






1. 盘古大模型的概念
1.1 华为云盘古大模型的发展背景
2006年,深度学习之父Geoffrey Hinton和他的学生采用预训练+微调的逐层训练方法解决了深层神经网络训练中梯度消失问题 (Hinton and Salakhutdinov, 2006),新一轮深度学习的发展浪潮由此开启。在过去十年,基于深度学习的人工智能技术在学术界和工业界各个领域的应用爆发式增长,其研究范式由从早期的“标注数据监督学习”的任务特定模型转变为“无标注数据预训练+标注数据微调”的预训练模型,再到如今的“大规模无标注数据预训练+指令微调+人类对齐”的大模型 (陶建华等, 2023)。
人工智能大模型是指拥有超大规模参数、超强计算资源的机器学习模型。基于深度学习的原理,人工智能大模型利用大量的数据和计算资源训练出具有大量参数(通常在十亿个以上)的神经网络模型。通过不断地调整模型参数,使大模型能够在各种任务中取得最佳表现。人工智能大模型通常具有复杂的结构,如递归神经网络 (RNN)、循环神经网络 (CNN) 和变压器 (Transformer) 等 (梁宏涛等, 2023)。
Bommasani et al (2021) 将人工智能大模型统一命名为基础模型 (Foundation Models),代表着人工智能大模型的构建逐渐朝向通用性发展,解决了传统AI模型的首要挑战。相较于传统的AI模型,基础模型的关键优势在于以下4点:
(1) 解决通用性难题:传统的AI模型面对行业、业务场景很多,人工智能需求正呈现出碎片化、多样化的特点;传统的AI模型从开发、调参、优化、迭代到应用的过程需要投入极高的研发成本与专业人员支持;行业知识与AI技术结合困难,导致实际应用效果不佳。基础模型采用大规模、广泛来源的数据集进行训练,“预训练大模型+下游任务微调”的方案使基础模型具备灵活应对多种非预设任务的能力。通过微调 (通过学习少量的单一领域数据对基础模型进行一定的调整)、零样本学习 (直接应用,无需调整) 等方式,基础模型可以直接在一系列下游任务上使用,大大提升了AI模型的通用性。
(2) 具备自监督学习功能:基础模型具备自监督学习功能,降低对数据标注的依赖,大量无标记数据能够被直接应用。一方面降低了人工成本,解决了人工标注成本高、周期长、准确度不高的问题。另一方面使得小样本训练成为可能,避免开发人员再进行大规模的训练,使用小样本就可以训练自己所需模型,极大降低开发使用成本。
(3) 具有强大的特征学习能力与多模态处理能力:基础模型能够自动从数据中学习复杂的特征表示,无需手动设计特征。同时能够处理多种模态数据,如文本、图像、音频等,并能够理解它们之间的关系。这使得基础模型能够处理大量数据,适应不同规模的数据集。
(4) 模型精度更高:基础模型的参数规模逐年扩大,比传统的AI模型高很多个数量级。研究表明,随着数据规模和模型规模的不断增大,模型精度进一步提升。Kolesnikov et al. (2020) 使用1000个类别共128万张图片和18291个类别共3亿张图片两个数据集分别训练视觉迁移模型Big Transfer,精度是77%和79%。
1.2 华为云盘古大模型的结构
2023年7月7日发布在华为开发者大会2023(Cloud)的盘古大模型3.0是一个完全面向行业的基础模型。盘古大模型3.0包括“5+N+X”三层架构,分别对应L0层、L1层和L2层。
1.2.1 基础大模型-L0层
“5”对应的L0层是类似于GPT3这样的基础通用大模型,L0层提供了包括自然语言、视觉、多模态、预测、科学计算五个基础大模型。
