






文章目录
前言
毕设学习记录,本次毕设主要是做一个基于嵌入式开发的落石检测系统,我主要负责的是AI模型的选取和训练。这里主要涉及到目标检测和石头的识别。即是Localization+Classification
定位:找到检测图像中带有一个给定标签的单个目标。
检测:找到图像中带有给定标签的所有目标。
一、模型选取和学习
根据调研发现yolov5参考资源更多且更适合嵌入式开发
模型选取调研记录
YOLO系列选取记录
一、 选择的标准
- 性能和准确度:不同版本的 YOLO 在性能和准确度上可能存在差异。
YOLOv5 是由 Ultralytics 开发的一个独立版本。它基于 YOLOv3 和 YOLOv4 进行了一些改进,提供了更高的准确度和速度。YOLOv5 通过引入新的特征提取网络、精细的数据增强和训练技巧,以及轻量级模型版本,使得在一些资源受限的场景下具有较好的性能。
二、环境的搭建
1.推荐顺序
anaconda–>CUDA—>CUDNN–>Pycharm–>Visual studio
主要参考这个博主搭建的,按着顺序来基本没什么大问题。
提示:一定要注意版本的要求,一一对应!
链接: link
2.搭建出现的问题
2.1 安装Pycharm
可以先把镜像源给配置了,这样一会安装所需要的库时会很快完成。
2.2 在完成安装所有库,接着跑项目时出现
requirements: importlib-resources; python_version < “3.7” not found and is required by YOLOv5, attempting auto-update。
意思是YOLOv5 需要 importlib-resources 库,但当前环境的 Python 版本小于 3.7,而这个库在 Python 3.7 以下的版本中需要手动安装,在终端输入即可。
pip install importlib-resources
3.结果显示
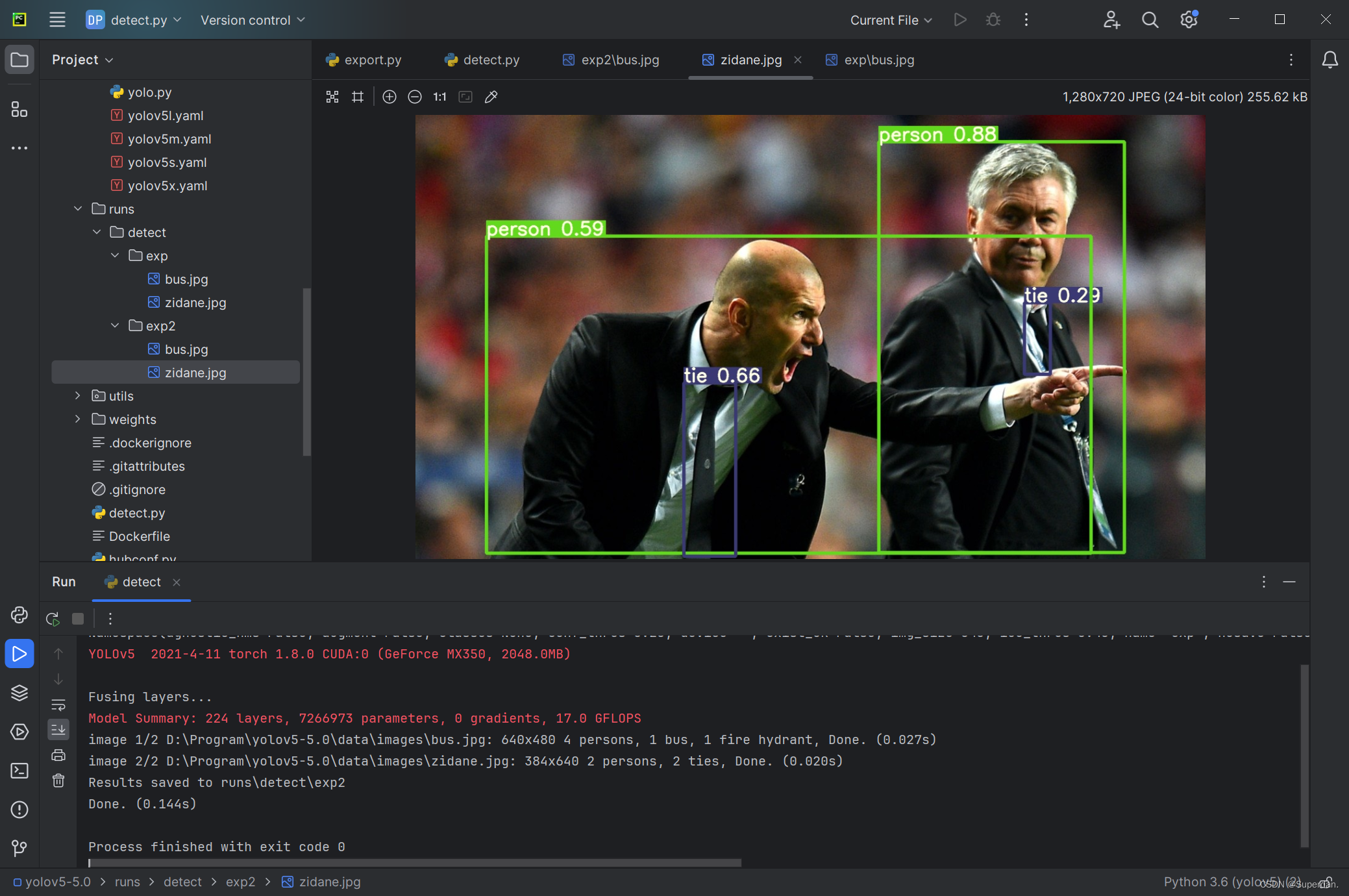
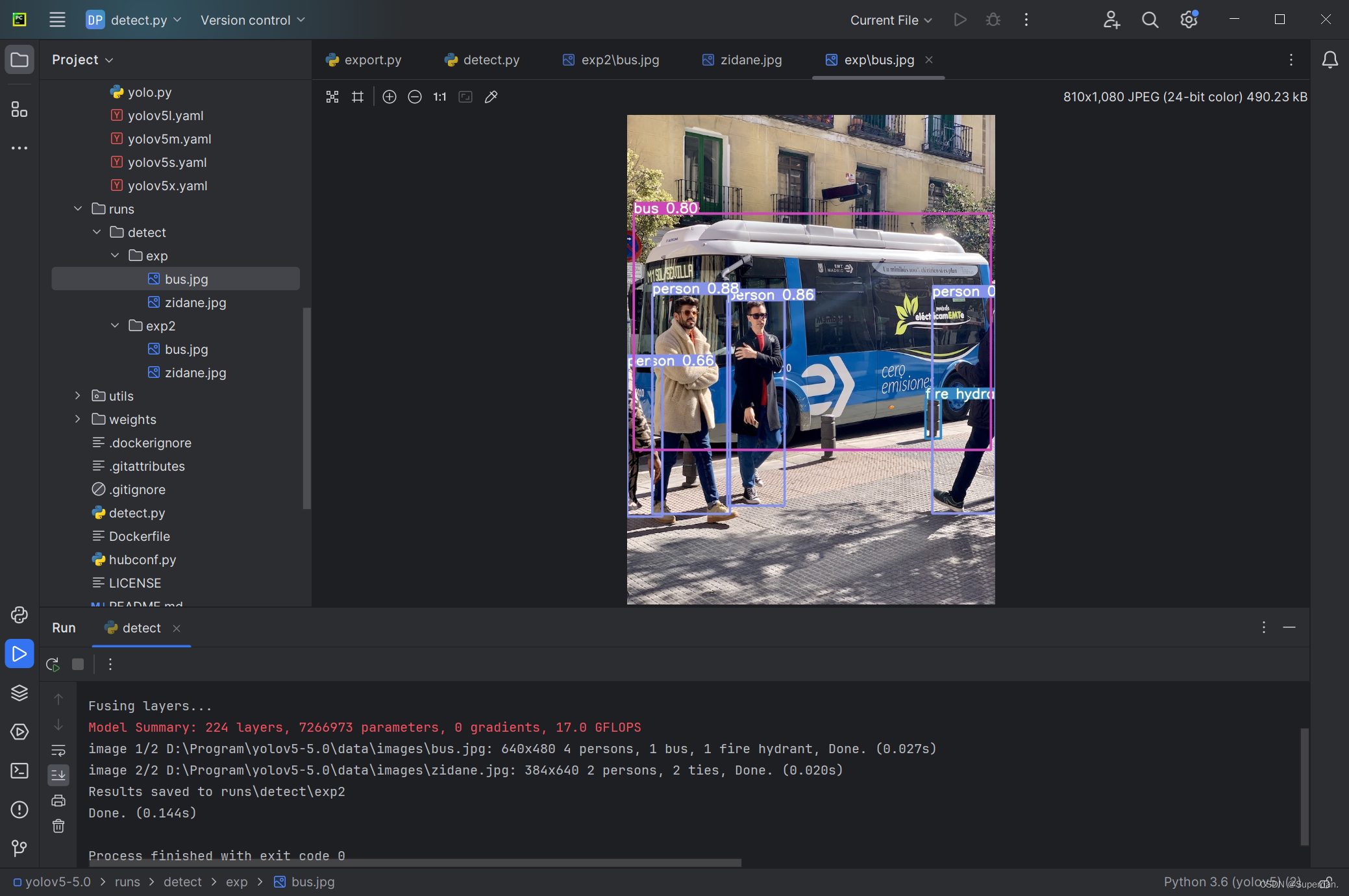
至此环境搭建结束。
利用YOLOV5训练自己的数据:
出现问题一:
No labels in D:\Program\yolov5-5.0\VOCData\dataSet_path\train.cache. Can not train without labels.

