







听课(李宏毅老师的)笔记,方便梳理框架,以作复习之用。本节课主要讲了Network Compression,包括为什么要压缩,压缩的主要手段(pruning,knowledge distillation,parameter quantization,architecture design,dynamic computation)
引言
为什么要压缩模型?
- resource-constrained:因为有时需要把模型跑在计算资源有限的设备上,比如手表
- lower latency:比如智能驾驶,把资料从车传到云端又传回来,sensor需要非常及时的响应
- privacy:把资料传到云端,则云端系统持有者就能看到我们的资料

Network Pruning
概念
有些没有工作的参数可以剪掉,不然会占资源。就像人刚出生时没什么神经连接,但是6岁时就很多,再长大到14岁时反而少一点了。

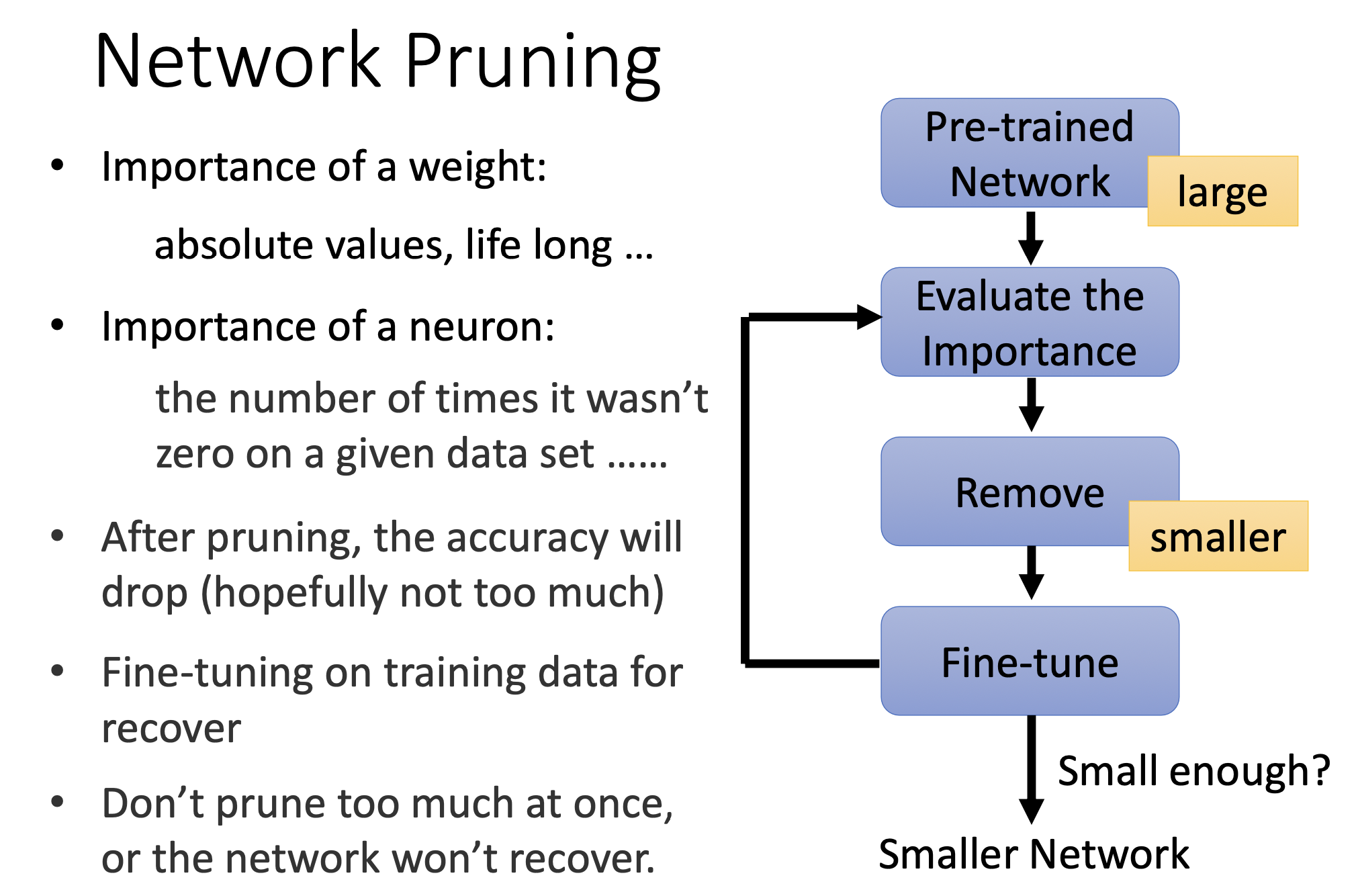
基本框架
- 预训练(此时是大模型)
- 评估重要性(参数或者神经元的)
- 剪枝
