









目录
前面的话
目的是抛砖引玉,不太建议直接抄。
为爱发电,多点赞可能会导致我更新未来你想要的内容。
正文
1、实验目的
利用感知机算法对鸢尾花种类进行分类,要求熟悉感知机算法,掌握利用Python实现机器学习算 法的一般流程,了解scikit-learn机器学习库的使用。
2、背景知识
植物的分类与识别是植物学研究和农林业生产经营中的重要基础工作,对于区分植物种类、探索 植物间的亲缘关系、阐明植物系统的进化规律具有重要意义。传统识别植物的方法主要依靠人工,需 要丰富的专业知识,工作量大,效率不高,而且难以保证分类的客观性和精确性。随着信息技术飞速 发展,将计算机视觉、模式识别、数据库等技术应用于植物种类识别,使得识别更加简单、准确、易 行。相对于植物的其它部分,其花朵图像更容易获取,花朵的颜色和形状等都可作为分类依据。本案 例在提取花朵形态特征的基础上,利用感知机算法进行分类与识别。 鸢尾花:鸢读音同"愿",英文为 Iris,多年生草本植物,花大而美丽,叶片青翠碧绿,观赏价 值很高,是一种重要的观赏用庭园植物。 其外形作为独特的徽章,在欧洲的宗教、皇室建筑上被广泛 应用。特别是在法国,印在法国军旗上的三朵鸢尾花图案标志着法兰西王国的王权。鸢尾花有三个主 要类型(种属): Setosa 山鸢尾、 Versicolour 变色鸢尾 和 Virginica 维吉尼亚鸢尾,其主要区别是 萼片长度、萼片宽度、花瓣长度和花瓣宽度。

鸢尾花数据集: scikit-learn 是基于 Python 的机器学习库,其默认安装包含了几个小型的数据集,
并提供了读取这些数据集的接口。 其中 sklearn.datasets.load_iris()用于读取鸢尾花数据集。
感知机( perceptron)是神经网络的基本组成单元,也被称为神经元, 由美国学者 Frank
Rosenblatt 于 1957 年提出。 下图为一个有三个输入的感知器的结构图。 其中 x1、 x2、 x3 为输入,
w1、 w2、 w3 为相应的权值, b 为偏置, f 为激活函数, y 为神经元的输出。 偏置 b 也可视为输入恒为
1 的边的权值,记为 w0。
