







目录
摘要
SegFormer是一种基于Vision Transformer演变而来的语义分割模型,通过引入分层Transformer编码器、重叠Patch Merging操作和轻量级全MLP解码器,解决了ViT在语义分割任务中计算复杂度高、内存消耗大以及细节信息丢失的问题。该模型在ADE20K、Cityscapes和COCO-Stuff等多个数据集上取得了领先的性能,同时具有结构简单、计算高效和泛化能力强的优势,为基于Transformer的密集预测任务提供了新的解决方案。
Abstract
SegFormer is a semantic segmentation model evolved from the Vision Transformer (ViT). By introducing a hierarchical Transformer encoder, overlapping Patch Merging, and a lightweight all-MLP decoder, it addresses issues such as high computational complexity, significant memory consumption, and loss of detailed information in ViT for semantic segmentation tasks. The model has achieved leading performance on multiple datasets, including ADE20K, Cityscapes, and COCO-Stuff, while offering advantages such as a simple structure, computational efficiency, and strong generalization capabilities. It provides a new solution for Transformer-based dense prediction tasks.
SegFormer
论文链接:[2105.15203] SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers
代码:GitHub - NVlabs/SegFormer: Official PyTorch implementation of SegFormer
SegFormer网络结构图如下所示:
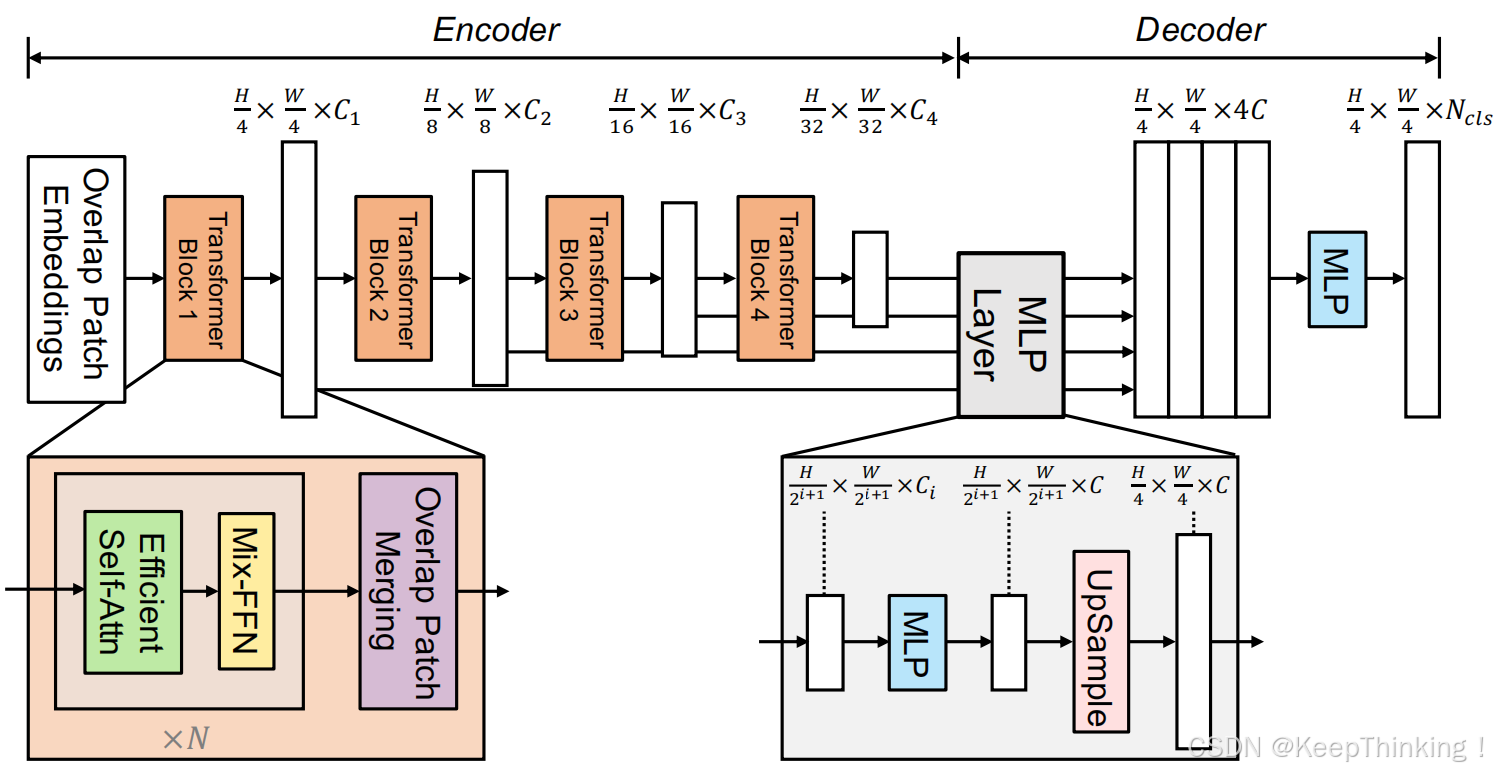
SegFormer主要由Transformer的编码器和轻量级的MLP的解码器组成。
网络特点:
1、结合了Transformers与轻量级的MLP解码器;
2、包含一个新颖的分层结构的Transformer编码器,该编码器输出多尺度特征。它不需要位置编码, 因此避免了位置编码的插值,但在测试分辨率与训练时不同的情况下可能会导致性能下降;
3、避免使用复杂的解码器。提议的MLP解码器从不同的层中聚合信息,从而同时结合了局部注意力和全局注意力来呈现强大的表示;