- 微调
- 可以再次回到评估阶段,循环多次
在剪枝后准确率会下降,但是可以通过微调,让模型恢复一些。最好不要一下子剪太多,不然模型无法恢复。可以一次剪一点,比如10%。
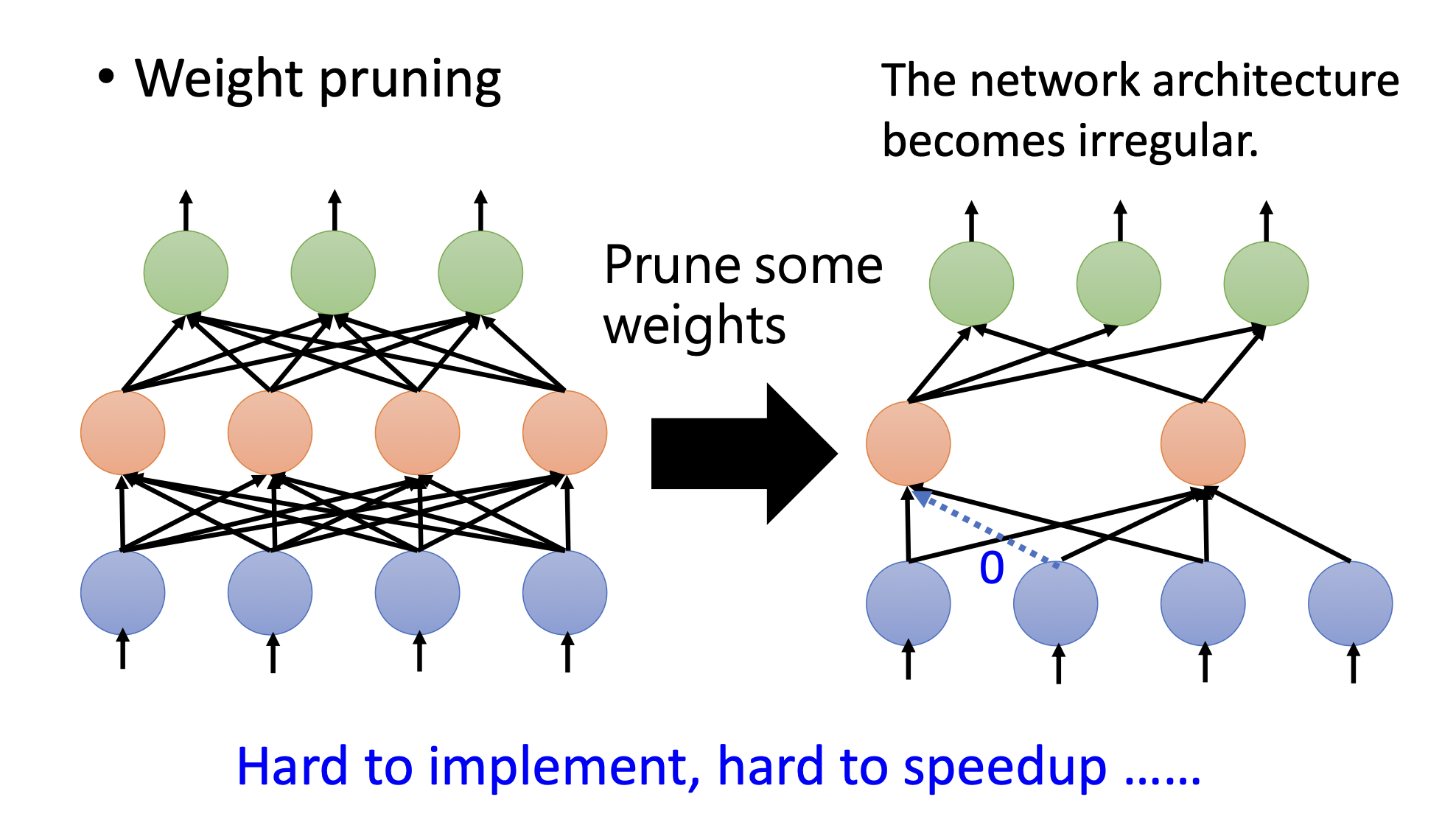
weight pruning
剪掉参数之后,模型不规则。所以用pytorch不好实践(主要是函数库的问题,如果写了不规则模型的函数库也可以),硬件也不允许。所以想通过把剪掉的参数补0来让模型变得规则,但实际上模型并没有变小。
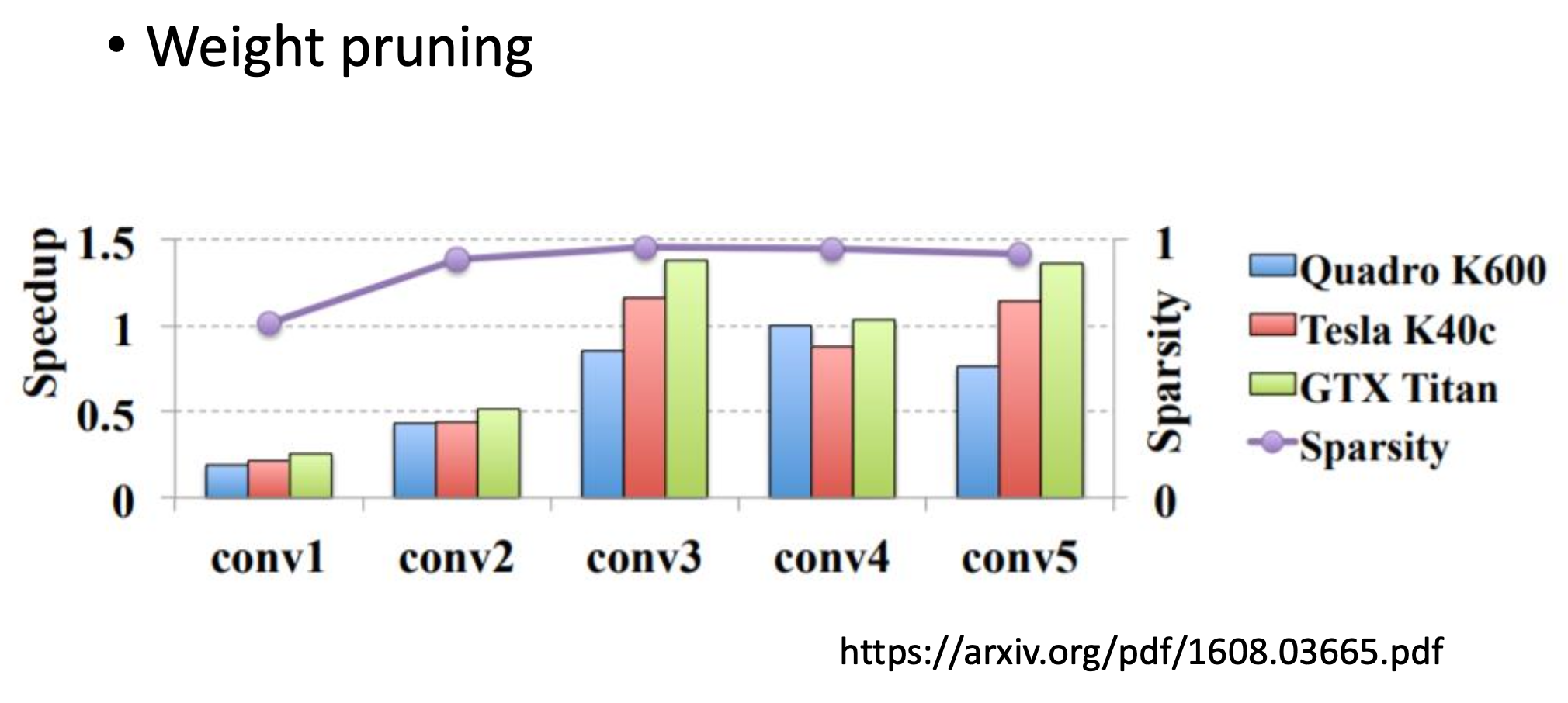
sparsity是指有多少百分比的参数被剪掉了,图中的sparsity接近1,但基本上没加速,多数情况下还变慢了
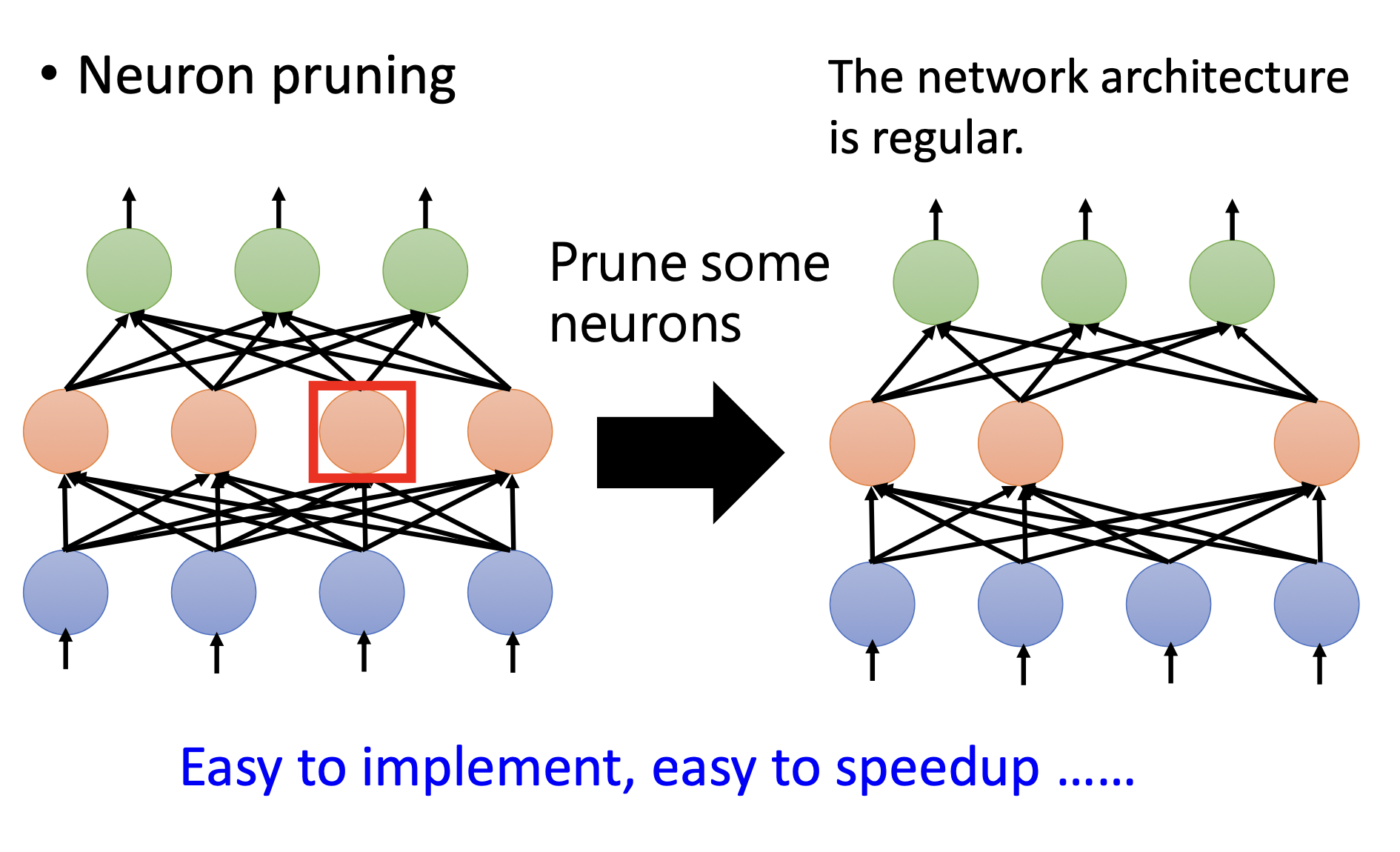
neuron pruning
Why pruning?
提出大乐透假说
为什么要先train大的再把它变成小的?怎么不直接从小的开始train?
因为大的模型更好train,直接train小的比train完大的变小的结果差。