发现没有找到images文件,注意将存放jpg的图片文件名更改为images。
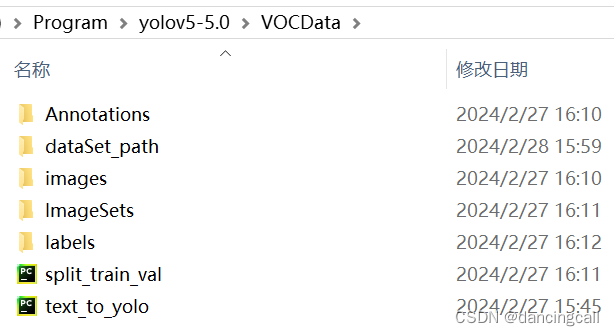
修改后的文件如图
出现问题二:

虚拟内存不足,需要降低线程–我降低为4了。
出现问题三:
UnicodeDecodeError: ‘gbk’ codec can’t decode byte 0xad in position 3: illegal multibyte sequence
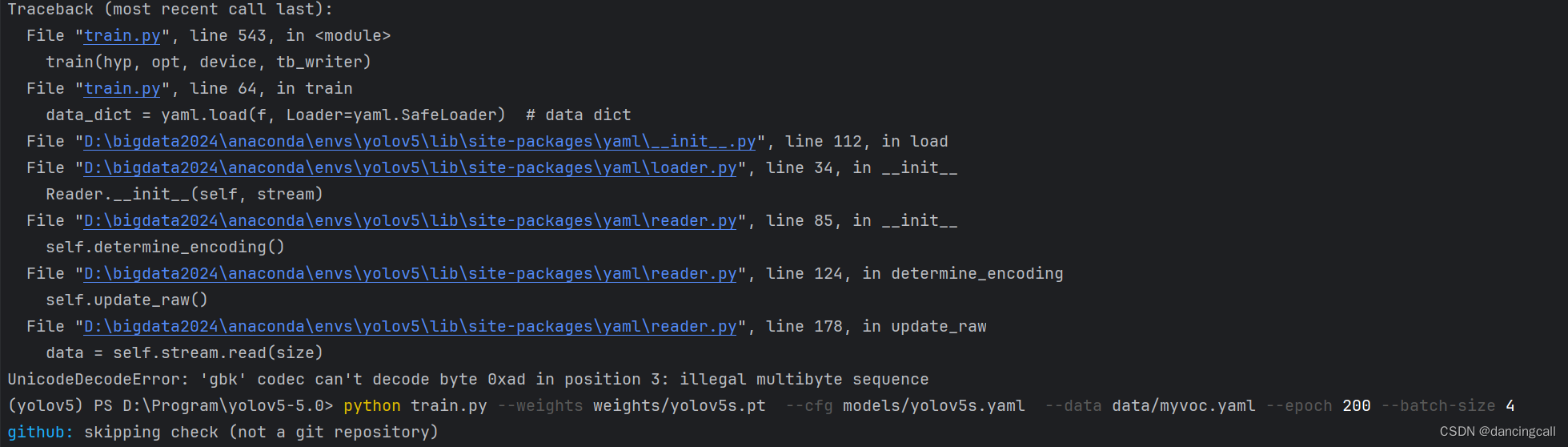
意思是读取train和val的txt文件出现问题,回到配置文件,注意包括注释不要有中文,不要有空行。

出现问题四:
当我更改权重参数将yolov5s->yolov5m时出现以下问题:
CUDA out of memory. Tried to allocate 20.00 MiB (GPU 0; 2.00 GiB total capacity; 1.08 GiB already allocated; 1.35 MiB free; 1.09 GiB reserved in tota