(1) 盘古自然语言处理(NLP)大模型是业界首个超千亿参数的中文预训练大模型,该模型通过对中文词汇、语法、语义等特征的深度分析,持续优化基础模型,打造了业界最强的中文理解和生成能力。盘古NLP大模型采用了Encoder-Decoder架构,兼顾了NLP大模型的理解能力和生成能力,保证了模型在不同系统中的嵌入灵活性。NLP大模型在训练过程中使用了 40TB 的中文文本数据,其中包含大量的通用知识与行业经验,具备领先的语言理解和模型生成能力,并通过行业数据的小样本调优提升模型在场景中的应用性能。在中文语言理解评测基准 CLUE 榜单中,盘古 NLP 大模型在总排行榜及分类、阅读理解单项均排名第一,刷新了三项榜单世界历史纪录。
(2) 盘古CV大模型是基于海量图像和视频数据构建的视觉基础模型,具备高效的图像识别和视频分析能力,适用于多种视觉相关的应用场景,是业界最大的 CV 模型。CV大模型包含 30 亿+参数,首次实现了模型的按需抽取,可以在不同部署场景下抽取出不同大小的模型,动态范围可根据需求覆盖特定的小场景到综合性的复杂大场景。盘古 CV 大模型已成功应用在铁路巡检、国家电力巡检等场景。例如在矿山领域,盘古CV大模型通过5G+AI全景视频拼接综采画面卷,传输到地面,地面工作人员将来可以实现地面控制机器进行采矿,实现矿下无人少人安全作业。
(3) 盘古多模态大模型具备图像和文本的跨模态理解、检索与生成能力,通过跨模态语义关联实现视觉-文本-语音多模态统一表示,采用一个大模型即可灵活支撑图-文-音全场景 AI 应用,能够实现图像生成、图像理解、3D生成和视频生成等功能。
(4) 盘古预测大模型是面向结构化数据的预测模型,通过模型推荐和融合技术两步优化策略,构建图网络架构AI模型。在回归预测、分类、异常检测、时序预测、融合神经网络模型等多个典型场景提供AI技术支撑。盘古预测大模型在多个行业中展现出其强大的应用潜力。在金融领域,盘古预测大模型能够根据历史数据预测企业财务状况,及时发现潜在的异常情况。在气象领域,盘古气象大模型是首个精度超过传统数值预报方法的AI预测模型,同时预测速度也有大幅提升。在铁路领域,盘古铁路大模型能精准识别现网运行的多种货车、故障,无故障图片筛除率高达95%。
(5) 盘古科学计算大模型专注于气象预报、药物研发等科学计算领域,采用AI数据建模、方程求解的方法从海量的数据中提取数理规律,为复杂的科学计算提供高效的计算能力,加速科研和工业生产的进程。其中,盘古药物分子大模型 (Lin et al., 2022) 基于对17亿个已知的药物分子化学结构的学习,在化学无监督学习模式下,实现了结构重构率、合法性、唯一性等指标的全面优化。通过集成靶点发现、虚拟筛选、化合物优化等环节,显著缩短了药物研发的周期并降低了成本。盘古大模型可以帮助研究人员在成千上万的小分子化合物中快速找到可成药的那一个,使得先导药的研发周期从数年缩短至数月,研发成本降低70%。而盘古气象大模型更是突破中长期气象预报难题,不仅预测速度相比传统数值预报提速10000倍以上,而且预测精度超过传统数值预报方法。目前,盘古气象大模型能够提供全球气象秒级预报,其气象预测结果包括位势、湿度、风速、温度、海平面气压等,可以直接应用于多个气象研究细分场景。
1.2.2 行业模型- L1层和L2层
“N”对应的L1层是基础模型与行业数据结合进行混合训练后的行业通用大模型,如盘古金融大模型、盘古矿山大模型、盘古电力大模型、盘古制造质检大模型、盘古药物分子大模型等行业大模型。
“X”对应的L2层是把L1再具体下游业务场景进行部署后生成的部署模型,更加专注于政务热线、网点助手、先导药物筛选、传送带异物检测、台风路径预测等具体行业应用或特定业务场景,为客户提供“开箱即用”的模型服务。

1.3 华为云盘古大模型的独特优势与发展趋势