Rosenblatt 在其感知机论文中使用的激活函数是 sign(x), 该函数用来描述一个实数的符号,当
x>0 时,输出值为 +1;当 x= 0 时,输出值为 0;当 x<0 时,输出值为-1。
感知器的学习规则,即感知器中的权值参数训练的方法,公式为: 𝜟𝒘𝒊 = 𝒍𝒓(𝒕 - 𝒚)𝒙𝒊,其中𝜟𝒘𝒊
表示第 i 个权值的变化, 𝒍𝒓表示学习率(Learning Rate),用来调节权值变化的大小; 𝒕是真值(目标值
target), y 为神经元的输出, 𝒙𝒊是输入。
3、 示例代码
1) 加载用到的库
1. import numpy as np
2. import matplotlib.pyplot as plt
3. from sklearn.datasets import load_iris #仅用于加载数据集
2) 加载鸢尾花数据集
1. iris = load_iris()
如前所述, scikit-learn 提供了读取鸢尾花数据集的接口 sklearn.datasets.load_iris(),该数据集
有 150 组 3 种类型鸢尾花的 4 种属性:萼片长度 sepal length、萼片宽度 sepal width、花瓣长度 petal
length 和花瓣宽度 petal width,样本编号与类型的关系是:样本编号 0 至 49 为 Setosa ,50 至 99 为
Versicolour ,100 至 149 为 Virginica。
代码 iris = load_iris()中得到的 iris 是一个字典,包含七个“key-value”对:
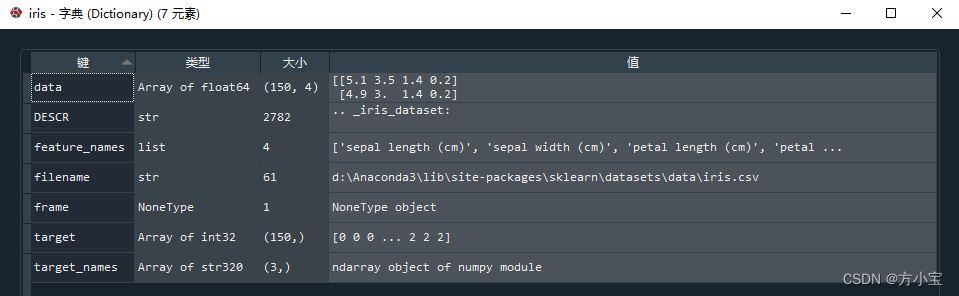
其中每一个 key 的意义和 value 说明如下: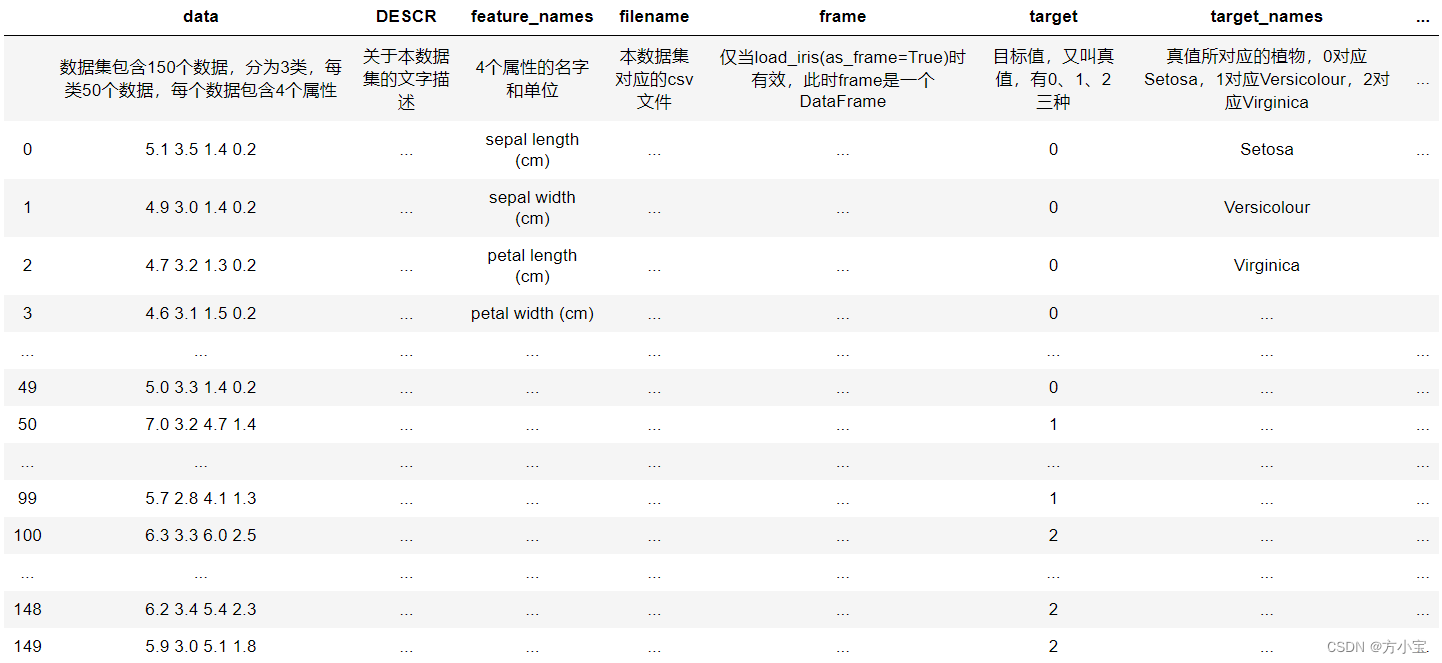
3) 通过画图了解三种鸢尾花的分布
1. plt.clf()
2. plt.xlim(0, 7)#x 轴上的最小值和最大值
3. plt.ylim(0, 4)
4. plt.title(u'iris 数据集 萼片', fontsize=15)
5. X=iris.data[:,0:2]
6.
