







题目:Improving Language Understanding by Generative Pre-Training
作者:Alec Radford、Karthik Narasimhan、Tim Salimans、Ilya Sutskever
年份:2018年
论文原文
这篇论文由OpenAI团队于2018年发布,提出了在大规模无监督语料库上进行预训练,然后在特定任务上进行微调的两阶段训练框架。这种方式在自然语言处理领域产生了深远影响,是NLP领域预训练模型的开端之一。 虽然后面bert的效果更好,这篇论文的出现比BERT更早,所以创新性比bert更强。
摘要
自然语言理解里很非常多的任务,比如文本蕴涵、问答、语义相似性评估和文档分类。虽然未标注的文本数据非常的丰富,但是标注好的文本数据却非常的有限。因此想使用标注数据去训练分辨模型的话,数据量是不够的(提出问题)。本文给出的解决方法是,先在没有标记的数据上训练预训练的语言模型,然后再针对不同的子任务,在有标签的数据上训练出微调模型(解决方法)。与以前的方法相比,本文在微调过程中构造和任务相关的输入,从而只需要对模型架构做微小的改变(和之前方法的比较)。最终本文的方法在12个任务里面,有9个达到了最好的效果。
引言
即使在有大量监督的情况下,以无监督的方式学习良好的表示也可以显著提高性能。比如说课上学过的word2vector,词嵌入模型就是使用无监督的方法训练词向量的。
作者还提到了使用无标签的文本的两个困难:
1、目标函数的选择,不知道该用什么样的目标函数,不同任务的适用的损失函数不同。
2、如何把从无标签文本学到的文本的表示传递到下游的子任务中去?目前没有一种简单的统一的有效的方式。
本文使用了一种先使用无监督的预训练,再进行监督学习微调的方法,目标是学习一种通用表示。采用两阶段训练程序。首先在未标记的数据上使用语言建模目标来学习模型的初始参数。然后使用相应的监督目标将这些参数调整为目标任务。
