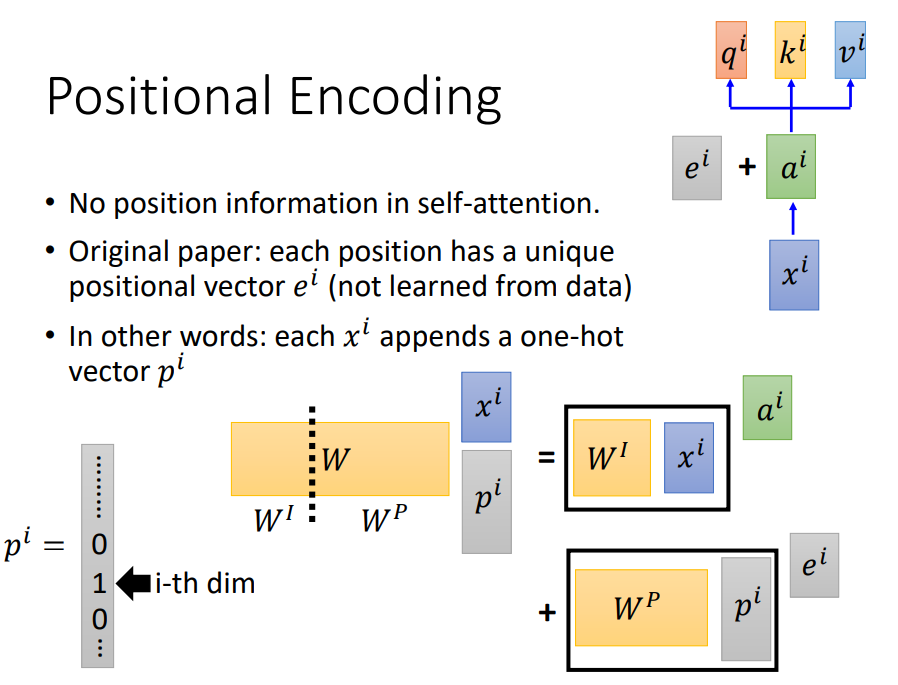
- Position Encoding
在原始文献中,用超参数e来代表位置信息。视频中提到的一种方法,用one-hot向量来代表位置信息,然后和x拼接,与W相乘,得到结果和论文中的一样。
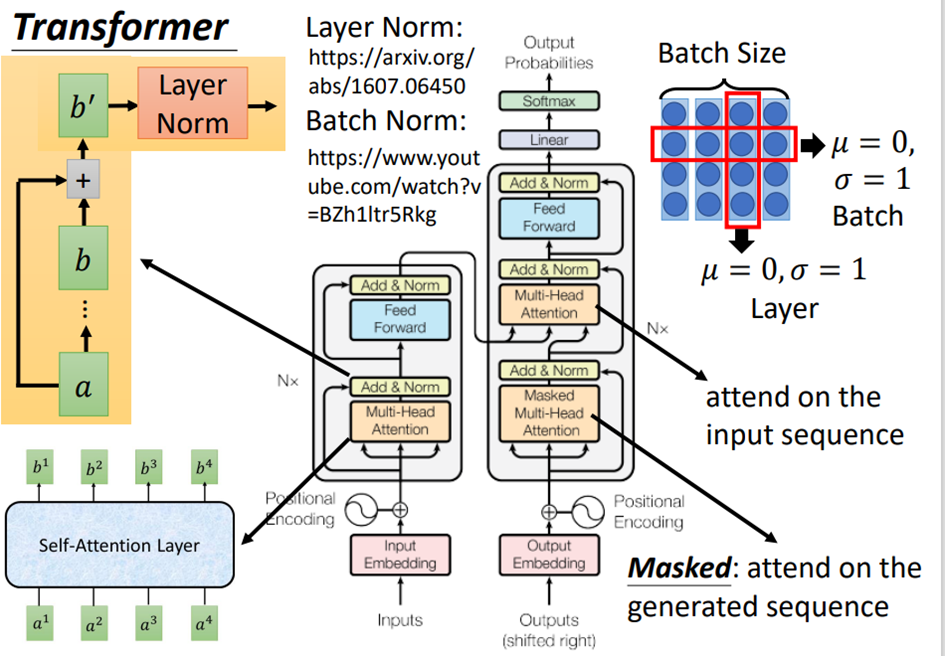
1.3 Transformer
下图是一个seq2seq 模型,左半部是encoder,右半部是decoder。
Encoder:
输入通过一个input embedding layer变成一个向量,然后加上一个位置向量进入灰色的block,这个block会重复多次。
第一层是Multi-head attention,输入一个sequence,输出另一个sequence;
第二层是Add&Norm:把Multi-head attention的输入和输出加起来得到b′,然后做layer Norm;
第三层是Feed Forward,会把sequence 的每个b′向量进行处理;
第四层是另一个Add&Norm。
Decoder:
decoder的输入是前一个时间点的输出,通过output embedding,再加上位置向量进入灰色的block,灰色block同样会重复多次。
第一层是Masked Multi-head attention,Masked的意思是,在做self-attention的时候,这个decoder只会append已经产生的sequence,因为没有产生的部分无法做attention;
- Application
只要用seq2seq的任务都可以换成transformer,比如机器翻译,文献摘要等。
















 40万+
40万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









