







目录
NetLLM: Adapting Large Language Models for Networking.
Glossary
Rule Engineering: 在网络系统中创建和实现基于规则的算法的过程,这些规则是预先设定的,在基于规则的系统中,每一个操作和决策都根据静态的、预先定义好的规则来执行。
Model Engineering: 设计、实施和训练机器学习模型,不依赖于硬编码的规则,而是通过数据驱动的方式学习如何从输入数据到输出决策的映射。主要挑战是设计出能够在复杂网络环境中有效工作的模型架构,并且这些模型需要在不同的网络任务中重新训练和调整。
Adaptive Bitrate Streaming (ABR) Model: 用于视频传输中的一种技术,根据用户的网络条件动态调整视频的比特率。此类模型需要能够快速响应网络环境的变化,并做出准确的比特率调整决策,以保证视频流的平滑播放和高质量。
Resource-intensive: 某些任务或过程在执行时需要消耗大量计算资源。
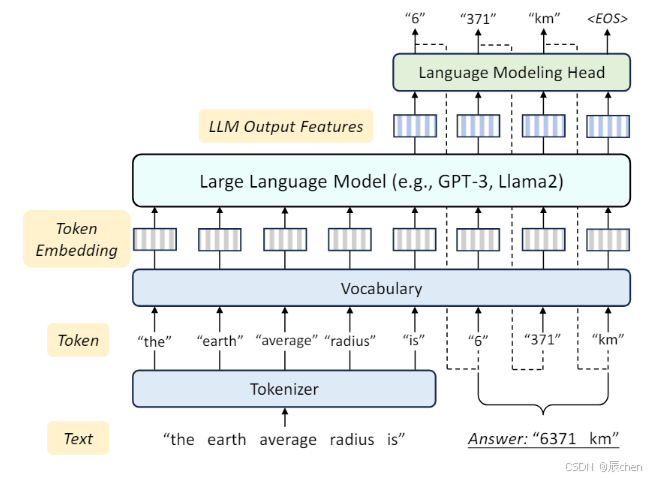
Token: 指的是文本中的一个词或标点符号,它是文本分词(Tokenization)的结果,是自然语言处理中用于文本分析和处理的基本单元。
Efficient fine-tuning technology: 使用优化的策略来调整预训练模型(如大型语言模型)的参数,在保持预训练模型泛化能力的同时,减少所需的资源(如计算时间和内存)和提高模型调整的效率。
hallucination: 模型生成的输出中包含的错误或与现实不符的信息。
(Experience) Trajector: 指在与环境交互过程中收集的一系列事件,轨迹反映了从开始到结束的一系列决策和结果,通常用于训练或微调强化学习模型。
CDF: CDF 表示随机变量 X小于或等于某个特定值 x 的概率
Notes
INTRODUCTION
The Main Roadmap so far
基于学习的算法存在两个关键限制:
- 高模型工程成本
- 低泛化能力
New Opportunities and Challenges
适应网络的LLM所面临的挑战:
- 大的输入模态差异:LLM的输入为纯文本,但网络任务中输入的信息格式多样。
- 回答生成的低效率:为网络任务生成的答案可能看似正确但实际上无效、LLM可能无法快速生成答案以响应网络系统的变化
- 高适应成本:LLM的参数量很大,微调的成本代价太高
Design and Contributions
NetLLM包括以下三个核心设计:
- Multimodal encoder:处理非文本信息
- Networking head:输出非文本内容
- Data-driven low-rank networking adaptation (DDLRNA):数据驱动的方式训练LLM,降低微调成本
NetLLM特性:
- 兼容性
- 可靠性
- 效率
BACKGROUND
Learning-Based Networking Algorithms
基于学习的算法设计和训练DNNs,通常采用SL和RL来促进学习过程,有效地学习解决网络任务,其限制为:
- 高开销:需要为不同的网络任务手动设计专门的DNN模型
- 泛化弱:DNN在未见数据分布/环境中可能表现不佳
Large Language Models
MOTIVATION
| 任务 | DNN输入 | DNN输出 | 目标 | 学习范式 |
|---|---|---|---|---|
| 视口预测 (VP) | 时间序列:历史视点;图像:视频内容信息 | 未来视点 | 最小化预测视点与实际视点之间的误差 | 监督学习 (SL) |
| 自适应比特率流 (ABR) | 时间序列:历史吞吐量,延迟;序列:不同比特率的块大小;标量:当前缓冲长度 | 为下一个视频块选择的比特率 | 最大化用户的质量体验 (QoE) | 强化学习 (RL) |
| 集群作业调度 (CJS) | 图:描述作业执行阶段的依赖性和资源需求的有向无环图 (DAGs) | 下一个要运行的作业阶段,分配给该阶段的执行器数量 | 最小化作业完成时间 | 强化学习 (RL) |
LLM适用于网络的三个主要挑战:
