







目录
一、Communication-Efficient Learning of Deep Networks from Decentralized Data
二、Federated Machine Learning:Concept and Applications
三、Towards Federated Large Language Models:Motivations, Methods, and Future Directions
A. 框架与基准(Framework & Benchmark)
B. 数据与模型初始化(Data and Model Initialization)
C. 联邦LLM微调(Federated LLM Fine-tuning)
D. 个性化联邦LLM(Personalized Federated LLM)
E. 无反向传播方法(Back-propagation-free Methods)
F. 局限性与经验教训(Limitations and Lessons Learned)
3.5 FL 和LLM 结合时在隐私和鲁棒性方面的最新研究进展
A. 联邦LLM隐私(Federated LLM Privacy)
B. 针对联邦LLM隐私攻击的防御方法(Defence Methods Against Federated LLM Privacy Attacks)
C. 联邦LLM鲁棒性(Federated LLM Robustness)
4.2 FederatedScope-LLM(FS-LLM)的总体架构概览
五、Securing federated learning with blockchain: a systematicliterature review
1.单点故障攻击(Single Point of Failure Attack, SPoF)
2.拒绝服务与分布式拒绝服务攻击(Denial of Service and Distributed Denial of Service Attack, DoS/DDoS)
5. 中间人攻击(Man-in-the-Middle Attack, MitM)
6. 窃听攻击(Eavesdropping Attacks)
学习路线:
1、《Communication-Efficient Learning of Deep Networks from Decentralized Data》
联邦学习开山之作
2、《Federated Machine Learning:Concept and Applications》
联邦学习新的概念,一篇综述
3、《Towards Federated Large Language Models:Motivations, Methods, and Future Directions》
联邦学习和LLM
一、Communication-Efficient Learning of Deep Networks from Decentralized Data
1.1 引言
简述:
每个客户端都有一个本地训练数据集,它永远不会上传到服务器。相反,每个客户端计算对服务器维护的当前全局模型的更新,并且仅传递此更新。
贡献:
1)识别来自移动的设备的分散数据的训练问题作为一个重要的研究方向;
2)选择一个简单实用的算法,可以应用于此设置;
3)所提出的方法的广泛的实证评估。更具体地说,我们提出了FederatedAveraging算法,该算法将每个客户端上的局部随机梯度下降(SGD)与执行模型平均的服务器相结合。我们对该算法进行了广泛的实验,证明它对不平衡和非IID数据分布具有鲁棒性,并且可以将在分散数据上训练深度网络所需的通信次数减少几个数量级。
联邦学习的理想问题具有以下属性:
1)在来自移动的设备的真实数据上进行训练,与在数据中心通常可用的代理数据上进行训练相比,具有明显的优势。2)这些数据是隐私敏感的,或者数据量很大(与模型的大小相比),因此最好不要将其记录到数据中心,纯粹用于模型训练(服务于集中收集原则)。3)对于监督任务,数据上的标签可以从用户交互中自然推断出来。
联邦学习对于隐私性的保护:
- 会进行通信的数据只有需要的更新,这保证了用户数据的安全;
- 更新数据不需要保存,一旦更新成功,更新数据将被丢失;
- 通过更新数据对原始数据的破解几乎不可能。
什么是联邦优化:
我们将联邦学习中隐含的优化问题称为联邦优化,与分布式优化进行联系(和对比)。联邦优化有几个关键属性,将其与典型的分布式优化问题区分开来:(不同的用户有着不同的行为)
-
非独立同分布(Non-IID):客户端的训练数据通常基于特定用户对移动设备的使用模式,因此任何用户的本地数据集都无法代表总体数据分布。
-
数据不平衡(Unbalanced):不同用户对服务或应用的使用程度差异巨大,导致本地训练数据量极不均衡。(指某些参与者的数据可能很多,而某些参与者数据可能很少)
-
大规模分布式(Massively Distributed):参与优化的客户端数量远大于每个客户端的平均数据量。(一个软件的用户可能非常多)
-
通信受限(Limited Communication):移动设备经常离线或处于低速、高成本的网络连接中。


在数据中心优化中,通信成本相对较低,而计算成本占主导地位。近年来,人们主要通过使用GPU来降低这些计算成本。相比之下,在联邦优化中,通信成本成为主要瓶颈——通常受限于上传带宽(如1 MB/s或更低)。此外,客户端通常仅在设备处于充电状态、连接未计量的Wi-Fi网络时,才愿意参与优化任务,且每天仅参与少量的更新轮次。另一方面,由于单个设备的数据集规模远小于总数据集规模,而现代智能手机的处理器(包括GPU)速度较快,对于许多模型类型而言,计算成本相比通信成本几乎可以忽略不计。因此,我们的目标是通过增加计算量来减少训练模型所需的通信轮次。
实现这一目标的主要方法有两种:
-
提高并行性:在每轮通信之间使用更多客户端独立进行计算;
-
增加每个客户端的计算量:让每个客户端在通信间隔执行更复杂的计算(如多轮本地梯度下降),而非仅执行简单的梯度计算。
尽管我们研究了这两种方法,但实验表明,速度提升主要源于增加每个客户端的计算量(前提是已实现一定程度的客户端并行性)。
联邦平均算法(就是聚合算法)
FedAvg 结合了客户端的本地随机梯度下降(SGD)和服务器端的模型平均。每个客户端在本地数据集上执行多次迭代更新,然后服务器对这些更新进行加权平均以更新全局模型。
FedSGD: 联邦随机梯度下降
知识补充:


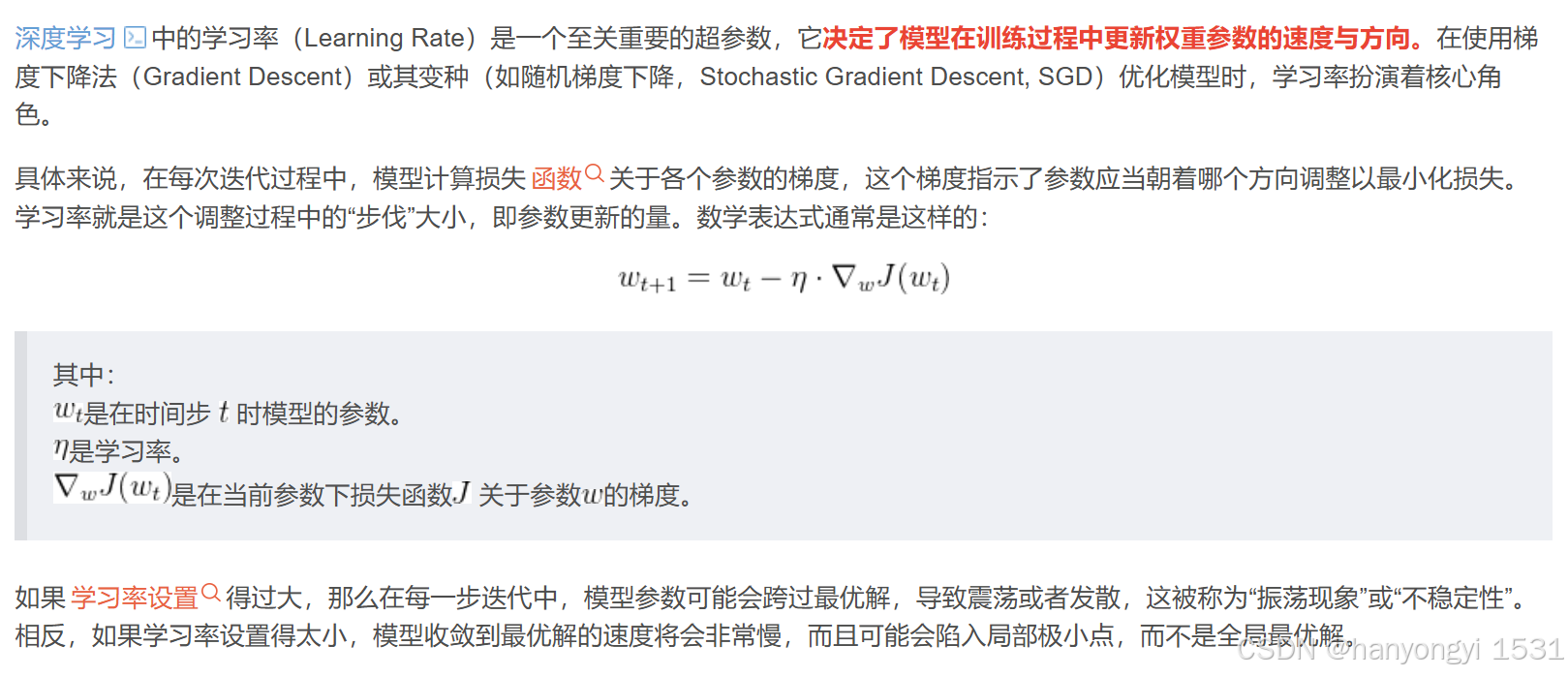
本质:平均梯度是本地数据对模型参数的“集体建议”,其加权平均确保了全局优化的方向与数据分布一致

每个参数都有一个对应的梯度值,因此梯度的大小和形状与参数相同。


二、Federated Machine Learning:Concept and Applications
参考这个文章:简单理解什么叫联邦学习(全)-CSDN博客
背景:如今人工智能仍然存在两个重大挑战:
- 1)数据以孤岛的形式存在;
- 2)数据隐私和安全问题。
引出:本文提出了可能的解决方案:一个更全面的安全联邦学习框架。该框架包括Horizontal(水平or横向)联邦学习、Vertical(垂直or纵向)联邦学习,以及联邦Transfer(迁移)学习。本文提供了联邦学习框架的定义、架构和应用程序,以及建立了基于联邦机制的组织之间建立数据网络,作为一种可以在不损害用户隐私的情况下共享知识(知识指参数、梯度等 )的有效解决方案。
2.1联邦学习的定义

2.2联邦学习隐私
隐私是联邦学习的基本属性之一,这需要安全模型和分析来提供有意义的隐私保证。下面介绍联邦学习的不同隐私技术,并确定防止间接泄露的方法和潜在挑战。
安全多方计算(SMC):
安全多方计算(SMC)的核心目标之一就是确保每个参与方只能知道自己的输入和最终的输出结果,而无法得知其他参与方的输入或计算过程中泄露的中间信息。
SMC 的设计确保:
- 协作方不会通过参与计算获得超出输入和输出之外的信息。
- 数据在多个参与方之间被“秘密共享”(secret sharing),即使单个方或服务器被攻破,也无法还原出原始数据。

差分隐私:另一种工作使用差分隐私 [18] 或k-匿名 [63] 技术来保护数据隐私 [1,12,42,61]。差分隐私、k-匿名和多样化 [3] 的方法涉及在数据中加入噪声,或使用泛化方法来掩盖某些敏感属性,直到第三方无法区分个体,从而使数据无法恢复到保护用户隐私。但是,这些方法的根源仍然要求将数据传输到其他地方,并这些工作通常涉及准确性和隐私之间的权衡。在 [23] 中,作者为联邦学习引入了一种差分隐私方法,以便通过在训练期间隐藏客户端的贡献来增强对客户端数据的保护。
它们的核心目标是让攻击者无法识别或区分具体的个体,从而保护用户隐私。

同态加密:机器学习过程中还采用同态加密 [53] ,通过加密机制下的参数交换来保护用户数据隐私 [24,26,48] 。与差分隐私保护不同,数据和模型本身不会传输,也不会被对方的数据猜到。因此,在原始数据层面泄露的可能性很小。最近的工作采用同态加密来集中和训练云上的数据[75,76] 。在实践中,加法同态加密 [2] 广泛使用,并且需要进行多项式近似来评估机器学习算法中的非线性函数,从而导致准确性和隐私性之间的权衡[4,35]。
**同态加密(Homomorphic Encryption,HE)**是一种加密技术,允许在加密数据上直接执行计算操作,而无需解密数据。计算结果经过解密后,与直接对明文计算的结果一致。
换句话说,同态加密可以让数据在加密状态下参与计算,确保数据隐私的同时支持数据的有效利用。
2.3间接信息泄露
先前联邦学习的工作暴露了中间结果, 例如来自优化算法,如随机梯度下降(SGD) [41,58]的参数更新,但没有提供安全保证,当这些梯度与数据结构(如像素图)一起暴露时,实际上可能会泄漏重要的数据信息 [51] 。研究人员考虑了一种情况,即联邦学习系统的一个成员通过允许插入后门来学习他人数据,从而恶意攻击他人。在 [6] 中,作者证明了在联合全局模型中插入隐藏后门是可能的,并提出了一种新的“约束-规模”模型中毒方法来减少数据中毒。在 [43] 中,研究人员发现了协作机器学习系统中潜在的漏洞,即协作学习中各方使用的训练数据很容易受到推理攻击。他们表明,敌对的参与者可以推断出成员以及与训练数据子集相关的属性。他们还讨论了可能的防御措施。在 [62] 中,作者暴露了一个潜在的安全问题,与不同方之间的梯度交换有关,并提出了梯度下降方法的一个安全变体,并表明它可以容忍恒定分数的拜占庭工人。
研究人员也开始将区块链视为促进联邦学习的平台。在 [34] 中,研究人员考虑了一种区块链联邦学习(BlockFL)架构,其中移动设备的本地学习模型更新通过利用区块链进行交换和验证。他们考虑了最佳区块生成、网络可扩展性和健壮性问题。
2.3 联邦学习的分类
水平联邦学习、垂直联邦学习、联邦迁移学习(详见下一章节)