为什么大的更好train?有一个假说叫大乐透假说。

大乐透假说的解释
一开始买更多彩票增加中奖率。可以把一个大的network看做是很多的sub-network。只要有一个sub-network成功,那这个大的network就能成功。
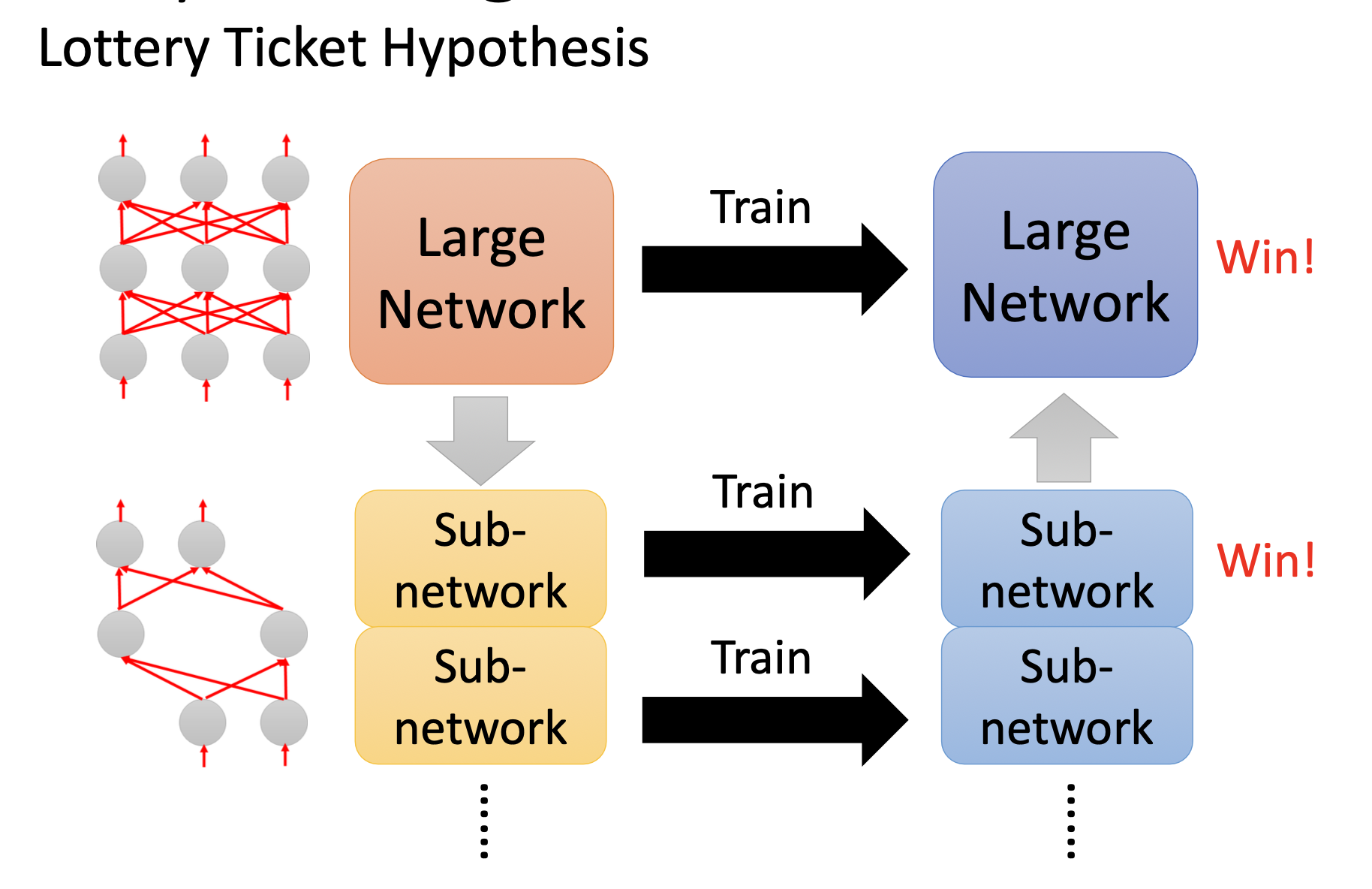
实验证明大乐透假说
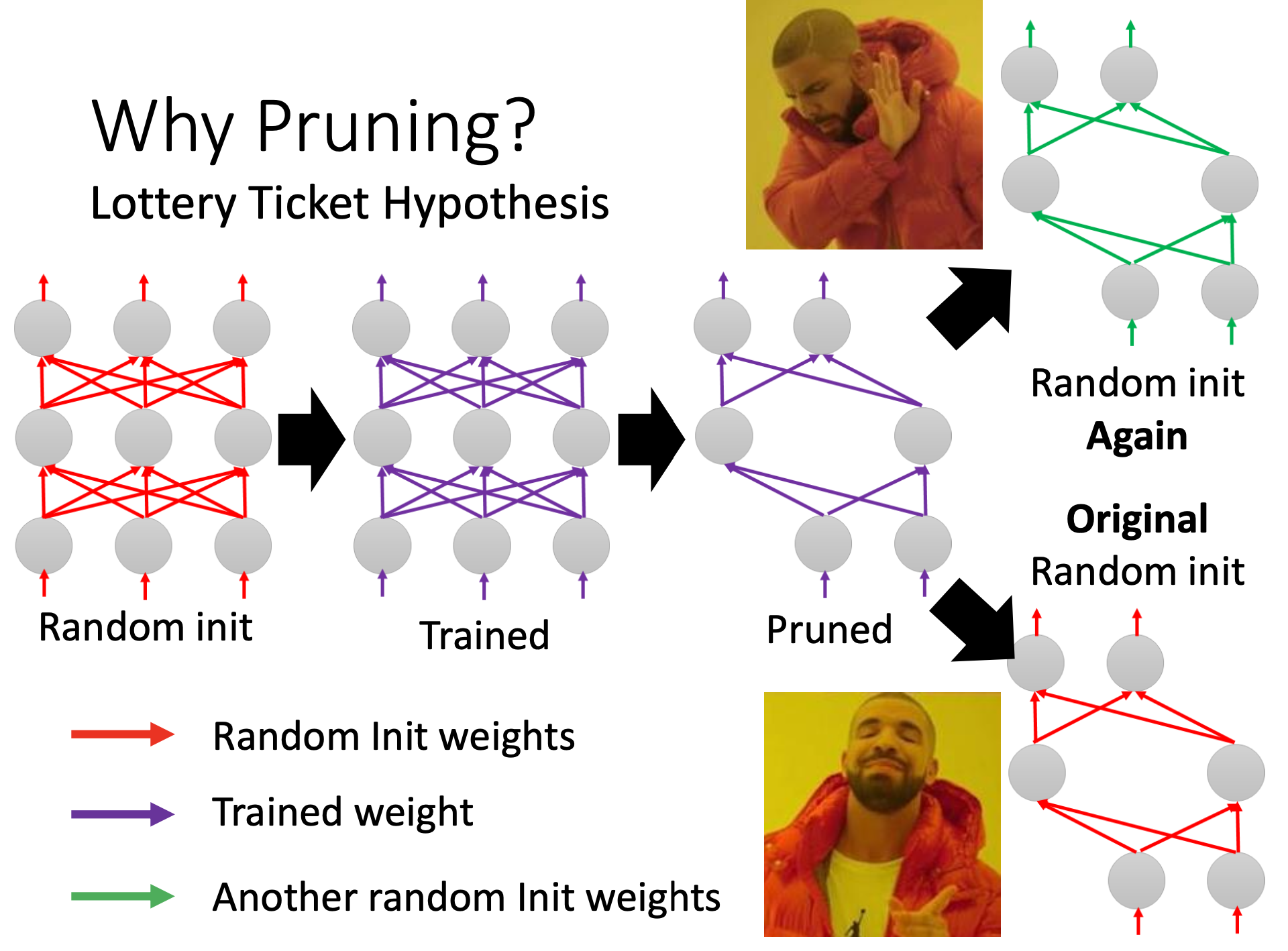
剪枝之后的小network,如果里面的参数都是random init的而不是没剪枝之前的,那就train不起来(对应绿色的参数);但是如果是用的剪枝之前的参数,相应位置的参数一一对应(红色的参数),这个小网络就能train。
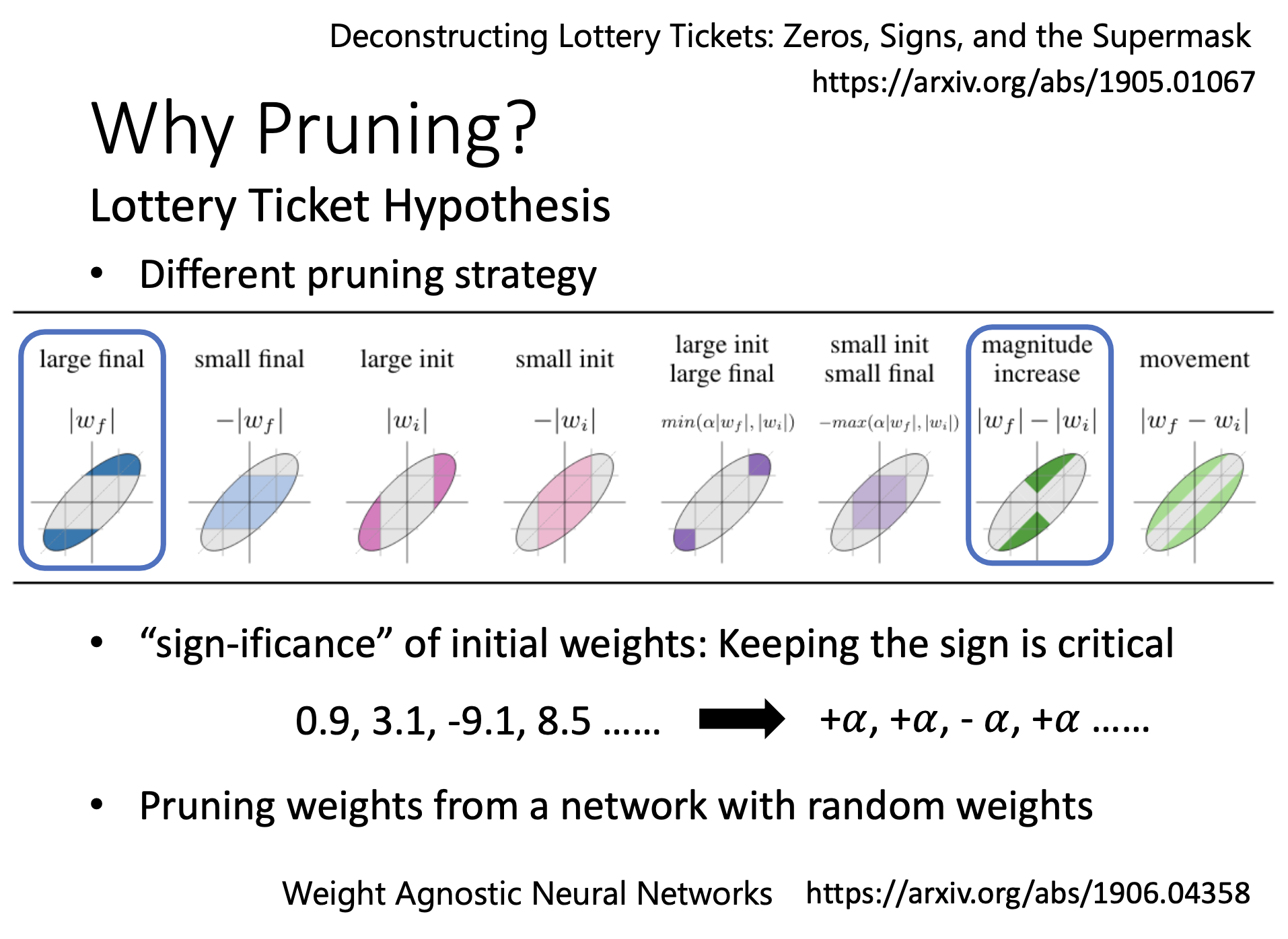
正负号是初始化参数能不能训练得起来的关键,绝对值不重要
反驳大乐透假说
- 直接train小的也可以,只要多点epoch(看Scratch-B的实验结果)
- 大乐透假说只在特定条件下起作用(小learning rate, unstructured)