l by PyTorch)
模型太大超出内存
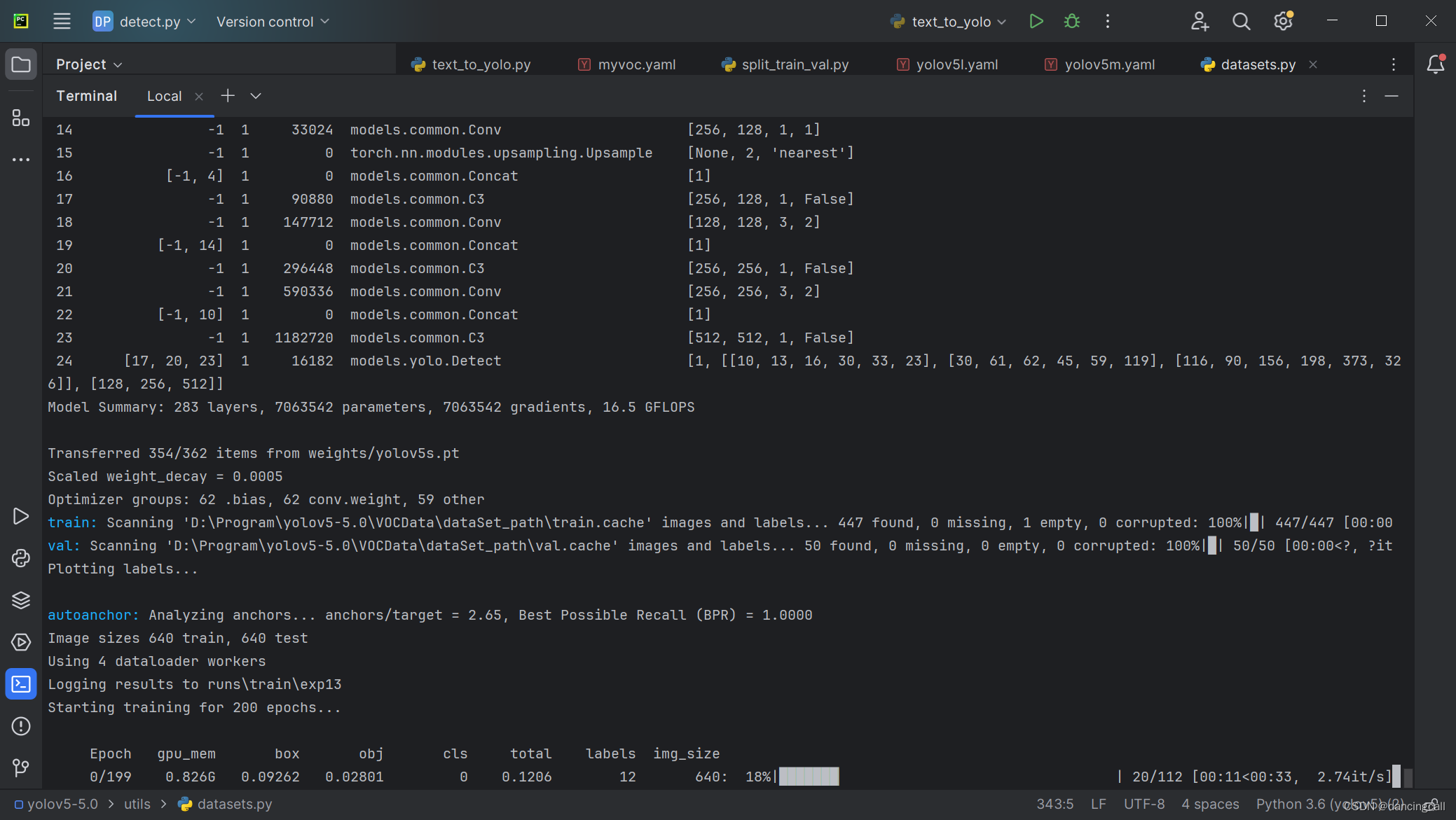
接下来我用服务器开始训练。
初步结果(未改进)
test结果


使用tensorboard --logdir=runs命令查看训练结果
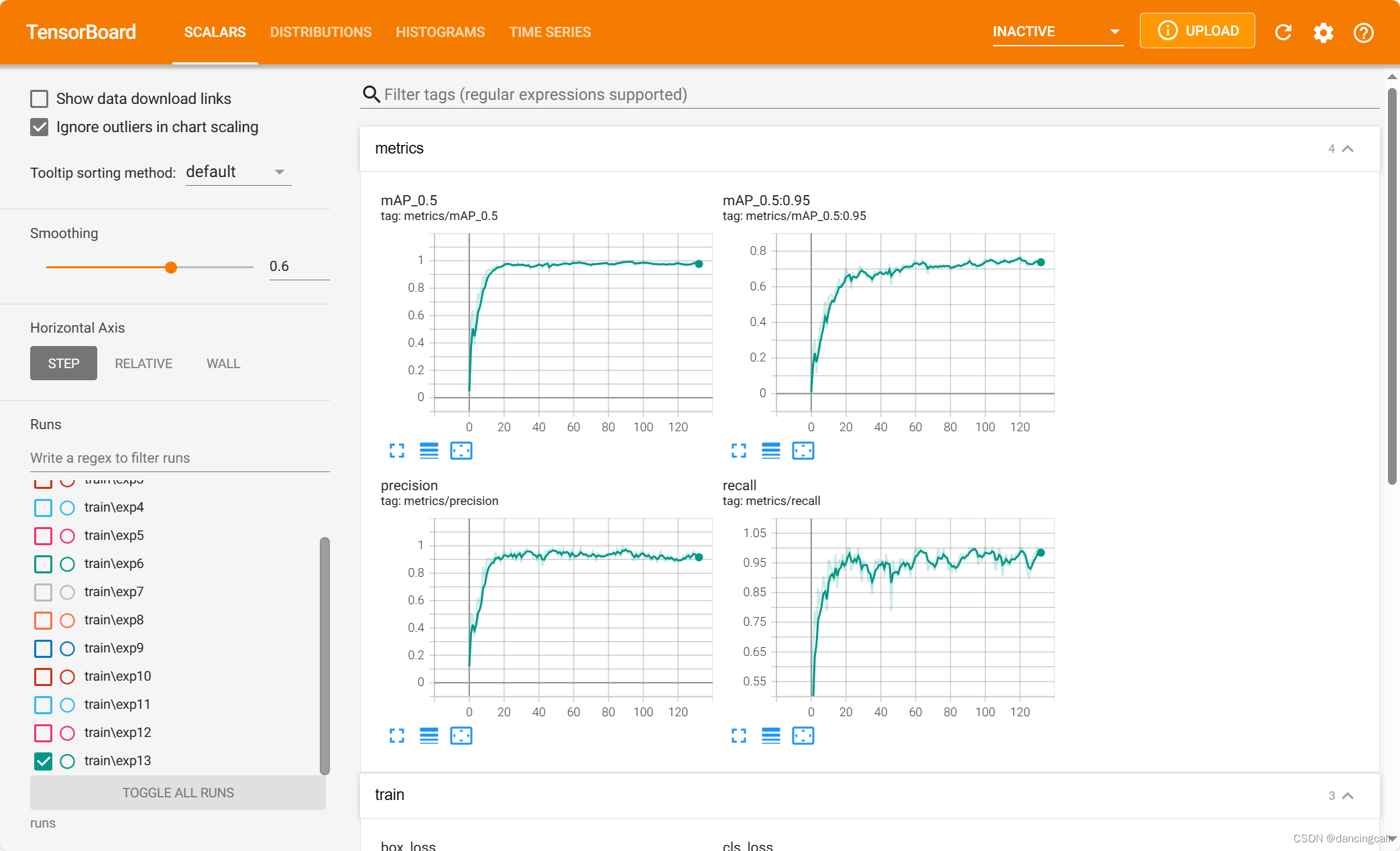
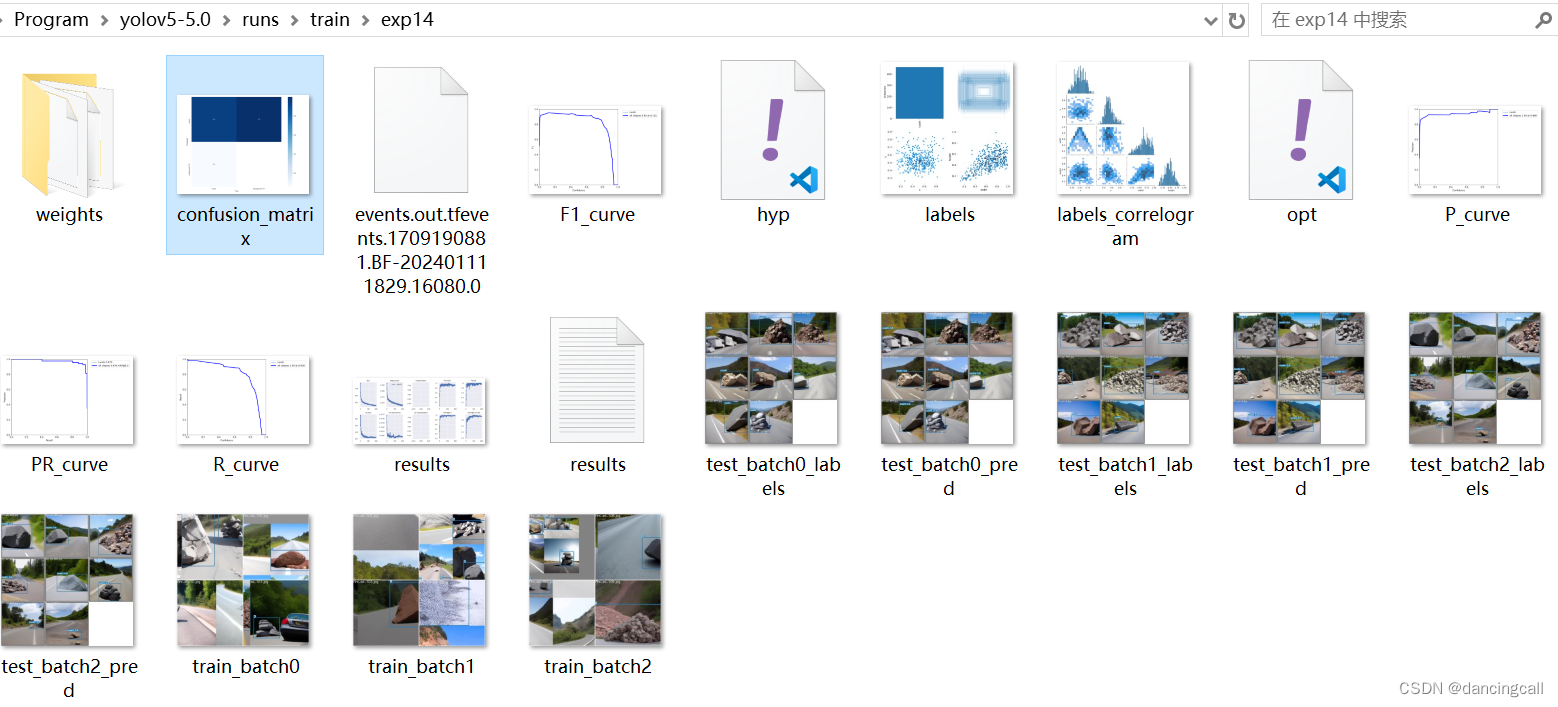
三、训练完后生成的结果显示
如图生成了以下文件夹和文件
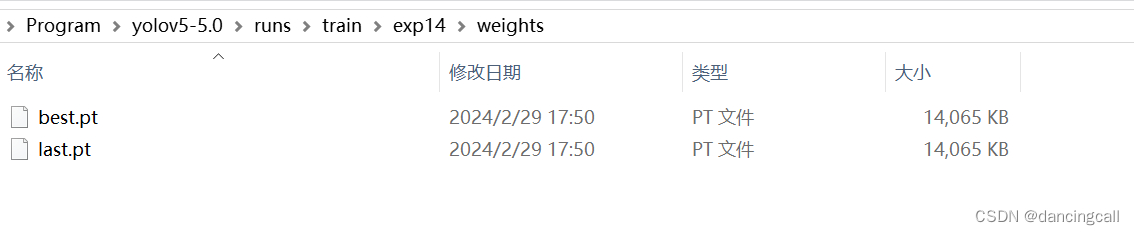
weights
包括训练出来的最好和最后权重
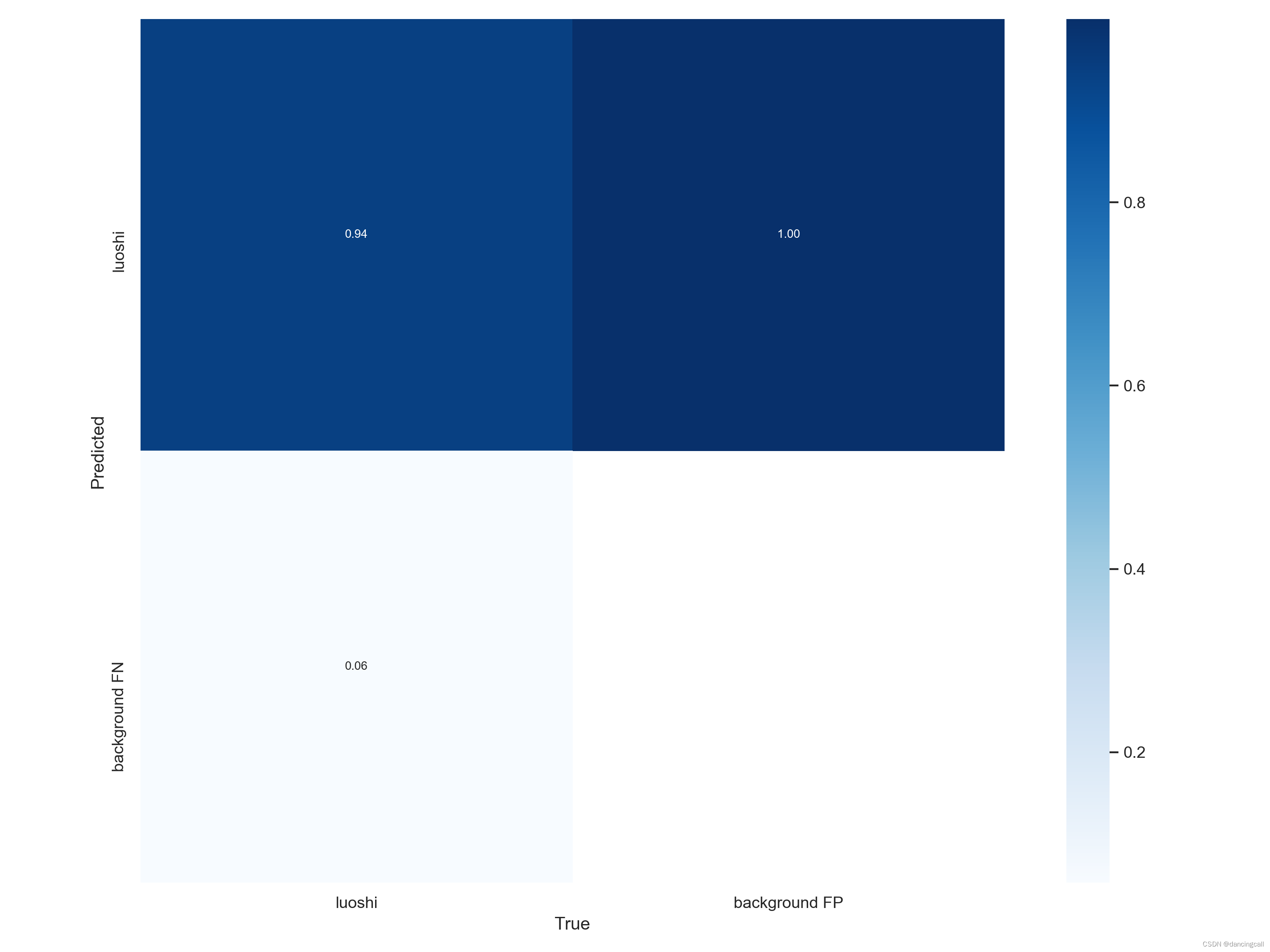
confusion_matrix
该混淆矩阵指明,类别精度
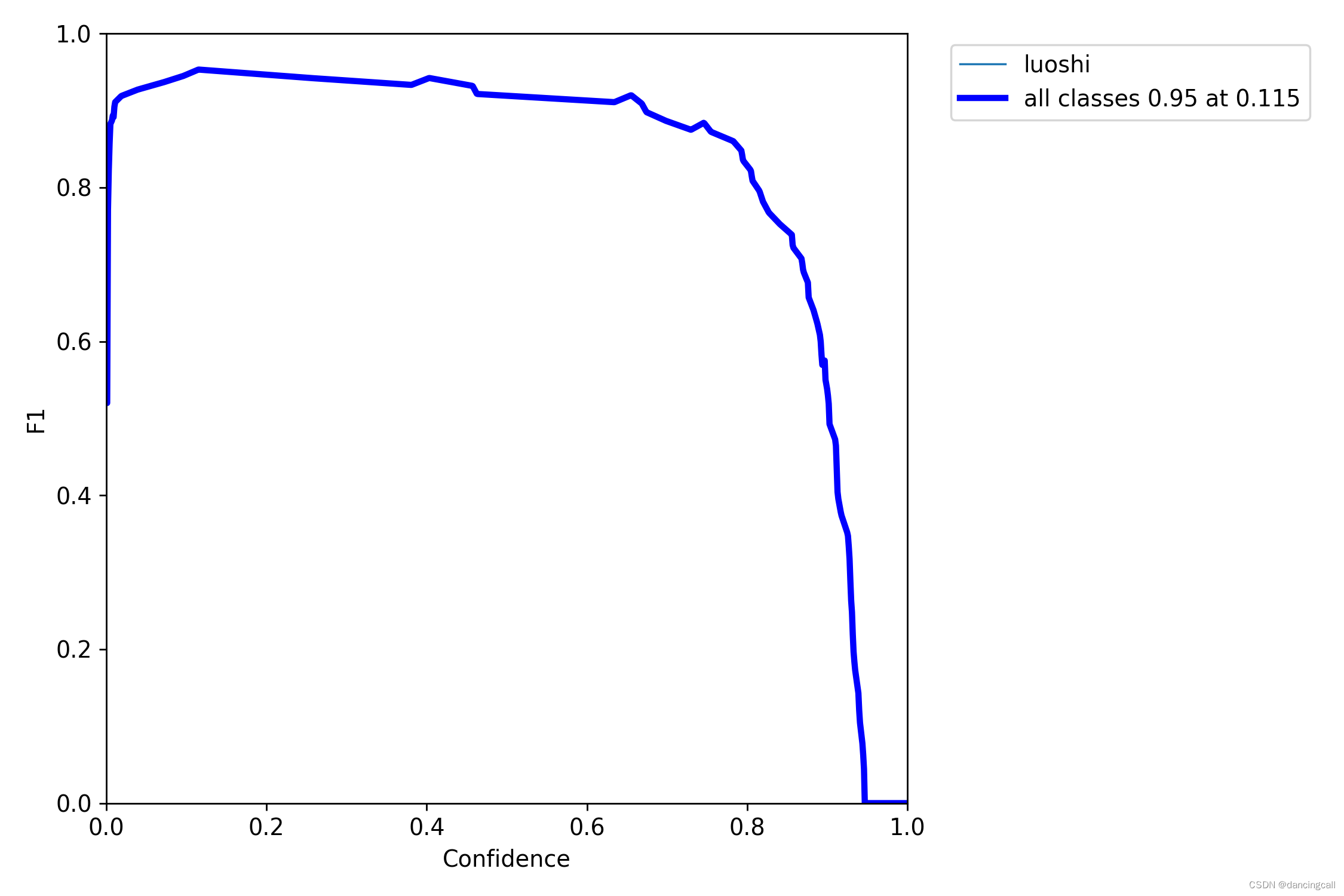
F1
衡量精度的指标
hyp.yaml
表示超参数

五、 train.py参数详解