7. plt.xlabel('petal length 萼片长度', fontsize=13)
8. plt.ylabel('petal width 萼片宽度', fontsize=13)
9. plt.plot(X[:50, 0], X[:50, 1], 'bo', color='blue', label='Setosa 山鸢尾')
10. plt.plot(X[50:100, 0], X[50:100, 1], 'bo', color='orange', label='Versicolour 变色鸢尾')
11. plt.plot(X[100:150, 0], X[100:150, 1], 'bo', color='red', label='Virginica 维吉尼亚鸢尾')
12. plt.legend()
13.
14. plt.show()
生成图片如下: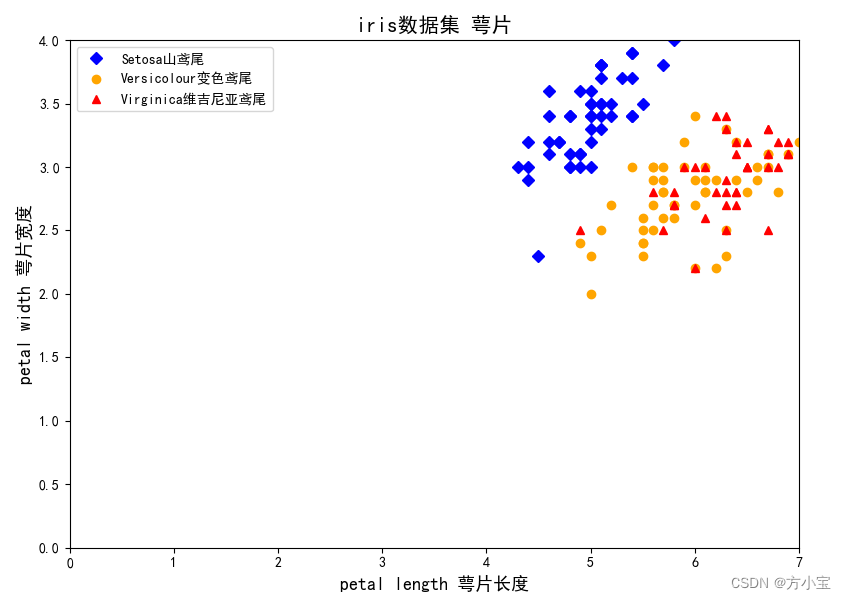
从图中大致可以看出,萼片长度和萼片宽度与鸢尾花类型间呈现出非线性关系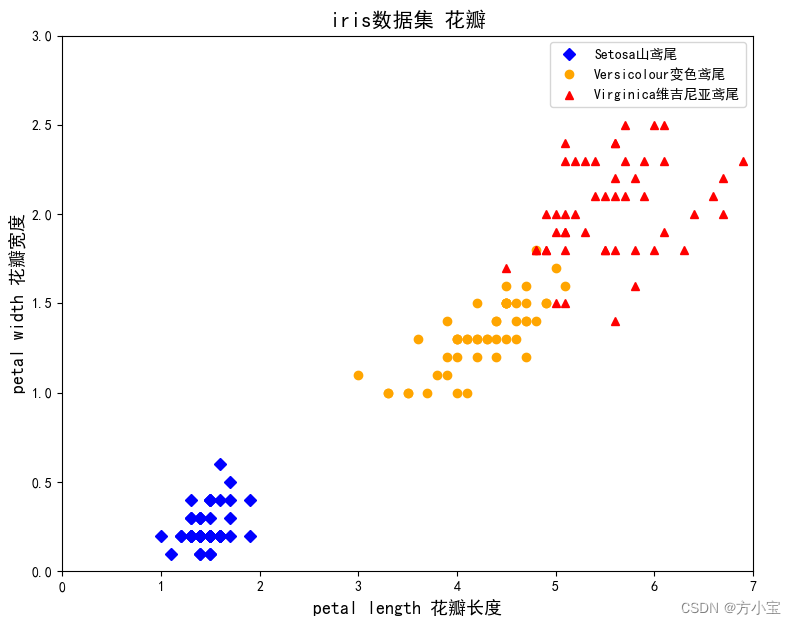
从图中大致可以看出, 花瓣长度和花瓣宽度与鸢尾花类型间有较好的线性关系,使用花瓣数据
来划分鸢尾花类型效果更好。
4) 算法初始化
1. X=np.c_[np.ones(100),iris.data[:100,2:4]] #输入 X
2. T=iris.target[:100].reshape(100,1) #真值 T
3. T[T!=1] = -1 #将 0 用-1 表示,以契合 sign 函数
4. W = np.array([[-7], #权值初始化, 3 行 1 列,即 w0 w1 w2
5. [1],
6. [1]])
7. lr = 1 # 学习率设置
8. Y = 0 # 神经网络输出
np.ones(100) 生成 100 行 1 列的 1,作为偏置的输入。
iris.data[:100,2:4] 得到前 100 行,2 列和 3 列数据,作为两个特征(花瓣长度、花瓣宽度)的输入。
np.c_是按行连接两个矩阵,就是把两矩阵左右相连形成一个新矩阵,要求行数相等。
组合两个特征和偏置,形成最终的输入 X。
X=(x0 x1 x2),即偏置、花瓣长度、花瓣宽度。
真值 T 直接从数据集中得到,然后将 T 中所有不等于 1 的元素赋值为-1,以契合接下来将要使
用到的 sign 函数。
5) 学习算法
1. def train():
2. global W
3. Y = np.sign(np.dot(X,W))
4. E = T - Y
5. delta_W = lr * (X.T.dot(E)) / X.shape[0]
6. W = W + delta_W
请参考教材加以理解。
6) 画图函数
1. def draw():
2. plt.clf()
3. plt.xlim(0, 6)#x 轴上的最小值和最大值
4. plt.ylim(0, 2)#y 轴上的最小值和最大值
5. plt.title(u'Perceptron 感知
器 epoch:%d\n W0:%f W1:%f W2:%f' %(i+1,W[0],W[1],W[2]), fontsize=15)
6.
7. plt.xlabel('petal length 花瓣长度', fontsize=13)
8. plt.ylabel('petal width 花瓣宽度', fontsize=13)
9.