这里的unstructured指的是以weight为单位prune才能观察到大乐透现象。

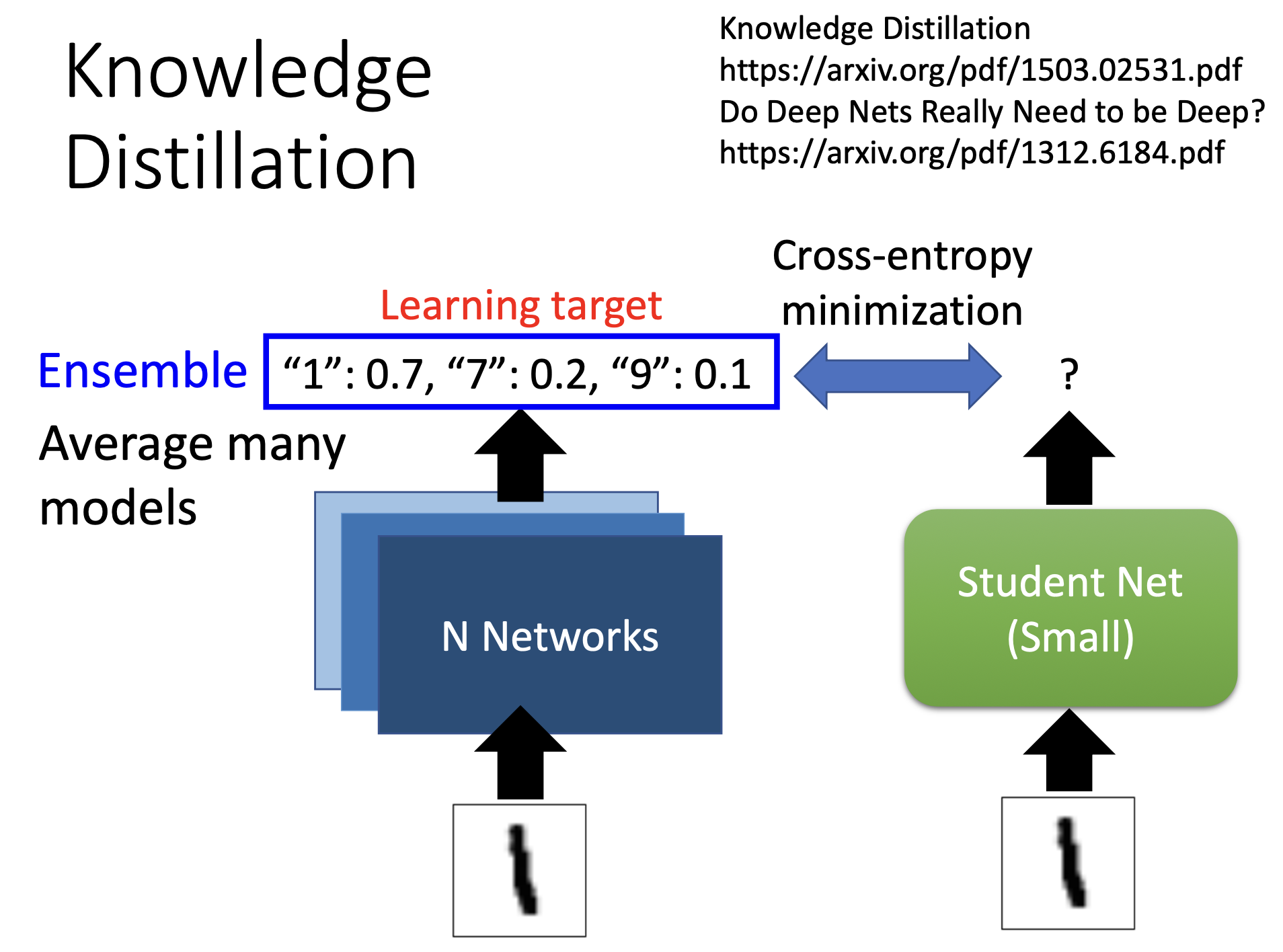
Knowledge Distillation
训练过程
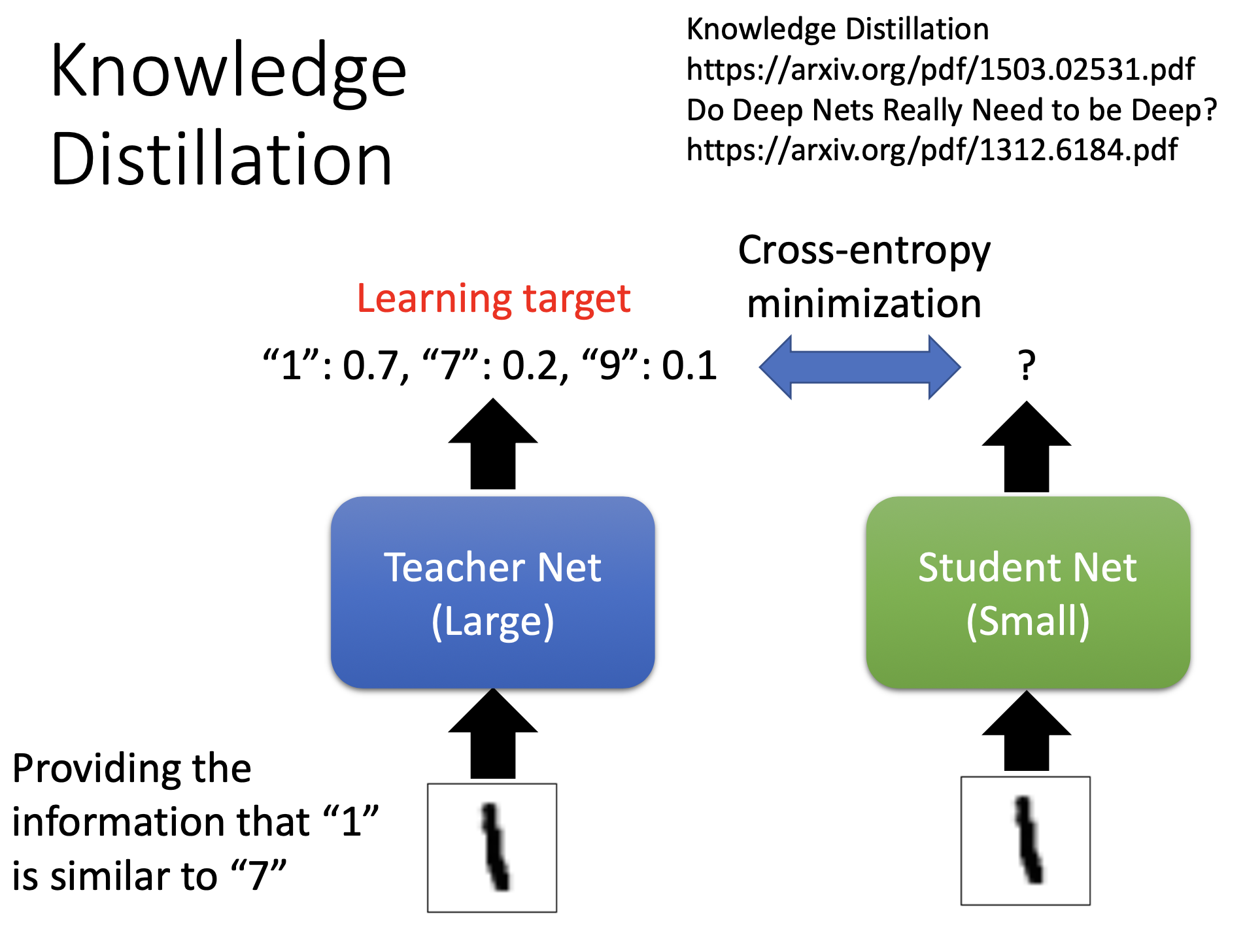
先train大network,小的network再根据大的network来学习。
以识别手写数字为例
teacher:输入图片后输出分布
student:输入跟老师一样的图片,不看正确答案,只跟老师的输出做cross-entropy。
ps:如果老师输出错了,学错了就学错了。
工作原理解释
从teacher那里能学习到额外的知识,比如1和7,1和9是比较相似的。如果让student直接分辨1和7可能太难了,先从老师那里学习,以后看到这张图就知道输出1而不是7。
仅仅是靠teacher告诉student1和7有什么关系,student就能在没看到某些数字的情况下学会该数字。比如student完全没看过7长什么样,但是teacher告诉student1和7的关系,student就有可能学到7
