






Abstract
Visual grounding着重于在视觉和自然语言之间建立细粒度的一致性, 现有方法使用预先训练的与查询无关的视觉主干来独立提取视觉特征映射,而不考虑查询信息。 本文认为从视觉主干中提取的视觉特征与多模态推理真正需要的特征是不一致的。一个原因是与训练任务和visual grounding任务之间是由差距的,由于骨干网络和query无关,很难完全避免不一致问题。本文提出了一种基于查询感知动态注意(QD-ATT)机制和查询感知多尺度融合的查询调制细化网络(QRNet),通过调整视觉主干中的中间特征来解决不一致问题。QD-ATT可以在由视觉主干生成的特征映射的空间和通道级别上动态计算与查询相关的视觉注意。
Introduction
之前的方法用的视觉backbone提取的特征与推理所需要的特征是不一致的,给定相同的image,无论查询语句是什么,与query无关的visual backbone始终输出相同的视觉特征
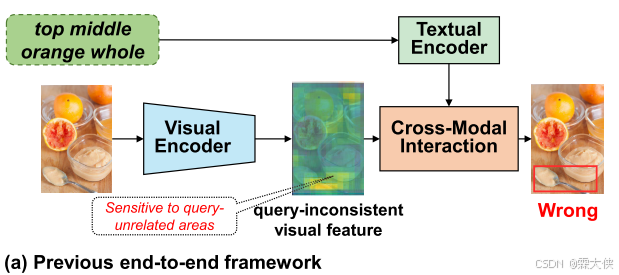
本文提出的QRNet可以结合query产生与query一致的视觉特征,这有利于query和相关区域之间的跨模态对齐,从而做出正确的预测。QRNet是基于swing transformer和一种新颖的查询感知动态注意(QD-ATT)设计的,QD-ATT在视觉特征上动态地计算文本依赖的视觉注意,将空间和通道关注与原始特征映射相乘,得到查询精细化的分层视觉特征映射。
Approach
Architecture
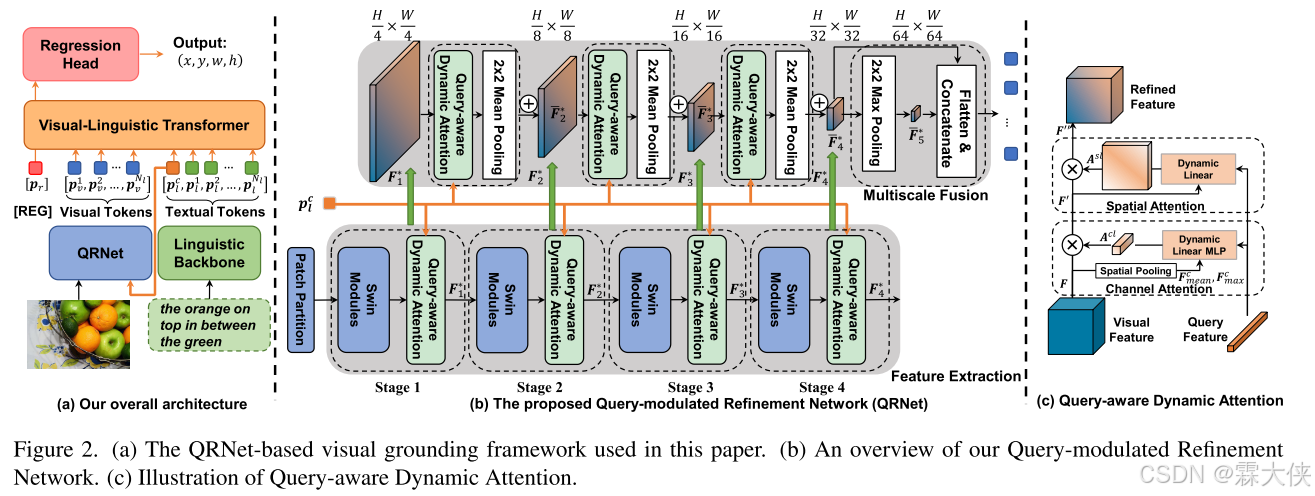
如图2 (a)所示,框架是基于典型的端到端可视化接地架构TransVG设计的。
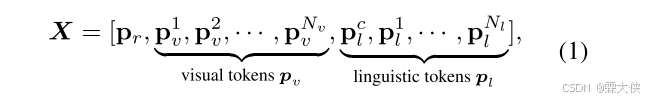
pr是[REG]令牌的可学习嵌入。 pcl是[CLS]文本token的表示,被视为上下文文本特征。然后,应用多层视觉语言转换器对联合序列进行模态内和模态间推理。 最后,预测头采用[REG]令牌的输出表示来预测边界框坐标b。使用平滑L1损失和giou损失来训练框架,损失为:
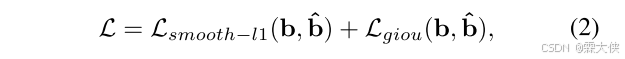
Query-modulated Refinement Network
查询调制细化网络(QRNet)的视觉主干网络,主要包含两个部分:(1)查询细化特征提取(query-refined Feature Extraction),提取具有层次结构的查询细化视觉特征图;(2)查询感知多尺度融合(query- aware multi - scale Fusion),在查询特征的引导下融合提取的不同尺度特征图。这两个阶段都依赖于QD-ATT,它在空间和通道维度动态地计算依赖于文本的视觉注意。
Query-aware Dynamic Attention