conf-thres //置信度的阈值
iou-thres // iou的阈值
六、真实图片预测
结果如图:

real_1.jpg 未识别出来

real_2.jpg将远处的车辆也识别为落石

real_3.jpg识别出来落石但置信度只有0.40
重新调整数据,增加一些真实的落石照片,dedao更好的效果:

七、代码,网络架构的学习
1、model文件夹
先从配置文件讲起,这三个配置文件的区别在于以下两个参数的不同来控制卷积层的层数以及每一层特征图的个数,从而来控制模型的大小。

anchors

1. backbone
yolo.py
进行模型初始化,先把网络层按顺序堆叠好。
读入配置文件,
na:anchors个数、no:输出结果的个数。gd:0.33
c1:输入
c2:输出
common.py
具体模块功能实现
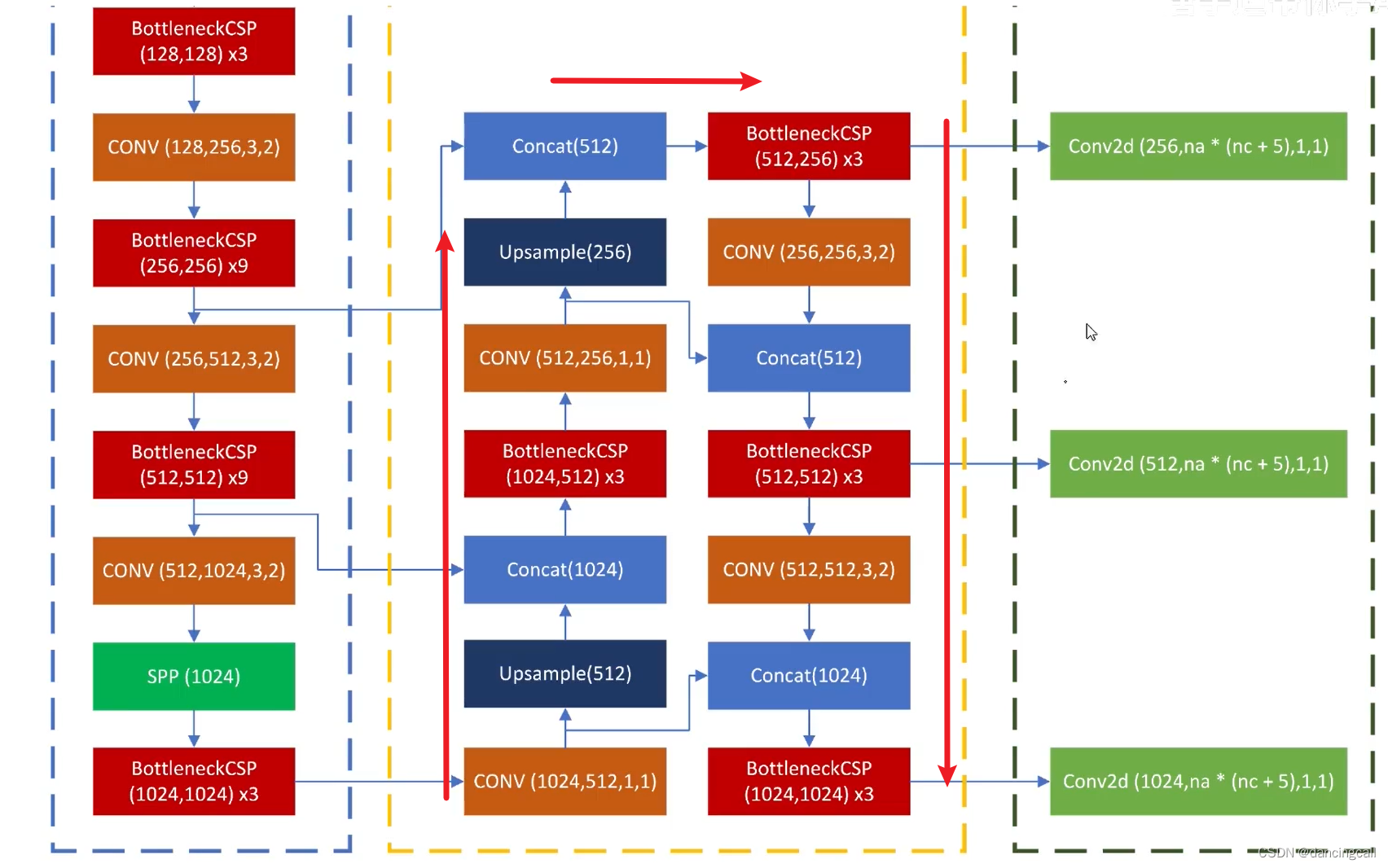
2.head
八、服务器
1.Pycharm的重新搭建
为了建立ssh连接必须使用pycharm专业版。
搭建成功,在本地测试成功。
九、跟嵌入式的连接
将训练好的best.py->best.onnx