student学习多个network ensemble后的结果
训练技巧
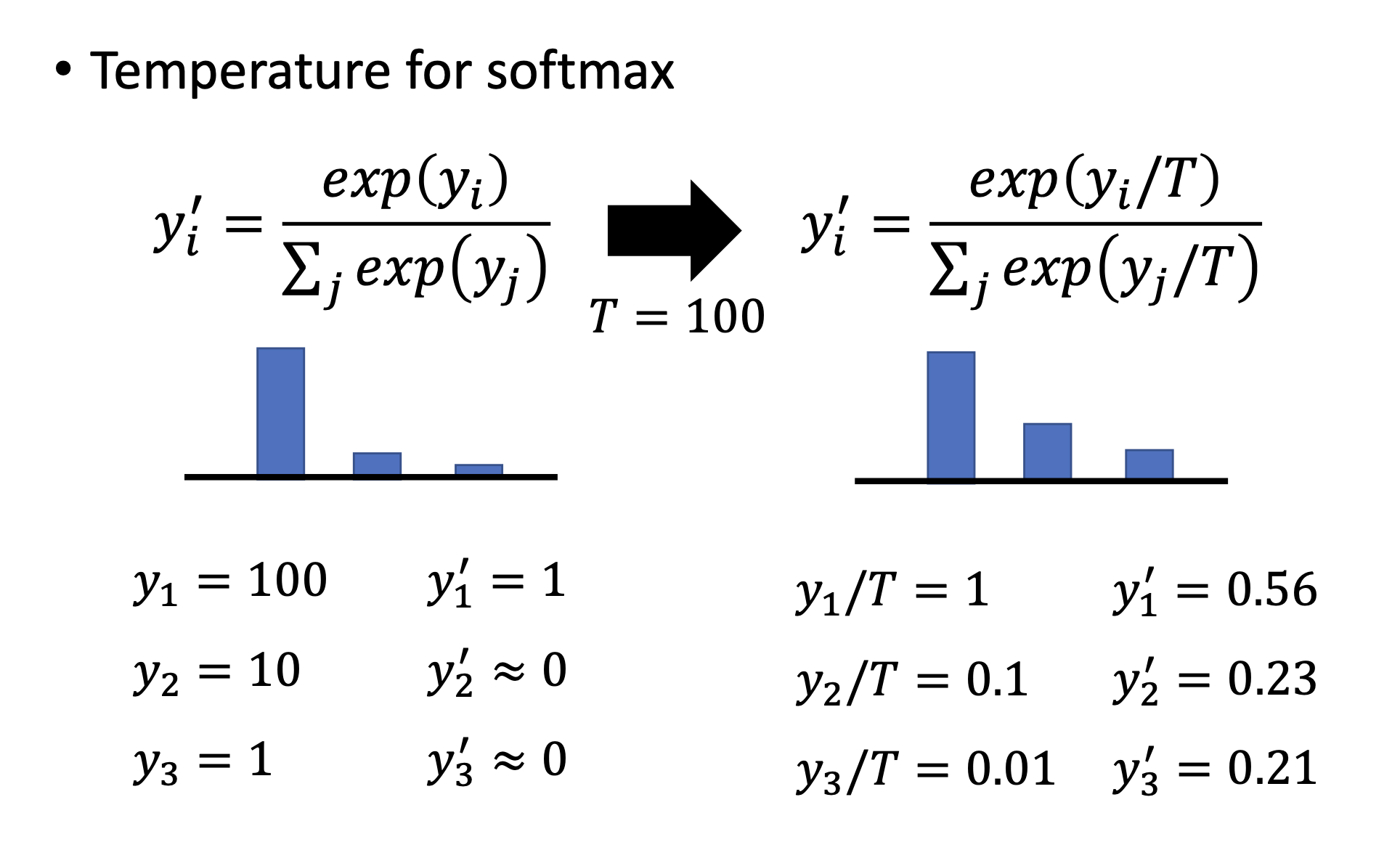
如果只用softmax不做其他修改,那么算出来的结果就像下图左边一样,基本是1或者0,那跟看正确答案没有区别,student 不能学到两个相似的数字之间的关系。
所以要加入tempeerature,使得分布变得平滑
T也是一个hyperparameter,设得太大也不行,这样所有输出都接近于0了。
Parameter Quantization
特点
可以使用更少的存储空间
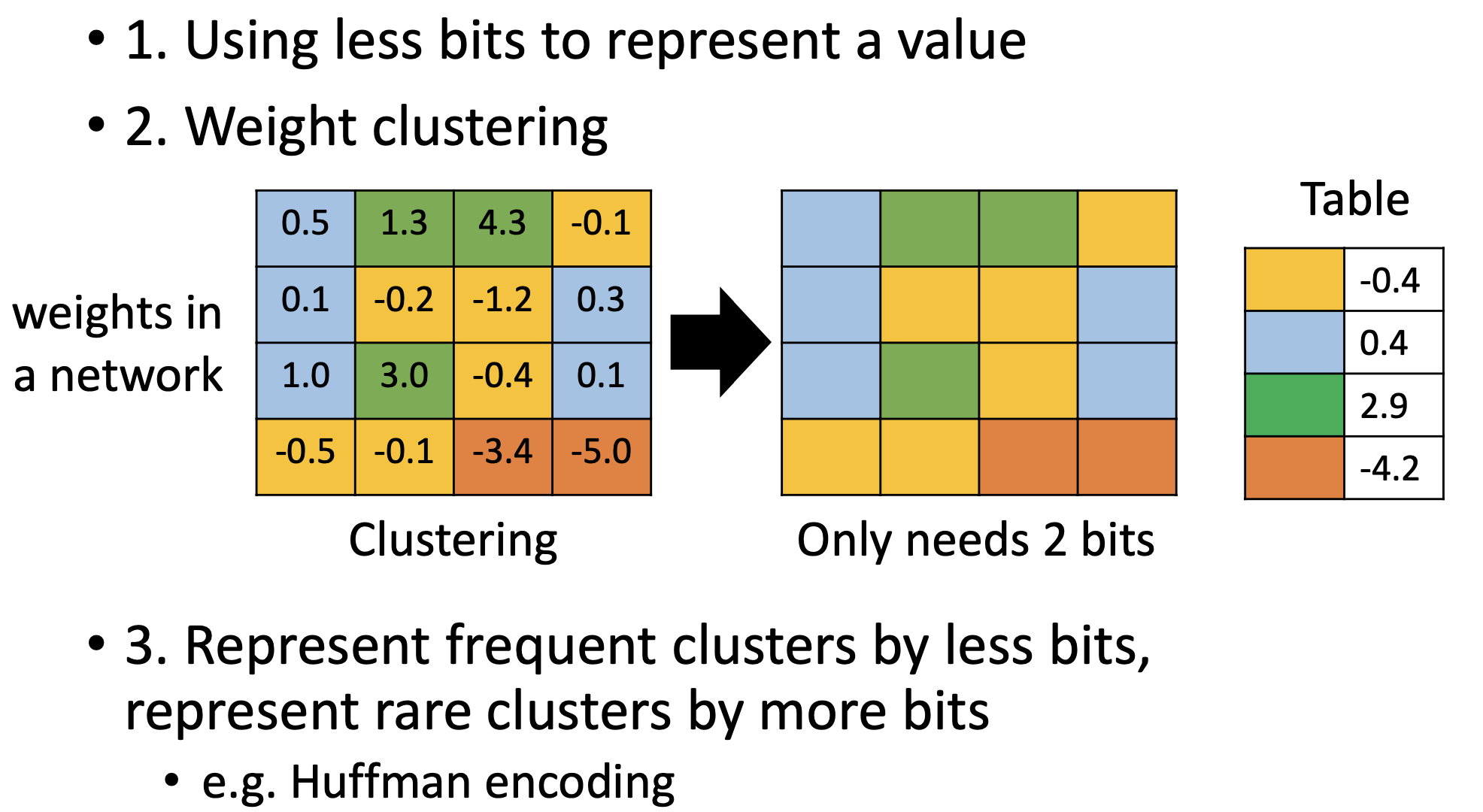
原理
对network中的weights做clustering,把相似的放在一组里,从这一组里选出一个代表(取平均),形成一个table。这样就只用存储这个table和每个参数属于哪个群。
甚至可以全用1或者-1来代表
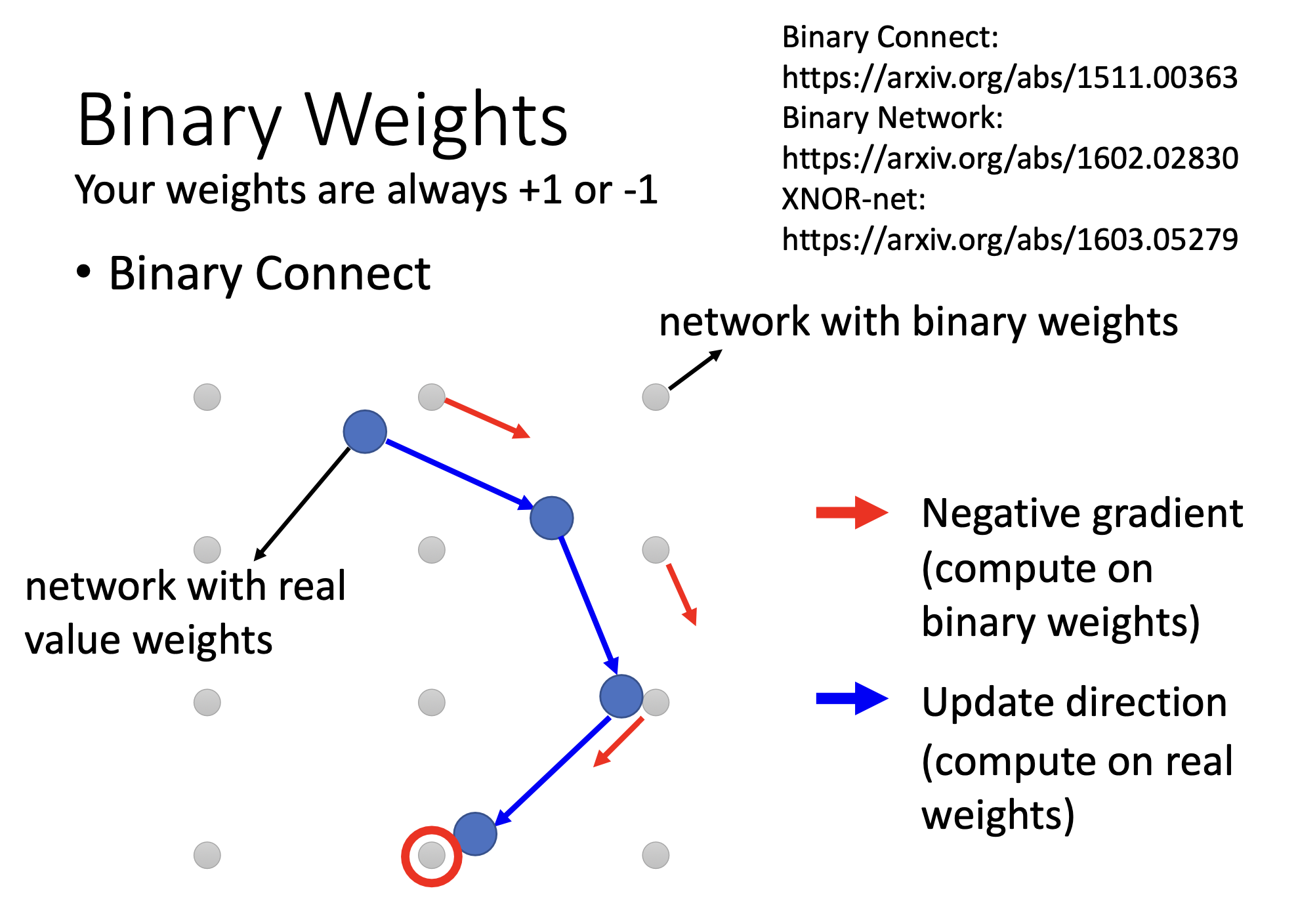