在图2(c)中展示了这个模块,有一个动态线性层,用来计算query-aware通道和空间注意,并获得与query一致的视觉特征。
Dynamic Linear Layer:可以利用上下文特征pcl来指导从给的输入向量zin到zout的映射,用于根据不同的文本查询调整图像的视觉特征映射,形式如下:
动态线性层的关键在于,它通过上下文文本特征 pcl来动态地计算权重矩阵 Wl和偏置 bl,而这些权重和偏置的计算不是固定的,而是与文本查询相关联的。



最终就可以表达成如下:
Channel and Spatial Attention:特征图的每个通道或每个区域的重要性应该根据查询语句动态变化,根据查询文本动态调整图像特征的通道注意力和 空间注意力,以便更好地进行跨模态对齐(cross-modal alignment)。
计算通道注意力的过程:
(1)首先通过平均池化和最大池化对其空间信息进行聚合得到![]()
(2)动态多层感知机和激活函数:
(3)将F与获得的通道注意力图做element-wise multiplication
空间注意力的计算:
(1)压缩维度:不对空间信息进行池化,而是通过一个 动态线性层 来减少通道维度,从而将输入的特征图压缩为空间维度的关注区域,会生成空间注意力图Asl
(2)做element-wise multiplication

Query-refined Feature Extraction
这个初始特征图 F0被输入到由 多个 Swin-Transformer block 和 QD-ATT(Query-aware Dynamic Attention)模块 组成的四个级联的阶段(stages)中。
- Swin-Transformer:Swin-Transformer 是一种基于 Transformer 的视觉模型,通过滑动窗口和局部注意力机制来提取图像的高级特征。每个阶段的 Swin-Transformer block 会根据前一阶段的输出特征图进行计算,逐步生成更精细的特征图。
- QD-ATT(Query-aware Dynamic Attention)模块:这个模块的作用是基于给定的查询文本来动态地调整每个阶段的图像特征。具体来说,这个模块会根据输入查询文本(通过 BERT 获取的 [CLS] token 表示)生成 查询感知的注意力图,然后对视觉特征进行加权,从而使得视觉特征更加关注与查询文本相关的部分。
Query-aware Multiscale Fusion
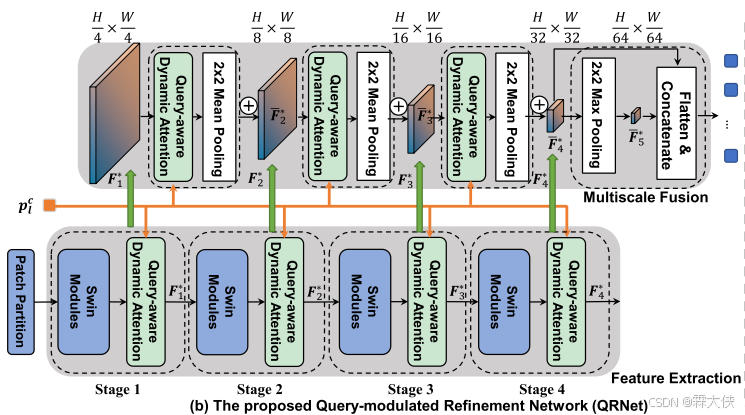
多亏Swin Transformer,我们可以获得多尺度信息,通过查询感知的动态关注机制和池化操作,将不同阶段获得的特征融合在一起。Swin-Transformer 本身有多个阶段(stages),每个阶段的输出特征图的分辨率逐渐降低,但每个阶段提取的特征都包含不同层次的信息。在每个阶段,Swin-Transformer 使用 patch merging 操作 来合并特征块,同时降低特征图的分辨率,并通过增加通道数来保留更多信息。
- 在图的上半部分,展示了多尺度特征的融合过程。首先,使用1×1卷积层将不同阶段的通道维度统一到D。
- 对于前三个阶段的特征图(F1, F2, F3),应用QD-ATT模块来产生加权特征图。然后,通过2×2的平均池化(mean pooling)降低分辨率,使其与下一个阶段的特征图(F(k+1))相同。
- 将池化后的特征图与下一个阶段的特征图进行平均,得到新的特征图(F̄*(k+1))。
- 对于最后一个阶段(Stage 4),使用2×2的最大池化(max pooling)来获得H/64×W/64的特征图(F̄*5)。


















 2170
2170

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