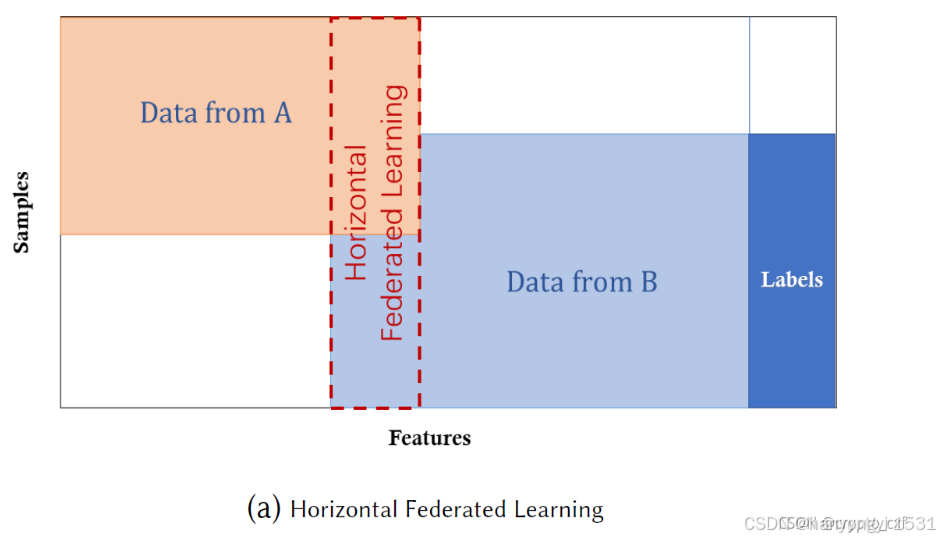

水平联邦学习用人话表述:不同的人提供差不多类型的东西
激励机制
为了使不同组织之间的联邦学习完成商业化,需要建立一个公平的平台和激励机制 [20] 。在建立模型之后,模型的性能将在实际应用程序中得到体现,并且这种性能可以永久的数据记录机制中记录下来,如区块链。模型的有效性取决于数据提供者对系统的贡献。上述架构的实现不仅考虑了多个组织之间的隐私保护和协作建模的有效性,而且还考虑了如何奖励贡献更多数据的组织,以及如何通过共识机制实现激励。因此,联邦学习是一种“闭环”的学习机制。
三、Towards Federated Large Language Models:Motivations, Methods, and Future Directions
虽然LLM在各个领域取得了令人印象深刻的成功,但这些模型需要大量的高质量数据和大量的计算资源,这导致LLM的培训和利用成本高昂。此外,LLM通常依赖于广泛的公共数据集进行训练。为了提高它们在特定领域的业绩,它们需要纳入来自医院和银行等私营实体的数据。然而,这些高度敏感的数据构成了隐私挑战,除非得到很好的解决,否则会阻碍LLM的进一步改进。
将FL与LLM相结合引入了新的和未探索的挑战。这些挑战包括联邦LLM培训的异质性,以及这种合并带来的新的隐私和安全问题。例如,FL与LLM的集成引起了关于数据泄漏和模型反转攻击的重大关注。攻击者可以利用训练过程中共享的梯度来推断有关底层数据的敏感信息。因此,迫切需要开发先进的密码技术和差分隐私方法来防范此类威胁。此外,FL和LLM的合并需要严格的访问控制和认证协议,以防止未经授权的访问,并确保训练数据的机密性。
3.1 本文贡献:
1)我们提出了一个国家的最先进的调查联邦LLM的主题,开始介绍基本的系统概念和FL和LLM的最新进展。我们还深入讨论了整合FL和LLM背后的动机,深入探讨了这个联盟如何促进创新和提高两个领域的效率。
2)我们对现有的工作进行全面的调查和分析,从预培训和微调到应用。各种详细的主题,如数据的建设,初始化和研究有关的异质性,进行了彻底的审查。此外,我们还提供了分类表,总结了联邦LLM的每个拟议方法的关键技术方面和贡献。
3)此外,我们从隐私和健壮性的角度进行了彻底的审查。我们已经策划了一个联邦LLM可能遇到的隐私和安全潜在威胁的列表,沿着了相应防御策略的详细分析。此外,我们还提供了分类表,总结了这些研究工作,提供了该领域的现状和挑战的清晰概述。
4)我们确定了几个关键的研究挑战,并概述了前瞻性的研究方向,旨在提高联邦LLM的性能和实用性。
3.2 背景
3.2.1 联邦学习
根据跨客户端的数据分布的性质,FL通常分为三个不同的类别,包括水平联合学习(HFL)[53],垂直联合学习(VFL)[54]和转移联合学习(TFL)[55],如图3所示。
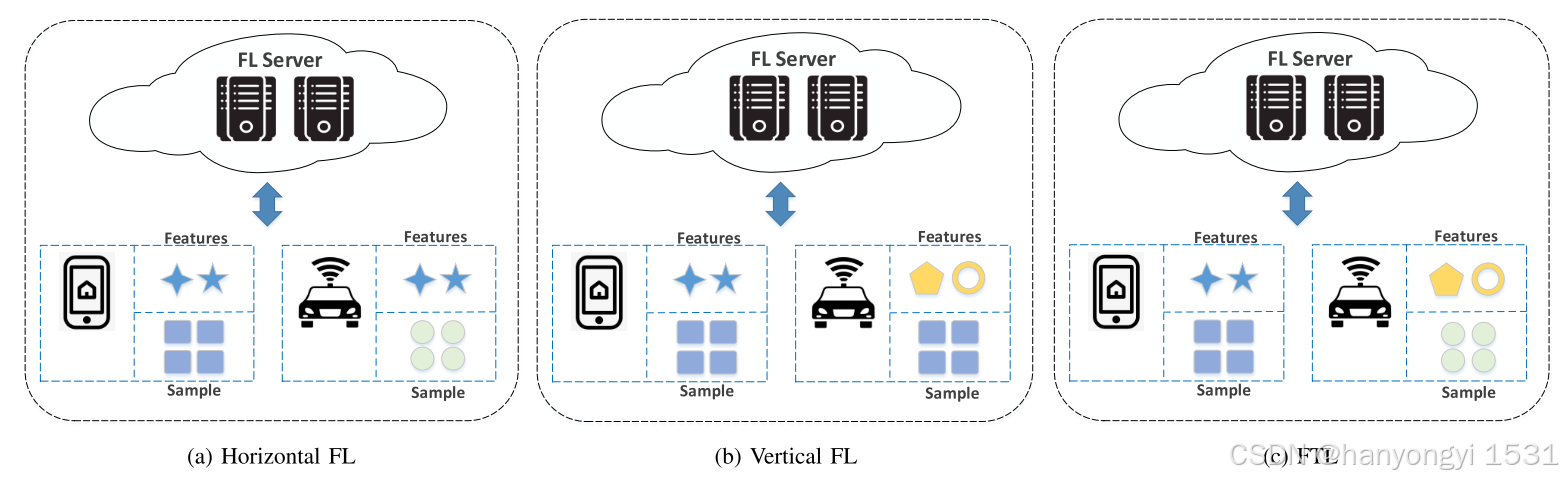
sample指的是样本(例如用户),每个用户有很多的特征(features)