介绍两个技术要点:
1、本文的模型是基于transformer架构的,transformer在机器翻译、文档生成和句法分析等各种任务上表现出色。作者认为transformer提供了更结构化的记忆,用于处理文本中的长期依赖关系效果更好,处理长文本信息的效果更好。和rnn相比,transformer能学习到的特征更加稳定,能更好地适应不同的下游任务。
2、在做迁移的时候,使用特定任务相关的结构化输入,将结构化文本输入作为单个连续的标记序列进行处理。
介绍实验结果:
在四种类型的语言理解任务上评估了本文的方法——自然语言推理、问答、语义相似性和文本分类。在12个自然语言任务中,有9个任务的技术水平得到了显著提高。例如,在常识推理上提高了8.9%,在问答方面提高了5.7%,还分析了预先训练的模型在四种不同环境下的零样本行为,并证明它为下游任务获得了有用的语言知识。
通过引言已经可以看出本文要解决的是什么问题,以及大致的方法,后续本文对技术细节进行展开。
相关工作(背景知识)
NLP的半监督学习:
半监督学习在自然语言处理中以及有了一些的应用,比如在序列标记和文本分类任务中,使用未标注的数据获得单词级或者短语级的信息,然后将其用在监督模型中。而词嵌入能提高各种任务的效果,这也是公认的。这更说明了使用无监督预训练模型是有效的。之前的方法更关注单词级的信息,本文的目标是从无标签的数据中捕捉更高级的语言信息(比如句子级)。
无监督的预训练模型:
这种方法之前一直应用在图像领域。
与本文工作比较接近的一项工作是Dai等人的,采用预训练微调的方法来改进文本分类任务,他们使用的LSTM模型效果不如本文使用的Transformer模型。而且本文的模型适合多种不同的下游任务。还有别的方法在后续调整阶段涉及大量的新的参数,或者模型的改动,而本文的模型只需要微调即可。