10. plt.plot(X[:50, 1], X[:50, 2], 'bo', color='red', label='Setosa 山鸢尾')
11. # 用黄色的点来画出负样本
12. plt.plot(X[50:100, 1], X[50:100, 2], 'bo', color='blue', label='Versicolour 变色鸢尾
')
13. plt.plot(2.5, 1, 'b+', color='black', label='待预测点')
14.
15. k = - W[1] / W[2]
16. d = -W[0] / W[2]
17. # 设定两个点
18. xdata = (0,6)
19. # 通过两个点来确定一条直线,用红色的线来画出分界线
20. plt.plot(xdata,xdata * k + d,'black', linewidth=3)
21. plt.legend()
22. ####################################################以下绘制决策面两边的颜色,不要求掌握
23. # 生成决策面
24. from matplotlib.colors import ListedColormap #绘制决策面两边的颜色,不要求掌握
25. # 生成 x,y 的数据
26. n = 256
27. xx = np.linspace(0, 6, n)
28. yy = np.linspace(0, 2, n)
29. # 把 x,y 数据生成 mesh 网格状的数据,因为等高线的显示是在网格的基础上添加上高度值
30. XX, YY = np.meshgrid(xx, yy)
31. # 填充等高线
32. colors = ('red', 'blue', 'lightgreen', 'gray', 'cyan')
33. cmap = ListedColormap(colors[:len(np.unique(np.sign(W[0]+W[1]*XX+W[2]*YY)))])
34. plt.contourf(XX, YY, np.sign(W[0]+W[1]*XX+W[2]*YY),8, alpha = 0.5, cmap=cmap)
35. #####################################################以上绘制决策面两边的颜色,不要求掌握
36. plt.pause(0.1)
37. plt.show()
请参考代码注释加以理解。
7) 主函数
1. # 训练 1000 次
2. for i in range(1000):
3. if(i==0): #特地画出未经训练的初始图像,以方便理解
4. draw()
5. plt.pause(5) #停留两秒,这是分类直线最初的位置,取决于 W 的初始值,是人为决定的超参数
6. train() #更新一次权值
7. draw() #画出更新一次权值后的图像
8. Y = np.sign(np.dot(X,W))
9. # .all()表示 Y 中的所有值跟 T 中所有值都对应相等,结果才为真
10. if(Y == T).all():
11. print('Finished')
12. # 跳出循环
13. break
请参考代码注释加以理解。
4、 实验内容
请回答下列问题:
1)考虑学习率的作用。修改示例代码,固定初始权值=(1,1,1),将学习率分别设定为 1、 0.5、
0.1(组合 1~3),程序在 epoch 等于多少时实现分类?
