







1、《Person Entity Alignment Method Based on Multimodal Information Aggregation》H. Wang, R. Huang, J. Zhang
提出了一种基于多模态信息聚合的人员实体对齐方法(PEAMA),旨在通过融合人脸图像和语义信息,解决大规模知识图谱中人员实体对齐的问题。该方法利用图卷积网络(GCN)和动态图注意力网络(DGA)提取实体结构特征,并通过层间门控网络(Layerwise Gated Network)聚合单跳和多跳邻域信息。此外,结合人脸特征和语义特征,增强目标实体的低维向量表示,并通过余弦相似度和贪婪策略生成对齐候选排序。
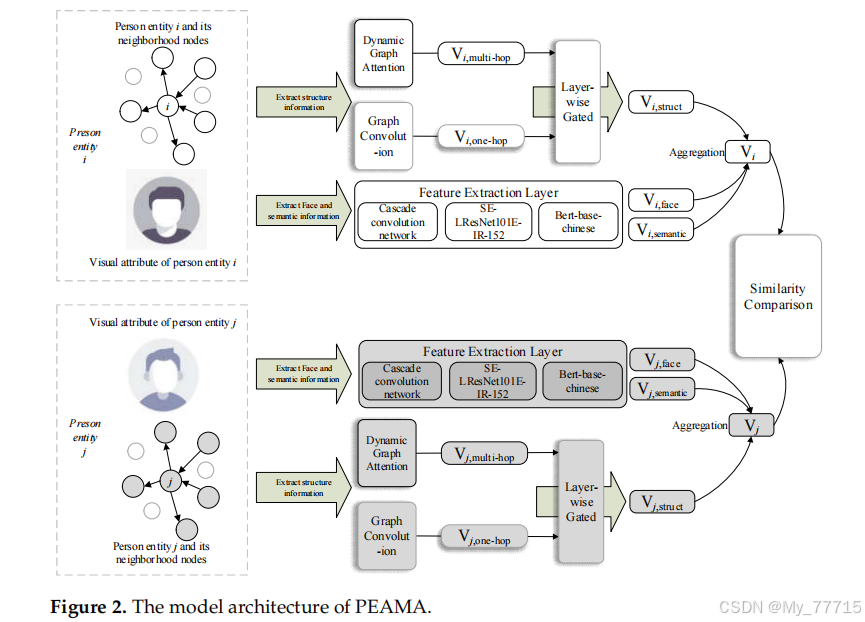
该方法依赖于预对齐的实体对和高质量的人脸图像数据。当人脸特征缺失或图像质量较差时,模型性能可能下降。此外,模型对预对齐实体对的质量要求较高,若预对齐数据稀疏,可能影响对齐效果。
2、《Cross-knowledge-graphentityalignmentviarelationprediction》H. Huang, C. Li, X. Peng, L. He, S. Guo, H. Peng, et al.
本文提出了一种基于关系预测的跨知识图谱实体对齐框架(RpAlign),通过将对齐任务转化为知识图谱补全任务,避免了传统方法中需要额外对齐组件的问题。该方法通过定义“锚点”关系来连接对齐实体,并利用数据增强和改进的自训练技术缓解数据不足问题。</
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 949
949

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









