







PyTorch以及VGG模型
PyTorch
- PyTorch是一个开源的Python机器学习库,基于Torch,用于自然语言处理等应用程序。
- 它是一个基于Python的可续计算包,提供两个高级功能:
1、具有强大的GPU加速的张量计算(如NumPy)
2、包含自动求导系统(自动微分机制)的深度神经网络
张量(Tensor)
- 张量(Tensor),类似于数组和矩阵, 是一种特殊的数据结构。在PyTorch中, 神经网络的输入、输出以及网络的参数等数据, 都是使用张量来进行描述。
- 张量的初始化:
- 由原始数据直接生成
- Numpy与Tensor的相互转换生成
- 根据已有的张量来生成
- 通过指定数据的维度生成
代码如下:
import torch
# 由原始数据直接生成
data = {
[1, 2], [3, 4]}
data_t = torch.tensor(data)
# Numpy与Tensor的相互转换生成
# 1. Tensor转化为Numpy
ten_data = torch.ones(3)
num_data = t.numpy()
# 2. Numpy转化为Tensor
num_data1 = np.ones(3)
ten_data = torch.from_numpy(n)
# 根据已有的张量来生成
data_t1 = torch.ones_like(data_t) # 保留data_t的属性
data_new = torch.rand_like(data_t, dtype=torch.float) # 改变data_t的数据类型(int——>float)
# 通过指定数据的维度生成
data_shape = (2,3,)
rand_ten = torch.rand(data_shape)
ones_ten = torch.ones(data_shape)
zeros_ten = torch.zeros(data_shape)
- 张量属性:
- 维度 tensor.shape
- 数据类型 tensor.dtype
- 所存储的设备 tensor.device
- 张量的计算在GPU上进行操作的方法
# 首先判断当前环境GPU是否可用, 如果可以将tensor导入GPU内运行
if torch.cuda.is_available():
tensor = tensor.to('cuda')
- 张量的计算:(tensor = torch.ones(4, 4))
-
索引和切片:tensor[ a : b(行索引), c : d (列索引)]
-
连接:torch.cat([tensor, tensor], dim=1)
-
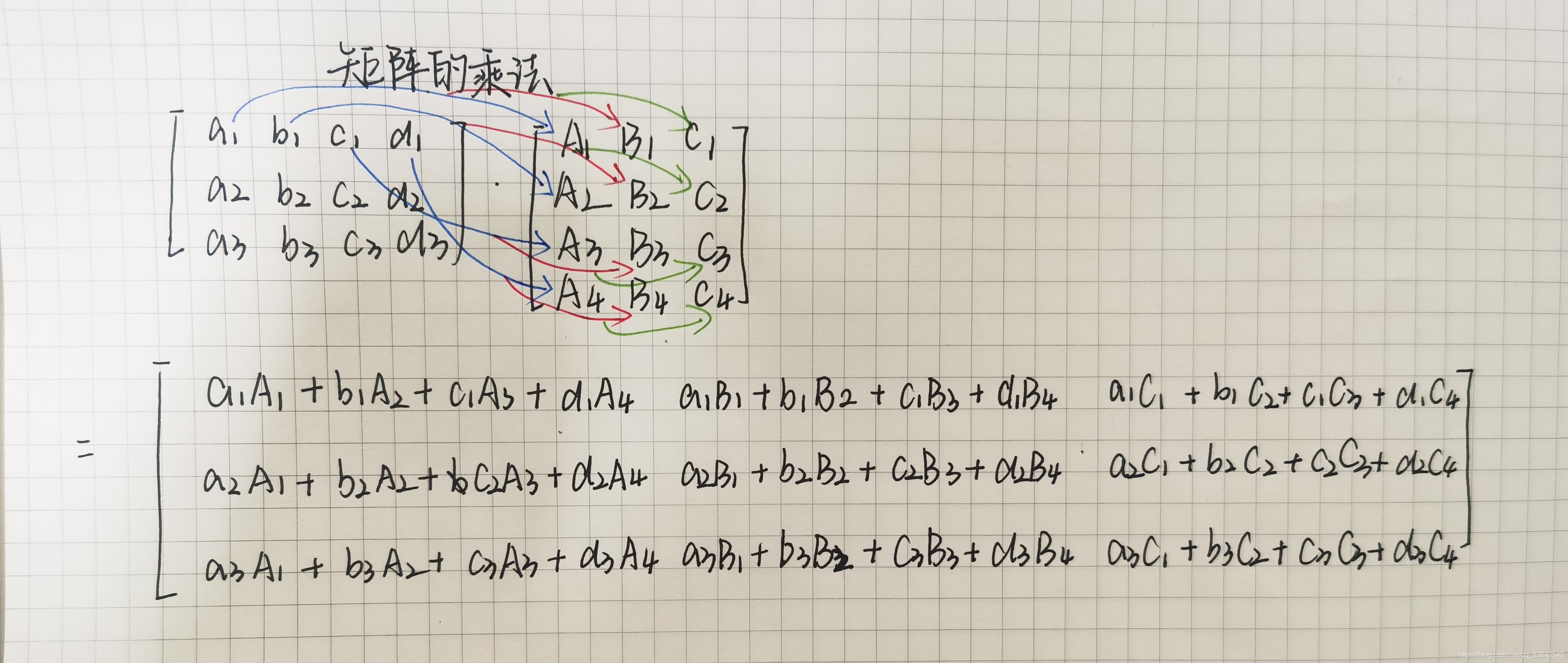
矩阵的乘法:
- y1 = tensor @ tensor,T
- y2 = tensor.matmul(tensor.T)
- y3 = torch.rand_like(tensor)
torch.matmul(tensor, tensor.T, out=y3)
-
矩阵按元素进行乘积:
- z1 = tensor * tensor
- z2 = tensor.mul(tensor)
- z3 = torch.rand_like(tensor)
torch.mul(tensor, tensor, out=z3)
-
就地运算(将结果存储到操作数中的运算称为就地运算):
以‘ _ ’后缀表示 -
单元素张量转换:
t_sum = tensor.sum()
t_item = t_sum.item()
-
数据集和数据加载器(DATASETS & DATALOADERS)
- 引言:用于处理数据样本的代码有时会很凌乱并且难以维护;在理想的情况下,我们希望能够将数据集代码与模型训练代码分离,以提高可读性和模块化性。
- PyTorch本身提供了两种数据原语(data primitives)
(补充说明–原语:原语是在操作系统中调用核心层子程序的指令;一般是指由若干条指令组成的程序段,用来实现某个特定功能,在执行过程中不可被中断。)- torch.utils.data.DataLoader
- torch.utils.data.Dataset
未完待续
VGG模型
PyTorch版(加载cifar10数据集)
cifar10数据集