根据网络结构划分:从网络架构的角度来看,FL可以分为两个子类别:集中式联邦学习(CFL)和分散式联邦学习(DFL)。
CFL是FL中最广泛采用的框架。这种结构涉及一个中央服务器与众多客户端协调来实现FL模型。在每次训练迭代期间,客户端根据本地数据单独训练他们的模型,然后将更新的参数转发到中央服务器。服务器采用专门的算法来聚合这些参数,例如Federated Averaging(FedAvg)[51],以产生全局模型。这一全球模式随后在所有客户中传播,以供进一步培训。然而,CFL的集中式设计可能会导致单点故障、信任依赖和服务器瓶颈等问题。这些都是中央服务器发挥关键作用的系统中的常见挑战。与CFL系统相比,DFL提出了一种无服务器的FL范例。这种方法强调了采用对等模型进行交付和聚合的好处,该模型独立于中央可信服务器。分散式FL中的参与者不是专门与中央服务器交互,系统通过利用彼此之间的网络连接,可以充分利用网络带宽。这种点对点通信允许更分布式和潜在更有弹性的系统。DFL的这些现代属性使其与点对点通信技术兼容,包括区块链[56],[57],以建立分散的FL网络。
分类方式的解说详看:
联邦学习分类合集-CSDN博客(写得太好了)
3.2.2 大模型
LLM-assisted FL:虽然FL可以解决与LLM相关的许多挑战,但LLM可以为经典FL提供大量支持。例如,经典FL中的一个常见问题是客户端漂移,这是由于客户端之间的私有数据分布的异质性引起的。为了提高FL性能,最近的研究表明,将从公共领域收集的数据,如互联网,到FL过程。利用公共数据的方法的成功在很大程度上取决于收集的公共数据的质量。为了克服与公共数据有关的限制,已经开发了用于FL的合成数据。LLM在广泛的数据集上进行预训练,具有强大的数据分布拟合能力。这使他们能够创建合成数据,忠实地反映现实生活中数据场景的多样性和复杂性。
此外,LLM可以通过称为知识蒸馏的过程有效地解决FL中次优性能的问题[78],[79]。知识蒸馏是一种技术,其中LLM,作为“教师”,赋予其知识,以简化FL框架内更基本的“学生”模型的培训。LLM通常采用知识蒸馏来提炼和浓缩学生模型。随后,FL网络中的每个参与者都利用这种经过提炼的学生模型来加强他们在当地的培训工作。将见解从LLM转移到较小的模型,提高了后者的性能和概括能力,解决了稀缺或分布不均匀的数据所带来的挑战。这种方法允许在FL系统内进行更高效和更有效的学习。
微调(分为三类):
- 监督微调(Supervised Fine-Tuning, SFT):使用任务特定标注数据优化模型,包含指令调优(Instruction Tuning)以提升模型对人类指令的理解。
- 对齐调优(Alignment Tuning):通过如强化学习与人类反馈(RLHF)消除偏见和不良内容,确保模型输出符合人类意图。
- 参数高效调优(Parameter-efficient Tuning, PEFT):如LoRA、Prefix Tuning等,仅调整少量参数以降低资源需求,适合消费级硬件。
3.3 FL和LLM结合的的动机和挑战
1. LLM训练数据的海量与分布式特性(Massive and Distributed Nature of LLM Training Data)
-
现状:LLMs(如GPT-3使用45TB数据,LLaMA-2使用20万亿token)需要海量高质量数据进行预训练,但公开数据的供应预计在五年内耗尽,且获取成本(如Twitter数据收费)与法律问题(如版权)日益增加。
-
FL的解决方案:FL允许直接利用分布在私人领域的大量数据(如个人和企业数据),无需集中式整合,避免隐私风险和复杂的数据迁移,从而为LLM提供更多样化的训练数据,优化预训练、微调和提示调优过程。
2. 数据隐私(Data Privacy)
-
问题:LLM训练涉及大量分布式数据,隐私保护成为关键问题。
-
FL的优势:FL无需传输原始数据,仅交换模型权重或梯度更新,确保敏感数据留在本地,降低外部泄露风险,从而增强LLM训练和应用中的隐私保护。
3. 持续性能改进与数据更新(Continuous Performance Improvement with Updating Data)
-
挑战:现实世界数据(如无人机、移动机器人生成的数据)不断增长,LLM需保持知识的时效性和相关性。
-
FL的贡献:FL支持模型持续适应和改进,利用分布式异构数据源进行本地微调,仅上传模型更新而非数据,实现全局模型的逐步增强。
4. LLM训练的高计算需求(High Computational Demand for LLM Training)
-
现状:LLM的大量参数需要巨大计算资源,单个实体难以独立完成训练。
-
FL的解决方式:FL通过分布式训练分担计算负担,结合不同计算能力的客户端(如低算力设备也能参与),减轻单点压力。
5. 模型个性化和适应性(Model Personalization and Adaptation)
-
需求:LLM需适应特定领域(如医疗、金融)并减少训练偏差。
-
FL的作用:FL的去中心化特性支持基于用户生成数据的个性化训练,提供定制化服务,同时通过数据多样性减少偏见,提升模型在不同任务和领域的表现。
6. LLM辅助FL(LLM-assisted FL)
-
FL的挑战:传统FL面临客户端漂移(client drift)等问题,因私有数据异构性导致性能下降。
-
LLM的帮助:
-
合成数据生成:LLM利用其预训练能力生成高质量合成数据,弥补公共数据不足,缓解非独立同分布(non-IID)问题。
-
知识蒸馏(Knowledge Distillation):LLM作为“教师”模型,通过知识转移优化FL中的“学生”模型,提升性能和泛化能力,尤其在数据稀疏或分布不均时
-
B. 挑战(Challenges)
这一部分分析了FL与LLM整合时面临的困难,重点从架构设计、隐私和安全性等方面展开。
1. 计算与通信资源问题(Computational and Communication Resource Issues)
-
问题:LLM的庞大规模导致FL中模型更新和参数同步的通信成本激增,计算密集性对客户端资源构成挑战。
-
缓解策略:
-
剪枝(pruning)、量化(quantization)和知识蒸馏等技术可减小模型规模。
-
对预训练模型进行微调而非从头训练可降低资源需求。
-
2. 同步与协调(Synchronization and Coordination)
-
问题:LLM参数众多,同步更新耗时长,可能导致更新过时(staleness),影响全局模型收敛。
-
解决方案:
-
同步聚合:等待所有客户端更新,增加延迟。
-
异步聚合:接收部分更新即聚合,需处理过时刻差。
-
延迟感知聚合:根据更新时效性加权处理。
-
处理慢客户端(stragglers):设置更新截止时间或部分聚合。
-
3. 异构性(Heterogeneities)
-
数据异构性(Data Heterogeneity):客户端数据非IID,导致模型发散。
-
系统异构性(System Heterogeneity):客户端计算能力、网络条件差异,影响训练进度。
-
解决方法:个性化联邦学习(如meta-learning、多任务学习)为每个客户端定制模型。
4. 隐私与安全问题(Privacy and Security Issues)
-
威胁:LLM易受对抗样本、后门攻击、数据投毒、模型窃取等威胁,尤其在FL中共享梯度可能泄露信息。
-
例子:词嵌入投毒可通过修改单一向量操控模型,联邦网络中少量受损客户端即可影响全局模型。
-
需求:需开发高级隐私保护技术(如加密、差分隐私)应对这些挑战。
3.4 FL 和LLM的预训练和微调结合的进展、现状
A. 框架与基准(Framework & Benchmark)
这一部分介绍了支持联邦LLM的工具、平台和基准研究,强调基础设施对推动研究的重要性。
-
背景:Google率先将FL用于Gboard的下一词预测和查询建议,之后出现了多种FL系统(如TFF、FedLab等)。近年来,针对LLM的FL框架迅速发展。
-
主要框架:
-
FedLLM / FATE-LLM / FS-LLM:
-
FedLLM:基于FedML,支持企业级私有数据训练,提供MLOps管道,支持LoRA等参数高效微调方法。
-
FATE-LLM(图5):基于FATE,支持异构和同构LLM的联邦训练,采用LoRA和P-Tuning-v2优化效率,并通过隐私保护机制保护知识产权。
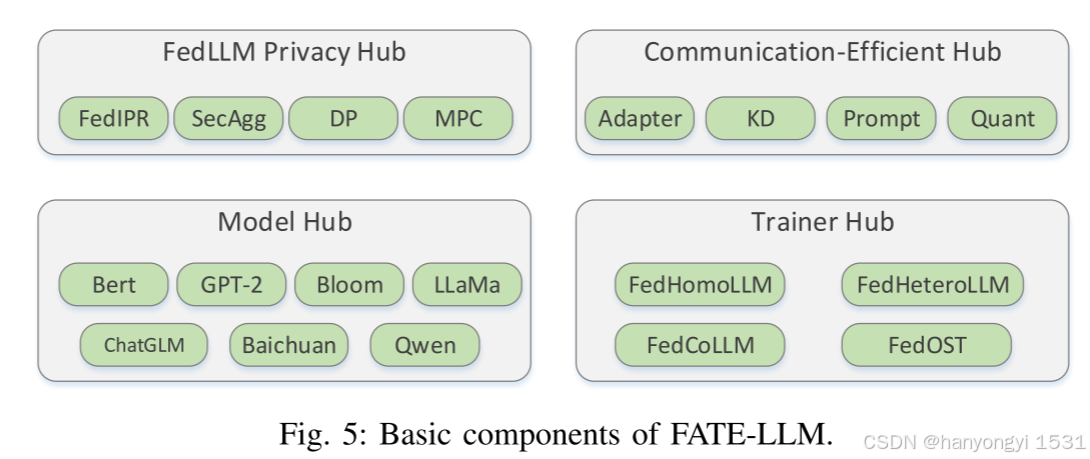
-
FS-LLM:全面工具包,提供数据集准备到性能评估的完整基准,支持多种PEFT算法,适应资源受限环境。
-
-
OpenFedLLM:通过FL协作优化共享模型,支持联邦指令调优和价值观对齐,涵盖8个训练数据集和30+评估指标。
-
-
基准研究:
-
FedIT:首个联邦指令调优研究,利用跨设备FL提升指令多样性,使用GPT-4自动评估验证效果。
-
Woisetschlager等人:对比边缘计算与数据中心GPU,微调FLAN-T5用于文本摘要,分析硬件效率。
-
Zhao等人:结合FL、PEFT和差分隐私(DP),优化通信成本并保护隐私。
-
其他模态:如Flower(微调Whisper用于关键词检测)和FedCLIP(轻量化CLIP适配器)。
-
B. 数据与模型初始化(Data and Model Initialization)
这一部分探讨了数据处理和模型初始化的关键作用及其在联邦LLM中的研究。
-
背景:传统FL常随机初始化权重,而集中式学习使用预训练权重以提升性能。联邦LLM需考虑初始化对优化效果的影响。
-
研究进展:
-
预训练模型初始化:研究(如[143], [144])表明,从预训练LLM初始化可显著减少IID与non-IID数据差异,降低本地训练轮次而不牺牲精度。
-
数据分组:Dataset Grouper库支持大规模分组数据集生成,适用于联邦环境,具有内存超载管理和框架无关性。
-
合成数据生成:
-
GPT-FL:利用生成式预训练生成合成数据,提升下游模型性能,优于传统FL在准确性、通信和采样效率方面。
-
Wang等人:结合公共数据集和LLM,通过知识蒸馏和分布匹配优化DP训练,平衡隐私与效用。
-
-
-
意义:预训练初始化和合成数据弥补了公共数据不足,提升了联邦LLM的训练效率和稳定性。
C. 联邦LLM微调(Federated LLM Fine-tuning)
这一部分聚焦于联邦环境下的LLM微调,分为参数高效微调(PEFT)和下游应用微调两类。
1. 联邦LLM与PEFT(Federated LLM with PEFT)
-
背景:由于预训练成本高,微调成为联邦LLM研究重点,PEFT通过冻结主架构调整少量参数降低资源需求(图6)。
-
主要研究:
-
LP-FL:结合LoRA和少样本提示学习,客户端为无标签数据分配软标签,减少通信开销。
-
Malaviya等人:验证PEFT(如Adapter、LoRA)在FL中降低通信成本,同时保持零样本学习能力。
-
FedTune:分析三种微调策略(输入修改、模块添加、架构调整),提升Transformer在FL中的收敛速度和准确性。
-
FedPETuning:为四种PEFT方法建立联邦基准,评估隐私威胁和性能。
-
FedPrompt:通过模型分割聚合实现提示调优,抗后门攻击能力强。
-
PROMPTFL:转向联邦提示训练,仅更新提示而非整个模型,加速训练和聚合。
-
SplitLoRA:结合分裂学习和FL,利用服务器分担训练负载,提供开源基准。
-
2. 下游应用微调(Fine-tuning for Downstream Applications)
-
目标:将预训练LLM适配特定任务,解决隐私和数据敏感性问题。
-
主要研究:
-
Riedel等人:微调多语言BERT和DistilBERT用于抗议新闻检测。
-
FedTherapist:基于FL的移动心理健康监测,微调BERT和GPT-3.5。
-
FedJudge:法律LLM微调,使用LoRA和持续学习保护敏感数据。
-
FedED:医疗关系提取,利用知识蒸馏优化通信。
-
Ahmed等人:新闻检索,结合主动学习和BERT。
-
FedHumor:个性化幽默识别,适配用户偏好。
-
Efficient-FedRec:新闻推荐,分裂模型保护隐私。
-
FEWFEDWEIGHT:少样本学习,利用伪数据提升性能。
-
FedNLP:支持四种NLP任务的标准化平台。
-
-
分类表:表II总结了微调研究的分类、方法、模型、数据集和贡献。
D. 个性化联邦LLM(Personalized Federated LLM)
这一部分讨论如何应对FL中的异构性问题,提供个性化解决方案。
-
异构性定义:
-
统计(数据)异构性:non-IID数据导致模型发散。
-
系统异构性:硬件能力差异。
-
模型异构性:不同实体使用不同模型。
-
-
主要研究:
-
Fed-PepTAO:参数高效提示调优,结合自适应优化解决客户端漂移。
-
Profit:研究个性化与鲁棒性的权衡,分析优化器和参数选择。
-
FedDAT:多模态FL,使用双适配器和知识蒸馏。
-
FedRA:通过随机分配矩阵和LoRA适配低资源客户端。
-
FedLoRA:统一适配器应对多种异构性。
-
pFedPG:双阶段优化生成个性化提示。
-
Heterogeneous-LoRA:异构LoRA秩优化性能。
-
AdaFL:动态调整适配器配置。
-
PERADA:通过全局适配器对齐提升泛化。
-
FedBERT / FEDBFPT / FEDOBD:分裂学习或块分解降低成本。
-
FedPerfix:部分个性化,针对敏感层调整。
-
-
其他方法:如RaFFM(模型压缩)和Fed-ET(知识迁移)。
-
分类表:表III总结了个性化研究的异构性类型、方法和贡献。
E. 无反向传播方法(Back-propagation-free Methods)
这一部分探索避免传统反向传播的优化方法,以降低计算和内存需求。
-
背景:LLM训练成本高,无反向传播(BP-free)方法(如零阶优化)可减少高达12.5倍内存使用,但面临高维扩展性挑战。
-
主要研究:
-
FwdLLM:结合零阶优化和PEFT,支持标准移动设备训练。
-
ZOOPFL:评估LLM对FL性能的影响,建议压缩和蒸馏优化。
-
FEDBPT:使用黑箱调优生成提示,降低通信和存储成本。
-
FedKSeed:仅传输种子和标量梯度,实现全参数调优。
-
-
潜力:显著降低资源需求,增强鲁棒性和泛化能力。
F. 局限性与经验教训(Limitations and Lessons Learned)
-
局限性:
-
预训练研究较少,因计算和通信成本高。
-
当前多集中于微调和PEFT,缺乏大规模标准化基准。
-
-
经验教训:
-
基础设施(如FedLLM)和基准(如FedIT)至关重要。
-
PEFT和BP-free方法扩展了LLM的可访问性。
-
个性化方法(如Fed-PepTAO)有效应对异构性。
-
3.5 FL 和LLM 结合时在隐私和鲁棒性方面的最新研究进展
A. 联邦LLM隐私(Federated LLM Privacy)
这一部分讨论了联邦LLM系统中可能出现的隐私威胁,并根据攻击目标将其分类。
1. 训练数据恢复攻击(Training Data Recovery Attacks)
-
定义:这类攻击(也称重建攻击)旨在通过分析客户端与服务器间传输的梯度,恢复客户端的私有训练数据。
-
机制:基于联邦随机梯度下降(SGD),攻击者利用梯度推断原始数据。
-
研究实例:
-
TAG:针对Transformer模型,通过恢复率和ROUGE分数评估攻击效果,在GLUE基准上优于先前方法。
-
LAMP:结合语言模型先验和连续/离散优化,提取BERT和GPT-2中的私有文本。
-
FILM:首创从128句大批量数据恢复文本,通过词提取和束搜索实现。
-
DECEPTIONS:利用Transformer架构单独恢复词和位置嵌入,强调恶意服务器威胁。
-
FLAT-CHAT:基于梯度稀疏性,通过矩阵展平攻击,评估冻结梯度和DP-SGD防御。
-
-
特点:主要针对图像数据有效,但在LLM中的梯度泄露研究较少。
2. 成员推断攻击(Membership Inference Attacks, MIAs)
-
定义:旨在判断特定数据集是否用于模型训练,可分为被动(观察参数)和主动(干扰训练)两类。
-
机制:
-
阈值攻击:通过词嵌入相似性判断数据成员身份,适用于Word2Vec、FastText等。
-
影子模型技术:构建影子模型模拟目标模型,训练攻击模型区分成员与非成员。
-
-
研究实例:
-
Song等人研究词嵌入模型隐私风险。
-
Song和Shmatikov等人探索文本生成中的成员推断。
-
-
现状:针对普通语言模型研究较多,但联邦LLM相关工作稀少,需进一步研究。
3. 属性推断攻击(Property Inference Attacks)
-
定义:推断客户端或数据集的敏感属性(如个人信息),而非直接训练目标。
-
研究实例:
-
Staab等人利用社交媒体内容,结合GPT-4推断用户属性,Top-1准确率达84.6%。
-
-
特点:关注较少,但对LLM隐私构成潜在威胁。
B. 针对联邦LLM隐私攻击的防御方法(Defence Methods Against Federated LLM Privacy Attacks)
这一部分综述了主流隐私保护技术及其在联邦LLM中的应用。
1. 差分隐私(Differential Privacy, DP)
-

-
类型:
-
全局差分隐私(GDP):在聚合数据上加噪,平衡隐私与性能。
-
本地差分隐私(LDP):客户端本地加噪,提供更强隐私保障。
-
-
研究实例:
-
Basu等人([244]):评估DP对BERT等模型性能影响,分析隐私预算对效用的折衷。
-
Basu等人([245]):在金融文本分类中结合DP和FL,测试IID与non-IID场景。
-
DP-LoRA:结合LoRA和Gaussian噪声,实现隐私保护的分布式训练。
-
-
优势与局限:DP有效对抗多种攻击,但在复杂任务中可能影响性能,且未充分考虑客户端异构性。
2. 同态加密(Homomorphic Encryption, HE)
-
定义:允许在加密数据上计算,结果解密后与明文计算一致,数学形式为
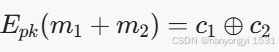
-
分类:部分同态(PHE)、有些同态(SHE)、完全同态(FHE)。
-
应用:增强FL中LLM的推理阶段安全性。
-
局限:计算和内存开销大,需权衡性能与安全。
3. 安全多方计算(Secure Multi-Party Computation, SMPC)
-
定义:允许多方在不泄露各自数据下联合计算,基于机制如混淆电路(GC)、无意识传输(OT)和秘密共享(SS)。
-
特点:隐私和准确性高,但计算和通信成本高,需同步协调。
-
改进:结合DP缓解数据泄露风险。
-
挑战:在典型FL架构下实用性有限。
C. 联邦LLM鲁棒性(Federated LLM Robustness)
这一部分分析了影响联邦LLM输出准确性的攻击及其防御方法。
1. 拜占庭攻击及其防御(Byzantine Attacks and Defences)
-
定义:恶意客户端发送伪造梯度,破坏全局模型完整性,分为无目标和有目标攻击。
-
在分布式系统中,“拜占庭”指的是系统中某些节点(参与者)可能出现任意形式的故障或恶意行为,而不是简单地停止工作(即崩溃故障)。
-