2)考虑初始权值的作用。修改示例代码,固定学习率=0.1,将初始权值分别设定为(-1,1,1)、
(+1,-1,-1)、 (1,-1,+1) 、 (-1,+1,-1) (组合 4~7) , 程序在 epoch 等于多少时实现分类?
3)示例程序使用的是离散感知机还是连续感知机?如何判断?
4) 为什么在学习算法中要除以 X.shape[0] ?示例程序采用的是批量下降还是逐一下降?是否属
于随机下降?是否属于梯度下降?
5) 假设你在自然界找到了一朵鸢尾花,并测得它的花瓣长度为 2.5cm,花瓣宽度为 1cm,它属
于哪一类?在 draw()中已用 plt.plot 画出这个'待预测点'。请观察 1~7 这 7 种组合中,感知机的判断始
终一致么? 这说明它受到什么因素的影响?
6)修改示例代码,将变色鸢尾的数据替换为维吉尼亚鸢尾,再进行分类。
即横轴为花瓣长度,纵轴为花瓣宽度,数据为 Setosa 山鸢尾+Virginica 维吉尼亚鸢尾。
7) 【可选】 目前感知机只有两个输入+偏置,如果有三个输入(比如增加萼片长度作为输入),
程序应如何修改(可以不画图)?
题目答案
1) 考虑学习率的作用。 修改示例代码, 固定初始权值=(1,1,1), 将学习率分别设定为 1、
0.5、 0.1(组合 1~3), 程序在 epoch 等于多少时实现分类?
答:
固定初始权值,
①当学习率设定为 1 的时候, 程序在 epoch 等于 8 的时候实现分类。
②当学习率设定为 0.5 的时候, 程序在 epoch 等于 9 的时候实现分类。
③当学习率设定为 0.1 的时候, 程序在 epoch 等于 181 的时候实现分类。
2) 考虑初始权值的作用。 修改示例代码, 固定学习率=0.1, 将初始权值分别设定为(-1,1,1)、
(+1,-1,-1)、 (1,-1,+1) 、 (-1,+1,-1) (组合 4~7), 程序在 epoch 等于多少时实现分
类?
答:
固定学习率,
①当初始权值分别设定为(-1,+1,+1)时, 程序在 epoch 等于 13 时实现分类。
②当初始权值分别设定为(+1,-1,-1)时, 程序在 epoch 等于 33 时实现分类。
③当初始权值分别设定为(+1,-1,+1)时, 程序在 epoch 等于 322 时实现分类。
④当初始权值分别设定为(-1,+1,-1)时, 程序在 epoch 等于 147 时实现分类。
3) 示例程序使用的是离散感知机还是连续感知机? 如何判断?
答:
示例程序用的是离散感知机, 判断的因素包括激活函数是离散的还是连续的, 因为
sign 激活函数是一个离散函数, 在 x=0 这个点函数是不连续的
4) 为什么在学习算法中要除以 X.shape[0] ? 示例程序采用的是批量下降还是逐一下
降? 是否属于随机下降? 是否属于梯度下降?
答:
是为了调整权值, X.shape[0]表示 X 的行数, 一次训练的数据量。 在调整 W 和 b 的之
前计算的时候是计算了一次训练的所有误差, 所以需要除以 X.shape[0]来正确的调整误差。
示例程序采用的是批量下降, 不属于随机下降, 属于梯度下降。
5) 假设你在自然界找到了一朵鸢尾花, 并测得它的花瓣长度为 2.5cm, 花瓣宽度为 1cm,
它属于哪一类? 在 draw()中已用 plt.plot 画出这个'待预测点'。 请观察 1~7 这 7 种
组合中, 感知机的判断始终一致么? 这说明它受到什么因素的影响?