- 大的模态差异:输入多样化与LLM单一文本输入不匹配,尽管设计提示模板进行辅助但结果仍欠佳。
- 基于token的答案生成效率低:幻觉问题且不满足网络任务需要的高可靠性和快速响应。
- 高适配成本:基于RL的大参数LLM实现成本过高。
NETLLM DESIGN
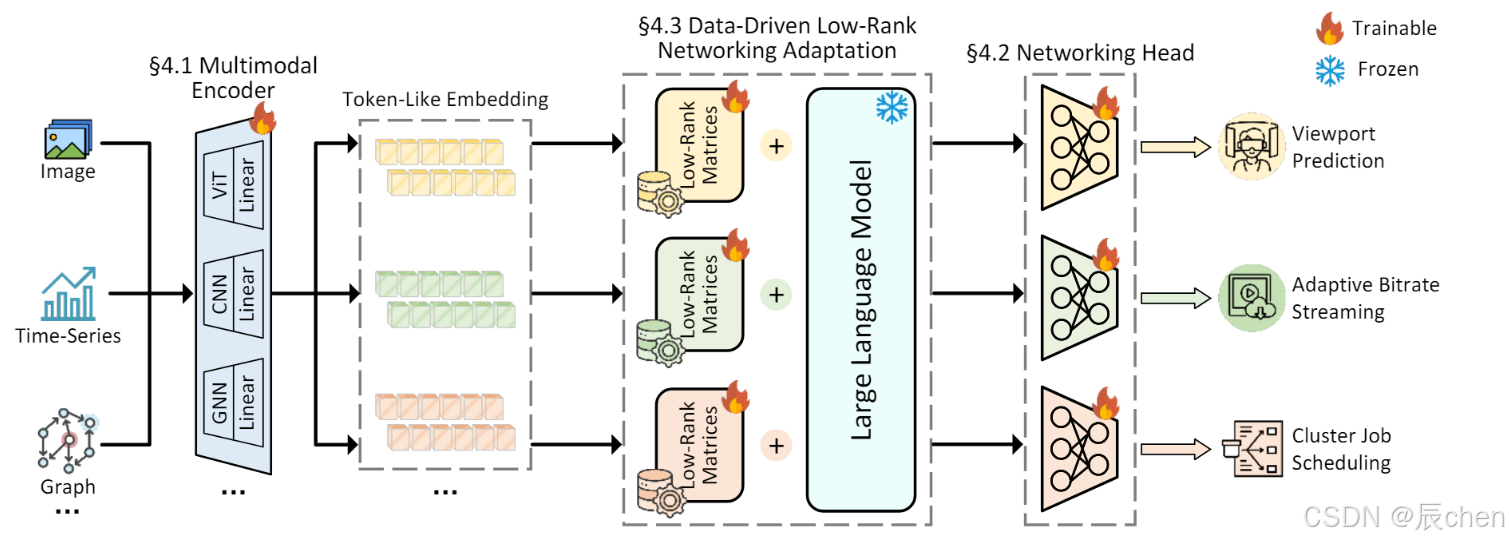
Multimodal Encoder

Feature encoder:对于不同种类的特征使用一些现有的高性能特征编码器提取特征。
Linear projection:解决提取到的特征维度与要求输入维度不等的问题。
Networking Head
相比于传统LLM,输出仅需一次推理,且输出的结果是有效的。
公式说明:
特定任务的数据集
:
D
s
l
=
X
,
Y
多模态编码器编码输入数据
:
x
L
L
M
中获取预测结果
:
y
^
网络头部计算参数更新的损失
:
L
s
l
=
F
s
l
(
y
,
y
^
)
特定任务的数据集:D_{sl}={X,Y} \\ 多模态编码器编码输入数据:x \\ LLM中获取预测结果: \hat{y} \\ 网络头部计算参数更新的损失:L_{sl}=F_{sl}(y, \hat{y})
特定任务的数据集:Dsl=X,Y多模态编码器编码输入数据:xLLM中获取预测结果:y^网络头部计算参数更新的损失:Lsl=Fsl(y,y^)
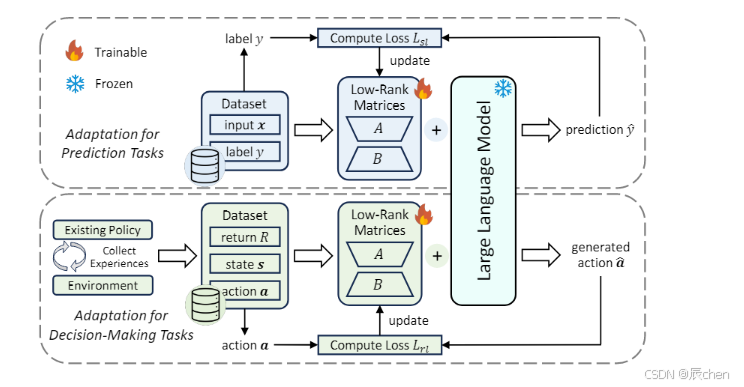
Data-Driven Low-Rank Networking Adaptation
DD-LRNA包含以下两个核心设计:
-
Data-Driven networking adaptation:DD-LRNA通过使用静态的、预先收集的数据集来优化模型,提高了训练的效率,降低了实时数据处理的复杂性和资源消耗。
公式说明:
多个经验轨迹: D r l = { τ 1 , … , τ ∣ D r l ∣ } 轨迹: τ = { r t , s t , a t } t = 1 T ,由奖励 r 、状态 s 和动作 a 组成 从状态 s t 预期获得的累计奖励: R t = ∑ i = t T r i ,替换 r t ( 强调未来奖励的重要性 ) 状态离散化: s t = { s t 1 , … , s t n } 动作离散化: a t = { a t 1 , … , a t m } τ = { R t , s t 1 , … , s t n , a t 1 , … , a t m } t = 1 T 随机抽样: d = { R i , s i 1 , … , s i n , a i 1 , … , a i m } i = t − w + 1 t ∈ D r l L L M 关于 d 的输出: { a ^ i 1 , . . . , a ^ i m } i = t − w + 1 t 损失函数: L r l = 1 w ∑ i = 1 w ∑ j = 1 m F r l ( a i j , a ^ i j ) 多个经验轨迹:\mathcal{D}_{rl} = \{\tau_1, \dots, \tau_{|\mathcal{D}_{rl}|}\} \\ 轨迹:\tau = \{r_t, s_t, a_t\}_{t=1}^T,由奖励r、状态s和动作a组成 \\ 从状态s_t预期获得的累计奖励:R_t = \sum_{i=t}^T r_i,替换r_t(强调未来奖励的重要性) \\ 状态离散化:s_t = \{s_t^1, \dots, s_t^n\} \\ 动作离散化:a_t = \{a_t^1, \dots, a_t^m\} \\ \tau = \{R_t, s_t^1, \dots, s_t^n, a_t^1, \dots, a_t^m\}_{t=1}^T \\ 随机抽样:d = \{R_i, s_i^1, \dots, s_i^n, a_i^1, \dots, a_i^m\}_{i=t-w+1}^{t} \in \mathcal{D}_{rl} \\ LLM关于d的输出:\{\hat{a}_i^1,...,\hat{a}_i^m\}_{i=t-w+1}^{t} \\ 损失函数:L_{rl} = \frac{1}{w} \sum_{i=1}^w \sum_{j=1}^m