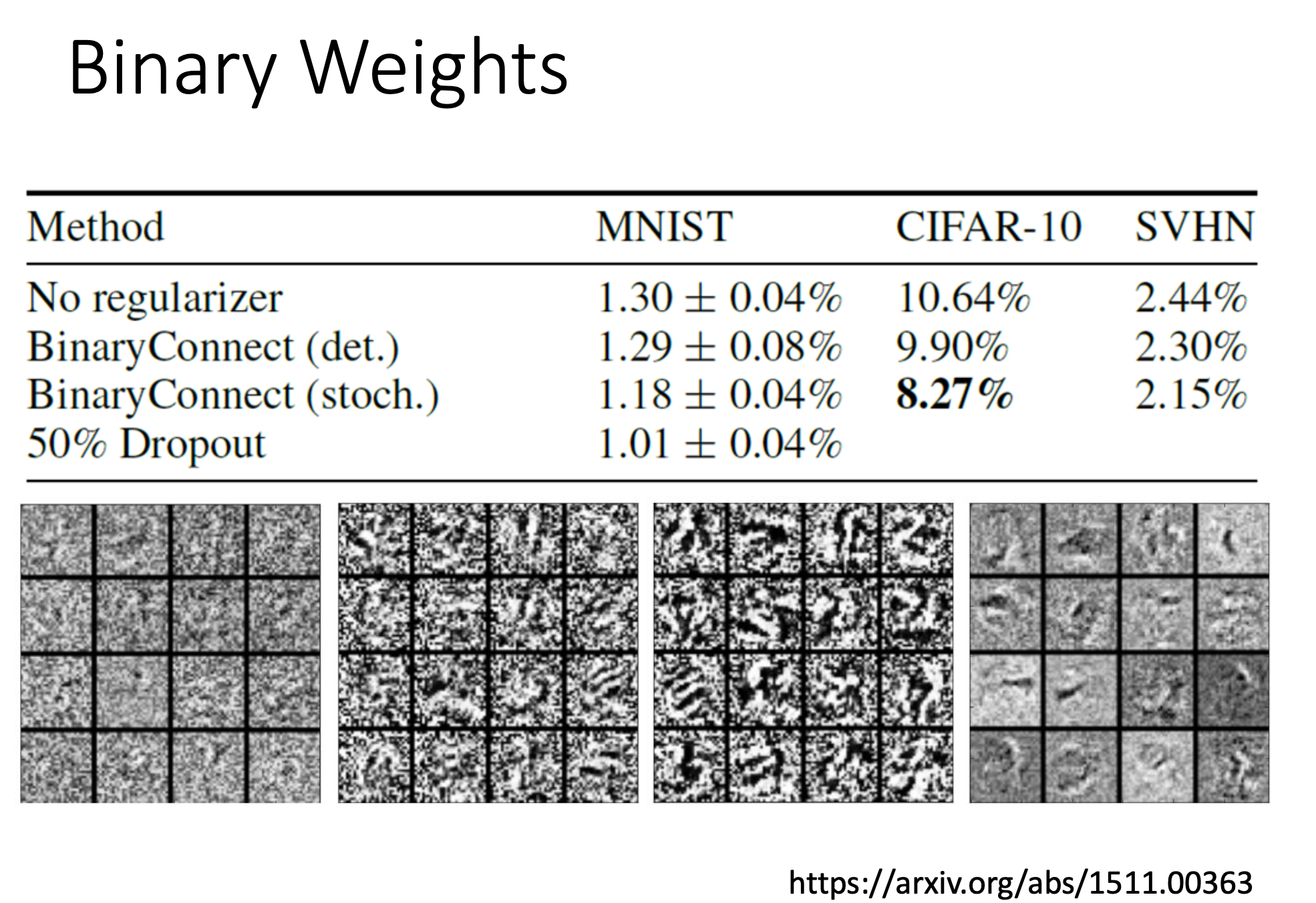
binary connect 的实验结果
参数全是-1或者全是1甚至比没用binary connect 错误率还低。
一种解释是如果设置参数全是-1或者1,给了模型比较大的限制,就不容易overfitting。
Architecture Design
通过network架构的设计减少参数量。
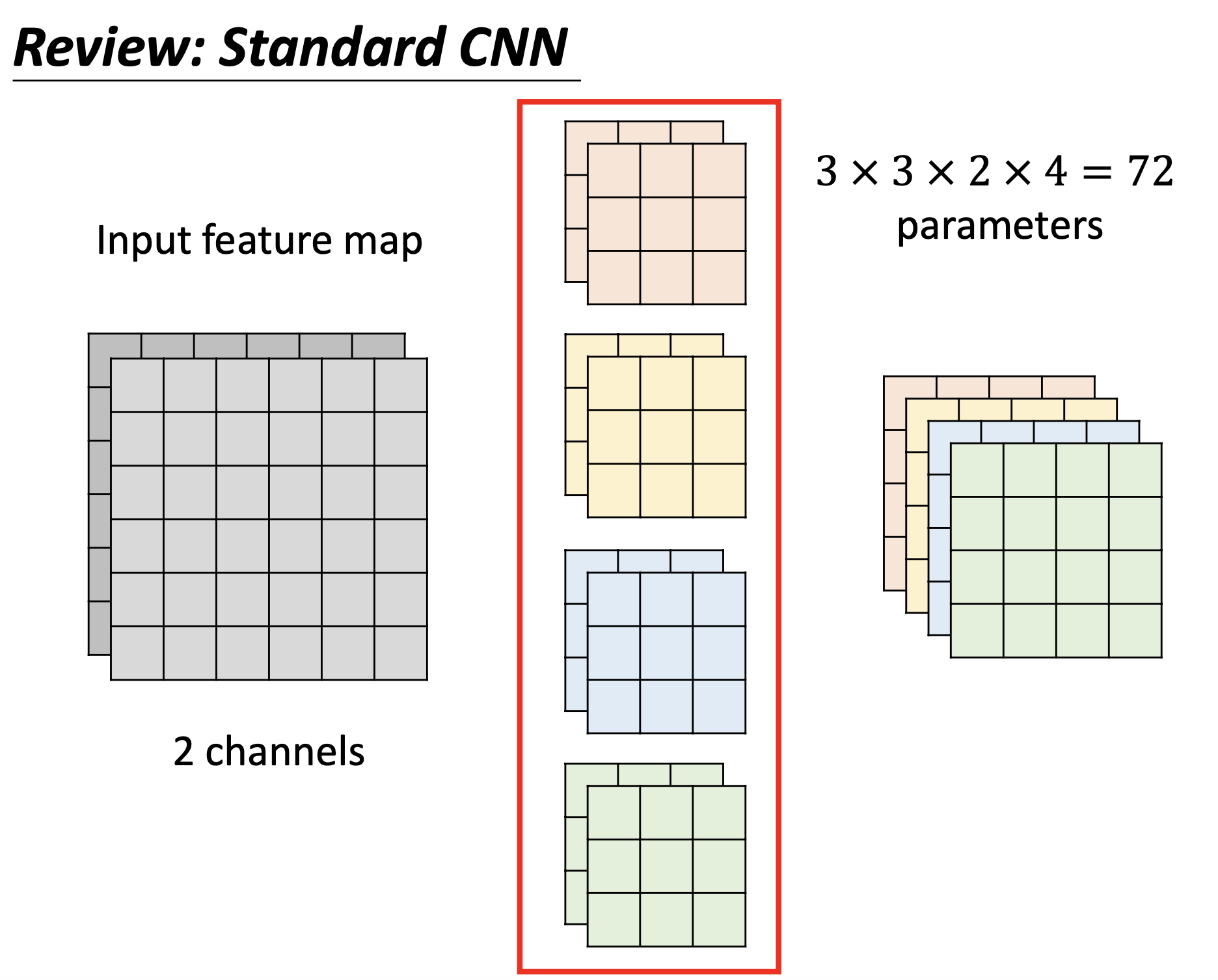
Review: Standard CNN
4个filter,feature map就有4个channel。
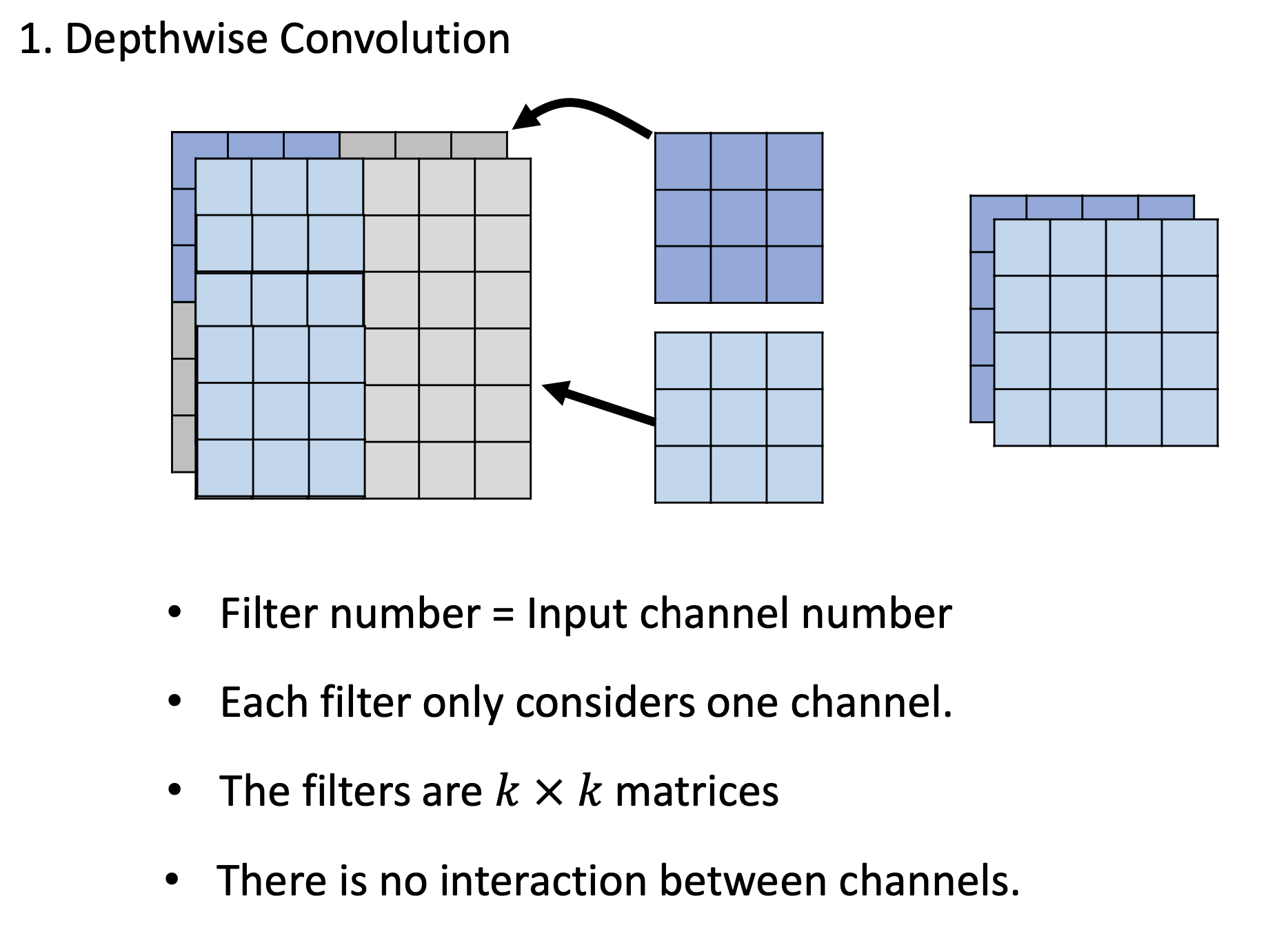
Depthwise Separable Convolution
一个filter只管一个channel。所以输入和输出的channel 是一样的(与传统CNN不同)
Depthwise Convolution
Pointwise Convolution
pointwise convolution的filter是1*1的,而且输入和输出channels可以不一样(跟传统CNN相似)