基本说明:CIFAR10包含了 10 个类别的 RGB 彩色图片,分别为:飞机(airplane)、汽车(automobile)、鸟类(bird )、猫(cat)、鹿(deer)、狗(dog)、蛙类(frog)、马(horse)、船(ship)和卡车(truck);该图像尺寸为32*32大小。
如图所示: data_batch_1-data_batch_5分别包含了5个批次的训练数据,每个批次有10000张训练图片;test_batch包含的是测试数据集,有10000张测试的图片。
加载数据集
''' 定义超参数 '''
batch_size = 256 # 每批数据量的大小
'''
transforms.Compose:将几个变换组合在一起
transforms.Normalize:用均值和标准差归一化张量图像--计算公式:output[channel] = (input[channel] - mean[channel]) / std[channel]
RandomHorizontalFlip:以0.5的概率水平翻转给定的PIL图像
transforms.RandomResizedCrop:将PIL图像裁剪成任意大小和纵横比
transforms.ToTensor:转换一个PIL库的图片或者numpy的数组为tensor张量类型;转换从[0,255]->[0,1]
'''
''' 数据增强 '''
transform = transforms.Compose([
transforms.RandomResizedCrop(32),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize(mean = [ 0.5, 0.5, 0.5 ],
std = [ 0.5, 0.5, 0.5 ]),
])
'''加载训练集 CIFAR-10 10分类训练集'''
train_dataset = datasets.CIFAR10(root=r"D:\TASK\VGG\DATA\datasets", train=True, transform=transform)
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_dataset = datasets.CIFAR10(root=r"D:\TASK\VGG\DATA\datasets", train=False, transform=transform)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)
VGG模型结构
表格示意图:

文字说明:

以VGG16为例由上图可知:在卷积中,卷积核的大小为33,步长为1,padding为1;在池化中,共有五个最大池化,池化窗口为22,步长为2
代码如下:
from torch import nn
class VGG(nn.Module):
def __init__(self,num_classes=1000):
'''
# VGG16继承父类nn.Moudle,即把VGG16的对象self转换成nn.Moudle的对象
# nn.Sequential()是nn.module()的容器,用于按顺序包装一组网络层
# nn.Conv2d(in_channels, out_channels, kernel_size, stride=1, padding=0)
# nn.Conv2d是二维卷积方法,nn.Conv2d一般用于二维图像;nn.Conv1d是一维卷积方法,常用于文本数据的处理
'''
super(VGG, self).__init__()
self.features=nn.Sequential(
# 第1层卷积 3-->64
nn.Conv2d(3,64,kernel_size=3,padding=1),
nn.BatchNorm2d(64), # 批归一化操作,为了加速神经网络的收敛过程以及提高训练过程中的稳定性,用于防止梯度消失或梯度爆炸;参数为卷积后输出的通道数;
nn.ReLU(True),
# 第2层卷积 64-->64
nn.Conv2d(64,64,kernel_size=3,padding=1),
nn.BatchNorm2d(64),
nn.ReLU(True),
# 第3层池化 图像大小缩小1/2
nn.MaxPool2d(kernel_size=2,stride=2),
# 第4层卷积 64-->128
nn.Conv2d(64, 128, kernel_size=3, padding=1),
nn.BatchNorm2d(128),
nn.ReLU(True),
# 第5层卷积 128-->128
nn.Conv2d(128,128,kernel_size=3,padding=1),
nn.BatchNorm2d(128),
nn.ReLU(True),
# 第6层池化 图像大小缩小1/2
nn.MaxPool2d(kernel_size=2, stride=2),
# 第7层卷积 128-->256
nn.Conv2d(128,256,kernel_size=3,padding=1),
nn.BatchNorm2d(256),
nn.ReLU(True),
# 第8层卷积 256-->256
nn.Conv2d(256,256,kernel_size=3,padding=1),
nn.BatchNorm2d(256),
nn.ReLU(True),
# 第9层卷积 256-->256
nn.Conv2d(256, 256, kernel_size=3, padding 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 485
485











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