-
防御策略:
-
鲁棒聚合:如Krum和Bulyan,选择与多数更新几何接近的更新,但在高比例受损或non-IID数据下效果下降。
-
拜占庭检测:识别并剔除恶意更新,鲁棒性更强但资源需求高。
-
-
现状:联邦LLM场景下研究不足,仍是开放问题。
2. 投毒攻击及其防御(Poisoning Attacks and Defences)
-
定义:分为数据投毒(收集阶段)和模型投毒(训练阶段),包括后门攻击。
-
特点:LLM易受互联网数据投毒影响,如少量(0.01%-0.1%)污染即可误导模型。
-
研究实例:
-
FedMLSecurity:评估拜占庭和标签翻转攻击,支持多种模型。
-
Li等人([286], [287]):提出Fed-EBD,利用合成公共数据集植入后门,难以检测。
-
Wu等人:设计新型后门攻击。
-
Zhou等人:通过特征距离调整预训练模型抗投毒。
-
Huang等人:基于模型切片和可信执行环境(TEE)保护。
-
-
挑战:联邦LLM的复杂性增加新威胁,防御研究不足。
3. 提示攻击及其防御Prompt Attacks and Defences)
-
定义:通过操控输入提示改变LLM输出,如提示注入绕过安全限制。
-
实例:通过对抗扰动或指令忽略影响GPT输出。
-
防御:预处理提示、改写、重新标记化和指令隔离等,但主要针对LLM而非FL过程。
-
现状:与FL整合影响较小,未深入探讨。
D. 局限性与经验教训(Limitations and Lessons Learned)
-
局限性:
-
当前研究多针对单一攻击,未全面评估联邦LLM的复杂威胁。
-
防御方法(如DP、HE)在性能与隐私间存在权衡,未完全适配异构环境。
-
-
经验教训:
-
自适应防御:需动态应对新兴威胁,结合实时数据检测。
-
多学科方法:整合密码学、ML和网络安全提升系统安全性。
-
透明性:可解释AI(XAI)增强模型理解和信任。
-
隐私与效用平衡:需创新方法优化两者关系。
-
3.6 FL和LLM结合的未来方向
联邦LLM的效率(Efficiency of Federated LLM)
-
挑战:LLM参数量巨大,导致训练和部署在资源受限客户端上成本高昂。
-
现有进展:如第四章所述,参数高效微调(PEFT,如LoRA)和无反向传播方法已降低部分开销。
-
未来方向:
-
模型结构优化:
-
引入更高效的注意力机制(如[303], [304])或动态神经网络(如Mixture-of-Experts, MoE [307]),减少计算和内存需求。
-
-
模型压缩技术:
-
应用剪枝(pruning [308], [309])、量化(quantization [310], [311])和知识蒸馏([181], [182]),在不显著牺牲性能下缩小模型规模。
-
-
基础设施改进:
-
利用并行计算([312])、键值缓存(KV cache [313])和新型边缘计算硬件提升计算效率。
-
-
-
研究空白:这些方法多针对独立LLM,结合FL的效果和优化方法尚未充分探索。
2. 联邦LLM的异构性(Heterogeneity of Federated LLM)
-
挑战:大规模联邦场景中,数据分布、模型结构、通信网络和设备能力差异显著,影响协作效果。
-
分类:
-
数据异构性:客户端数据非独立同分布(non-IID),本地优化目标与全局目标不一致。
-
通信异构性:网络条件差异。
-
设备异构性:计算能力和硬件限制。
-
模型异构性:不同客户端使用不同模型。
-
-
现有进展:第四章中PEFT方法(如FedRA)适配设备异构性,但其他异构性研究较少。
-
未来方向:
-
深入研究数据异构性的双重影响:可能导致本地模型偏离全局最优,但数据多样性也可能提升泛化能力。
-
开发针对通信和模型异构性的新算法,确保训练一致性和效率。
-
-
意义:数据异构性对联邦LLM影响更大,需进一步量化其作用并设计应对策略。
3. 联邦LLM的隐私(Privacy of Federated LLM)
-
挑战:隐私保护是核心需求,但现有方法在复杂任务和异构环境下的适用性有限。
-
现有进展:
-
第五章提到的差分隐私(DP)提供通用保护,但对复杂任务性能影响较大。
-
同态加密(HE)和安全多方计算(SMPC)用于推理阶段,但通信和计算成本高。
-
-
未来方向:
-
全面评估:分析现有隐私方法在联邦LLM全生命周期(预训练、微调、推理)的效果。
-
适应性设计:开发考虑客户端异构资源(如低算力设备)的隐私算法。
-
成本优化:降低HE和SMPC的资源需求,提升实用性。
-
-
研究空白:缺乏适用于联邦LLM的鲁棒隐私算法,需进一步验证可行性。
4. 联邦LLM的鲁棒性(Robustness of Federated LLM)
-
挑战:联邦LLM系统规模复杂,易受拜占庭攻击、投毒攻击等威胁。
-
现有进展:第五章讨论了少量针对后门攻击等的防御,但整体研究不足。
-
未来方向:
-
全面脆弱性评估:研究拜占庭、投毒及潜在新攻击对联邦LLM的影响。
-
防御机制评估:验证鲁棒聚合和检测方法对新兴威胁的有效性。
-
创新防御:设计针对联邦LLM特定复杂性的新策略。
-
-
意义:随着系统规模扩大,攻击机会增加,需持续创新确保鲁棒性。
其他值得探索的机会
除了解决上述挑战,文章还提出了以下新兴研究方向:
1. 多模态模型整合(Multimodal Models Integration)
-
背景:除LLM外,多模态模型(如GPT-4o、Vision Transformers、CLIP)同样需要大量数据和计算资源,适合FL。
-
挑战:不同模态数据(文本、图像、音频)的分布、维度和质量差异影响训练效率。
-
方向:研究数据对齐、增强和选择策略,扩展联邦LLM研究至更广泛的基础模型。
2. 联邦领域特定AI代理(Federated Domain-specific AI Agents)
-
背景:领域特定LLM代理(如医疗、金融)需处理敏感分布式数据,FL可保护隐私。
-
方向:开发联邦训练的领域AI代理,提供定制化服务。
3. 联邦LLM的持续学习(Continual Learning for Federated LLM)
-
背景:现实世界数据分布随时间变化,需持续更新LLM知识,避免灾难性遗忘。
-
方向:结合持续学习方法(如[319]),研究联邦LLM如何适应数据漂移。
4. 合法、负责且盈利的使用(Legal, Responsible, and Profitable Usage)
-
挑战:联邦LLM涉及多方数据和知识产权(IP)争议,如纽约时报诉OpenAI案。
-
方向:
-
技术上:开发水印等IP保护方法。
-
多学科:结合法律、伦理和社会科学,确保合法性。
-
商业模式:设计盈利策略(如医疗、金融应用),推动广泛采用。
-
5. 联邦LLM的数据擦除(Data Erasure for Federated LLMs)
-
背景:GDPR等法规要求“被遗忘权”,LLM需移除特定数据。
-
挑战:FL中数据分散,集中式擦除不适用。
-
方向:开发分布式机器遗忘方法,确保隐私合规性。
四、FederatedScope-LLM: A Comprehensive Package for Fine-tuning Large Language Models in Federated Learning
这篇文章的主要介绍了一个名为FederatedScope-LLM(FS-LLM)的开源软件包,旨在解决在联邦学习(Federated Learning, FL)框架下微调大型语言模型(Large Language Models, LLMs)的挑战,并推动相关研究和应用。
4.1引言
1、微调LLMs面临两大主要障碍:
-
计算资源需求高:微调需要大量计算资源,特别是在资源有限的环境中难以实现。
-
数据隐私问题:领域数据的共享受限于隐私法规,多个实体无法直接集中数据进行训练。
2、解决方案:
-
参数高效微调(PEFT):针对计算资源问题,近年来的研究(如LoRA、prefix-tuning等)通过调整少量参数(如适配器模块)来适配预训练模型,显著降低资源需求。
-
联邦学习(FL):针对数据隐私问题,FL允许多个实体在不共享原始数据的情况下协作优化模型,成为可行的解决方案。
3、现有FL框架的不足
尽管现有FL框架(如Bonawitz et al., 2019; Ryffel et al., 2018)支持多种机器学习模型,但在联邦环境下微调LLMs仍处于初级阶段,存在以下差距:
-
缺乏全面支持:现有FL框架缺少针对LLM微调的标准化基准和高效算法实现,无法有效比较模型性能、通信成本和计算开销。
-
计算成本仍高:即使使用PEFT算法,客户端的计算开销仍然较大。
-
模型访问限制:由于LLMs的知识产权价值,客户端可能无法访问完整模型(如闭源LLMs),现有框架难以应对这一需求。
-
高级FL问题的适用性未知:如个性化联邦学习(pFL)和联邦超参数优化(FedHPO)等高级算法是否适用于LLM微调尚不清楚。
4、本文贡献
文章提出了FederatedScope-LLM(FS-LLM)软件包,并详细介绍了其主要组件和功能:
-
端到端基准测试管道:
-
FS-LLM提供了一个完整的管道,自动化了数据预处理、联邦微调执行或模拟、以及性能评估的过程。
-
这一管道支持展示联邦微调LLMs在不同能力上的表现,便于基准测试。
-
-
参数高效微调(PEFT)算法与扩展接口:
-
软件包集成了全面且现成的联邦参数高效微调(Parameter-Efficient Fine-Tuning, PEFT)算法实现。
-
这些算法能在低通信和计算成本下提升LLMs在FL场景中的能力,甚至支持不访问完整模型的情况(如闭源LLMs)。
-
提供灵活的编程接口,便于未来扩展。
-
-
加速与资源高效运算:
-
FS-LLM采用了多种加速运算符和资源高效运算符,适用于资源有限的场景。
-
提供灵活的插件式子程序,支持跨学科研究(如个性化联邦学习)。
-
4.2 FederatedScope-LLM(FS-LLM)的总体架构概览
文章强调FS-LLM是基于FederatedScope(FS,一个易用的FL平台,Xie et al., 2023)构建的,FS提供了基本的FL功能(如通信模块、聚合策略和训练接口)。在此基础上,FS-LLM新增了三个关键模块以应对LLM微调的特殊需求,填补第一章提到的差距:
- LLM-BENCHMARKS:用于端到端基准测试。
- LLM-ALGZOO:提供微调算法集合。
- LLM-TRAINER:优化训练过程。
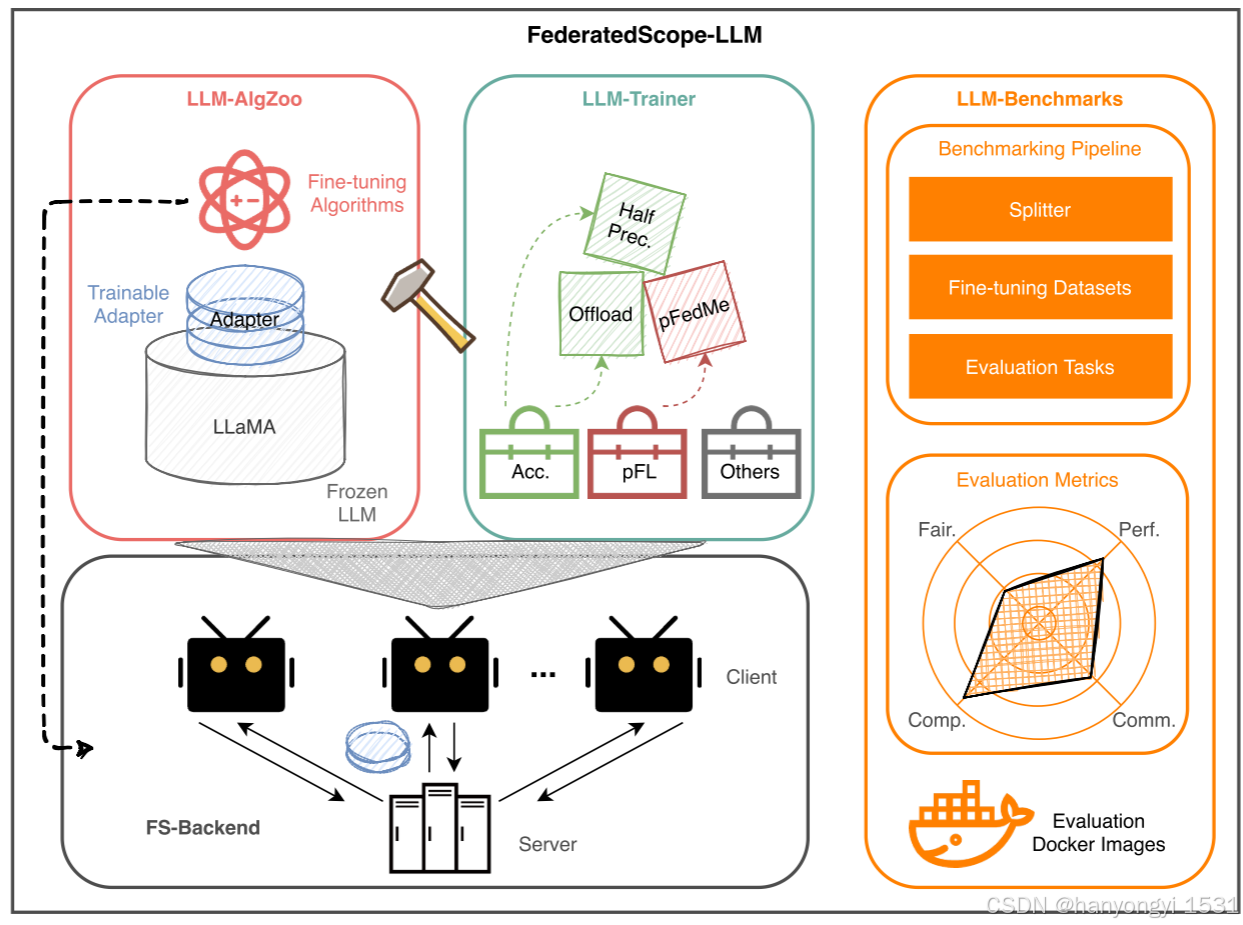
1. FS-LLM架构的核心组件
架构示例
文章通过上图展示了一个具体应用场景:使用参数高效微调(PEFT)算法(如LoRA)在FL中微调LLaMA(Touvron et al., 2023)。在这个例子中:
-
采用半精度训练(Micikevicius et al., 2018)和卸载策略(Ren et al., 2021)以降低资源需求。
-
使用pFedMe算法(T Dinh et al., 2020)进行个性化联邦学习。
-
客户端仅传输适配器(adapter,参数量极少),实现高效的通信和计算。