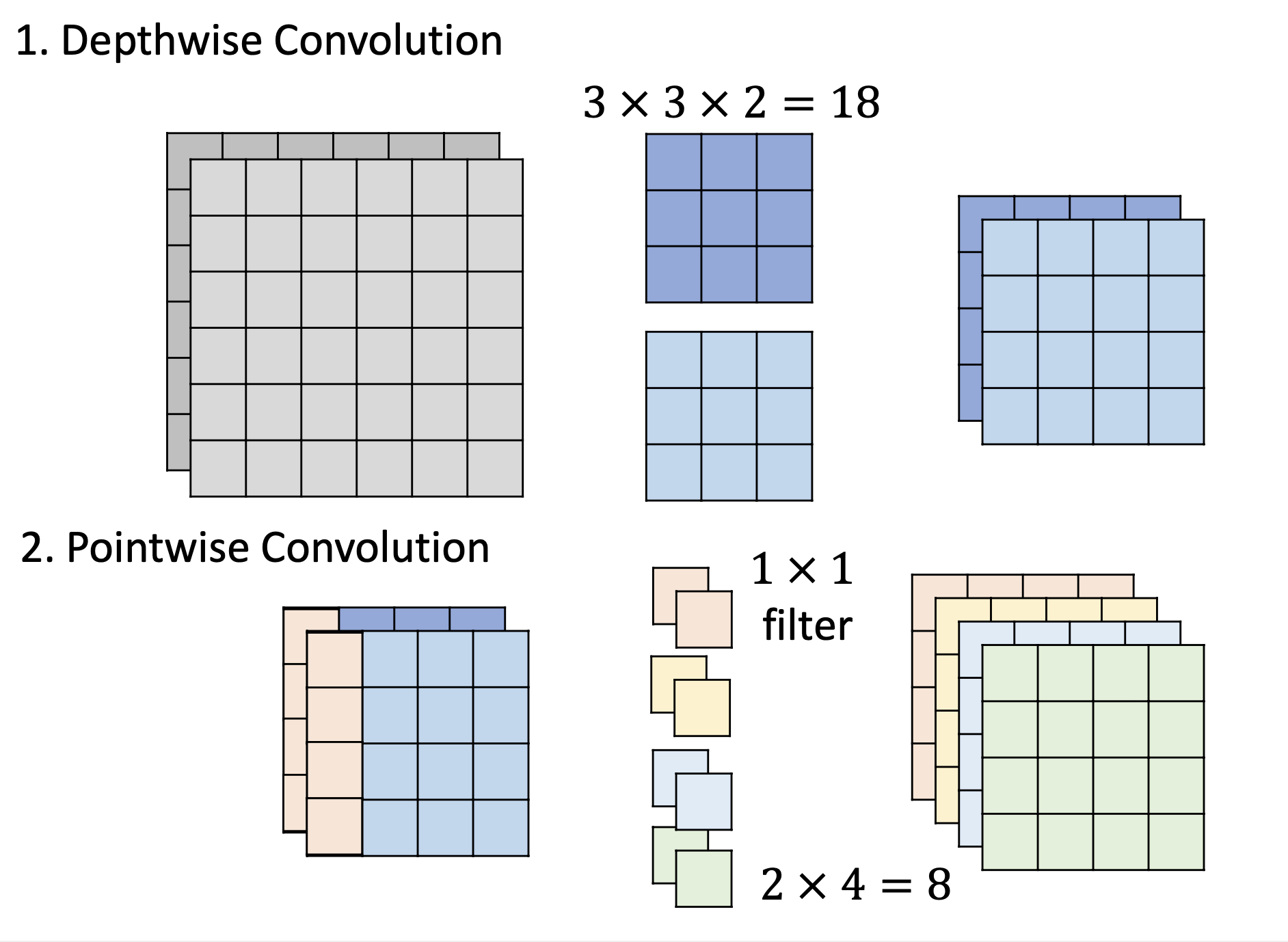
depthwise separable convolution与传统CNN网络架构参数的对比
左边是传统CNN,右边是depthwise separable convolution
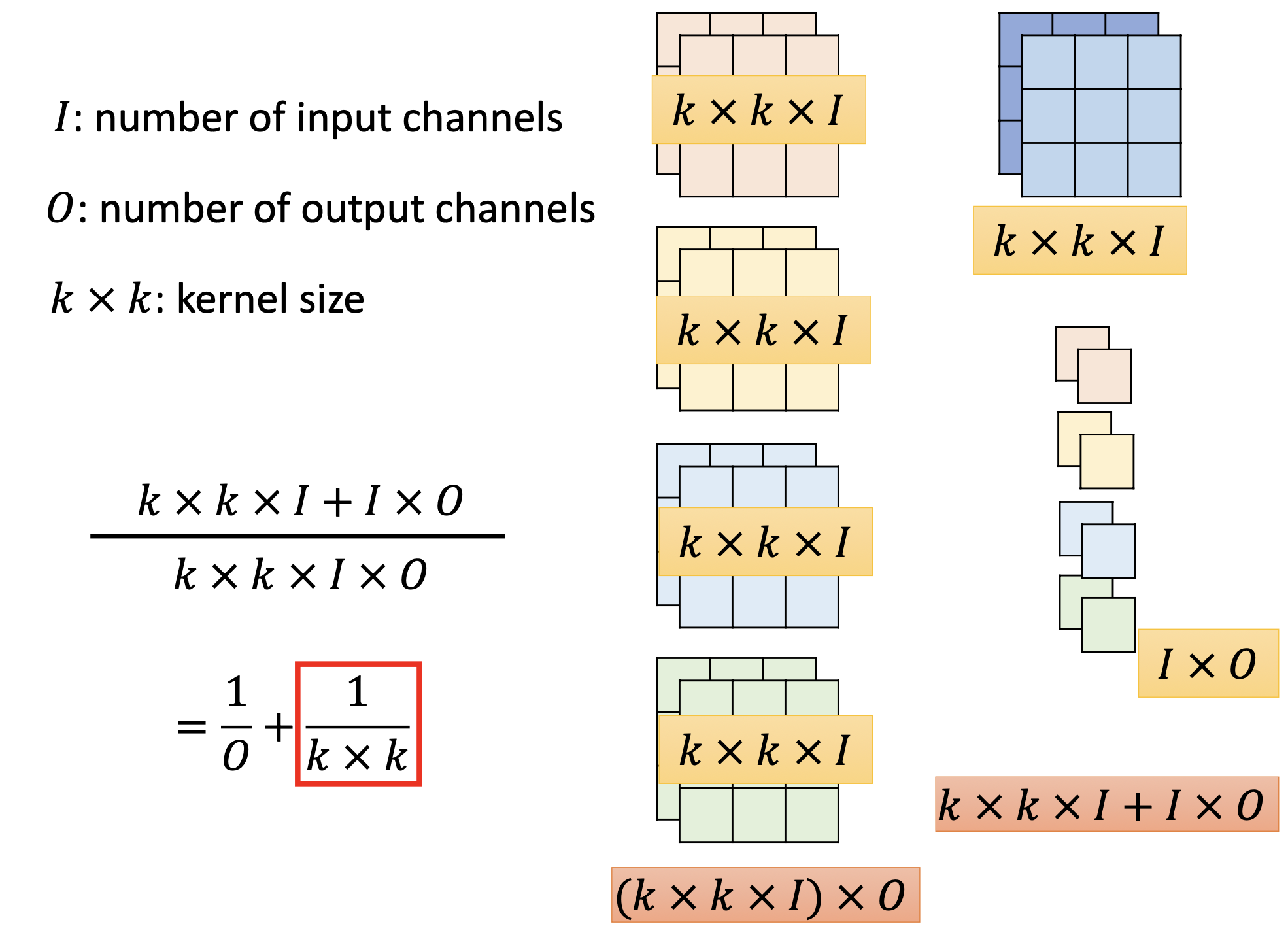
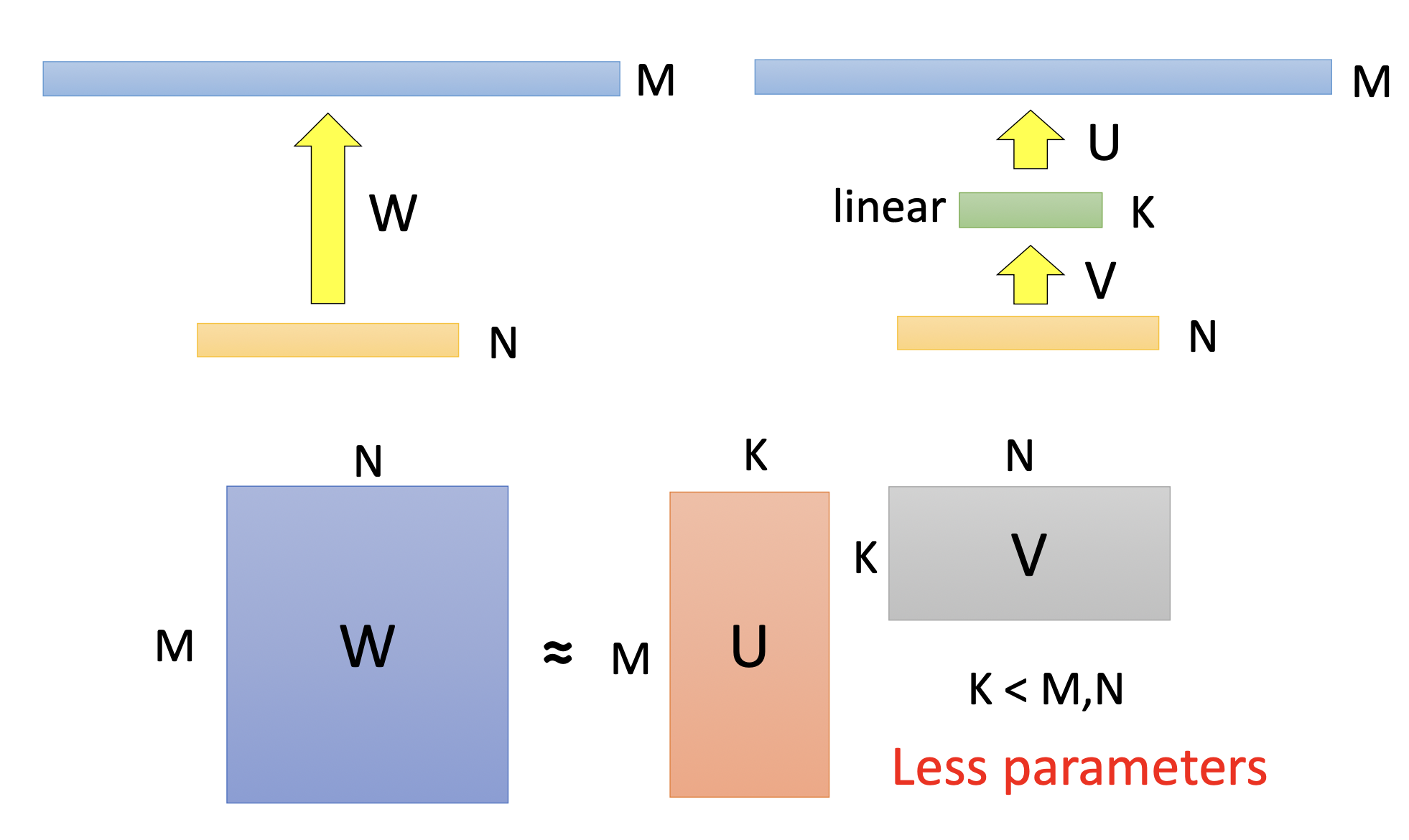
Low rank approximation
中间加一层conv layer,反而总的参数量变少。
原来是MN,现在是MK+N*K,只要K小点,就能比原来的参数量少。
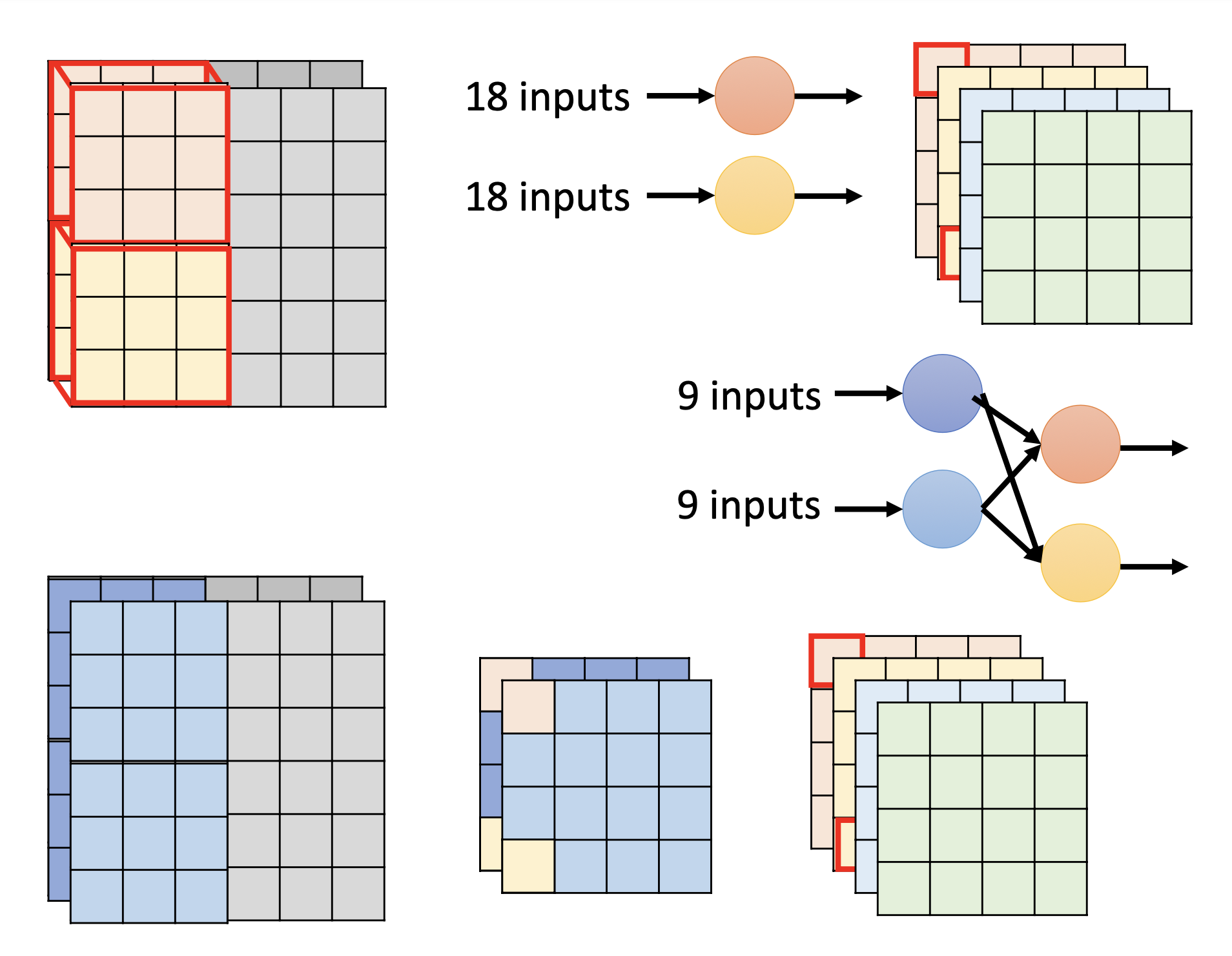
具体过程
Dynamic Computation
训练好的network可以放在不同的设备上或者同一个设备上电量不同,根据运算资源不同自动调整运算量。
为什么不训练一套models以应对不同要求呢?存储空间有限。

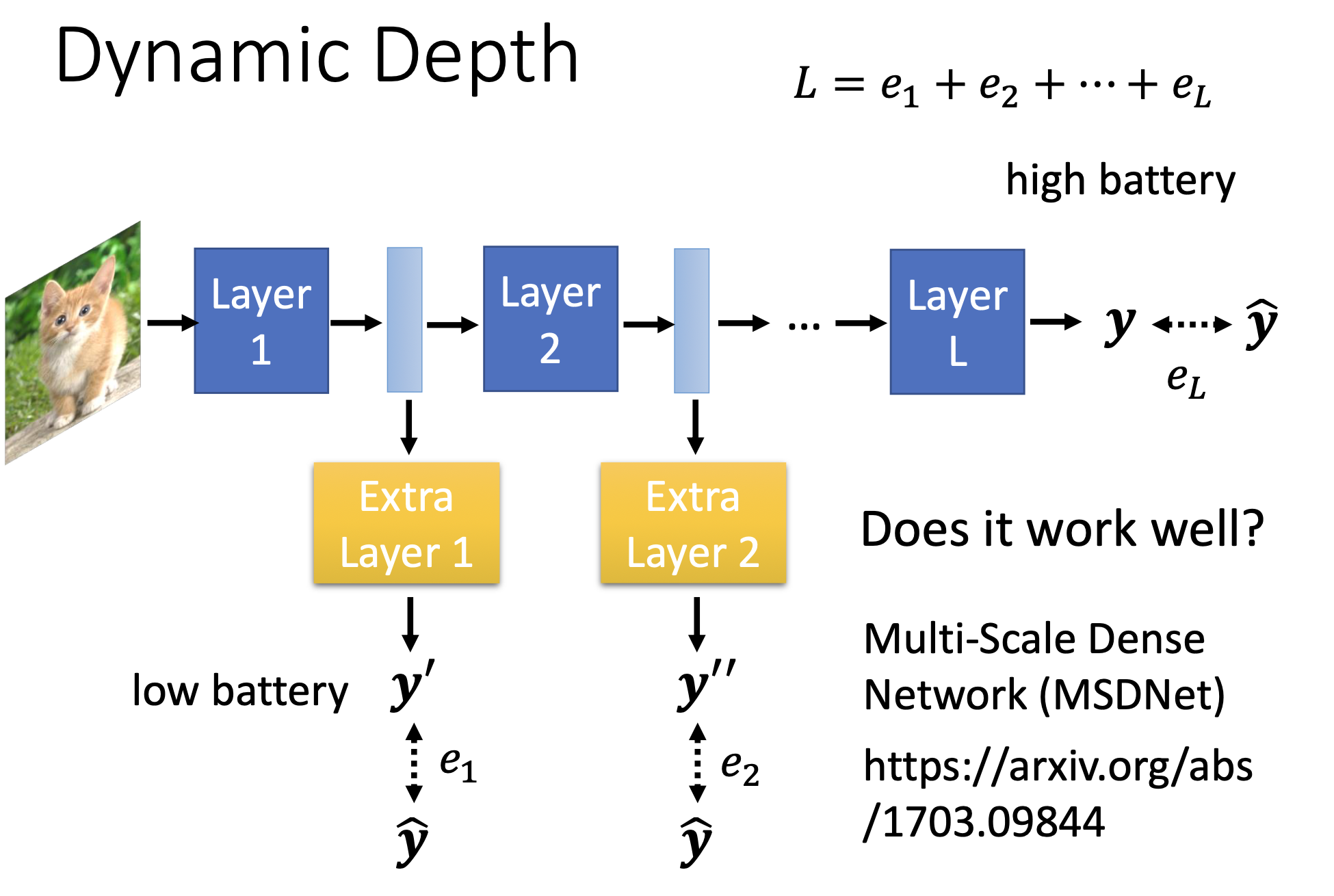
