









Abstract
以往的方法虽然能够在各种场景理解任务中达到较好的准确率,但训练速度往往较慢,网络结构复杂。本文针对这些问题,提出了一种有效的端到端置换不变卷积算法用于点云深度学习。我们名为ShellConv的简单而有效的卷积运算符使用同心球壳的统计数据来定义代表性特征并解决点序不规则性,从而允许对这些特征执行传统卷积。在ShellConv的基础上,我们进一步构建了一个高效的神经网络ShellNet,在保持较少层数的情况下,直接消耗接受野较大的点云。
Introduction
由于PointNet收敛速度慢,网络复杂,PointNet++ 以分层方式应用PointNet,效果虽好,但是网络也变的更加复杂,速度也有所降低。逐点卷积实现简单,但不准确。
本文提出在每个点上查询点邻域,并用一组同心球体对其进行划分,得到同心球壳。在每个壳体中,可以根据其内部点的统计信息来提取具有代表性的特征。通过使用ShellConv作为核心卷积算子,可以构造一个高效的神经网络ShellNet来解决物体分类、物体部分分割和语义场景分割等三维场景理解任务。
ShellConv, 一种简单而有效的无序点云卷积算子。卷积定义在可以由同心球壳划分的区域上,通过定义从内到外的卷积顺序,同时允许高效的邻点查询和解决点序歧义;
ShellNet, 是一种基于ShellConv的高效神经网络体系结构,可以直接从三维点云中学习,而不存在任何点序模糊;
ShellNet在对象分类、对象部分分割和语义场景分割方面的应用,实现了最先进的准确性。
Related Works
除了学习非结构化点云之外,还有一些值得注意的扩展工作,例如使用分层结构学习,使用自组织网络学习,学习将3D点云映射到2D网格,处理大规模点云分割,处理非均匀点云,以及使用谱分析。这些想法与我们的方法是正交的,将它们添加到我们提出的卷积之上可能是一个有趣的未来研究。

The ShellConv Operator
为了实现高效的点云神经网络,第一个任务是定义一个能够直接消耗点云的卷积。我们的问题陈述是给出一组点作为输入,定义一个卷积,可以有效地输出一个特征向量来描述输入点集。
在定义这种卷积时,有两个主要问题。首先,必须定义输入点集。它可以是整个点云,也可以是点云的子集。前者寻找描述整个点云的全局特征向量;后者为每个点集寻找可在需要时进一步组合的局部特征向量。其次,必须无缝地处理集合中的点序模糊性和点云中的点的密度。PointNet选择学习全局特征,但最近的工作表明,局部特征可以导致更具代表性的特征,从而产生更好的性能。我们受到这些工作的启发,定义了一种卷积来获取局部点集的特征。
Convolution: 我们在图2中展示了卷积的主要思想。传统CNN架构中的常见策略是降低输入的空间分辨率,并在更深的层输出更多的特征通道。我们在卷积中也支持这一策略,将点采样结合到卷积中,在更深的层输出更稀疏的点集。与以往通过层叠多层来增加感受野的方法不同,我们的方法可以在不增加层数的情况下获得更大的感受野。具体地,从输入点集合中随机采样一组代表点(图2(A)中的红点)。每个代表点及其邻接点定义一个用于卷积的点集(图2(B))。


现在让我们关注单个代表点p及其邻居q∈Ωp,其中Ωp是由最近邻居查询确定的邻居集。根据定义,p处的卷积为:
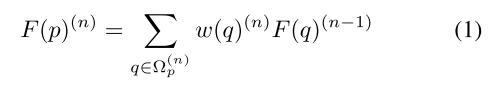
其中,F表示平面通道的点集的输入特征,w表示卷积的权重。我们使用上标(N)来表示层n的数据或参数。请注意,F§和F(Q)表示点p和q的特征。
我们可以利用将邻域划分为区域的方法,使得w定义得很好,并且可以有效地计算输出。特别是,为了方便邻居查询,我们使用一组多尺度同心球体来定义区域(图2©)。两个球体之间的区域形成一个球壳。同心球壳的并集产生域Ωp。因此,我们可以将卷积定义为
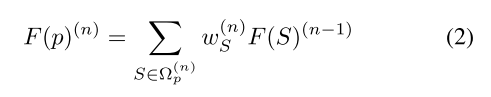
由于壳是自然排序的(从最里面到最外面),所以壳之间没有歧义,卷积被很好地定义,每个壳的权重WS。仍然模棱两可的是贝壳中点的顺序。为了解决这个问题,我们提出了一种统计方法来聚合每个壳中点的特征,从而产生顺序不变的输出。特别是,我们选择仅通过每个要素通道中的最大值来表示要素:
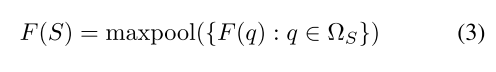
其中ΩS表示壳S。从理论上讲,最大值是对底层分布的粗略近似,但由于每个点通常具有数十或数百个特征通道,仍然可以表示壳中许多点的信息。
Spherical Shells Construction: 我们使用一个简单的启发式方法来建立球壳,如下所示。我们首先计算邻点到中心代表点的距离。然后,我们对距离进行排序,并根据壳到中心的距离(从内到外)将点分配给壳。我们为每个外壳分配固定数量的点,即在我们的实现中,每个外壳分配n个点。特别是,我们首先从中心开始生长球体,直到n个点落入球体内。这是最里面的壳。在此之后,球体继续增长以收集形成第二个壳的另外n个点,依此类推。我们发现,这种壳构造方法提供了壳中点分布的良好分层。
ShellNet
我们从典型的2D卷积神经网络中得到启发,构建了一个名为ShellNet的体系结构,它使用ShellConv来代替传统的2D卷积(参见图3)。该体系结构可用于多场景理解任务。特别是,分类和分割网络都共享编码器部分,只是在之后的部分有所不同。由于ShellConv对于输入点是排列不变的,因此ShellNet能够直接消耗点集。