图中的术语(如Acc.表示加速操作、Comm.表示通信、Comp.表示计算、Fair.表示公平性)进一步说明了FS-LLM关注的多方面优化目标。
三大模块简介
FS-LLM的三个核心模块在架构中分工明确:
-
LLM-BENCHMARKS:
-
提供端到端的基准测试流程,包括数据预处理、微调执行和性能评估。
-
整合了多种语料数据集,覆盖不同领域(如代码生成、通用语言能力等),并根据元信息分割为联邦版本。
-
提供数据分割工具(Splitter)和预配置的Docker镜像,便于用户比较不同微调算法的效果。
-
-
LLM-ALGZOO:
-
包含一系列专为FL定制的微调算法(如LoRA、prefix-tuning等PEFT算法)。
-
这些算法针对FL中通信和计算资源有限的特点进行优化。
-
支持未来扩展的统一编程接口。
-
- LLM-TRAINER:
- 提供加速和资源高效的操作(如DeepSpeed的ZeRO、数据并行、模型量化)。
- 通过灵活的插件式子程序支持跨学科研究(如个性化FL和超参数优化)
2. 模块功能的具体作用
(1) LLM-BENCHMARKS:基准测试支持
-
数据集准备:从不同领域收集语料(如代码、数学、自然语言),并根据元信息(如编程语言、任务类型)分割为联邦数据集,模拟真实FL场景中的数据异构性。
-
评估任务:为每个数据集搭配特定评估任务,确保微调效果可量化。
-
扩展性:提供Splitter工具,用户可自定义数据集分割方式;Docker镜像则简化了环境配置。
(2)LLM-ALGZOO:算法支持
-
高效性:通过PEFT算法减少通信和计算开销。例如,客户端只需传输适配器而非整个模型。
-
灵活性:支持完整模型访问和非访问场景(如闭源LLMs),通过隐私保护算法(如offsite-tuning)满足知识产权需求。
(3) LLM-TRAINER:训练优化
-
资源优化:集成加速运算符(如半精度训练、多GPU并行)以适配资源受限的客户端。
-
跨学科支持:通过插件式设计,轻松集成高级FL功能(如pFL和FedHPO)。
4.3 LLM-BENCHMARKS
- 第三章开篇指出,第一章提到的差距之一是学术界和工业界缺乏对联邦微调LLM算法的公平评估标准和基准。因此,FS-LLM引入了LLM-BENCHMARKS,旨在提供一个方便且公正的模块,涵盖从数据集构建到性能评估的完整流程。具体目标包括:
- 解决如何公平比较联邦微调算法的问题;
- 提供标准化的数据集和评估任务;
- 确保实验的可复制性和一致性。
该模块包括数据准备、微调执行和结果评估的全流程,并通过预置的查找表和容器化环境(如Docker镜像)支持用户验证和比较。
4.3.1 联邦微调数据集构建
背景与挑战
-
微调LLMs通常是为了适配特定领域(如代码生成、数学推理),这些领域差异显著。
-
在FL中,客户端的本地数据集可能存在不同程度的异构性(heterogeneity),即使在同一领域内。例如,同样是代码生成任务,某些客户端可能主要拥有Java代码,而其他客户端则以Python为主。
数据集设计
为了反映真实FL场景中的多样性和异构性,LLM-BENCHMARKS提供了三个精心设计的联邦微调数据集:
-
Fed-CodeAlpaca:
-
来源:CodeAlpaca(Chaudhary, 2023)。
-
目标:增强LLMs的代码生成能力。
-
设计:模拟9个客户端的FL场景,每个客户端的数据集限定为一种编程语言(如Java、Python)的编码练习和答案,体现高度异构性。
-
-
Fed-Dolly:
-
来源:Databricks-dolly-15k(Conover et al., 2023)。
-
目标:提升LLMs的通用语言能力。
-
设计:将数据集分为8个客户端,每个客户端专注于一种NLP任务(如信息提取、问答),数据异构性较高。
-
-
Fed-GSM8K-3:
-
来源:GSM8K(Cobbe et al., 2021)的训练集。
-
目标:增强LLMs的思维链(Chain of Thought, CoT)能力。
-
设计:将数学问题随机分为3个子集,分配给3个客户端,数据分布独立同分布(i.i.d.),异构性较低。
-
扩展性
4.3.2联邦LLM微调评估
-
除了内置数据集,FS-LLM提供Splitter工具,允许用户根据元信息(如语言、任务类型)或异构性程度(如均匀分割、Dirichlet分割)自定义分割集中式数据集。
-
示例数据集包括Alpaca(Taori et al., 2023)和CleanedAlpaca(Ruebsamen, 2023),具体细节见附录A.1。
评估的复杂性
-
LLMs能力强大,但单一指标难以全面评估其性能。
-
目前缺乏现成的工具来评估联邦微调LLMs的效果,尤其是在个性化FL场景下。
评估目标与设计
文章提出,微调应关注两类能力提升:
-
通用语言能力;
-
特定领域能力。
为此,LLM-BENCHMARKS设计了三个评估数据集和任务,与前述微调数据集对应(见表1):
-
HumanEval(Chen et al., 2021):
-
领域:代码生成。
-
指标:Pass@1分数,衡量代码正确性。
-
与Fed-CodeAlpaca搭配,测试异构数据下代码生成能力的提升。
-
- HELM(Liang et al., 2022):
- 领域:通用语言能力。
- 指标:16个子任务的混合分数(另有简版HELM-MINI含4个子任务)。
- 与Fed-Dolly搭配,评估异构数据下语言能力的提升。
- GSM8K-test(Cobbe et al., 2021):
- 领域:思维链(CoT)。
- 指标:准确率。
- 与Fed-GSM8K-3搭配,测试同分布数据下CoT能力的提升。
评估分数定义
- 为统一不同数据集的评估结果,引入“评估分数”(evaluation score)概念:
- HumanEval:Pass@1;
- HELM:16个子任务的分数混合;
- GSM8K-test:准确率。
- 微调和评估数据集之间通常存在分布偏移(distribution shift),增加了评估难度。
一致性与效率
- 为确保结果一致性,评估任务的运行环境被容器化为Docker镜像。
- 提供成本相关指标(如GPU使用率、通信消息大小),全面评估微调过程的效率。
4.4.1降低通信与计算成本的PEFT算法
挑战
-
通信瓶颈:在FL中,客户端和服务器之间的带宽有限,全参数微调需要传输大量参数。例如,微调LLaMA-7B模型每次通信需传输28GB数据,假设带宽为100MBps,仅上传下载就需75分钟,对带宽受限的客户端不可接受。
-
计算瓶颈:全参数微调需要大量GPU内存。例如,LLaMA-7B需要28GB存储模型,加上优化器和梯度需额外92GB,总计约112GB,超出大多数资源受限实体的能力。
解决方案:PEFT算法
FS-LLM集成了以下参数高效微调(Parameter-Efficient Fine-Tuning, PEFT)算法:
-
LoRA(Hu et al., 2022):通过低秩矩阵适配器调整模型层,参数量极少。
-
Prefix-tuning(Li & Liang, 2021):在输入中添加可训练的前缀,仅调整这些参数。
-
P-tuning(Liu et al., 2021b):通过插入可学习标记优化输入。
-
Prompt tuning(Lester et al., 2021):使用少量可训练提示调整模型。
优势
-
通信效率:客户端只需传输适配器(参数量远小于全模型),将传输时间缩短至几十秒甚至几秒。
-
计算效率:冻结大部分参数,仅训练适配器,显著降低GPU内存需求。例如,LLaMA-7B的适配器微调大幅减少内存占用,使其适用于资源受限的客户端。
适用性
这些PEFT算法使联邦微调在资源受限环境中变得可行,解决了通信和计算效率问题。
4.4.2无需完整模型访问的联邦微调
背景与需求
-
许多LLMs(如OpenAI的GPT系列、Anthropic的Claude)因高训练成本、数据隐私和商业机密等原因闭源。
-
下游客户希望基于私有领域数据定制这些模型,但无法通过API完全满足需求,且数据隐私限制了集中式微调。
解决方案:FedOT
FS-LLM改进了隐私保护微调算法offsite-tuning(Xiao et al., 2023),并将其适配为联邦版本(称为FedOT):
-
机制:在FL开始时,服务器向客户端发送一个压缩的、不可训练的模型(模拟器,emulator),客户端基于此模拟器和本地数据微调适配器。
-
优势:
-
保护模型知识产权:客户端无法访问完整LLM。
-
保护数据隐私:本地数据不需共享。
-
利用分布式数据适配领域需求。
-
与PEFT结合
FedOT可进一步与4.1节的PEFT算法集成,进一步优化效率。
4.4.3 统一的扩展接口
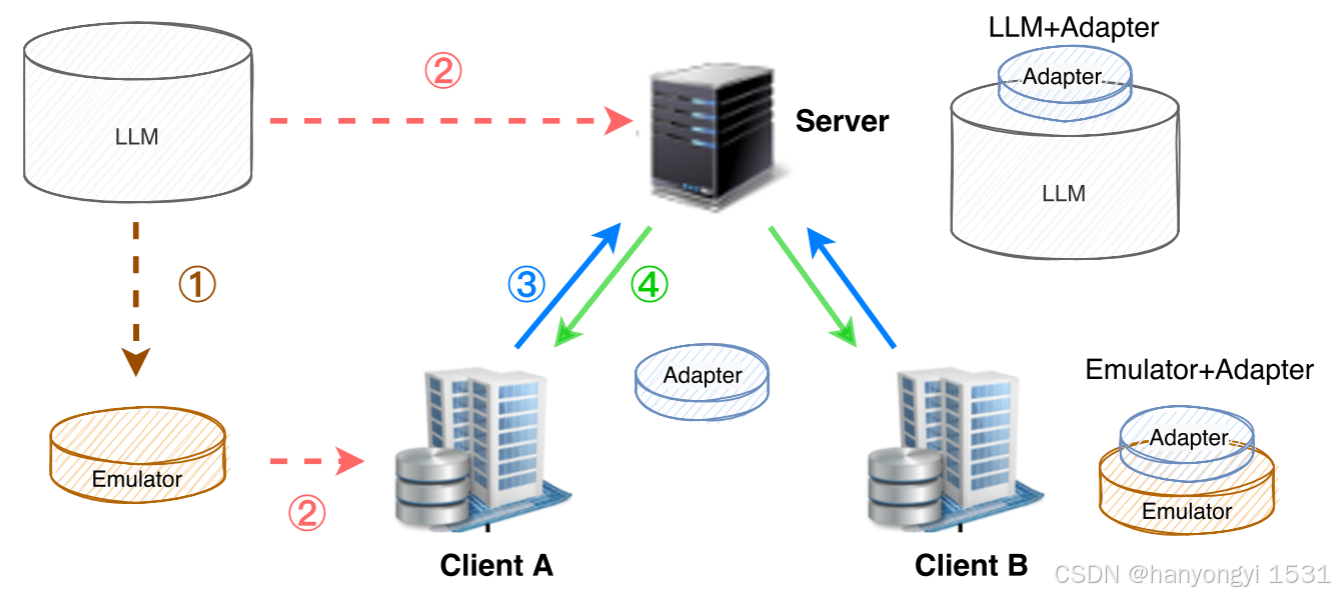
图2展示了几个关键接口:
- 模型预处理接口(箭头①):
- 闭源LLM:通过蒸馏、剪枝或量化生成模拟器。
- 开源LLM:直接输出原始模型。
- 初始模型广播接口(箭头②):服务器将模型或模拟器分发给客户端。
- 共享参数聚合接口(箭头③):客户端上传适配器参数,服务器聚合。
- 参数重新分发接口(箭头④):服务器将更新后的参数广播回客户端。
4.5 LLM-TRAINER
(1)第五章开篇指出,尽管参数高效微调(PEFT)算法(如第四章所述)显著降低了计算成本,但对于资源受限的客户端而言,训练仍可能过于昂贵。因此,LLM-TRAINER模块旨在:
- 进一步加速本地训练和消息传输阶段的计算效率;
- 节省资源以适配不同硬件条件;
- 支持高级FL任务(如个性化FL和超参数优化)的扩展。
该模块通过一系列加速运算符、资源高效运算符和灵活的训练范式,解决第一章中提到的差距(ii)和(iv)。
(2). 训练运算符:加速与效率(5.1 Training Operators for Acceleration and Efficiency)
背景
即使采用PEFT,客户端的计算资源(如GPU内存)和通信带宽仍可能不足。LLM-TRAINER通过多种运算符优化训练过程,分为以下三类:
通用运算符(Mode-generic Operators)
-
适用场景:适用于所有FL模式(模拟、分布式、集群)。
-
实现:
-
混合精度训练:减少GPU内存占用(如Micikevicius et al., 2018的半精度训练)。
-
梯度累积:分批计算梯度,降低单次计算的资源需求。
-
PyTorch数据并行(Paszke et al., 2019):支持多GPU并行加速本地微调。
-
模式特定运算符(Mode-specific Operators)
-
目标:针对不同FL模式的瓶颈进行优化。
-
实现:
-
模拟模式(单机多客户端):
-
问题:多个客户端共享一台机器,独立模型实例占用大量内存。
-
解决方案:轮询切换运算符(round-robin switching operator),客户端轮流使用冻结的全模型微调适配器,内存增量仅为适配器大小。
-
-
分布式与集群模式(多机):
-
问题:通信开销高。
-
解决方案:通信高效运算符,包括:
-
量化运算符:将参数位宽降至16或8位。
-