辅助训练目标:
添加辅助训练目标是半监督学习的一种形式,本文也使用了一个辅助目标。
一点理解:这三部分背景知识其实也对应了本文的思路,先使用无标签的数据进行预训练,使用有标签数据进行模型微调、微调的时候添加辅助目标函数。
框架(主要部分)
模型分为两阶段
1、在大型文本语料库上学习高容量语言模型。
2、随后是微调阶段,在该阶将模型调整为具有标记数据的判别任务。
无监督预训练
给定一个未标注文本语料 库![]() ,其中u1,. . .,un 是一系列的词。
,其中u1,. . .,un 是一系列的词。
模型通过以下公式最大化语言模型的似然:
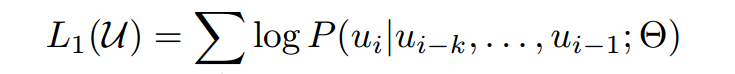
就是通过ui前面的k个词来预测ui 的概率(其实就是n-gram的思想),k就是上文的长度。一般来说k越大看到的信息越多,效果越好。参数是使用随机梯度下降训练的。
具体的模型:
无监督预训练采用了多层Transformer解码器
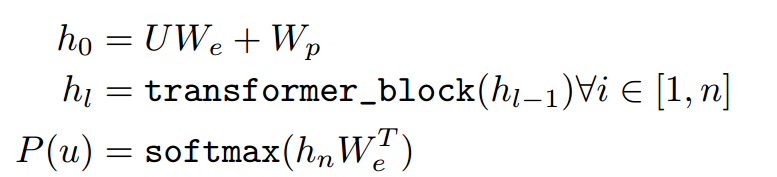
第一个公式对应的是嵌入层(Embedding Layer),U就是前面讲的未标注的文本预料
We是词嵌入矩阵,Wp表示位置编码,h0也是第一层的输入。
第二个公式讲的是transformer块的堆叠。将h0输入到transformer块之后,得到输出h1, 将h1输入给transformer块之后,得到输入h2。
最后通过 softmax 函数对词表中的所有词计算概率分布
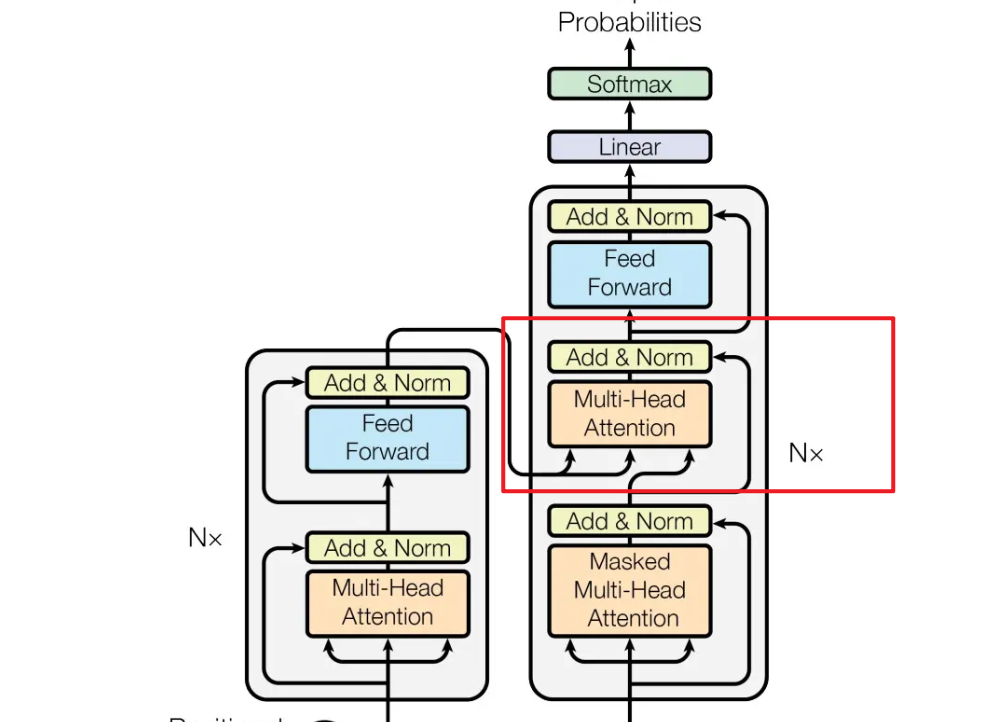
思考:为什么只用transformer解码器。
还是设计的原因,前面讲到模型要通过前面的k个词,预测下一个词。