Dynamic Depth
在每层layer结束之后增加一个extra layer,如果低电量或者计算资源较少的情况下,可以在layer1之后就从extra layer 1 输出,不用再走layer2;如果在运算资源充足的时候就跑完。
训练时min( L )=e1+e2+…+el
e1…l是每层与ground truth 的cross entropy
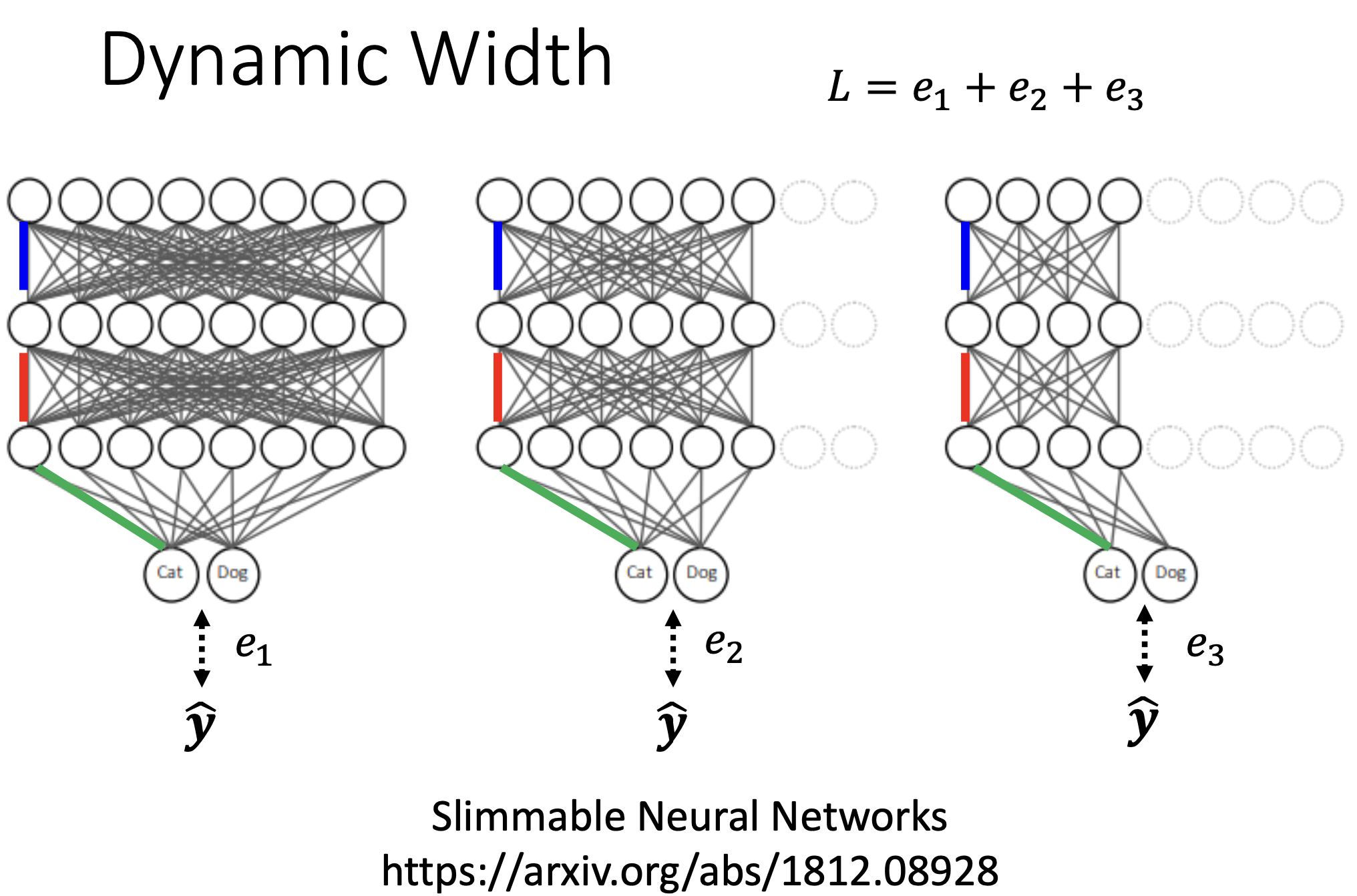
Dynamic Width
下面三个是同一个network,相同颜色表示相同的weight。
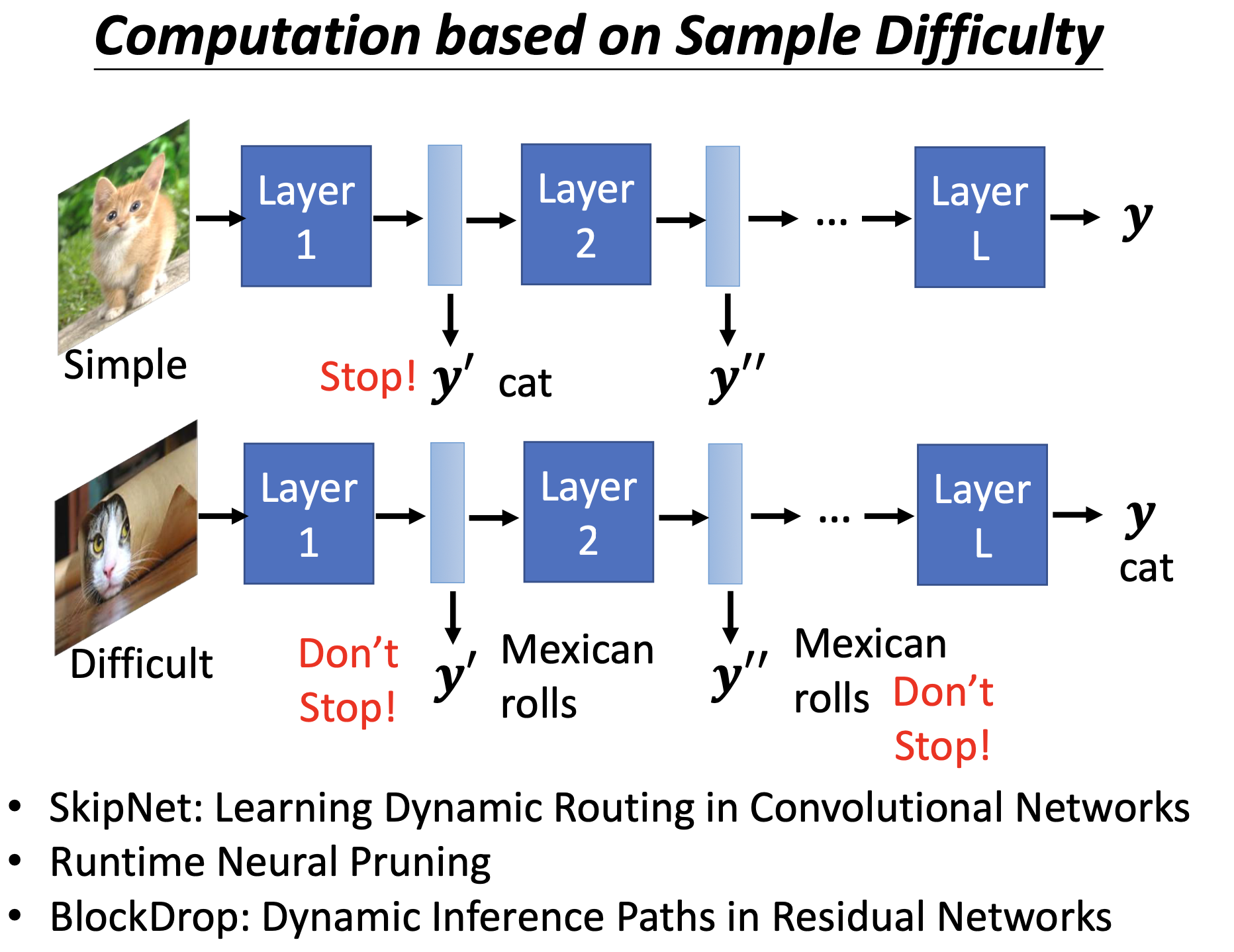
Computation based on Sample Difficulty
对于训练样本不同的困难性有不同的计算量。
总结
这些技术不是互斥的,是可以同时使用的。

















 926
926











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