流式运算符:序列化参数避免类型转换开销。
-
压缩运算符:使用DEFLATE(Deutsch, 1996a)或Gzip(Deutsch, 1996b)压缩消息。
-
-
效果:通信速度提升1-2个数量级。
-
-
并行运算符(Parallelization Operators)
-
实现:集成DeepSpeed(Rasley et al., 2020)的功能(见图3),包括:
-
多GPU数据并行:优化内存使用。
-
CPU卸载(Ren et al., 2021):将部分计算移至CPU。
-
-
优化细节:
-
主进程(Rank 0)负责日志和保存,非主进程禁用冲突模块(如日志、WandB)。
-
分布式和集群模式下,各子进程独立通信,仅在本地微调时同步,确保一致性。
-
作用
这些运算符优化了CPU/GPU内存消耗、多GPU并行和通信成本,使FS-LLM能在不同硬件条件下高效运行。
(3). 训练范式:支持高级FL任务的扩展性(5.2 Training Paradigm for Extendability towards Advanced FL Tasks)
设计理念
LLM-TRAINER采用钩子式(hook-like)函数设计,支持灵活扩展和与现有训练范式的无缝集成。一个典型的微调过程包括:
-
数据准备与批处理;
-
迭代更新模型参数;
-
验证数据集上的性能评估。
通过在这些步骤中插入钩子函数,LLM-TRAINER支持高级FL任务的定制。
个性化联邦学习(pFL)适配
-
背景:pFL(如Tan et al., 2022)旨在为每个客户端定制模型,但资源限制(如内存)使同时维护全局和本地模型不现实。
-
优化:
-
仅使用全局和本地适配器,避免完整模型的重复存储。
-
通过添加pFL钩子函数,兼容PEFT算法与pFL算法(如pFedMe,T Dinh et al., 2020)。
-
-
优势:增强了个性化微调的扩展性。
联邦超参数优化(FedHPO)适配
-
背景:FedHPO(如Wang et al., 2023)优化超参数以提升性能。
-
实现:支持多种HPO方法:
-
无模型方法:随机搜索(Bergstra & Bengio, 2012)、网格搜索。
-
基于模型方法:贝叶斯优化(Shahriari et al., 2015)。
-
多保真方法:连续折半算法(Jamieson & Talwalkar, 2016)。
-
FedHPO方法:FTS(Dai et al., 2020)、FLoRA(Zhou et al., 2021)。
-
-
扩展性:通过钩子函数快速集成这些方法。
支持多种模式
-
模拟模式:单机模拟FL,适合实验。
-
分布式模式:每客户端一台机器,真实分布式训练
-
集群模式:每集群一个客户端,支持大规模部署。
-
这些模式共享一致的编程范式,确保行为一致。
未来潜力
这种扩展性设计为LLMs与FL的跨学科研究(如pFL和FedHPO)提供了丰富的可能性,详见第7章讨论。
4.6 实验
实验围绕以下研究问题展开:
- PEFT算法的有效性与效率:联邦微调LLMs使用PEFT算法的效果和资源消耗如何?
- 无需完整模型访问的微调效果:在无法访问完整模型的情况下,联邦微调的效果如何?
- 跨学科能力洞察:FS-LLM在解决个性化FL(pFL)和联邦超参数优化(FedHPO)问题时能提供哪些见解?
中间:略
第六章通过实验验证了FS-LLM在效率、隐私保护和高级FL任务支持上的能力,同时揭示了挑战(如pFL精度损失、FedHPO敏感性),为第7章的未来方向提供了依据。
4.7联邦微调大型语言模型(LLMs)的未来研究方向
4.7.1研究的局限性
文章坦诚地讨论了当前研究的局限性,为后续改进提供了背景:
- 批大小限制:
- 由于资源限制,所有实验使用批大小为1。然而,更大的批大小可能提升性能,但未能在本次研究中验证。
- 提示设计的影响:
- 微调和评估中的提示(prompt)设计会影响结果。为确保公平比较,实验采用了固定提示,但不同提示的探索可能揭示更多潜力。
这些局限性表明,当前结果可能未完全反映FS-LLM的全部能力,未来需扩展实验条件。
4,7.2未来研究方向
基于实验观察和分析(尤其是第六章的结果),文章提出了以下五个具有前景的未来研究方向:
设计计算高效的微调算法
-
问题:即使使用PEFT算法,计算成本对资源受限客户端仍过高。
-
目标:开发更高效的算法,降低计算需求,使更多数据持有者能参与联邦微调,扩大受益范围。
-
意义:降低参与门槛,推动FL在实际场景中的普及。
探索无需完整模型访问的隐私保护算法
-
问题:FedOT显示出压缩率与性能之间的权衡,高压缩率损害模型能力。
-
目标:改进压缩技术,在保护LLM敏感信息(如预训练数据和完整模型)的同时维持性能,避免恶意利用或商业损失。
-
意义:增强模型隐私保护,适用于闭源LLM的商业场景。
优化pFL算法与高效运算符的兼容性
-
问题:实验显示,低精度训练(如半精度)对pFL(如pFedMe)性能有负面影响,且加速运算符限制了超参数空间。
-
目标:优化pFL算法,使其与加速和资源高效运算符(如混合精度、DeepSpeed)无缝协作,提升异构数据下的个性化性能。
-
意义:提高pFL在资源受限环境中的实用性。
研究低保真FedHPO方法
-
问题:实验发现验证损失与泛化性能不一致,且超参数对性能影响敏感且不平滑。
-
目标:开发低成本、高效的FedHPO方法,找到最佳超参数,同时解决验证指标的可靠性问题。
-
意义:降低超参数优化的资源需求,提升联邦微调的泛化能力。
扩展到跨设备场景
-
问题:当前研究聚焦跨孤岛(cross-silo)场景,但跨设备(cross-device)场景(如移动设备)需求日益增加。
-
挑战:跨设备场景客户端数量多、异构性高、计算资源更有限、网络条件复杂。
-
目标:研究如何在跨设备场景下有效微调LLMs,解决上述挑战。
-
意义:拓宽联邦微调的应用范围,满足移动互联网时代的需求。
五、Securing federated learning with blockchain: a systematic
literature review
5.1 联邦学习的攻击
1.单点故障攻击(Single Point of Failure Attack, SPoF)
- 描述:传统联邦学习依赖中央服务器来聚合本地模型更新并维护全局模型。如果中央服务器发生故障或被攻破,会导致整个系统崩溃。
2.拒绝服务与分布式拒绝服务攻击(Denial of Service and Distributed Denial of Service Attack, DoS/DDoS)
- 描述:恶意参与者通过传播虚假模型更新,试图压垮系统资源,导致服务不可用。
- 具体形式:
- DoS:单一恶意设备持续发送伪造更新,耗尽系统资源。
- DDoS:被攻破的联邦学习服务器或多个恶意参与者协同攻击,瘫痪整个系统。
- 附加威胁:恶意服务器或参与者可能在全局模型中添加微弱噪声,替换为新模型,影响准确性但不易察觉。
- 影响:系统崩溃或性能显著下降。
3. 搭便车攻击(Free-riding Attack)
- 描述:由于机器学习训练需要消耗大量资源(如 CPU、网络带宽),一些不诚实的参与者可能不实际参与训练,而是发送虚假或低质量模型更新以获取奖励。
- 具体行为:
- 发送带有最小噪声的假更新。
- 直接上传未经训练的模型。
- 影响:导致公平性和可信度问题,难以区分搭便车者和真实数据贡献者。
- 文献支持:参考 Fraboni et al. (2021a)。
4. 毒化攻击(Poisoning Attacks)
- 描述:毒化攻击分为数据毒化(Data Poisoning)和模型毒化(Model Poisoning)两种。
- 具体形式:
- 数据毒化:恶意参与者修改训练数据(如翻转标签),生成虚假模型更新。
- 模型毒化:通过数据毒化进一步影响全局模型,或直接生成随机/逆向的模型更新。
- 随机毒化:使用随机梯度更新模型。
- 逆向毒化:将模型更新方向调整为相反。
- 影响:降低全局模型性能,导致不准确的结果。
- 文献支持:参考 Chen et al. (2018) 和 Li et al. (2021c)。
5. 中间人攻击(Man-in-the-Middle Attack, MitM)
- 描述:攻击者拦截联邦学习服务器与客户端之间的通信,伪装成合法一方以发送虚假更新或控制流量。
- 常见类型:
- 会话劫持(Session Hijacking):攻击者劫持客户端与服务器之间的合法会话。
- IP 欺骗(IP Spoofing):伪装成可信实体与服务器或客户端通信。
- 影响:破坏通信安全,篡改模型更新。
6. 窃听攻击(Eavesdropping Attacks)
- 描述:攻击者通过监听联邦学习服务器与参与者之间的通信,泄露敏感信息(如性别、职业、位置等)。
- 附加威胁:
- 删除、修改或拦截广播的模型更新。
- 可能升级为更严重的攻击,如干扰(Jamming)或 DoS。
- 影响:隐私泄露,可能引发进一步的网络攻击。
- 文献支持:参考 Wang et al. (2019a)。
5.2 基于区块链的联邦学习架构
1. 架构目标
- 主要目标:
- 保护数据隐私:避免数据拥有者的隐私泄露。
- 奖励参与者:根据贡献公平分配奖励。
- 防止恶意客户端:通过去中心化机制检测和排除恶意行为。
- 区块链的作用:作为一种完全去中心化和安全的架构,区块链消除了传统联邦学习对中央服务器的依赖,解决了单点故障(SPoF)等问题。
2. 架构组件
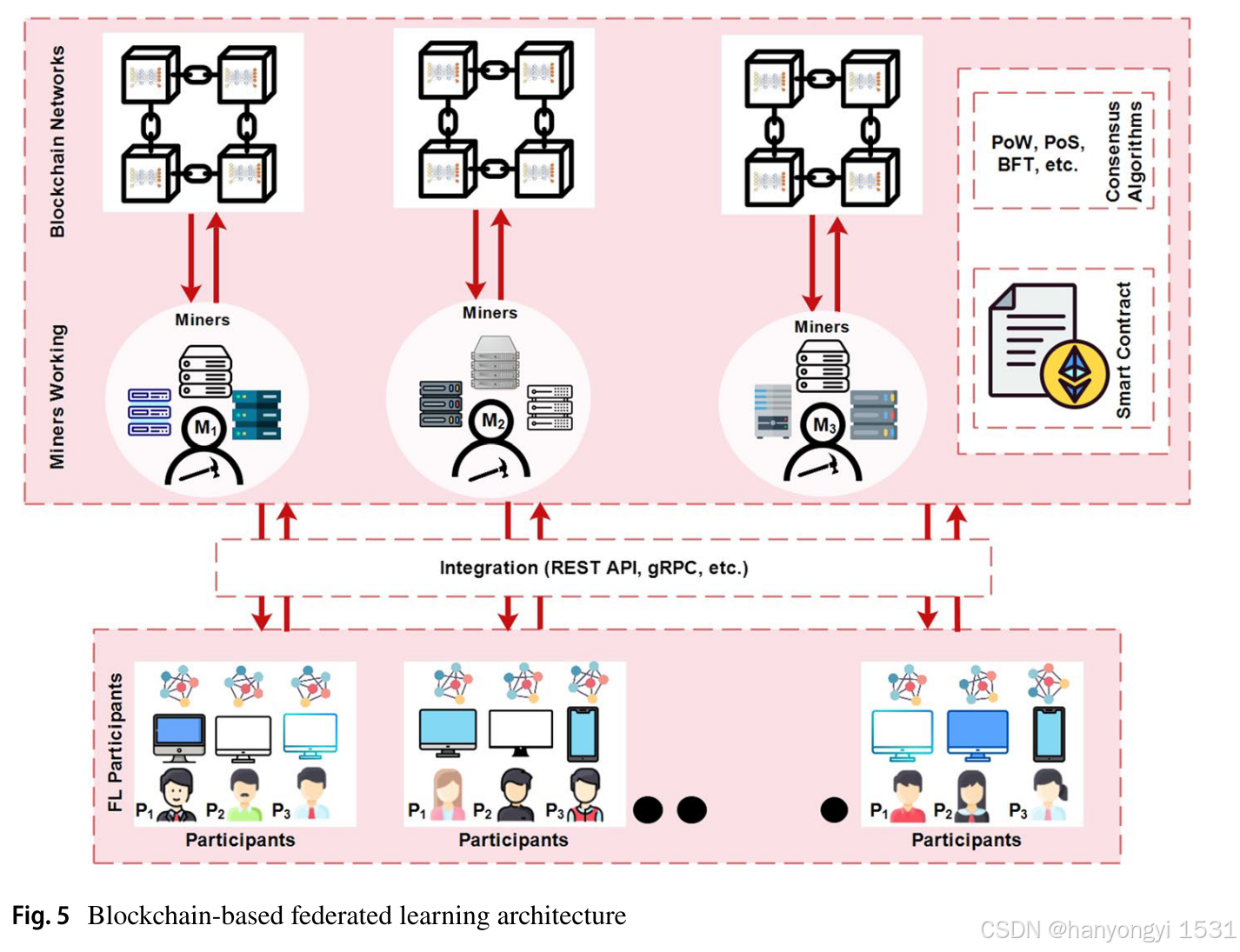
该节通过图5(Blockchain-based Federated Learning Architecture)展示了基于区块链的联邦学习架构,并详细描述了以下六个基本组件:
- 联邦学习参与者(Federated Learning Participants)
- 角色:与传统联邦学习中的客户端类似,参与者在本地训练模型并生成更新。
- 工作流程:
- 接收初始全局模型。
- 基于本地原始数据集生成模型更新。
- 将更新发送给矿工进行验证和聚合。
- 特点:直接与矿工通信,确保去中心化交互。
- 联邦学习与区块链的集成(FL Integration with Blockchain)
- 角色:作为中间件,连接联邦学习参与者和区块链网络。
- 实现方式:
- REST-API:例如,Martinez et al. (2019) 使用 REST-API 与 Hyperledger Fabric 区块链交互,记录和激励梯度上传。
- gRPC API:通过 Google 开发的远程过程调用(RPC),实现与 Ethereum 区块链的数据传输。
- 功能:提供参与者和区块链之间的无缝通信。
- 矿工工作(Miners Working)
- 角色:矿工是运行挖矿软件的节点(如个人电脑、备用服务器或云节点),负责接收、验证和聚合模型更新。
- 工作流程:
- 接收来自联邦学习参与者的本地模型更新。
- 根据共识算法执行聚合。
- 将聚合结果上传至区块链网络。
- 特点:确保持续通信,矿工的选择基于自愿参与。
- 智能合约(Smart Contract, SC)