而transformer编码器的注意力机制可以看到前后所有的词的信息。transformer编码器 使用掩码自注意力机制,每个位置只能看到其前面的词。所有就用了transformer编码器。
而且本文使用的decoder和原始的transformer的decoder结构还有些不同,比如下图中红框中的部分,是需要来自编码器的输入的,而且GPT中并没有编码器,所以解码器中的这部分也不需要了。
有监督的微调
这部分是对前面无监督训练的模型进行微调,此时有一个标注的数据集 C
这时候使用有标签y 的数据对模型进行训练。 微调的目标是最大化标签的条件概率
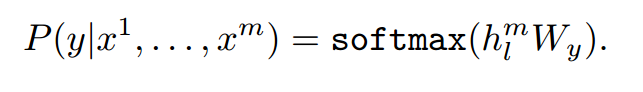
x1,…xn表示输入的序列
hml就表示输入序列经过预训练模型最后一层的输出。
Wy 是微调调阶段新添加的线性分类头的参数,就是说将输出在送到一个分类头中做分类,为了和标签y做损失。
统计所有的序列对,就得到了微调模型的优化目标
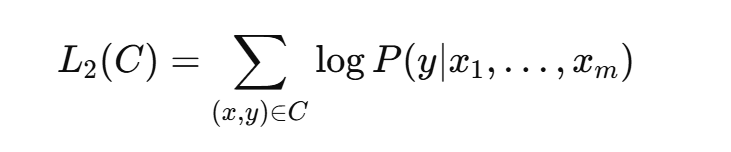
作者还提到,将语言建模作为微调的辅助目标有助于学习:
(a)提高监督模型的泛化能力
(b)加速收敛。这与之前的一些工作的结论一致,通过这种辅助目标,性能得到了改善。
具体来说,本文优化了以下目标函数(具有权重λ):
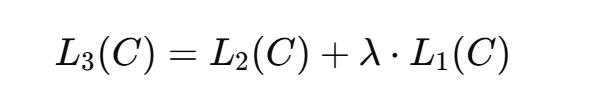
总体而言,在微调过程中,需要的唯一额外参数是Wy(线性分类头的参数)和分隔符标记的嵌入(不同任务需要在句子中加入标记符)
对特定任务的输入转换
论文中的这张图很清楚的展示了对一些不同任务的输入序列的构造,老师上课的PPT上也用到了这个图。
1、首先是分类任务:
只需要和前面讲的一样,在原始序列的头部加上start标记,在尾部加上extract标记,在模型的后面加上一个线性分类层就能对句子做分类了。比如说情感分类,给一个句子,对这个句子表达的情感做分类。