F_{rl}(a_i^j, \hat{a}_i^j) 多个经验轨迹:Drl={τ1,…,τ∣Drl∣}轨迹:τ={rt,st,at}t=1T,由奖励r、状态s和动作a组成从状态st预期获得的累计奖励:Rt=i=t∑Tri,替换rt(强调未来奖励的重要性)状态离散化:st={st1,…,stn}动作离散化:at={at1,…,atm}τ={Rt,st1,…,stn,at1,…,atm}t=1T随机抽样:d={Ri,si1,…,sin,ai1,…,aim}i=t−w+1t∈DrlLLM关于d的输出:{a^i1,...,a^im}i=t−w+1t损失函数:Lrl=w1i=1∑wj=1∑mFrl(aij,a^ij) -
Low-rank networking adaptation:冻结LLM的参数,引入了额外的低秩矩阵来近似LLM参数中所需的变化。该方法的基本思想是:调整期间的参数变化(即ΔΦ)**本质上是低秩**的。
公式说明:
预训练矩阵 W 0 ∈ Φ 0 ,维度为 d × k 假设 ∃ r ≪ m i n ( d , k ) 构建: A ∈ d × r , B ∈ r × k 更新优化为: W = W 0 + Δ W = W 0 + A B 预训练矩阵W₀ ∈ Φ₀,维度为d × k \\ 假设∃r≪min(d, k) \\ 构建:A∈d×r, B∈r×k \\ 更新优化为:W = W₀ + ΔW = W₀ + AB 预训练矩阵W0∈Φ0,维度为d×k假设∃r≪min(d,k)构建:A∈d×r,B∈r×k更新优化为:W=W0+ΔW=W0+AB
EVALUATION
Setup
三个基于学习的算法(基准线):
- VP 的 TRACK
- ABR 的 GENET
- CJS 的 Decima
三个性能指标:
- VP 的平均绝对误差(MAE):越低越好
- ABR 的体验质量(QoE):越高越好
- CJS 的作业完成时间(JCT):越低越好
Deep Dive
- 预训练知识的重要性与领域特定知识的重要性
- NetLLM 具有兼容性,适用于各种 LLM
- 参数超过 1B 的 LLM 适合用于网络适配
- 计算开销可以接受
DISCUSSION
多模态LLM并不一定优于单模态LLM,这一问题可以通过开发更通用的LLM(例如,支持更多模态)来缓解。
NetLLM 的理念可以轻松应用于其他网络任务,还需验证 NetLLM 在适配LLM以解决更多网络问题方面的有效性。
模型压缩研究可用于减少LLM的计算开销,这些研究可以整合到NetLLM中,以减少在实际网络部署中LLM的开销。
Codes
run_plm.py
LoRA技术:引入低秩矩阵来修改网络的权重,原始的高维权重矩阵可以通过两个较小的矩阵的乘积来近似表示。
adapt
-
初始化
- 优化器使用
AdamW加入了权重衰减,有助于控制模型的过拟合。
- 优化器使用
-
学习率调度器使用
LambdaLR动态调整学习率。 -
训练循环
- 每次训练后保存日志和损失
- 固定周期后保存检查点
- 固定周期评估模型,择优更新
-
记录最终损失
run
- 搭建模拟环境,设置经验池
- 加载指定模型,创建EncoderNetwork将环境状态信息转为NN可处理的形式,创建RL策略
- 使用裁剪和归一化处理设置奖励
plm_special
data
dataset.py:
discount_returns:计算给定奖励序列的折扣累积回报sample_batch:抽批次_normalize_rewards:奖励归一化_compute_returns:计算每个时间步的折扣累积回报。
models
state_encoder.py:
-
self.fc1和self.fc2是全连接层,分别用于编码上一个比特率和当前缓冲大小。 -
self.conv3、self.conv4和self.conv5是一维卷积层,用于编码过去的吞吐量、下载时间和接下来的块大小。 -
self.fc6是全连接层,用于编码剩余块数。 -
均使用
LeakyReLU激活函数来增加非线性
rl_policy.py:
- 设置多模态编码器部分
- 定义了
OfflineRLPolicy类的forward方法 - 在给定状态、目标回报和时间步的情况下,进行动作采样
gpt2.py:
- 模型初始化:嵌入层、Dropout层、主体层、归一化层
- 设置早停机制
llama.py:
- 模型初始化:嵌入层、多个解码层、规范化层(RMSNorm)
- 设置早停机制
utils
plm_utils.py:
- 将 Llama 模型的各个层分配到不同的设备(GPU)上
- 加载特定的预训练语言模型
- 向预训练模型的分词器中添加特殊令牌,并在必要时调整模型的嵌入层大小以适应新增的令牌。
utils.py:
- 处理批数据,转换为PyTorch张量,推送到指定设备
- 设置随机种子,确保可重复性
- 动作转比特率
- 从一系列日志文件中计算出平均奖励
trainer.py
- 训练器的初始化
- 分别定义训练一个批次和训练一个周期的函数
evaluate.py
- 评估一个环境中的模型表现
test.py
- 在指定的仿真环境中测试机器学习模型,主要关注模型的决策和性能。
Learning NetLLM Code Details
dataset.py
def discount_returns(rewards, gamma, scale):
折扣因子 gamma:决定未来奖励在当前的价值,较高的 gamma 值表示长远的回报对当前决策的重要性更大。
对于一个完整的奖励序列 r1, r2, ... , rn,从时间 t 开始的折扣回报 Rt 可以递归地表示为:
R
t
=
r
t
+
γ
r
t
+
1
+
γ
2
r
t
+
2
+
…
+
γ
n
−
t
r
n
R_t = r_t + \gamma r_{t+1} + \gamma^2 r_{t+2} + \ldots + \gamma^{n-t} r_n
Rt=rt+γrt+1+γ2rt+2+…+γn−trn
其中 γ 是折扣因子,rt 是在时刻 t 获得的即时奖励。
更有效的方法是使用逆序计算
for
t
=
n
−
1
to
1
:
R
t
=
r
t
+
γ
×
R
t
+
1
\begin{aligned} & \text{for } t = n-1 \text{ to } 1: \\ & \quad R_t = r_t + \gamma \times R_{t+1} \end{aligned}
for t=n−1 to 1:Rt=rt+γ×Rt+1
假设我们有一个简单的强化学习任务,智能体需要在一系列状态中选择最佳行为以最大化累积奖励。我们收集了以下经验数据:
- 状态列表:[S1, S2, S3, S4]
- 对应行为:[A1, A2, A3, A4]
- 对应奖励:[R1, R2, R3, R4]
- 完成标志:[False, False, True, False] —— 表示第三个行为后任务完成
给定折扣因子 γ=0.9
从后向前遍历:
-
对于第四个状态(S4),由于它后面没有完成任务,所以其折扣回报就是奖励本身,即 4。
-
第三个状态(S3)标志了一个任务的完成,因此它的回报是当前奖励加上后续折扣回报的 (0.9) 倍。计算如下:
R 3 = 3 + 0.9 × 0 = 3 R3 = 3 + 0.9 \times 0 = 3 R3=3+0.9×0=3 -
第二个状态(S2)的计算需要包括从这个状态开始直到任务完成的所有折扣奖励。计算如下:
R 2 = 2 + 0.9 × 3 = 4.7 R2 = 2 + 0.9 \times 3 = 4.7 R2=2+0.9×3=4.7 -
第一个状态(S1)的折扣回报包括从状态一开始直到任务完成的所有奖励:
R 1 = 1 + 0.9 × 4.7 ≈ 5.23 R1 = 1 + 0.9 \times 4.7 \approx 5.23 R1=1+0.9×4.7≈5.23
结果 折扣回报列表将会是:[5.23, 4.7, 3, 4]
缩放因子 scale:用于将回报值归一化,保持数值稳定性。
def sample_batch(self, batch_size=1, batch_indices=None):
假设我们的经验池包含以下数据,并且已经通过前面的步骤计算了折扣回报和时间步:
- 状态:[[S1], [S2], [S3], [S4]]
- 行为:[[A1], [A2], [A3], [A4]]
- 折扣回报:[[G1], [G2], [G3], [G4]]
- 时间步:[[0], [1], [2], [3]]