分段网络遵循U-Net,这是一种具有跳过连接的编解码器体系结构。反卷积部分从编码器的一组n2个点开始,经过ShellConv运算符,直到点云达到原始分辨率。反褶积层逐渐输出更多的点,但更少的特征通道。跳过连接保留早期层中的要素,并将它们连接到反褶积层的输出要素。这种策略被证明对于图像上的密集语义分割是非常有效的,我们在这里针对点云采用了这种策略。请注意,我们使用ShellConv进行卷积和反卷积。输出的N×C也被送入MLP生成分割概率图,其中我们得到一个64×kseg矩阵,其中kseg表示分段标签的数量。
Experimental Results
Parameter Setting
ShellNet有三个编码层,每个编码层都包含一个ShellConv。参数为Ni、Si和Ci,分别表示每层中的代表点数量、壳体数量和输出通道。从第一层到第三层,对于i=0、1、2,分别将Ni设置为512、128、32,将Si设置为4、2、1,并且将Ci设置为128、256和512。C在用于分割的最后一次卷积时被设置为64。我们将每个壳中包含的点数定义为壳的大小,对于分类,设置为16,对于分割,设置为8。因此,每个代表点的邻域个数分别为Si×16和Si×8,对于三层分类,分别等于64、32和16,对于分割,分别等于32、16、8。在训练过程中,我们使用32个批次的大小进行分类,16个批次进行分割。优化是使用Adam优化器完成的,初始学习率设置为0.001。我们的网络在TensorFlow中实现,并在NVIDIA GTX 1080图形处理器上运行,用于所有实验。
Object Classification
正如我们所看到的,我们的结果已经达到了最先进的水平。虽然外壳大小(Ss)为16的ShellNet是分类的默认设置,但也会测试其他ss。当SS减小到8时,感受野变小,重叠变小,准确率也略有下降,但仍在91.0%左右。当SS增加时,感受野扩大,从而捕捉到更多的空间语境信息。ShellNet在SS为32的情况下达到93.1%的准确率。然而,这并不意味着越大越好,因为太大的感受野也会冲刷掉特征的高频精细结构[24]。我们可以看到,当ss设置为64时,准确率下降到92.8%。为了在速度和精度之间取得平衡,我们将目标分类的ss设置为16。图1提供了等时间和等历元设置下的精度曲线图。可以看出,我们的方法比所有测试的方法都要好,是最快和最准确的收敛方法。与本实验中最快的方法之一PointCNN[20]相比,我们使用了简单得多的网络架构。为了将点云转化为潜在的规范表示,其X-Conv算子需要学习变换矩阵,而我们的方法只需要统计计算来聚集特征。这使得我们的卷积更直观,更容易实现,但能够获得高性能。我们还在补充文档中提供了每一类的准确性。

Segmentation




Network Efficiency

我们工作的速度和内存的提高来自于在我们的网络中有效地使用MLP和一维卷积。特别是,在基于同心壳的点分组的系统方法的基础上,该方法自然地处理多尺度特征,我们只需要一个MLP来学习壳中的点特征,以及一维卷积来关联壳中的特征(图2)。这种简单性大大减少了可训练参数的数量和计算量。
在ShellNet中,感受野直接由壳的大小控制。因此,我们可以进一步分析不同外壳大小的ShellNet的性能(图7)。在等时比较中,贝壳大小为16的ShellNet表现最好,在很短的时间内实现了高精度。当壳大小为64时,它的性能略差。在等世代环境下,由于接受野较小,壳大小为8的处理效果不如其他处理。拥有一个在大小和速度之间取得平衡的接受场会产生最佳的收敛。

Neighboring Point Sampling
在这里,我们比较四种设置。特别是,设置A是我们的分类实验的默认配置,其中使用随机采样来获得邻接点,每个同心壳包含固定数量的点。通过改变相邻采样策略来获得设置B、C、D。在设置B中,我们将邻居采样更改为最远点采样。在设置C中,我们将局部区域划分为等距的壳,从而得到包含动态数量的点的壳。在设置D中,我们在特征空间而不是3D坐标空间中搜索最近邻。结果如表4所示。它表明不同变量的准确度是相似的,设置A对于分类任务是最有效的。对于分割,我们也进行了相同的实验,发现设置B在这种情况下效果最好。原因是设置B中最远的点采样会产生更均匀的点分布,可以覆盖更多的几何体细节,从而导致更准确的分割。

Conclusion
提出了一种基于局部点集构造同心球壳的三维点云深度学习新方法。我们设计了一种新的卷积算子ShellConv,它基于壳及其统计量有效地支持点集的卷积。这种结构不仅自然地解决了卷积排序问题,而且在不增加网络层数的情况下,允许更大、更重叠的接受域。
















 580
580











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