2、文本蕴含任务:
Premise是一个前提句子,Hypothesis是一个假设句子,文本蕴含任务大致判断Premise句子支不支持后面的假设句子。构造的时候在两个句子中间加上一个分隔符,同样在首部加上Start,在尾部加上Extract。然后输入给模型,在后面加上一个线性层。
3、相似性任务
判断两个文本的相似度。要构建两条输入,因为文本1和文本2相似,文本2和文本1必然也相似。这是没有顺序关系的。但是将text1和text2连接在一起就必然有了句子的先后顺序关系。所以构造如图所示的两个序列。分别输入到模型中去,最后将预训练模型的输出融合在一起,可以是加,也可以是concat拼接在一起等。再送到线性层做判断。
4、选择问题
把每个答案分别和句子拼接成一个序列,n个答案就有n个序列,输入到预训练模型中分别通过线性层得到一个分数。把每个分数经过softmax层和正确的答案做比较。
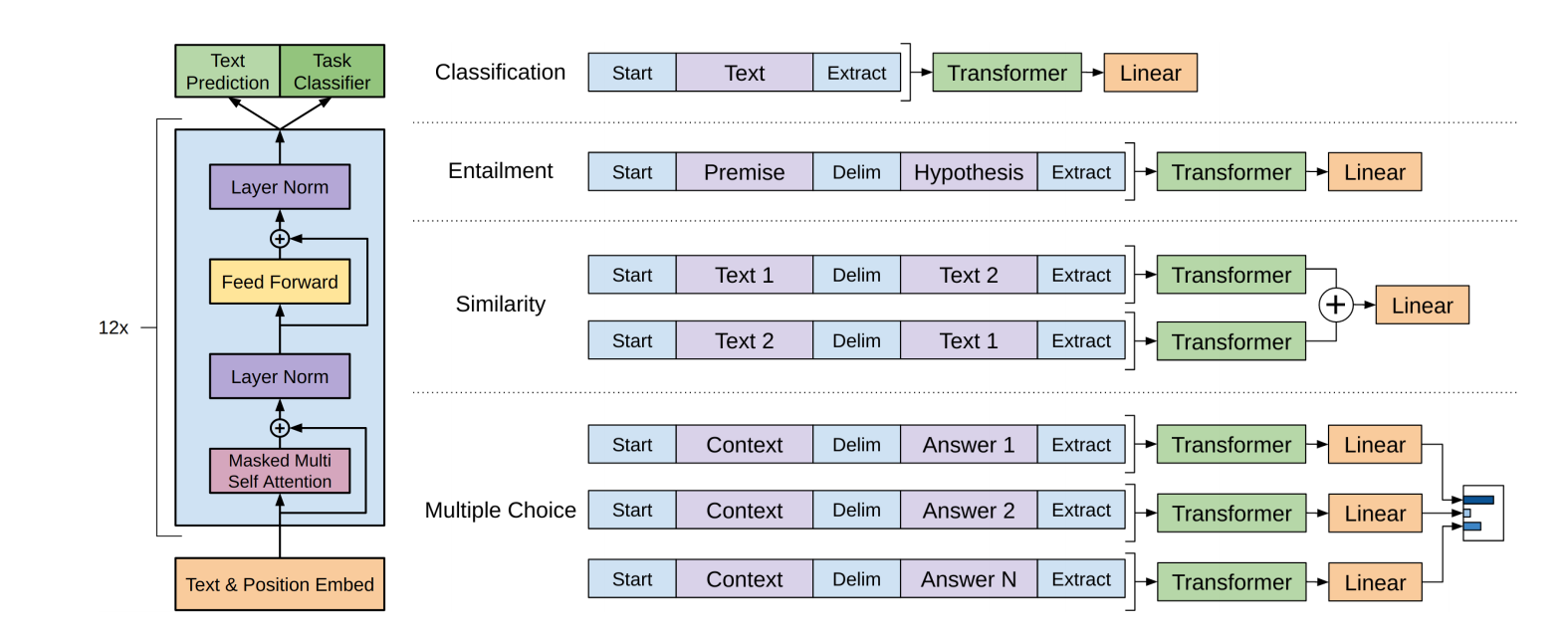
ps:需要注意的是这里面的Start、Extract、Delim都应该是文本中没有的特殊符号,避免和文本混淆。
实验部分
1、实验设置
无监督预训练:
使用BooksCorpus数据集来训练语言模型,它包含7000多本独特的未出版书籍,来自各种流派,包括冒险、幻想和浪漫。至关重要的是,它包含长段连续的文本,这使得生成模型能够学习对长距离信息的处理。
模型的设置:
使用了12 层的Transformer解码器,768 维隐状态,12 个自注意力头。
使用Adam优化器,初始学习率 2.5×10−4,使用线性预热和余弦衰减 。
序列长度为512个token,batch_size设置为64,训练100个epoch。