4、设计非常简单和轻量级,这是在Transformers上实现高效分割的关键;
5、SegFormer系列模型从SegFormer-B0到SegFormer-B5有多个版本,与之前的模型相比,它们的性能和效率都有显著的提高。
EnCoder
Overlap Patch Embeddings:通过2D卷积操作将图像分为4块,并将其嵌入到指定的维度的模块,通过Hierarchical Feature Representation这种方式,编码器可以同时提供高分辨率的粗糙特征和低分辨率的精细特征,从而更好地捕捉不同尺度的上下文信息。
#block1 对输入图像进行分区,并下采样512, 512, 3 => 128, 128, 32 => 16384, 32
self.patch_embed1 = OverlapPatchEmbed(patch_size=7, stride=4, in_chans=in_chans, embed_dim=embed_dims[0])
#block2对输入图像进行分区,并下采样,128, 128, 32 => 64, 64, 64 => 4096, 64
self.patch_embed2 = OverlapPatchEmbed(patch_size=3, stride=2, in_chans=embed_dims[0], embed_dim=embed_dims[1])
#block3对输入图像进行分区,并下采样 64, 64, 64 => 32, 32, 160 => 1024, 160
self.patch_embed3 = OverlapPatchEmbed(patch_size=3, stride=2, in_chans=embed_dims[1], embed_dim=embed_dims[2])
#block4对输入图像进行分区,并下采样32, 32, 160 => 16, 16, 256 => 256, 256
self.patch_embed4 = OverlapPatchEmbed(patch_size=3, stride=2, in_chans=embed_dims[2], embed_dim=embed_dims[3])Efficient self-attention:Attention注意力机制:Encoder 中计算量最大的就是 self-attention 模块进行特征提取。
self.attn = Attention(
dim, num_heads=num_heads, qkv_bias=qkv_bias, qk_scale=qk_scale,
attn_drop=attn_drop, proj_drop=drop, sr_ratio=sr_ratio
)Mix FNN:在 FNN 中使用了 3 x 3 的卷积和 MLP ,作者认为 position encoding 来引入局部位置信息在语义分割中是不需要的,所以引入了一个 Mix-FFN,
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1711
1711

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