现在我们调用 sample_batch(batch_size=2) 方法:
- 由于没有提供
batch_indices,方法内部将随机选择两个索引,假设为1和3。 - 使用索引1和3从数据集中获取数据:
- 索引1:状态 [S2],行为 [A2],折扣回报 [G2],时间步 [1]
- 索引3:状态 [S4],行为 [A4],折扣回报 [G4],时间步 [3]
- 将获取的数据分别添加到批次数据列表中:
batch_states包含 [[S2], [S4]]batch_actions包含 [[A2], [A4]]batch_returns包含 [[G2], [G4]]batch_timesteps包含 [[1], [3]]
- 最终,方法返回这四个列表作为一批数据。
while episode_start < self.exp_pool_size:
try:
episode_end = self.dones.index(True, episode_start) + 1
except ValueError:
episode_end = self.exp_pool_size
self.returns.extend(discount_returns(self.rewards[episode_start:episode_end], self.gamma, self.scale))
self.timesteps += list(range(episode_end - episode_start))
episode_start = episode_end
assert len(self.returns) == len(self.timesteps)
假设我们的经验池数据如下:
- 状态:[S1, S2, S3, S4, S5]
- 行为:[A1, A2, A3, A4, A5]
- 奖励:[R1, R2, R3, R4, R5]
- 完成标志(
dones):[False, False, True, False, False]
在这个例子中,第三个时间步后有一个 True 值,表示一个episode结束。但是,最后一个时间步虽然没有 True 值,也会被视为一个episode的结束(因为已经是经验池的最后)。因此,代码会计算两个episode的折扣回报:
- 第一个episode从S1到S3,计算
R1到R3的折扣回报。 - 第二个episode从S4到S5,计算
R4和R5的折扣回报。
state_encoder.py
def __init__(self, conv_size=4, bitrate_levels=6, embed_dim=128):
bitrate_levels : 指视频可以被编码和传输的不同质量级别,一个视频可以有多个分辨率和码率的版本,每个版本对应一个比特率级别。
embed_dim : 嵌入维度的大小,它定义了网络输出特征的维度。用于初始化多个全连接层和卷积层的输出通道数,确保所有特征映射到相同维度的空间。
rl_policy.py
# =========== multimodal encoder (start) ===========
# 存储状态编码器和状态特征维度
self.state_encoder = state_encoder
self.state_feature_dim = state_feature_dim
# 创建一个嵌入层,用于将时间步转换为固定维度的向量。
# max_ep_len + 1 是嵌入矩阵的大小,确保可以嵌入从 0 到 max_ep_len 的任何时间步
self.embed_timestep = nn.Embedding(max_ep_len + 1, plm_embed_size).to(device)
# 线性层,将单一值(如返回值和动作值)转换为与PLM相同维度的向量。
self.embed_return = nn.Linear(1, plm_embed_size).to(device)
self.embed_action = nn.Linear(1, plm_embed_size).to(device)
# 多状态特征的嵌入层,将不同的状态特征转换为PLM的嵌入空间
self.embed_state1 = nn.Linear(state_feature_dim, plm_embed_size).to(device)