答:
第一组: 初始权值设置为(+1,+1,+1), 学习率设置为 1
预测结果为: Versicolour 变色鸢尾
第二组: 初始权值设置为(+1,+1,+1), 学习率设置为 0.5
预测结果为: Versicolour 变色鸢尾
第三组: 初始权值设置为(+1,+1,+1), 学习率设置为 0.1
预测结果为: Versicolour 变色鸢尾
第四组: 初始权值设置为(-1,+1,+1), 学习率设置为 0.1
预测结果为: Versicolour 变色鸢尾
第五组: 初始权值设置为(+1,-1,-1), 学习率设置为 0.1
预测结果为: Versicolour 变色鸢尾
第六组: 初始权值设置为(+1,-1,+1), 学习率设置为 0.1
预测结果为: Versicolour 变色鸢尾
第七组: 初始权值设置为(-1,+1,-1), 学习率设置为 0.1
预测结果为: Setosa 山鸢尾
从上面的数据来看, 第七组其他组的预测结果不一样。 如果只从上面的数据得到预测
结果与初始权值的相关性比较大, 与学习率的相关性比较小。
6) 修改示例代码, 将变色鸢尾的数据替换为维吉尼亚鸢尾, 再进行分类。 即横轴为花瓣
长度, 纵轴为花瓣宽度, 数据为 Setosa 山鸢尾+Virginica 维吉尼亚鸢尾。
答:
在程序的算法初始化中修改:
X=np.c_[np.ones(100),iris.data[:100,2:4]]
T[T!=1] = -1
为:
X1=np.c_[np.ones(50),iris.data[0:50,2:4]]
X2=np.c_[np.ones(50),iris.data[100:150,2:4]]
X=np.r_[X1,X2]
T1=iris.target[:50].reshape(50,1)
T2=iris.target[100:150].reshape(50,1)
T=np.r_[T1,T2]
T[T==0]=1
T[T==2]=-1
X1 是 Setosa 山鸢尾的数据, X2 是 Virginica 维吉尼亚鸢尾的数据, 再使用 np.r_函
数, 按列连接两个矩阵, 把两矩阵上下相加, 要求列数相等。
然后再修改程序中的画图模块:
plt.xlim(0, 6)#x 轴上的最小值和最大值
plt.ylim(0, 2)#y 轴上的最小值和最大值
plt.plot(X[:50, 1], X[:50, 2], 'bo', color='red', label='Setosa 山鸢尾')
plt.plot(X[50:100, 1], X[50:100, 2], 'bo', color='blue', label='Versicolour 变色鸢尾')
xdata = (0,6)
xx = np.linspace(0, 6, n)
yy = np.linspace(0, 2, n)
分别修改为
plt.xlim(0, 8)#x 轴上的最小值和最大值
plt.ylim(0, 3)#y 轴上的最小值和最大值
plt.plot(X[:50, 1], X[:50, 2], 'o', color='red', label='Setosa 山鸢尾')
plt.plot(X[50:100, 1], X[50:100, 2], 'o', color='blue', label='Virginica 维吉尼亚鸢尾')
xdata = (0,8)
xx = np.linspace(0, 8, n)
yy = np.linspace(0, 3, n)
分别修改 x、 y 轴上的最大最小值, 修改两个坐标轴的含义, 分割线的长度, 带颜色划
分区间的大小。
得到运行结果, 当初始权值为(+1,+1,+1), 学习率为 0.1 的情况下, 运行到 epoch=129
的时候完成, W[0]=-0.236 W[1]=-0.1622 W[2]=0.8234。 运行结果如下图所示。
7)【可选】 目前感知机只有两个输入+偏置, 如果有三个输入(比如增加萼片长度作为输
入),
程序应如何修改(可以不画图) ?