使用N(0; 0.02)的初始化权重,词嵌入是基于BPE的词汇表,包含 40,000 个子词
PS:BPE 是一种基于频率的分词方法,旨在将文本中的字符逐步合并成子词单元,以优化表示单词的能力。先将单词视为字符的序列,然后不断寻找文本中最频繁的字符或字符组合,将它们合并成一个新的子词,直到达到预定的子词数量或词汇表大小。
微调时的超参数和预训练基本一致,另外作者还提到,微调阶段训练3个epoch大概就够了。
监督微调
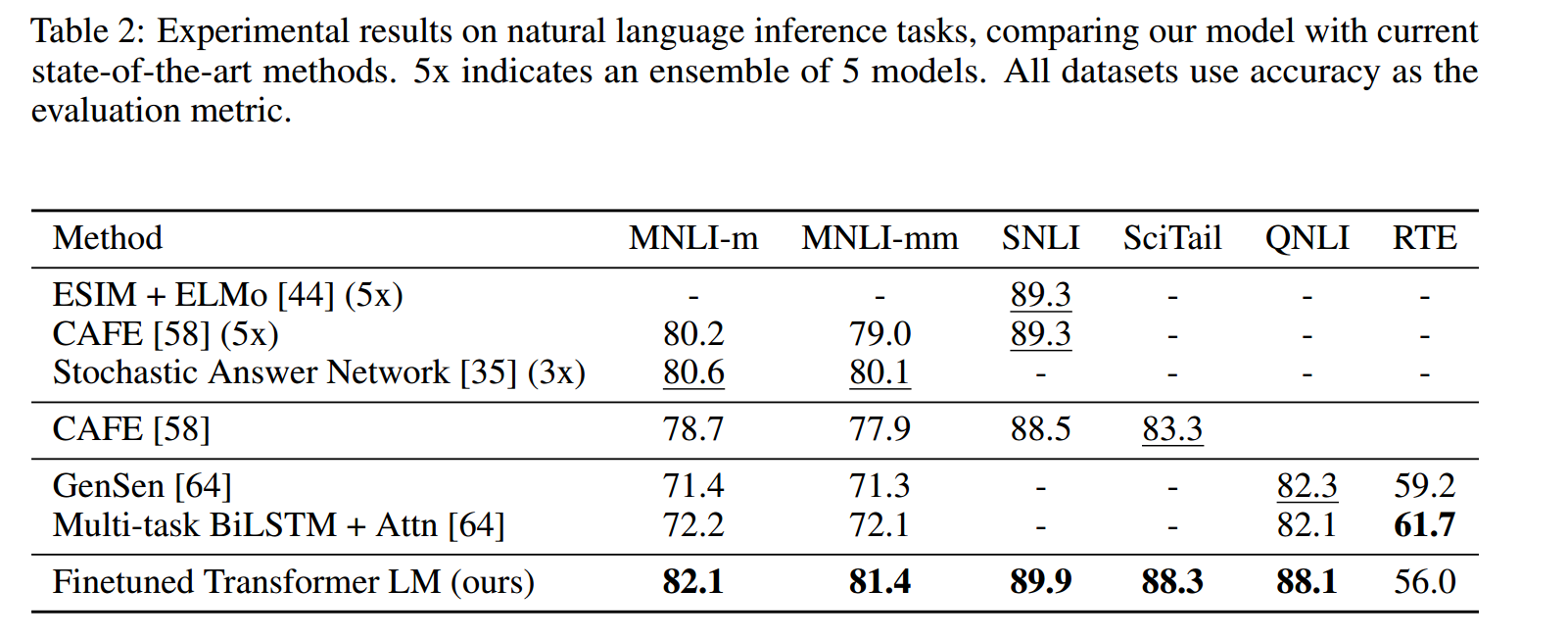
1、文本蕴含任务:
本文实验评估了五个不同来源的数据集,包括图像标题(SNLI)、转录语音、流行小说和政府报告(MNLI)、维基百科文章(QNLI)、科学考试(SciTail)或新闻文章(RTE)。
在前四个数据集中本文的方法都达到了最好的效果,在最后一个数据集上效果没有那么好。RTE是最小的一个数据集,推测可能是数据集规模的原因。
2、问答与常识推理
使用RACE数据集,数据集由英语段落和初中和高中考试的相关问题组成。该语料库已被证明包含比其他数据集更多的推理型问题,该模型经过训练可以处理远程上下文(值得是相距较远的句子语义)。
还对故事完形填空测试进行了评估,该测试涉及从两个选项中选择故事的正确结局。
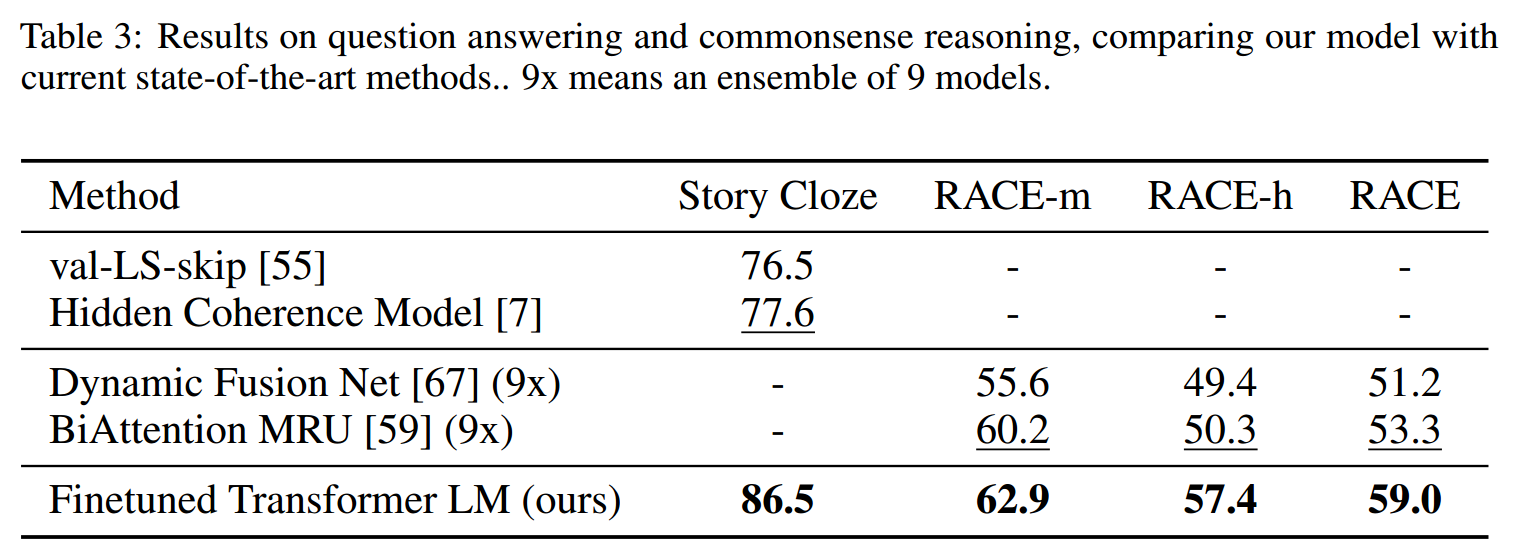
本文模型同样在这两个数据集上都达到了最好的效果,这证明了本文的模型能够有效地处理远程上下文。
3、语义相似性任务
语义相似性:预测两个句子在语义上是否等价。
主要困难有:识别概念的改写、理解否定和处理句法歧义。
本文使用三个数据集来完成这项任务:微软短语语料库(MRPC ,从新闻来源收集)、Quora问题对(QQP)数据集和语义文本相似性基准数据集(STS-B)。
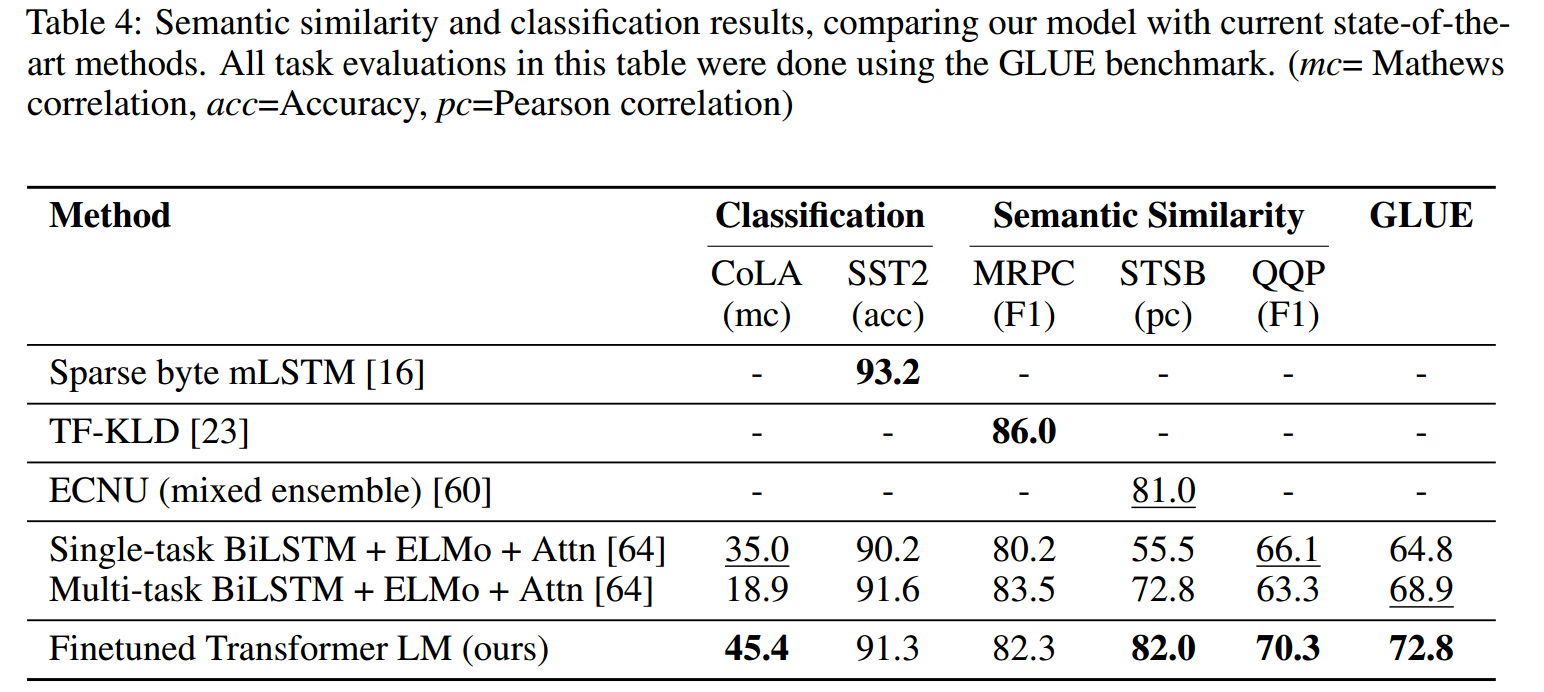