self.embed_state2 = nn.Linear(state_feature_dim, plm_embed_size).to(device)
self.embed_state3 = nn.Linear(state_feature_dim * (6 - conv_size + 1), plm_embed_size).to(device)
self.embed_state4 = nn.Linear(state_feature_dim * (6 - conv_size + 1), plm_embed_size).to(device)
self.embed_state5 = nn.Linear(state_feature_dim, plm_embed_size).to(device)
self.embed_state6 = nn.Linear(state_feature_dim, plm_embed_size).to(device)
# 规范化嵌入向量
self.embed_ln = nn.LayerNorm(plm_embed_size).to(device)
# =========== multimodal encoder (end) ===========
def forward(self, states, actions, returns, timesteps, attention_mask=None):
嵌入向量的意义:是高维空间中的点,它们能够以密集的形式表示原始数据的信息。每个状态、动作、回报和时间步被转换为嵌入向量,这些向量是通过学习得到的,能够捕捉输入数据的重要特征。时间步的嵌入加到其他嵌入上,可以帮助模型理解序列中每个元素的位置或顺序,这对于处理序列数据非常重要。
时间步嵌入的原因:告诉模型序列中每个状态或动作发生的具体时刻、帮助模型捕捉序列中的时间动态、模型可以更容易地学习到不同时间步骤之间的依赖关系(如需要基于前一个状态或动作来预测下一个动作的场景)、自回归模型时,时间步嵌入可以增强模型对序列的理解。
堆叠嵌入向量:“将回报、状态和动作嵌入按序堆叠起来”意味着将这些不同的嵌入向量按照它们在序列中的逻辑顺序(如先是回报,再是状态,最后是动作)连续排列。这种排列方式使得整个输入序列像是一个自然语言处理中的长句子,每个嵌入向量都是句子中的一个“词”,这样预训练模型就可以按照这个序列来预测下一个最可能的“词”(在这里是动作)。
这里的步骤可以总结为以下几点:
- 特征嵌入:将动作、回报、和时间步转换成嵌入向量。这些嵌入向量通过专门的神经网络层(如
nn.Linear和nn.Embedding)生成,以将单一或者少量维度的数据映射到更高维的表示空间中。 - 时间步嵌入:时间步的嵌入类似于自然语言处理中的位置嵌入(positional embeddings),它帮助模型理解序列数据中各个元素的顺序。这里,时间步的嵌入被加到了动作嵌入和回报嵌入上,增强了时间信息在决策过程中的作用。
- 状态特征编码:状态特征通过一个专门的状态编码器(
state_encoder)处理,目的是从原始状态数据中提取有用的特征表示。 - 特征融合:将所有的嵌入向量(包括动作、回报、时间步以及从多维状态数据中提取的多个嵌入结果)按序堆叠成一个大的序列。这个序列捕捉了决策点的全面信息,为下一步的预测提供了必要的上下文。
- 动作预测:堆叠的嵌入向量被送入一个预训练的语言模型(PLM),以处理序列化的数据并产生预测输出。输出再经过一个特定的网络层(如动作头)来预测最优动作。
def forward(self, states, actions, returns, timesteps, attention_mask=None):
这里的步骤可以总结为以下几点:
-
堆叠以前的状态、动作和回报特征
-
处理目标回报和时间步:生成回报和时间步的嵌入向量,并将时间步嵌入向量加到回报嵌入向量上。
-
处理状态:输入的状态通过状态编码器转换为特征表示,每个特征都会被进一步处理成嵌入向量,状态特征的嵌入向量与时间嵌入向量相加,以整合时间信息。
-
堆叠回报、状态和先前的嵌入向量:把以前的状态等信息和本次的信息堆叠在一起送入模型进行预测么
-
通过预训练语言模型处理堆叠的嵌入:堆叠的嵌入向量通过层归一化,然后输入到PLM中