华为云盘古大模型的独特优势在于其强大的行业定制化能力、高性能计算能力、生态系统和开放性以及技术创新,这些优势使得华为云盘古大模型在众多大模型中脱颖而出,能够更好地服务于各个行业和领域。
(1) 高性能计算能力:华为云盘古大模型在处理自然语言任务时具有高效性和泛化能力,可以在不同领域和场景中适应和应用。
(2) 生态系统和开放性:华为云盘古大模型具备良好的生态系统,与其他华为云服务和合作伙伴的产品相互配合,形成完善的解决方案。用户可以通过盘古云平台快速搭建自己的应用环境,并享受高质量的云服务。盘古云不仅能提供基础设施服务,还支持容器、人工智能、大数据等领域的应用开发和部署。
(3) 技术创新:华为云盘古大模型采用了创新的网络结构,实现了对地球上每一个经纬度的气象天气要素的精准获取。这种精细化的数据处理方式,使得预测结果更加准确可靠,为各行业提供了有力的数据支持。
(4) 行业定制化能力:华为云盘古大模型采用了分层解耦设计,可以快速适配、快速满足行业不断变化的需求。客户可以为自己的大模型加载独立的数据集,也可以单独升级基础模型或能力集。在L0、L1大模型的基础上,华为云还为客户提供大模型行业开发套件。通过对客户自有数据的二次训练,客户可以拥有自己专属的行业大模型。
华为云盘古大模型正在不断升级和改进,以更好地满足行业需求。华为云还计划推出盘古大模型5.0版本,该版本将专为行业而生,解决实际问题。未来,华为云盘古大模型将更加注重行业应用,继续深化与各行业的合作,在更多行业中得到应用,推动各行业的智能化升级。并通过技术创新和优化,一方面推出更多层级和更大规模的模型,另一方面提高模型的性能、效率和泛化能力。
2. 盘古大模型的原理
2.1 Transformer模型架构
卷积神经网络 (CNN) (He et al., 2016) 和循环神经网络 (RNN) (Chung et al.,2015) 是十分强大的深度网络模型。前者模拟人类视觉关注特征,通过不断的卷积和池化操作自动提取图像特征、保留关键信息,使神经网络更好地学习到数据特征,提高模型性能;后者引入了“记忆”机制,使神经网络可以处理序列数据并保持对过去信息的记忆,该模型能更好地理解和预测序列数据。
盘古大模型采用的Transformer (Vaswani et al., 2017) 架构则是更为先进的深度网络模型,该模型解决了循环神经网络存在的无法并行训练与需要大量资源存储整个序列信息的问题。Transformer模型最初是为了解决自然语言处理 (NLP) 任务而设计的,但其灵活性和通用性使其能够被应用于其他领域,在图像分类、目标检测等计算机视觉领域足以媲美甚至领先卷积神经网络 (田永林等, 2022)。
Transformer模型的主要组成部分包括编码器 (Encoder) 和解码器 (Decoder)。这种Encoder-Decoder架构是自然语言处理 (NLP) 和其他序列到序列 (Seq2Seq) 转换任务中的一种常见框架。编码器负责分析输入文本,提取文本信息与隐藏关系。解码器依托编码器提供的深入洞察,负责生成所需的输出。Transformer的编码器和解码器均由6个相同的层组成,编码器的每一层包括一个多头自注意力子层和一个逐位置的前馈神经网络子层,解码器的每一层包含自注意力子层、编码器-解码器注意力子层和前馈神经网络子层。
