







《HE-Drive:Human-Like End-To-End Driving With Vision Language Models》2024年10月发表,来自地平线、香港大学、中科院大学和北京交大的论文。
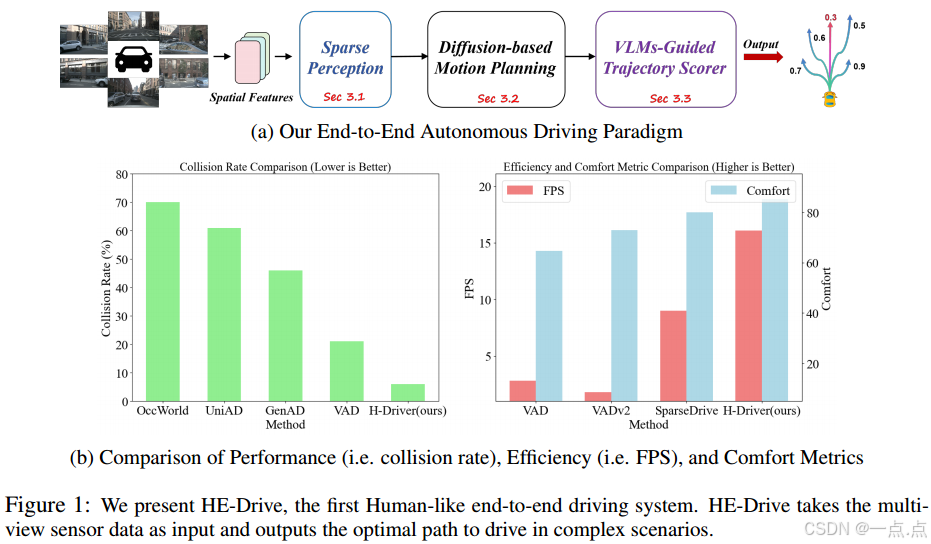
在这篇论文中,我们提出了HE Drive:第一个以人类为中心的端到端自动驾驶系统,可以生成时间一致且舒适的轨迹。最近的研究表明,基于模仿学习的规划者和基于学习的轨迹评分者可以有效地生成和选择接近专家演示的精确轨迹。然而,这些轨迹规划者和记分员面临着生成时间不一致和不舒服的轨迹的困境。为了解决上述问题,我们的HE Drive首先通过稀疏感知提取关键的3D空间表示,然后将其作为基于条件去噪扩散概率模型(DDPM)的运动规划器的条件输入,以生成时间一致性的多模态轨迹。视觉语言模型(VLM)引导的轨迹评分器随后从这些候选者中选择最舒适的轨迹来控制车辆,确保像人一样的端到端驾驶。实验表明,HE Drive不仅在具有挑战性的nuScenes和OpenScene数据集上实现了最先进的性能(即比VAD将平均碰撞率降低71%)和效率(即比SparseDrive快1.9倍),而且在现实世界数据上提供了最舒适的驾驶体验。
研究背景与问题
-
核心问题:现有端到端自动驾驶系统在轨迹规划中存在时间不一致性(连续预测不稳定)和不舒适性(急刹、转向过度)的缺陷。
-
原因分析:
-
时间不一致性:传统模仿学习规划器依赖单帧历史信息,忽视连续预测的关联性,且受限于专家轨迹质量,泛化能力不足。
-
不舒适性:规则评分器泛化性差,学习评分器在闭环场景中表现不佳,缺乏统一的舒适度度量标准。
-
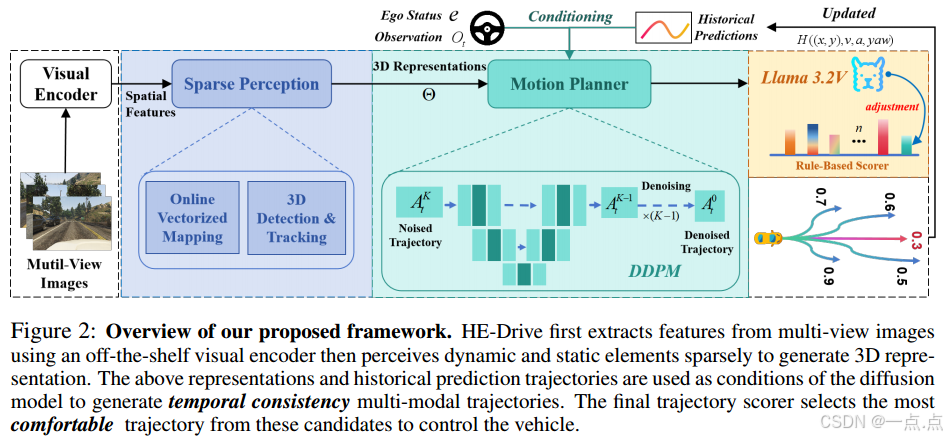
方法创新
HE-Drive系统由三个核心组件构成:
-
稀疏感知模块
-
输入多视角图像,通过视觉编码器提取特征,生成紧凑的3D场景表示(包含动态与静态元素),为后续模块提供空间上下文。
-
基于SparseDrive的稀疏感知方法,提升计算效率。
-
-
扩散模型驱动的运动规划器
-
采用条件去噪扩散概率模型(DDPM)生成多模态轨迹,输入条件包括3D场景表示、历史轨迹的速度/加速度/偏航角、自车状态。
-
关键设计:
-
通过FiLM层将条件信息注入U-Net,引导轨迹生成。
-
引入历史轨迹的动态参数(速度、加速度),增强时间一致性。
-