问题一
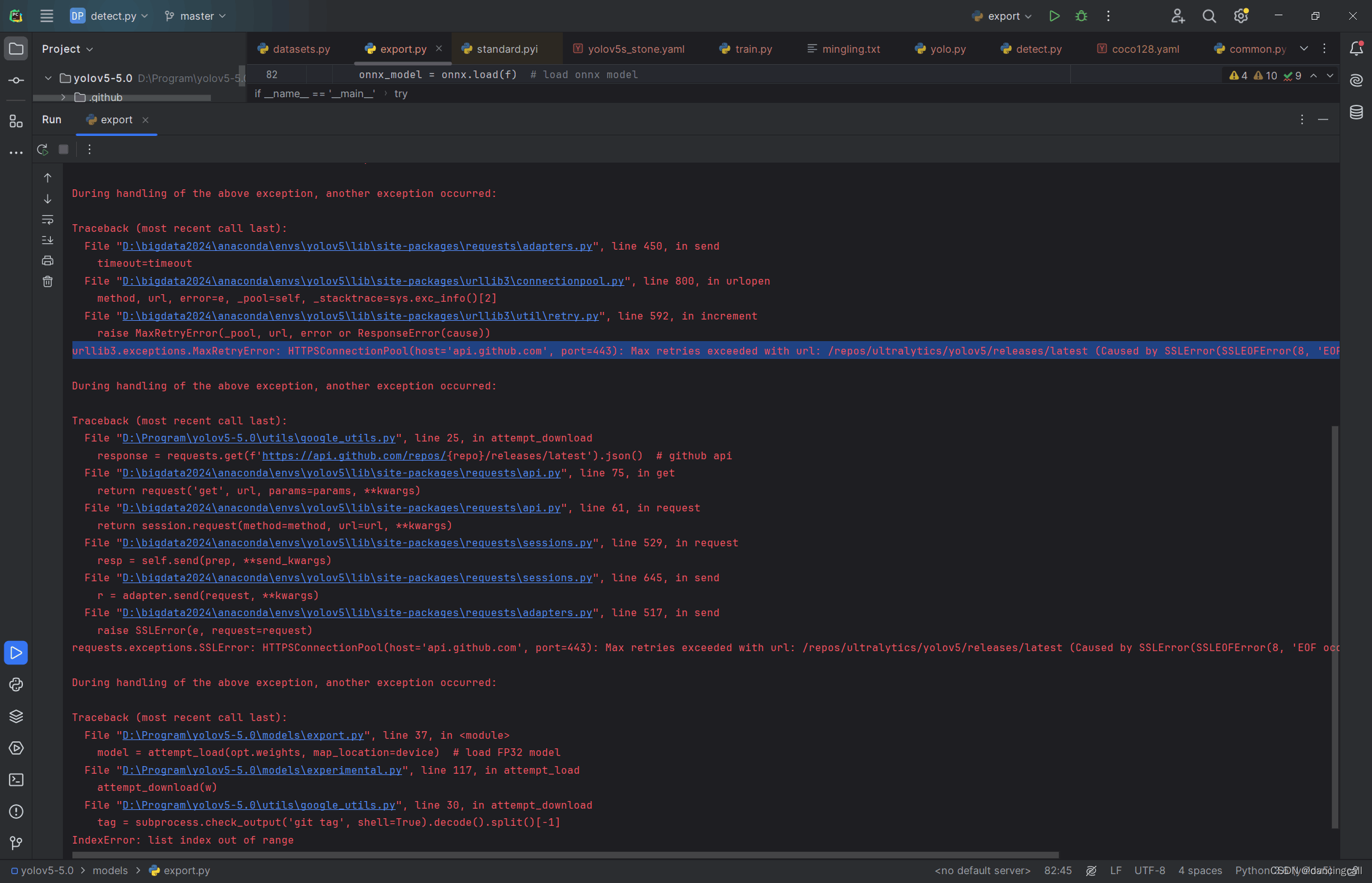
urllib3.exceptions.MaxRetryError: HTTPSConnectionPool(host=‘api.github.com’, port=443): Max retries exceeded with url: /repos/ultralytics/yolov5/releases/latest (Caused by SSLError(SSLEOFError(8, ‘EOF occurred in violation of protocol (_ssl.c:852)’),)) During handling of the above exception, another exception occurred:
表示在与HTTPS连接池进行通信时违反了协议。这可能是由于网络问题、证书问题或其他SSL相关问题导致的。
解决办法:关闭相关网络代理
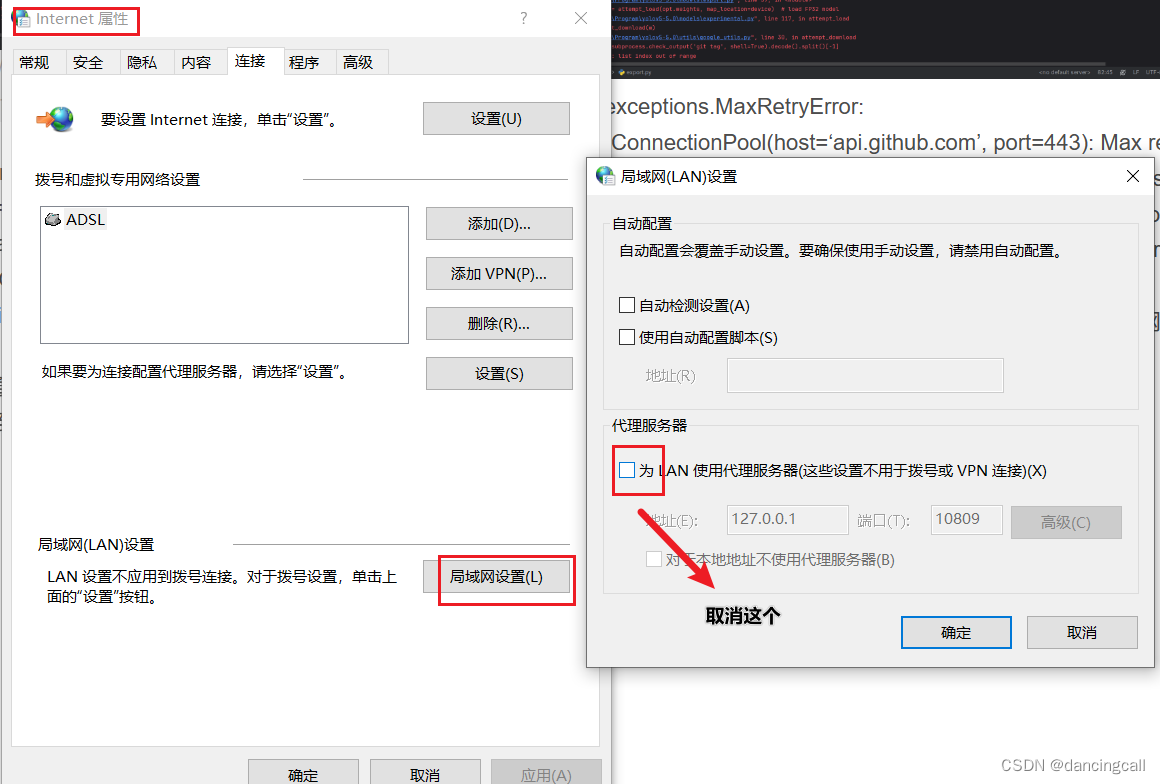
问题二
未安装onnx库:之前直接在终端安装 pip install onnx