从表中可以看出,本文在三个语义相似性任务中中的两个上达到了当时的最好效果。
4、分类任务
数据集:语言可接受性语料库(CoLA)包含对句子是否符合语法的专家判断,并测试训练模型的固有语言偏见。
斯坦福情感树库(SST-2)是一个标准的二元分类任务。
本文模型在CoLA上达到了当时最好的效果,在SST2虽然没有达到最优,但是也有91.3的准确率。
总结
****通过无监督预训练,模型能学习到通用语言表示,并在多种任务上实现高效迁移。
总体而言,本文在方法12个数据集中中的9个数据集中取得了最新的最先进的结果,在另外3个数据中虽然没有达到最优,但是效果也都和当时最先进的方法效果接近。
而且实验结果还表明了,本文的微调方法在小数据集和大数据集上都有不错的效果,适用范围广。
分析
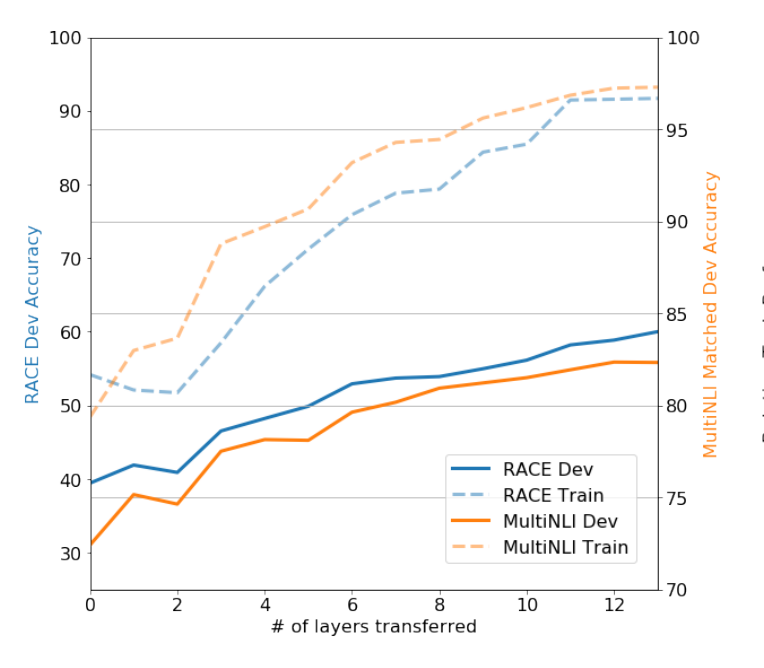
1、转移层数的影响
本文还测试了将不同数量的 Transformer 层从无监督预训练转移到监督微调任务中的效果,使用 MultiNLI(自然语言推理)和 RACE(阅读理解)数据集进行评估。
理解:这部分实验的意思是探寻预训练模型哪部分对下游任务的贡献最大。比如说构建一个12层的模型,拿出其中两层进行微调看看效果怎么样,拿出其中四层进行微调看看效果怎么样。然后本文工作发现 每一层的 Transformer 表示都包含与目标任务相关的信息 ,多层叠加效果更好。
2、 零样本行为
在没有进行监督微调的情况下,直接使用预训练模型完成某些任务,观察其零样本推断能力。
使用数据集: CoLA(语言接受性判断,分类任务)、SST-2(情感分析)、RACE(阅读理解)、Winograd Schema Challenge(代词消解)
作者设计了一些启发式的方法,让模型能够直接完成任务,而无需监督微调.