自注意力机制 (Self-Attention) 是Transformer架构的核心,它允许模型在处理输入序列时将不同位置的信息赋予不同的权重。通过计算每个位置与其他位置的相关性,使得模型能够有效地捕获长距离依赖信息,这在处理自然语言等序列数据时尤为重要。此外,自注意力机制在处理序列数据时不需要按顺序迭代计算,因此可以高效地并行处理整个序列,大大加快了训练和推理速度。自注意力机制生成的注意力权重可以被视为模型在处理特定任务时对输入数据的重视程度,这为理解和解释模型的决策提供了可能。相较于传统的卷积神经网络 (CNN) 和循环神经网络 (RNN),基于自注意力机制的Transformer模型可以同时对整个序列进行计算,允许并行处理;同时模型能够同时关注到整个序列的信息,从而更全面地建模上下文关系,提高了模型对序列的理解能力。
Wang et al. (2023) 发现特征坍塌问题影响了盘古大模型中 Transformer 架构的表达能力,极大地降低了自然语言处理 (NLP) 模型的生成质量和多样性。华为诺亚方舟实验室等联合推出盘古大模型π通过增强模型的非线性表达能力解决特征塌陷问题,其核心改进在于以下两点:在前馈网络 (FFN) 中加入了串联激活函数,这种基于级数的激活函数包含多个可学习的仿射变换,有效增强了非线性,同时计算量较小;在多头自注意力 (MSA) 中集成了增强型快捷连接 (Aug-S),这种连接能将每个token的特征转换为不同表示形式,有助于防止特征塌陷问题。尽管盘古大模型π从两个关键方面增强了模型的非线性表达,但它并未显著增加模型的复杂性。这意味着在相同规模的参数下,盘古大模型π能够实现显著的效率提升。在实际应用表现上,盘古大模型π在大规模语料库上进行训练后,在下游任务上展现出了良好的通用语言能力。在各种NLP任务上进行的大量实验显示,盘古大模型π在模型大小相似的情况下,比之前的大模型具有更高的准确性和效率。
2.2 盘古大模型的训练原理
2.2.1 盘古大模型的训练方法
盘古大模型通过自监督学习方式进行训练,模型通过输入数据本身生成的伪标签来进行训练,这些伪标签不是由人工标注的,而是由模型根据一定的规则自动生成的。盘古大模型采用的自监督学习训练任务模型主要采用了掩码语言模型 (Masked Language Model, MLM),即将其中一部分输入词进行随机掩码(替换为一个特殊的掩码符号),模型的任务就是预测这些被掩码的词。这种训练方式类似于让模型不断进行完形填空,从而学习到文本的深层语义结构。
伪标签由模型根据一定的规则自动生成,其中包括基于预训练模型的聚类生成伪标签、对比学习以及对抗训练等。
(1) 聚类生成伪标签:盘古大模型可以通过预训练模型对未标注数据进行特征提取,然后使用聚类算法 (如K-means) 对特征进行聚类,将属于同一聚类的数据点用相同的伪标签进行标记。这些伪标签作为引导学习的基础,使得模型能够在没有真实标签的情况下进行学习。
(2) 对比学习:在自监督学习中,盘古大模型可以设计一个对比任务,通过模型的自我对比来生成伪标签。例如,可以将一段文本分成两个部分,然后让模型判断这两个部分是否相似,从而生成伪标签。通过训练模型来最大化相似样本的相似度,最小化不相似样本的相似度,可以实现无监督的表示学习。
(3) 对抗训练:对抗训练是一种旨在通过生成对抗网络 (GAN) 对模型进行训练的方法,以提高其对噪声、扭曲和攻击的鲁棒性。通过对抗训练,模型可以识别和生成不同类型的数据,并在面对不确定性时保持稳定和可靠。盘古大模型采用了一种名为“基于对抗训练的伪标签约束自编码器”的方法,这种方法通过缩短原始图的伪标签和网络表示的伪标签之间的距离,减少编码过程中产生的信息损失,约束和引导模型有效学习。
其次,盘古大模型采用自动并行的训练策略。通过组合使用数据并行、算子级模型并行、Pipeline模型并行、优化器模型并行、重计算等技术,使盘古大模型能够在大规模计算资源上高效运行,从而实现了超大规模的分布式训练。
2.2.2 盘古大模型的训练过程
盘古大模型分为三个训练阶段:
(1) 大规模预训练,利用海量数据进行预训练得到通用基础模型。在预训练阶段,盘古大模型会学习大量的中文文本数据,例如盘古NLP大模型预训练阶段学习了40TB的中文文本数据。这些数据有助于模型吸收海量的知识,提高模型的泛化能力,减少对领域数据标注的依赖。预训练过程还包括了模型架构的设计和优化。盘古NLP大模型采用了deep encoder(深编码)和shallow decoder(浅解码)结构,目的是为了保证模型在生成和理解两个方面的性能都表现优异,同时加速生成过程。
(2) 下游微调,针对下游行业具体任务,结合行业数据进行微调。微调是在大模型的基础上,针对特定任务进行进一步训练,以提升模型在该任务上的性能。盘古大模型的微调方法主要包括数据准备、参数初始化、模型训练、模型验证和模型部署等步骤。通过微调,可以使模型更好地适应特定任务,提升模型的准确性和泛化能力。盘古大模型的"5+N+X"三层架构,采用了完全的分层解耦设计,这种设计允许快速适配和满足行业的多变需求。客户可以为自己的大模型加载独立的数据集,根据具体任务的需求和数据的特性进行微调。
(3) 大模型迭代:盘古大模型在使用过程中会结合不断产生的新数据和之前训练数据进行更新和优化,从而适应新数据与变化的环境,保持模型的时效性和准确性。增量学习和终身学习是盘古大模型的重要特性,增量学习是指模型在原有知识的基础上,通过学习新的数据来不断扩充和优化自身的能力。盘古大模型通过增量学习,可以在不重新训练整个模型的情况下,快速吸收新的知识和技能。例如,盘古大模型在电力行业的应用中,通过一次预训练加上下游任务的微调,推出了专门针对无人机电力巡检细分场景的模型,解决了小样本学习、主动学习、增量学习等问题。终身学习则是指模型能够在其生命周期内不断学习和进化,即使在初始训练之后也能继续改进。盘古大模型通过终身学习,能够不断适应新的数据和环境,保持其性能的持续提升。
2.3 盘古大模型的推理方案
推理是指使用训练好的模型来进行预测或决策的过程。在模型被训练以学习数据的特征和模式之后,推理就是将实际的数据输入模型,以获得输出结果的步骤。盘古大模型的推理过程主要包括两个阶段:全量推理和增量推理。全量推理是指用户给出一个查询,然后输出第一个token。增量推理则需要反复执行多次,通常是生成多少个token就执行多少次减一。这两个过程所面临的难点是不同的:全量推理是计算密集型的,而增量推理则是访存密集型的。在全量推理阶段,每次计算一个token时,都会涉及一个大的权重矩阵乘以一个小的输入向量。而在增量推理阶段,需要加载大的权重矩阵和kv缓存,且序列长度与加载的数据量成正比。
为了解决这些问题,盘古大模型采用了增量推理和分布式推理的方式。增量推理通过将推理过程分为两个阶段,第一阶段执行一步,然后执行第二阶段若干步。使用增量推理的方式,模型在第二阶段 (输入长度=1) 的执行速度可以达到第一阶段 (输入长度=1024) 的5倍,随着批次大小的增大,提升愈发明显。由于第二阶段会执行多次,整体性能提升比较明显。增量推理与常规推理在数学原理上并不完全等价,但在下游任务实验中两种推理的精度基本一致。分布式推理是指在多个计算节点上进行模型推理的过程。对于盘古大模型,分布式推理主要采用两种并行策略:OP-Level和PipeLine模型并行。OP-Level模型并行是算子级别的并行,会将单个tensor在不同的维度进行切分,每块卡只保存tensor的一部分;而PipeLine模型并行是将整个模型切分为几张子图,每张子图放置在若干节点上。分布式推理使盘古大模型能够在多个计算节点上并行处理数据,显著提高推理速度,满足大规模应用场景的需求。
3. 盘古大模型在地球科学方面能做什么?