答:
在程序的“算法初始化” 模块中修改:
X=np.c_[np.ones(100),iris.data[:100,0:1],iris.data[:100,2:4]]
目的是在设置输入 X 的时候, 将 1、 2、 3 列都放入 X 中, 最后形成(100, 4) 的二维
数组。 增加萼片长度作为输入。
在程序的“算法初始化” 模块中修改:
W = np.array([[+1],
[+1],
[+1],
[+1]])
四个输入对应的也就是四个权值, 需要初始化四个权值。 然后再更改画图函数。
def draw1():
fig = plt.figure()
ax = plt.axes(fc='whitesmoke', projection='3d')
n = 100
plt.title(u'Perceptron 感 知 器 epoch:%d\n W0:%f W1:%f W2:%f
W3:%f' %(i+1,W[0],W[1],W[2],W[3]), fontsize=15)
ax.scatter(X[:50, 1], X[:50, 2], X[:50, 3], 'o', color='red', label='Setosa 山鸢尾')
ax.scatter(X[50:100, 1], X[50:100, 2], X[50:100, 3], 'o', color='blue',
label='Versicolour 变色鸢尾')
op=7
A = np.linspace(0, op, op)
B = np.linspace(0, op, op)
XX, YY = np.meshgrid(A,B)
Q = -W[0] / W[3]
E = -W[2] / W[3]
R = -W[1] / W[3]
ax.plot_surface(XX,YY,Z=XX*(R)+(E)*YY+Q, color='y',alpha=0.8)
ax.set_xlabel('萼片长度')
ax.set_ylabel('花瓣长度')
ax.set_zlabel('花瓣宽度')
plt.show()
具体更改思路是创建一个三维画布然后在其中放入所有的数据, 包括 Setosa 和
Versicolour 的萼片长度、 花瓣长度和花瓣宽度。 经过训练之后, 得到的 W[0] 代表偏置,
W[1]代表萼片长度权值, W[2]代表花瓣长度权值, W[3]代表花瓣宽度权值。 期望在三维平
面中描绘一个平面, 平面的表达式为 AX+BY+CZ+D=0。 对于这个三维图, A 代表的是萼片长
度权值, 对应的是 W[1], B 代表的是花瓣长度权值, 对应的是 W[2], C 代表的是花瓣宽度
权 值 , 对 应 的 是 W[3] , D 代 表 的 是 偏 置 , 对 应 的 是 W[0] 。 得 到 Z 的 表 达 式 为
Z=-D/C-(B/C)*Y-(A/C)X, 带入 W[0]、 W[1]、 W[2]、 W[3]得 Z 的表达式为 Z=- W[0]/
W[3]-( W[2]/ W[3])*Y-( W[1]/ W[3])X。 代码中为了方便运算, Q = -W[0] / W[3], E =
-W[2] / W[3], R = -W[1] / W[3]。
得到运行结果, 当初始权值为(+1,+1,+1,+1), 学习率为 0.1 的情况下, 运行到 epoch=3
的时候完成, W[0]=0.7 W[1]=-0.5018 W[2]=0.5614 W[3]=0.9262。 运行结果如下图所示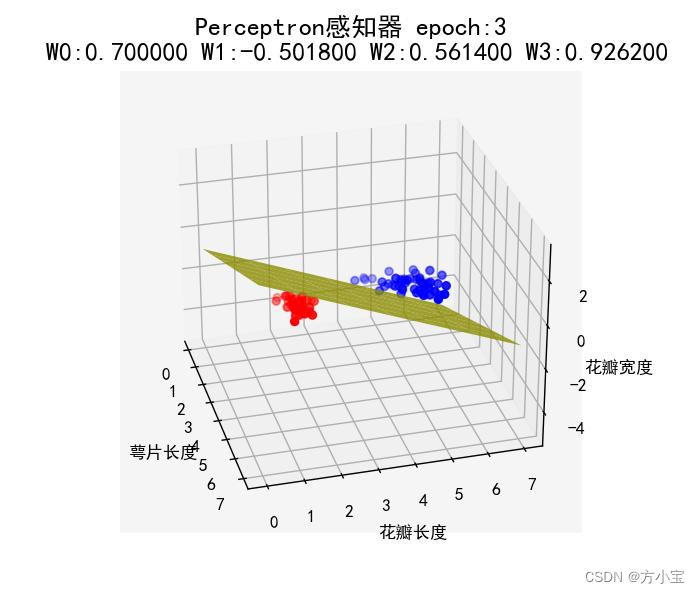
最后的话
:)看完点赞让我更快更新到你想要的内容。

















 524
524

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