对于CoLA分类任务, 计算每个句子的平均对数概率(由语言模型给出),通过设定阈值判断句子的语法接受性。 对于SST-2(情感分析分类任务), 在句子后面添加“very”,限制模型的输出为 “positive” 或 “negative”,预测概率更高的作为结果。 对于RACE(问答任务), 对每个可能的答案,模型生成完整的上下文(包括问题和答案),选择概率最大的答案 。
3、消融研究
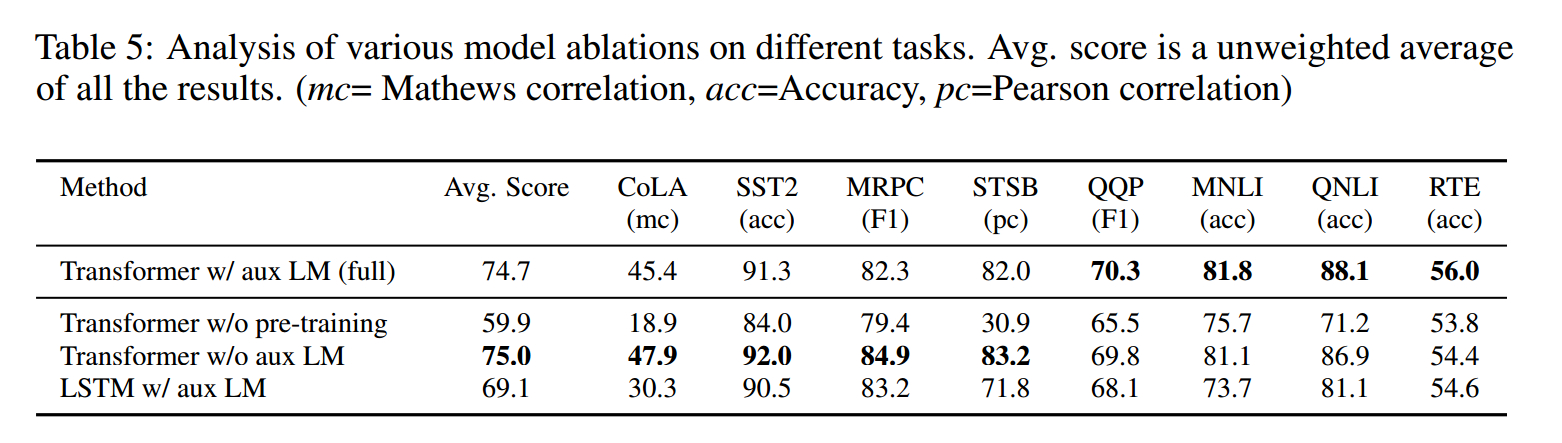
本文进行了三种消融实验
1、在微调阶段不使用辅助目标函数(就是前面预训练阶段的目标函数),
结果表明在大数据集任务(如 MultiNLI 和 QQP)上性能下降,但在小数据集任务上变化不大。
个人理解:辅助目标函数可能帮助了大数据集任务的泛化和收敛,而小数据集因标注数据有限,其主要依赖监督目标损失。
2、 将 Transformer 替换为 LSTM
结果表明模型平均性能下降了 5.6%,尤其是在需要捕捉长距离依赖的任务(如 RACE 和 MultiNLI)上表现显著变差。
这也对应了论文开头 选择Transformer作为模型主要结构的时候所说的, Transformer 比RNN模型更擅长捕捉长距离依赖关系。
3、不使用预训练
不使用预训练模型的性能下降明显,说明了无监督预训练的有效性。
总结和思考
本文的核心思想就是使用大规模无监督语料进行生成式语言建模预训练,捕捉通用的语法和语义知识。然后通过少量标注数据进行任务微调,适配具体任务。并没有对模型结构做什么创新,而是提出了这样一种预训练微调模型的训练方法,是预训练微调方法的开山之作。 开启了自然语言处理的第三范式,标志着 NLP 从传统的特征工程与监督学习范式,转向预训练+微调的时代。
理解论文时产生的一些思考在前面对应的部分都有写了,包括为什么只使用Transformer解码器不使用编码器等问题论文的核心思想还是很简明的,很好奇后续的GPT2、GPT3又做了哪些改进。



















 699
699

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