3.1 气象预测
3.1.1 盘古气象大模型的背景
数值天气预报 (NWP) 基于物理方程建立描述天气演变过程的数学模型,通过计算机数字求解后,实现对未来天气情况的预测。一直以来,NWP都是天气预报的主流方法。但是传统的NWP使用超级计算机进行模拟与预测,对计算资源与专家经验要求很高。此外,大气的混沌效导致十分依赖参数化的NWP可能会出现很大的不确定性 (Stevens and Bony, 2013)。
随着气象数据的规模与质量的不断提高,完全由数据驱动的AI模型在天气预报中展现巨大潜力。AI模型预测天气的一般方法为基于历史天气资料训练深度神经网络,根据输入数据预测目标时间点的天气状态。根据不同的深度神经网络方法,国内外开发出多种AI气象预报模型。由NVIDIA实验室开发的FourCastNet模型基于傅立叶预测神经网络,首次进行了分辨率为 0.25°的深度学习天气预报 (Pathak et al., 2022)。该方法比传统数值天气预报模型快约45000倍,但它在异常相关系数 (ACC) 和均方根误差 (RMSE) 方面与传统的数值天气预报模型相当。由谷歌DeepMind团队开发的GraphCast模型采用了图神经网络(GNN)技术,能够在1分钟内以0.25°的分辨率在全球范围内预测超过10天的数百个天气变量,并且在多个验证目标上显著优于现有的天气预报模型 (Lam et al., 2023)。
但现有的 AI 气象预报模型,如FourCastNet模型,预测精度仍然显著低于数值预报方法。Bi et al (2023) 指出AI 气象预报模型的不足之处:现有的 AI 气象预报模型都是基于 2D 神经网络,无法很好地处理不均匀的 3D 气象数据。其次,AI 方法缺少数学物理机理约束,因此在迭代过程中会不断积累迭代误差。Bi et al (2023) 从该问题出发,提出了一种新的高分辨率全球 AI 气象预报系统—盘古气象 (Pangu-Weather) 大模型。盘古气象大模型的训练和测试均在ECMWF第五代再分析数据(ERA5) 进行,包括43年(1979-2021年)的全球实况气象数据。其中,1979-2017年数据作为训练集,2019年数据作为验证集,2018、2020、2021年数据作为测试集。盘古气象大模型是首个精度超过主流综合预报系统 (IFS) 的AI模型,速度相比传统数值预报提速10000倍以上。该模型能够提供全球气象秒级预报,其气象预测结果包括位势、湿度、风速、温度、海平面气压等,可以直接应用于多个气象研究细分场景。在实际应用中,盘古气象大模型已经展现出了惊人的效果,例如在台风“玛娃”的路径预报中,盘古气象大模型提前五天预报出其将在台湾岛东部海域转向路径,而传统数值预报方法则一直没有预测出这一转向。在第19届世界气象大会上,欧洲中期预报中心也指出,盘古气象大模型在精度上有不可否认的能力,纯数据驱动的AI天气预报模型,展现出了可与数值模式媲美的预报实力。
3.1.2 盘古气象大模型的创新点与不足
相较于传统的AI 气象预报模型,盘古气象大模型的创新点在于以下两点:
(1) 采用三维神经网络架构 (3D Earth-specific transformer, 3DEST):三维神经网络架构属于transformer 的3D变体,与FourCastNet等二维模型相比,3D模型通过将高度公式化为单个维度,能够捕获不同压力水平下大气状态之间的关系,更适合处理地球坐标系统下复杂的不均匀的3D 气象数据。3DEST 架构的输入和输出数据包括13层的高空变量和地表变量,通过patch 嵌入技术对数据进行降维处理,并将降采样的数据组合成一个 3D 立方体。团队在对气象数据性质进行仔细分析后在每一个网络block里引入了Earth-Specific位置编码。气象预报数据和普通图像数据最大的区别在于,特征图上的每个像素都对应于地球上的一个绝对位置,而图像上的像素往往只包含相对位置信息。同时,如图所示,气象要素数据对应的经纬度网格是不均匀的,而不同的要素在不同纬度、高度的分布也是不均匀的。对这些不均匀性的建模,有利于学习气象数据背后潜藏着的复杂物理规律,如科里奥利力等。为此,盘古气象大模型在每一个transformer模块中引入和纬度、高度相关的绝对位置编码来学习每一次空间运算的不规则分量。