- 角色:自动执行预定义逻辑的去中心化程序,协调联邦学习过程。
- 功能:
- 注册参与者:确保参与者符合训练条件。
- 协调训练:管理模型训练流程。
- 聚合更新:验证并聚合本地模型更新。
- 评估贡献:计算参与者的贡献度。
- 分配奖励:根据贡献发放奖励。
- 特点:透明且不可篡改,部署在参与者和矿工之间,无需可信第三方。
- 共识算法(Consensus Algorithm)
- 角色:区块链网络的核心,用于验证交易并达成一致。
- 工作流程:
- 矿工通过共识机制(如 Proof of Work (PoW)、Proof of Stake (PoS)、Byzantine Fault Tolerance (BFT))验证更新。
- 达成一致后,将新区块添加到区块链。
- 效果:增强联邦学习的灵活性,确保全局模型的安全性和一致性。
- 区块链网络(Blockchain Network)
- 角色:存储经过验证的区块,包含全局模型。
- 功能:
- 持续运行联邦学习过程,直到达到所需学习率。
- 允许参与者或其他客户端下载全局模型。
- 特点:去中心化存储,确保模型更新记录的永久性和安全性。
3. 实例与应用
- 文献支持:本节引用了多项研究,展示了区块链在联邦学习中的实际应用:
- Kang et al. (2020b):通过信誉度量选择可信参与者,防御恶意更新。
- Lo et al. (2022):提出基于区块链的可信联邦学习架构,引入智能合约实现责任追踪。
- Toyoda et al. (2020):使用区块链设计奖励机制,基于竞赛理论评估参与者贡献,解决 SPoF 问题并确保工人选择的可靠性。
- 具体实现:
- 参与条件、奖励金额和获奖人数通过智能合约明确定义。
- 去中心化特性提高了系统的鲁棒性和公平性。
4. 核心优势
- 去中心化:消除对中央服务器的依赖,避免单点故障。
- 安全性与隐私:通过共识算法和智能合约验证更新,防止恶意行为。
- 激励机制:通过奖励吸引更多参与者,提升模型训练的参与度。
- 透明性与可追溯性:区块链记录所有交易,确保过程可审计。
六、Advances and Open Challenges in Federated Foundation Models
6.1引言
研究背景与意义:基础模型(Foundation Models, FMs)与联邦学习(Federated Learning, FL)的结合代表了人工智能(AI)领域的一种变革性范式。这种结合在提升模型能力的同时,解决了隐私保护、数据去中心化和计算效率等问题。FedFM 的出现旨在利用 FL 的分布式特性,应对传统 FMs 在集中式训练中面临的挑战,如高昂的计算成本和数据隐私问题。
研究目标:本文旨在全面调研 FedFM 领域,阐明 FL 与 FMs 的协同关系,探讨新的方法论、现有挑战以及未来发展方向,为 FL 研究在基础模型时代蓬勃发展提供指导。
主要内容:
- 提出了一种系统性的多层次分类法(multi-tiered taxonomy),对现有的 FedFM 方法(如模型训练和生产)进行了分类。
- 深入讨论了 FedFM 面临的关键挑战,包括如何应对高复杂度的计算需求、隐私考虑、贡献评估和通信效率。
- 探索了在通过 FL 训练或微调 FMs 时涉及的通信、可扩展性和安全性等复杂问题。
- 强调了量子计算在优化 FedFM 的训练、推理和安全性方面的潜力。
6.2背景
1、Foundation Models(基础模型)
指的是一种可以作为多种任务特定模型基础的预训练模型。这些模型在训练期间保持架构稳定,并在适应阶段保持参数一致性。
发展驱动力与挑战:
- 高昂的训练成本:从头训练大规模模型需要大量计算资源和数据。FMs 通过预训练减少了每次新任务的资源需求。例如,GPT-3 有 1750 亿参数,内存占用约 350 GB。
- 数据稀缺:许多 AI 任务缺乏足够的高质量标注数据。FMs 利用预训练知识适应小数据集任务。
- 可扩展性:传统模型难以处理多样化任务和大数据集,而 FMs 的架构具有更强的适应性。
- 知识迁移能力:FMs 通过迁移学习快速适应新任务。
- 效率与性能:FMs 在 NLP(如 GPT 系列)和计算机视觉(如 Stable Diffusion)中显著提升了效率和性能。
- 统一架构:FMs 提供适用于多任务的统一架构,简化开发流程。
2、Federated Learning(联邦学习)
发展驱动力:
- 数据隐私与安全:FL 确保敏感数据留在本地,仅共享模型更新,降低隐私风险。
- 分布式数据利用:FL 能有效利用分布在各地的宝贵数据,而无需集中化。
- 减少通信开销:传输模型更新比传输原始数据更高效。
- 可扩展性与协作:FL 支持多方协作,提升模型的通用性和可扩展性。
- 模型鲁棒性:通过多源数据训练,FL 模型更具鲁棒性和泛化能力。
6.3提出的 FedFM 分类法
1、高效联邦训练与聚合:FedFM 的基础
目标与挑战:
- 研究重点在于适应传统 FL 训练方法以高效处理 FMs 的规模和复杂性,减少计算和通信开销。
- 探讨如何有效聚合来自多个 FL 客户端的 FMs 参数更新,而不使通信网络不堪重负。
关键研究领域:
- FedFM 聚合:
- 传统方法:加权平均(如 FedAvg)因简单高效而被广泛采用。
- 新兴技术:如模型汤(model soups,通过平均不同超参数微调的模型权重提升性能)和混合专家模型(MoE)等,用于开发更复杂的聚合策略。
- 计算高效的 FedFM:
- 技术包括参数高效微调(PEFT)、提示调优(Prompt Tuning, PT)和指令调优(Instruction Tuning, IT),通过仅调整少量参数降低计算和存储需求。
- 通信高效的 FedFM:
- 方法包括模型剪枝(仅传输重要参数)和模型压缩(减少传输参数量),以应对 FMs 的大规模通信开销。
2、信任性:FedFM 完整性的关键支柱
研究如何确保 FedFM 系统对攻击的鲁棒性并保护参与者数据的隐私,维护学习过程的完整性。
关键研究领域:
- 鲁棒性:
- 讨论毒化攻击(包括无目标和有目标攻击)如何威胁模型完整性。
- 提出拜占庭鲁棒聚合规则(如几何异常检测、顶级性能选择)来对抗这些攻击,但其在 FedFM 复杂环境中的有效性仍需探索。
- 隐私保护:
- 分析隐私攻击(如成员推断和数据重构攻击)及其在 FedFM 中的新挑战。
- 防御策略包括差分隐私、置信度掩码和模型压缩,旨在平衡隐私与模型质量。
- 知识产权保护:
- 提出黑盒微调和水印技术来保护 FedFM 的所有权,防止未经授权使用,但其在分布式环境中的适用性需进一步研究。
3、激励机制:促进 FedFM 的参与、协作和适应性
- 激励机制旨在鼓励数据拥有者贡献本地数据和计算资源,需平衡参与激励与奖励分配的实用性。
- 常借助经济和博弈论设计公平的补偿机制。
关键研究领域:
- 参与者选择:
- 传统方法:基于合同理论、博弈论和拍卖机制优化资源和奖励。
- 新兴方法:模型中心方法,根据参与者模型特性(如任务特定训练适应性和垂直训练能力)选择参与者。
- 贡献评估:
- 挑战包括 Shapley 值方法因高延迟而不实用,以及 FMs 在组合问题上的局限性,难以直接评估贡献。
- 奖励分配:
- 目标是防止搭便车、激励参与并确保项目可持续性,需在奖励与成本间找到平衡。
6.4迈向高效 FedFM
1、FedFM 训练与聚合
传统 FL 流程(如 FedAvg)涉及服务器协调多个客户端协作训练深度学习模型,但 FMs 的庞大规模引入了新的复杂性。
该节提出了三个关键研究问题(在算法 1 中高亮显示):
- Q1:如何聚合 FMs 以提升性能? 当前聚合技术较少针对 FMs 的规模和复杂性设计。
- Q2:如何提高计算效率以支持客户端托管和更新 FMs? 客户端设备通常资源有限,FMs 的规模加剧了这一挑战。
- Q3:如何提升通信效率? FMs 的参数量大,导致通信开销显著增加。
研究维度:
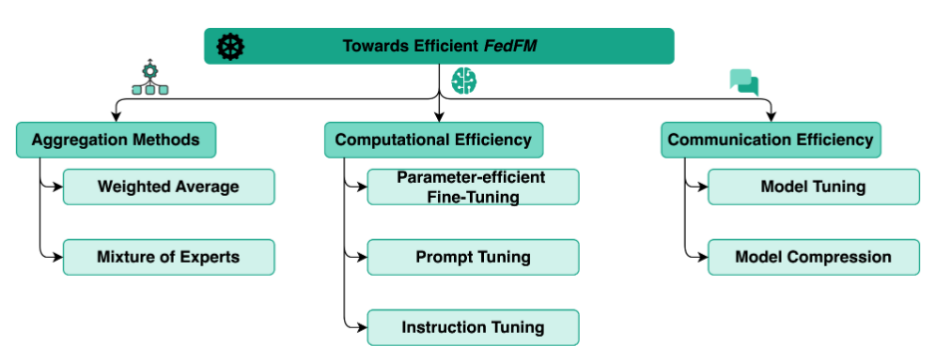
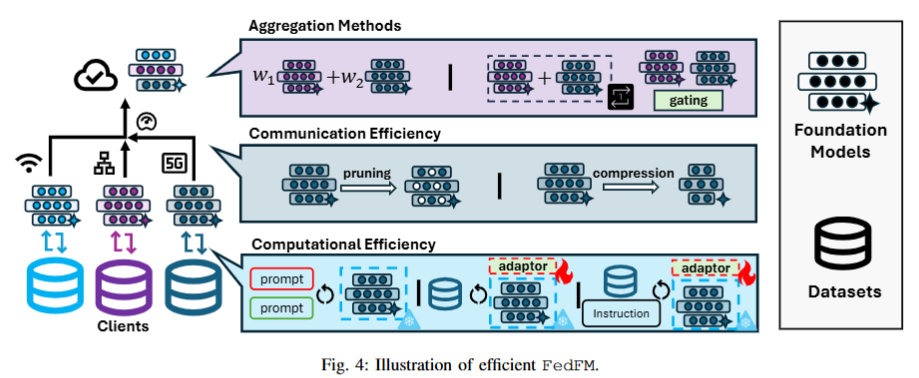
- 聚合方法:
- 传统方法:加权平均(如 FedAvg)是主流,但需探索更适合 FMs 的技术。
- 新兴技术:如模型汤(model soups)和混合专家模型(MoE),有望提升 FedFM 的性能和鲁棒性。
- 计算效率:
- 参数高效微调(PEFT):仅调整少量参数以适应特定任务。
- 提示调优(Prompt Tuning):通过文本提示优化性能,无需直接训练模型。
- 指令调优(Instruction Tuning):通过指令序列微调 FMs,替代传统输入-输出对。
- 通信效率:
- 模型剪枝(Model Pruning):仅传输关键参数,减少通信量。
- 模型压缩(Model Compression):减少传输的参数总数。
2、FedFM 的扩展努力
- 传统 FL 的局限:
- 传统 FL 模型参数通常少于 1000 万(如 FedAvg 测试的最大模型为 500 万参数的 LSTM),而 FMs(如 GPT-3)参数量达数十亿甚至万亿。
- 现有 FL 方法在规模上远不及集中式训练的 FMs,引发对其适用性的质疑。
- 当前进展与需求:
- 近年研究开始测试更大模型(如基于 Transformer 的模型),但仍远小于突破性 FMs。
- 需要新的技术和实验设计来验证 FL 方法在 FedFM 中的可行性,依赖于支持 FMs 的框架(在第七节 A 部分进一步分析)。
3、FedFM 的聚合方法
- 加权平均(Weighted Average):
- 当前 FedFM 研究的主流方法,通过平均客户端本地模型更新生成全局模型。
- 优点是简单高效,但可能无法充分利用 FMs 的复杂性。
- 新兴方法:
- 探讨了如模型汤和 MoE 等技术,旨在提升聚合效果,但具体应用和优势需进一步研究。
- MoE-FL [78] 使用 MoE 在服务器上聚合一个强大的全局模型。它假设服务器和客户端之间存在信任,每个客户端都与服务器共享部分数据。虽然生成的强大聚合模型可以过滤异常值(中毒/损坏/过时的客户端模型),但在大多数有隐私要求的 FL 应用中,共享部分本地数据可能是被禁止的。为了解决 FL 中的数据异构性问题,FedMix [79] 允许每个客户端利用 MoE 自适应地选择与其相关的客户端专家模型。Fed-MoE [80] 获得在本地数据上预训练的所有客户端本地模型。
- PFL-MoE [81] 将 MoE 与个性化 FL (PFL) 相结合,以在保持模型泛化的同时提高模型个性化。它为每个客户端构建一个 MoE,涉及门控网络和两个专家模型——全局模型和局部个性化模型。每个客户端使用门控网络为两个专家模型的输出生成两个权重,并将加权输出混合作为最终输出。pFedMoE [82] 首次将 MoE 引入模型异构个性化 FL (MHPFL),以实现异构客户端模型之间的协作和高效的通信和计算。每个客户端都由一个由门控网络、作为全局专家的共享同质特征提取器和作为局部专家的异构客户端模型组成的 MoE 构建而成。对于每个局部数据样本,门控网络生成一对个性化权重来表示两个专家。客户端对它们执行加权平均,以形成包含广义和个性化特征的完整表示。