支持多锚点(8个模式)生成,覆盖多样化驾驶决策。
-
-
-
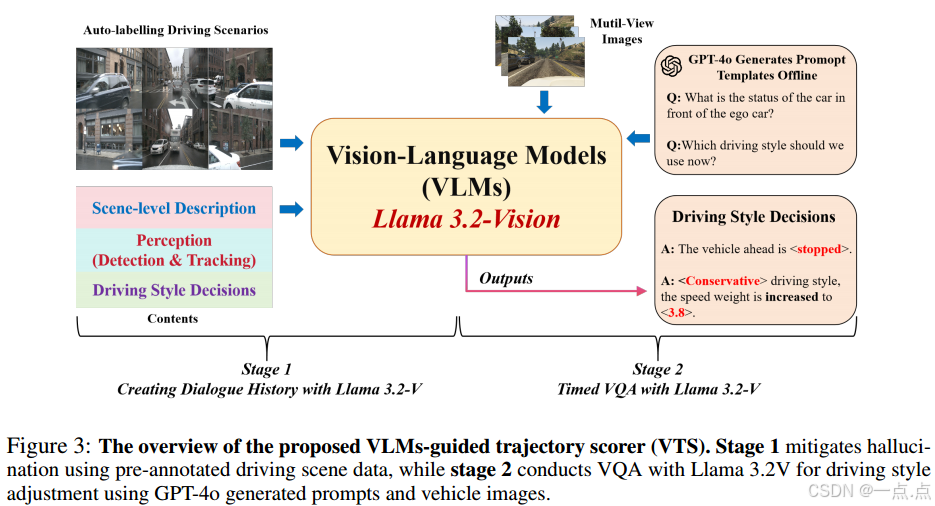
VLM引导的轨迹评分器
-
规则评分器:结合安全成本(碰撞风险、终点距离、航向偏差、速度偏差)与舒适成本(横向/纵向/向心加速度)。
-
VLM动态调整:利用Llama 3.2V分析场景(如天气、交通密度),通过视觉问答(VQA)动态调整规则评分器的权重,实现驾驶风格自适应(激进/保守)。
-
优势:结合规则评分器的可解释性与VLM的泛化能力,避免直接依赖VLM决策导致的幻觉风险。
-
实验与结果
-
数据集:nuScenes(开放环评测)、OpenScene(闭环评测)、真实世界数据。
-
主要结论:
-
性能优势:
-
在nuScenes上,平均L2误差降低17.8%,碰撞率降低68%,效率达16.1 FPS(比SparseDrive快1.2倍)。
-
在OpenScene上,综合评分(安全、舒适、进度)超越基线模型(85.2 vs. 83.0)。
-
-
舒适性提升:真实数据中3秒轨迹舒适度提升32%,1秒轨迹舒适度达100%。
-
消融实验:
-
VLM的引入使3秒碰撞率降低2.6倍。
-
历史轨迹动态参数(速度/加速度)显著提升时间一致性。
-
多锚点(8个模式)生成效果最优。
-
-
贡献总结
-
扩散运动规划器:首次将DDPM用于自动驾驶轨迹生成,解决时间不一致性问题。
-
可插拔轨迹评分器:结合规则与VLM,实现终身评估与风格自适应。
-
通用舒适度量:提出基于加速度、转向率、曲率的量化指标,支持跨场景比较。
局限与未来方向
-
计算开销:扩散模型的迭代去噪可能增加实时性负担(需依赖DDIM加速)。
-
VLM依赖:需高质量标注数据训练对话模型,场景理解能力受限于VLM的预训练知识。
-
扩展性:未涉及复杂天气(如暴雨)或极端场景的验证。
总结
HE-Drive通过稀疏感知-扩散规划-VLM评分的三阶段框架,在轨迹生成的时间一致性、舒适性、效率上实现了突破,为端到端自动驾驶提供了一种更接近人类驾驶的解决方案。其结合生成模型与语言模型的思路,为多模态决策系统的设计提供了重要参考。
如果此文章对您有所帮助,那就请点个赞吧,收藏+关注 那就更棒啦,十分感谢!!!

















 1417
1417

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