(2) 使用分层时间聚合策略:盘古气象大模型按照 1 小时、3 小时、6 小时和 24 小时的前导时间 (输入和输出之间的时间差) 训练了四个深度网络模型。使用单个模型进行中期天气预报时需要进行多次迭代,而分层时间聚合将大大减少迭代次数、降低迭代误差。如图2b,前导时间为 56 小时的情况下,只需要执行 24 小时的预报模型 2 次,6 小时的预报模型 1 次,1 小时的预报模型 2 次。与使用固定的 6 小时预报模型的 FourCastNet 相比,盘古气象大模型提供了更高精度的时间分辨率与更低的迭代误差。
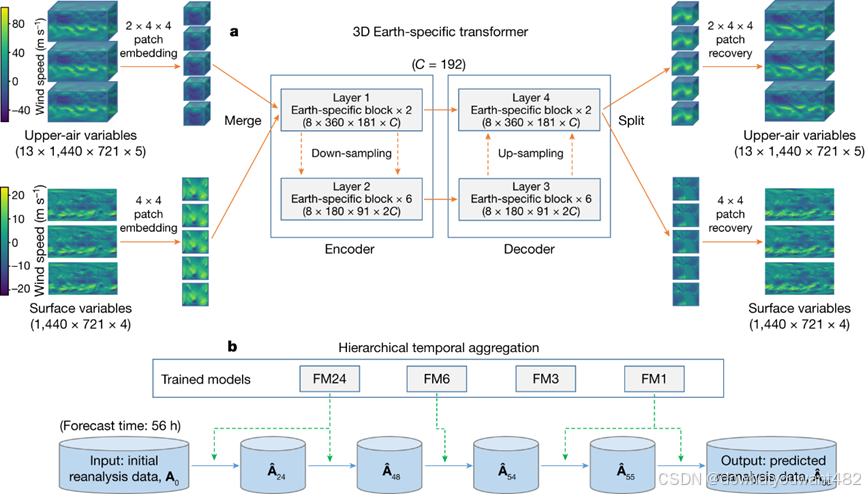
尽管盘古气象大模型具有着超越数值模式的里程碑意义,被审稿人评价为“让人们重新审视预报模型的未来”,但是存在一些局限性。盘古气象大模型采用的分层时间聚合策略会导致时间序列不存在连续性,例如,23小时的预报是由12h+6h+3h+1h+1h的模型生成,而24h的预报则直接由24h模型生成;模型使用ERA5作为初始场,并非是对真实大气的预测;尚未对降水进行预报等等。
3.2 遥感领域
盘古CV大模型是基于海量图像和视频数据构建的视觉基础模型,具备高效的图像识别和视频分析能力,适用于多种视觉相关的应用场景。盘古CV大模型在遥感领域展现出其强大的应用潜力,通过大量遥感数据对盘古CV大模型进行预训练和微调,能够实现对遥感数据的精细化、智能化分析和应用。首先,盘古CV大模型在图像分割方面已经取得了显著进展,在没有增加额外标注代价的情况下,达到了最多12%的分割精度提升。因此同样可以设计针对遥感影像的预训练算法,为遥感数据的分析和应用提供有力支持。其次,盘古CV大模型具有良好的可迁移性。它使用超大规模图像进行预训练,能够直接迁移到其他领域进行推理,如工业质检的缺陷检测,无需进行额外的微调,仍然能够获得较高的准确率。这种可迁移性使得盘古CV大模型能够在多个领域发挥作用,拓宽其应用范围。此外,盘古CV大模型还在图像生成方面展现出创新力。它能够通过文本描述生成与之对应的视觉内容,为人类关于地球机理的先验知识提供直观的图像表达。这对于遥感领域中的零样本学习和小样本学习具有重要意义,有助于解决数据稀缺问题。
盘古多模态模型能够处理和理解多种类型数据,通过利用不同遥感数据源的互补性和协同效应,提供更准确、更全面的信息。例如,盘古多模态模型可以结合光学图像、雷达数据和其他地理空间数据,以提高土地覆盖类别分类的准确性。 该基础模型能够有效利用多模态遥感大数据的丰富性、多样性,为解决对地观测应用的复杂性提供了一个强大的框架。
3.3 其他领域
目前,盘古大模型在地球科学的应用主要在于天气预报,其优势主要体现在其高精度、高速度和先进的模型结构上,这些优势或可为盘古大模型在地球科学其他领域的应用提供重要技术支持。比如在城市空气质量监测和污染物扩散路径分析方面,华为云盘古大模型可以通过集成各种传感器数据和气象数据,利用机器学习算法构建预测模型,对未来空气质量进行预测。这种模型可以帮助相关部门提供空气质量预警和决策支持,从而改善城市环境。通过对历史空气质量数据、气象数据和其他相关数据的分析,模型可以帮助识别污染物的来源和传播路径,为环境执法提供证据支持,加强对空气污染企业的监督管理。盘古大模型所提供的位势、湿度、风速、温度、海平面气压等预测变量可为气候变化、自然灾害预警等方面的研究提供数据支撑。
4. 怎么应用和运行盘古大模型?