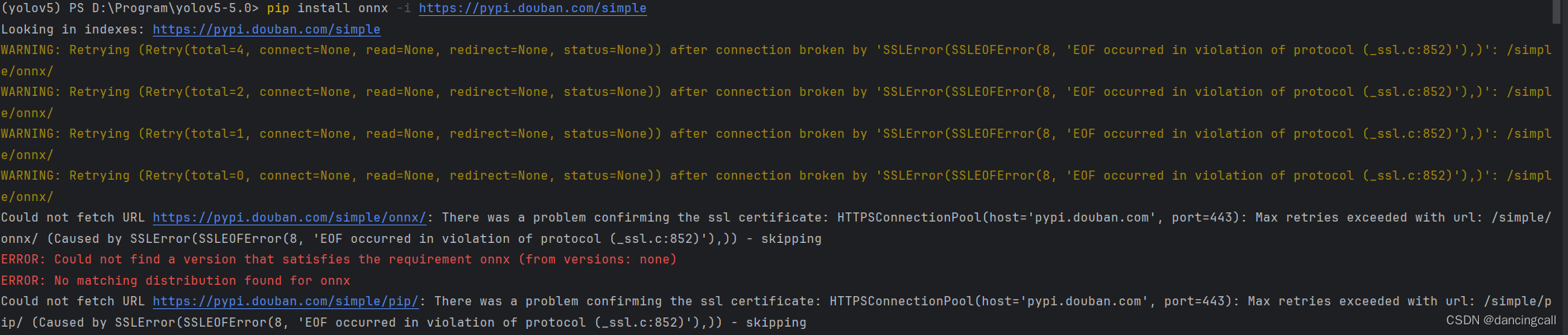
ERROR: Could not find a version that satisfies the requirement onnx (from versions: none)
ERROR: No matching distribution found for onnx
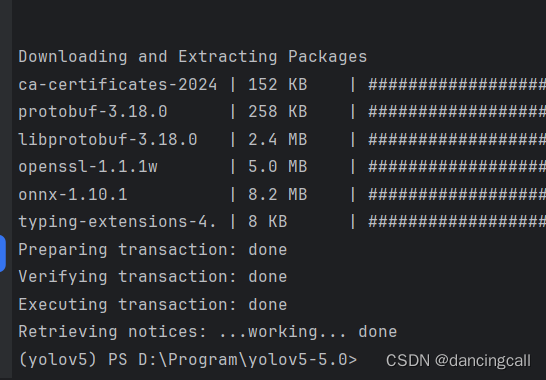
解决办法:用conda下载
conda install -c conda-forge onnx
问题三、
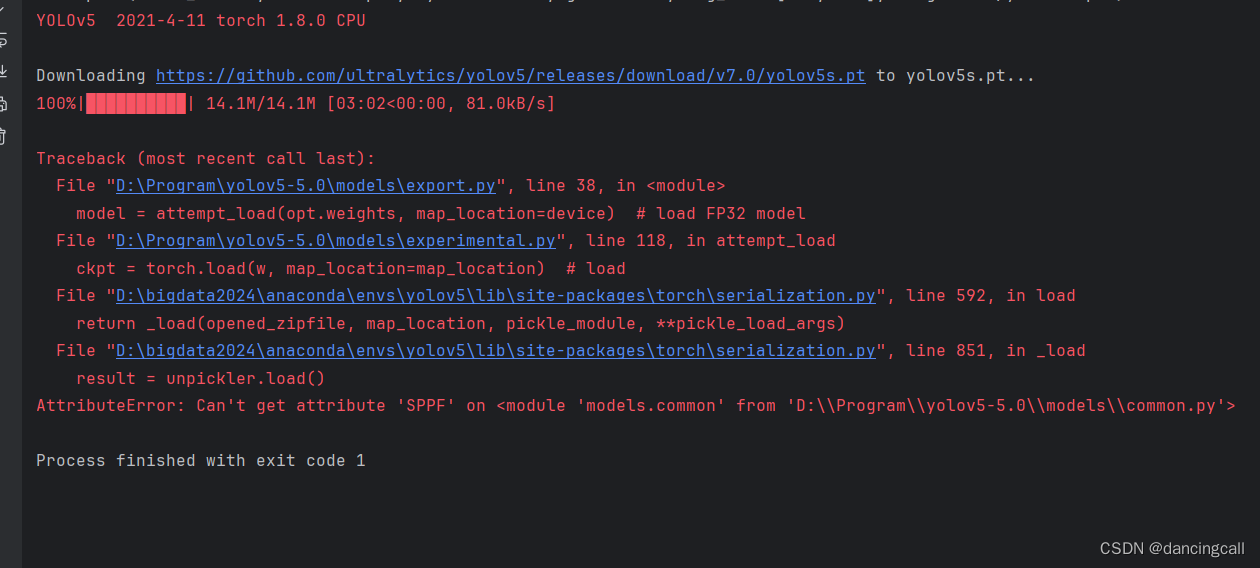
解决办法:
在common.py中加入SPPF模块
import warnings
class SPPF(nn.Module):
# Spatial Pyramid Pooling - Fast (SPPF) layer for YOLOv5 by Glenn Jocher
def __init__(self, c1, c2, k=5): # equivalent to SPP(k=(5, 9, 13))
super().__init__()
c_ = c1 // 2 # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c_ * 4, c2, 1, 1)
self.m = nn.MaxPool2d(kernel_size=k, stride=1, padding=k // 2)
def forward(self, x):
x = self.cv1(x)
with warnings.catch_warnings():
warnings.simplefilter('ignore') # suppress torch 1.9.0 max_pool2d() warning
y1 = self.m(x)
y2 = self.m(y1)
return self.cv2(torch.cat([x, y1, y2, self.m(y2)], 1))

















 351
351

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