-
预测动作
-
更新队列
gpt2.py
self.wte = nn.Embedding(config.vocab_size, self.embed_dim)
嵌入层:把一个单词(最大单词数为vocab_size)转换为一个固定长度(embed_dim)的向量,方便后续处理。
llama.py
def _prepare_decoder_attention_mask(self, attention_mask, input_shape, inputs_embeds, past_key_values_length):
注意力掩码(Attention Mask):用于控制模型应该关注(即"注意")序列中的哪些部分。在实现上,注意力掩码通常是一个与输入序列形状相匹配的张量,在需要遮蔽的位置上的值非常小(如负无穷),而其他位置的值为0。这样,在计算softmax归一化的注意力权重时,遮蔽位置的权重会接近于0,从而在实际的注意力计算中被忽略。
plm_utils.py
tokenizer = model_class.tokenizer.from_pretrained(model_path)
print("If tokenizer is loaded: ",tokenizer.encode("hello world"),"\n")
wrapper = model_class.wrapper
model, tokenizer = add_special_tokens(model, tokenizer, specials_to_add=specials_to_add)
**分词器(Tokenizer)**是用于将文本数据转换为模型可以理解的格式的工具。在自然语言处理(NLP)任务中,模型无法直接处理原始文本,需要将文本转换为数值形式。分词器负责这一转换过程,通常包括以下步骤:
- 分词(Tokenization):将连续的文本字符串分割成较小的单元,例如单词、子词或字符。
- 编码(Encoding):将分割后的单元转换为整数索引。
- 添加特殊标记:例如,句子开始(BOS)和结束(EOS)标记,或用于填充(Padding)的标记。
示例: 假设我们有一个简单的英文句子:“Hello, world!”。使用一个基本的分词器,该句子可能会被分割为 [“Hello”, “,”, “world”, “!”],然后每个分词根据词汇表被编码为一个整数,例如 [687, 12, 523, 3]。
分词器和嵌入层之间的工作流程是紧密连接的,主要步骤如下:
- 分词器(Tokenizer):首先使用分词器处理文本。分词器将文本分解成更小的单元(如词、子词片段或字符),并将这些单元转换为数字ID。这个过程通常包括清洗文本、分割词汇和映射到预定义词汇表的索引。
- 嵌入层(Embedding Layer):接着,这些数字ID被送入嵌入层。嵌入层将每个数字ID转换为一个密集的向量表示。这些向量是在模型训练过程中学习得到的,能够捕捉单词之间的语义和语法关系。
**包装器(Wrapper)**是一个封装层,用于处理模型和其它组件(如分词器)之间的交互。在使用预训练模型(如BERT、GPT等)进行特定任务时,直接与原始模型交互可能不够方便或不符合任务需求。包装器提供了一种灵活的方式来调整模型的输入输出,以适应特定任务的需求。
示例: 假设我们使用BERT模型进行情感分类任务。原始BERT模型输出一系列与输入文本同样长度的隐藏状态,但情感分类只需要基于整个输入的一个总体判断。这时,可以使用一个包装器来提取BERT输出的第一个token(通常对应于特殊的分类标记[CLS])的隐藏状态,并将其传递给一个分类层,最终输出正面或负面的情感判断。
utils.py
def calc_mean_reward(result_files, test_dir, str, skip_first_reward=True):
matching = [s for s in result_files if str in s]
reward = []
count = 0
for log_file in matching:
count += 1
first_line = True
with open(test_dir + '/' + log_file, 'r') as f:
for line in f:
parse = line.split()
if len(parse) <= 1:
break
if first_line:
first_line = False
if skip_first_reward:
continue
reward.append(float(parse[7]))
print(count)
return np.mean(reward)
跳过每个文件的第一行奖励值skip_first_reward=True(可能因为第一行是初始化值或者只是表头)
举例:
file1.txt
time step reward
0 1 2.0
1 2 3.5
2 3 3.0
file2.txt
time step reward
0 1 1.0
1 2 4.0
2 3 5.0
result_files = ["file1.txt", "file2.txt"]
test_dir = "/path/to/logfiles"
keyword = "file"
mean_reward = calc_mean_reward(result_files, test_dir, keyword, skip_first_reward=True)
print("Average Reward:", mean_reward)
-
匹配文件:
matching = ['file1.txt', 'file2.txt']- 匹配所有包含"file"的文件。 -
初始化奖励列表和计数器:
reward = []count = 0 -
逐文件处理:
-
对于
file1.txt:- 读取并跳过第一行(如果
skip_first_reward=True)。 - 从第二行开始,解析每行的第三个值作为奖励,并添加到
reward列表。 reward更新为[3.5, 3.0]。
- 读取并跳过第一行(如果
-
对于
file2.txt:- 类似地处理,跳过第一行。
reward更新为[3.5, 3.0, 4.0, 5.0]。
-
-
计算平均值并返回:
np.mean(reward)计算出3.875。
输出:
Average Reward: 3.875
trainer.py
for step, batch in enumerate(self.dataloader):
train_loss = self.train_step(batch)
train_losses.append(train_loss.item())
# perform gradient accumulation update
# 将损失除以梯度累积步数,用于实现梯度累积
train_loss = train_loss / self.grad_accum_steps
train_loss.backward()
# 梯度裁剪,防止梯度爆炸
torch.nn.utils.clip_grad_norm_(self.model.parameters(), .25)
if ((step + 1) % self.grad_accum_steps == 0) or (step + 1 == dataset_size):
self.optimizer.step()
self.optimizer.zero_grad(set_to_none=True)
# 如果存在学习率调度器,更新学习率。
if self.lr_scheduler is not None:
self.lr_scheduler.step()
梯度累积:这种方法允许模型以比物理内存限制更大的有效批量大小进行训练。模型参数的更新不是在每个批次后立即进行,而是在多个批次的梯度被累加之后进行。这意味着每个批次计算得到的梯度不会立即用于更新参数,而是累积到一定数量后,再统一进行参数更新。这样做可以模拟更大批量数据的训练效果,有助于稳定训练过程并提高模型性能。
梯度裁剪:指在训练过程中梯度的值变得非常大,以至于更新后的模型参数使得模型变得不稳定。梯度裁剪通过设定一个阈值,将那些超过这个阈值的梯度裁剪到一个最大值,从而控制梯度的最大更新量。


















 189
189

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