在华为云服务平台,注册登录之后, 通过华为云的控制台来申请华为云盘古大模型:控制台左侧导航栏——“人工智能”选项——选择“盘古大模型”——填写基本信息——提交申请。或者使用API调用华为盘古大模型的相关接口:在盘古AI官网注册并获取API Key和Secret Key——下载安装Python SDK——通过Python调用SDK,实现相应的功能。华为云提供了盘古ai大模型的详细使用教程 (盘古ai大模型使用教程_ai盘古ai大模型-华为云)。
盘古气象大模型已在Github上开源(GitHub - 198808xc/Pangu-Weather: An official implementation of Pangu-Weather),提供的已训练模型包括:逐小时预报模型、逐3小时预报模型、逐6小时预报模型和逐日预报模型。目前可预测的变量包括垂直高度上13个不同气压层,每层五种气象要素 (温度、湿度、位势、经度和纬度方向的风速),以及地表四种气象要素 (2米温度、经度和纬度方向的10米风速、海平面气压)。首先进行前期准备,注册 Climate Data Store账号获取CDS API,将url和key复制到python的.cdsapirc 文件中;根据CPU或GPU环境安装模型依赖包;在 Pangu-Weather 开源网站上下载上述4个预训练模型。第二步运行模型,设置 data_prepare.py 中初始场和目标场的 date_time,程式会自动组合4个预训练模型,通过最少的迭代完成预测。最后,在完成预测后对结果进行可视化。也可以登录 ECMWF 网站 (https://charts.ecmwf.int/?query=pangu) 直接获取基于盘古气象大模型的未来10 天的全球天气预报。
参考文献
Bi K, Xie L, Zhang H, et al. Accurate medium-range global weather forecasting with 3D neural networks[J]. Nature, 2023, 619(7970): 533-538.
Bommasani R, Hudson D A, Adeli E, et al. On the opportunities and risks of foundation models[J]. arXiv preprint arXiv:2108.07258, 2021.
Chung J, Gulcehre C, Cho K, et al. Gated feedback recurrent neural networks[C]//International conference on machine learning. PMLR, 2015: 2067-2075.
He K, Zhang X, Ren S, et al. Deep residual learning for image recognition[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2016: 770-778.
Hinton G E, Salakhutdinov R R. Reducing the dimensionality of data with neural networks. Science, 2006, 313(5786): 504-507.
Kolesnikov A, Beyer L, Zhai X, et al. Big transfer (bit): General visual representation learning[C]//Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part V 16. Springer International Publishing, 2020: 491-507.
Lam R, Sanchez-Gonzalez A, Willson M, et al. Learning skillful medium-range global weather forecasting[J]. Science, 2023, 382(6677): 1416-1421.
Lin X, Xu C, Xiong Z, et al. PanGu Drug Model: learn a molecule like a human[J]. Biorxiv, 2022: 2022.03. 31.485886.
Pathak J, Subramanian S, Harrington P, et al. Fourcastnet: A global data-driven high-resolution weather model using adaptive fourier neural operators[J]. arXiv preprint arXiv:2202.11214, 2022.
Stevens B, Bony S. What are climate models missing?[J]. science, 2013, 340(6136): 1053-1054.
Vaswani A, Shazeer N, Parmar N, et al. Attention is all you need[J]. Advances in neural information processing systems, 2017, 30.
Wang Y, Chen H, Tang Y, et al. PanGu-π: Enhancing Language Model Architectures via Nonlinearity Compensation[J]. arXiv preprint arXiv:2312.17276, 2023.
田永林, 王雨桐, 王建功, 等. 视觉 Transformer 研究的关键问题: 现状及展望[J]. 自动化学报, 2022, 48(4): 957-979.
陶建华, 吴飞, 黄民烈等. 中国人工智能系列白皮书——大模型技术[M]. 中国人工智能学会, 2023.
梁宏涛, 刘硕, 杜军威等. 深度学习应用于时序预测研究综述[J]. Journal of Frontiers of Computer Science & Technology, 2023, 17(6).

















 2432
2432

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