6.5迈向可信的 FedFM
FedFM 结合了联邦学习(FL)和基础模型(FMs)的优势,但其复杂性和分布式特性带来了新的安全和隐私挑战。
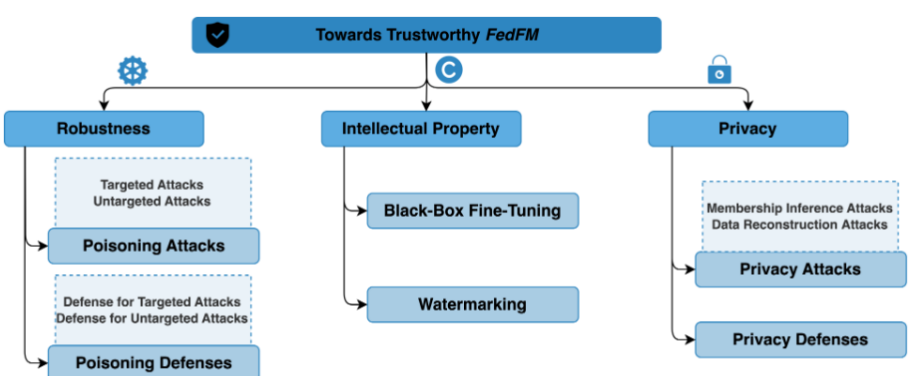
A. Robustness(鲁棒性)
- 挑战:
- 毒化攻击(Poisoning Attacks):
- 无目标攻击:旨在破坏训练过程,阻止模型收敛。
- 有目标攻击:微妙地操纵模型输出,难以检测。
- FedFM 的复杂性和异构性(heterogeneity)使得这些攻击更难实施和防御。
- 毒化攻击(Poisoning Attacks):
- 解决方案:
- 拜占庭鲁棒聚合规则(Byzantine-robust Aggregation Rules):
- 如几何异常检测(geometrical outlier detection)、顶级性能选择(top performance selection)和混合方案。
- 这些方法旨在过滤恶意更新,但其在 FedFM 环境中的有效性受到质疑,需要针对其复杂性开发新方法。
- 拜占庭鲁棒聚合规则(Byzantine-robust Aggregation Rules):
- 研究现状:
- 现有防御机制多针对传统 FL,未完全适应 FMs 的规模和特性,需进一步创新。
B. Privacy Preservation(隐私保护)
- 挑战:
- 隐私攻击:
- 成员推断攻击(Membership Inference Attacks):推测特定数据是否用于训练。
- 数据重构攻击(Data Reconstruction Attacks):尝试重构原始训练数据。
- FMs 的大规模和 FedFM 的分布式特性增加了新的漏洞。
- 隐私攻击:
- 解决方案:
- 隐私防御技术:
- 差分隐私(Differential Privacy):通过添加噪声保护个体数据。
- 置信度掩码(Confidence Masking):隐藏敏感信息。
- 模型压缩(Model Compression):减少共享信息的暴露风险。
- 原文:通过在共享本地模型更新中添加统计噪声,差分隐私技术可以在不同程度上提供隐私保护保障 [131]–[133]。隐私保护和模型性能之间的权衡已经得到了广泛的研究,博弈论通常被用来约束添加到模型中的噪声的方差,同时通过激励机制补偿客户的隐私风险 [134],[135]。通过结合梯度/模型压缩和稀疏化机制,可以进一步增强恢复隐私本地数据的难度 [136]–[139]。由于模型性能和压缩程度之间的紧张关系,性能和隐私之间的权衡也是一个重要的研究课题 [139],[140],旨在找到对性能影响较小的隐私保障潜在最优解决方案。
- 这些技术需平衡隐私保护与模型更新质量。
- 隐私防御技术:
- 研究现状:
- 当前方法需针对 FedFM 的特性调整,以应对其独特威胁景观(threat landscape)。
C. Intellectual Property Protection(知识产权保护)
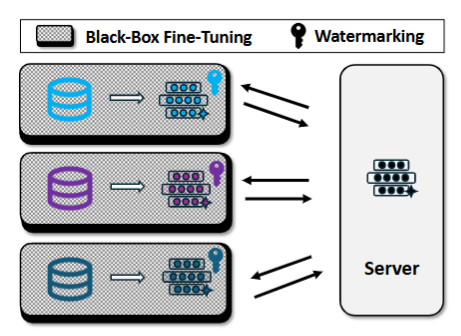
- 挑战:
- FedFM 的分布式训练增加了模型被盗用或未经授权使用的风险。
- 保护模型所有权在多样化和复杂环境中尤为重要。
- 解决方案:
- 黑盒微调(Black-box Fine-tuning):
- 允许模型适应特定任务,同时保持核心知识产权不变。
- 黑盒微调:黑盒微调是指在不访问模型内部参数的情况下对 FM 进行微调的方法 [142]。这种方法在 FL 中尤其重要,因为维护原始模型的完整性和所有权至关重要。黑盒微调方法通常会在保持原始模型不变的情况下添加新参数,从而保留原始模型的知识产权。例如,Fed-BBPT [143] 是一个提示调整框架,它支持跨多个客户端联合训练轻量级提示生成器。该框架允许客户端在本地微调其模型,而无需访问或更改核心模型参数。类似地,[144] 中的方法称为 FedBPT,它使用进化算法来训练最佳提示,从而增强冻结 FM 的性能。这些黑盒微调方法确保可以在强大的知识产权保护下实现 FM 的本地微调。然而,当前的研究主要集中于使用小数据集进行少样本学习以进行 FM 微调,这表明需要使用更大的数据集和多种数据类型进行进一步探索,以充分利用黑盒微调对 FedFM 的潜力。
- 水印技术(Watermarking):
- 在模型中嵌入可识别标记以证明所有权。
- 水印:水印是一种广泛采用的知识产权保护技术,通过将标识符嵌入模型来证明所有权。在 FL 环境中,[141] 引入了 WAFFLE,这是一种将水印嵌入全局模型的解决方案。即使模型分布在多个客户端上,这种技术也能确保模型的所有权得到验证。最近,[145] 开发了 DUW,它将一个唯一的密钥嵌入到每个客户端的本地模型中。该密钥可以识别泄露模型的来源并验证所有权,从而为联邦环境中的知识产权保护提供强大的机制。
- 这些方法旨在确保 FedFM 在分布式网络中的安全使用。
- 黑盒微调(Black-box Fine-tuning):
- 研究现状:
- 当前策略的有效性在 FedFM 的异构环境中仍需验证,需开发更鲁棒的定制方法。
6.6迈向 FedFM 的激励机制
- FedFM 的成功依赖于多方协作,但参与者可能因资源成本或隐私顾虑不愿参与。
- 本节旨在审查激励机制的设计,解决参与激励、贡献量化以及公平分配的挑战,为 FedFM 的可持续发展和广泛采用提供支持。
A. Participant Selection(参与者选择)
- 挑战:
- 需要选择能够提供高质量数据和计算能力的参与者,同时平衡资源分配和协作效率。
- FedFM 的复杂性要求参与者具备适应大规模模型的能力。
- 解决方案:
- 传统方法:
- 合同理论(Contract Theory):通过合同设计激励参与并优化资源。
- 博弈论(Game Theory):分析参与者的策略行为以制定协作规则。
- 拍卖机制(Auction Mechanisms):通过竞价选择参与者并分配任务。
- 新兴方法:
- 模型中心方法(Model-centric Approaches):
- 根据参与者的模型特性(如任务特定训练适应性或垂直训练能力)选择参与者。
- 强调参与者对 FedFM 性能的具体贡献。
- 模型中心方法(Model-centric Approaches):
- 传统方法:
- 研究现状:
- 传统方法已在 FL 中广泛应用,但针对 FedFM 的模型中心方法尚处于探索阶段,需进一步验证其可行性。
B. Contribution Assessment(贡献评估)
- 挑战:
- 准确量化每个参与者对 FedFM 的贡献是激励机制的核心问题。
- FMs 的复杂性和分布式训练的异构性(如 non-IID 数据)使得传统评估方法(如 Shapley 值)计算成本高且不实用。
- 解决方案:
- 传统方法:
- Shapley 值:基于博弈论的公平贡献评估,但因指数级计算复杂度在 FedFM 中难以实施。
- 新兴方法:
- 开发轻量级贡献评估技术,如基于梯度影响或性能增益的近似方法。
- 针对 FedFM 的组合问题,探索更高效的评估框架。
- 传统方法:
- 研究现状:
- 当前方法在 FedFM 的大规模和动态环境中存在局限,需创新以适应其独特需求。
C. Reward Distribution(奖励分配)
- 挑战:
- 需要设计公平的奖励机制以防止搭便车(free-riding)、激励持续参与并确保项目的可持续性。
- 奖励分配需平衡参与者的贡献与成本(如计算和通信开销)。
- 解决方案:
- 经济激励:
- 基于贡献的货币或代币奖励。
- 非经济激励:
- 如访问改进模型的权限或优先权。
- 动态分配:
- 根据实时贡献调整奖励,确保公平性和灵活性。
- 经济激励:
- 研究现状:
- 奖励分配在传统 FL 中已有初步研究,但 FedFM 的复杂性(如大规模参数和多样化参与者)要求更精细和适应性强的机制。
6.7FedFM 的实现与应用
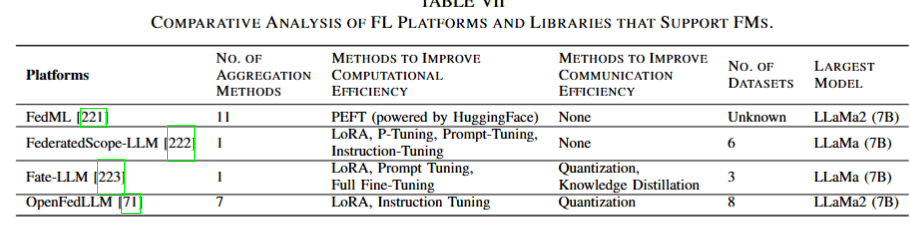
A. Frameworks Supporting FedFM(支持 FedFM 的框架)
- 目标:
- 提供支持 FedFM 训练、聚合和部署的技术基础设施,适应其大规模和分布式特性。
- 现有框架:
- 传统 FL 框架:
- 如 TensorFlow Federated (TFF) 和 PySyft,支持分布式训练和隐私保护,但主要针对较小规模模型。
- 新兴框架:
- Flower:一个灵活的 FL 框架,支持异构设备和大规模协作,逐渐适应 FedFM 的需求。
- FedML:提供模块化支持,包括 FedFM 的训练和微调,强调可扩展性和研究友好性。
- 量子计算支持:
- 探索量子计算框架(如 Qiskit 和 PennyLane)在优化 FedFM 训练和推理中的潜力。
- 传统 FL 框架:
- 挑战与需求:
- 当前框架需进一步优化以支持 FMs 的庞大参数量和高计算需求。
- 需要集成更高效的通信协议和聚合算法,以适应 FedFM 的分布式环境。
B. Applications(应用)
- 医疗保健(Healthcare):
- 场景:利用 FedFM 分析分散的患者数据(如电子健康记录),开发疾病预测模型。
- 优势:保护患者隐私,同时利用多机构数据提升模型性能。
- 案例:跨医院协作训练诊断模型。
- 金融(Finance):
- 场景:基于分散的交易和客户数据训练欺诈检测或风险评估模型。
- 优势:避免数据集中化,满足严格的合规性要求(如 GDPR)。
- 案例:银行间协作改进反洗钱系统。
- 智能物联网(Smart IoT):
- 场景:在边缘设备(如智能家居设备)上训练 FedFM,用于实时预测和优化。
- 优势:减少云端依赖,提升响应速度和隐私性。
- 案例:分布式智能城市管理系统。
- 自然语言处理(NLP):
- 场景:基于多语言用户数据训练语言模型,支持个性化服务。
- 优势:利用全球分布式数据提升模型的多样性和泛化能力。
- 案例:跨国协作的聊天机器人开发。
- 其他领域:
- 如自动驾驶(协作训练感知模型)和教育(个性化学习模型),展示了 FedFM 的广泛适用性。
C. Implementation Challenges(实现挑战)
- 技术挑战:
- 计算资源:边缘设备的异构性限制了 FedFM 的本地训练能力。
- 通信效率:大规模参数传输导致高延迟和带宽需求。
- 模型聚合:FMs 的复杂性要求更鲁棒的聚合方法。
- 信任性挑战:
- 需应对毒化攻击和隐私泄露风险,确保系统的安全性和可靠性。
- 激励机制:
- 设计公平的激励以鼓励持续参与和资源贡献。
D. Future Directions(未来方向)
- 框架优化:
- 开发专门支持 FedFM 的框架,集成量子计算和高效通信技术。
- 跨领域扩展:
- 探索 FedFM 在更多领域的应用,如能源管理和气候建模。
- 实验验证:
- 通过更大规模的实验验证 FedFM 的性能和可行性。

















 3911
3911

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









