









摘要
在这项工作中,我们提出了一种新的数据驱动的鲁棒的6DoF目标姿态估计方法,从单个RGB-D图像。与以前直接回归姿势参数的方法不同,我们使用基于关键点的方法来处理这一具有挑战性的任务。具体地说,我们提出了一种深度霍夫投票网络来检测物体的3D关键点,然后以最小二乘拟合的方式估计出6D姿态参数。我们的方法是成功地在基于RGB的6DoF估计上工作的2D Keypoint方法的自然扩展。该算法充分利用了刚体目标的几何约束和额外的深度信息,便于网络学习和优化。通过大量的实验验证了3D-KeyPoint检测在6D位姿估计任务中的有效性。实验结果还表明,在几个基准测试中,我们的方法比最先进的方法有很大的优势。代码和视频可在https://github.com/ethnhe/PVN3D.git.上获得
Introduction
由于光照变化、传感器噪声、场景遮挡和目标截断,6DOF估计已被证明是一个相当具有挑战性的问题。像[19,30]这样的传统方法使用手工制作的特征来提取图像和对象网格模型之间的对应关系。这种人类设计的经验性特征在光照条件变化和场景严重遮挡的情况下性能有限。最近,随着机器学习和深度学习技术的爆炸性增长,基于深度神经网络(DNN)的方法被引入到这一任务中,并显示出有希望的改进。[50,52]建议使用DNN直接回归对象的旋转和平移。然而,由于[37]解释的旋转空间的非线性,这些方法通常具有较差的泛化能力。相反,最近的工作利用DNN来检测对象的2D关键点,并使用透视点(PNP)算法来计算6D姿势参数[37,36,41,47]。虽然这两个阶段的方法表现得更稳定,但大多数都建立在2D投影的基础上。在真实的3D空间中,投影中的小误差可能会很大。此外,3D空间中的不同关键点在2D投影后可能会重叠,从而很难区分它们。此外,由于投影的影响,刚体物体的几何约束信息会部分丢失。
另一方面,随着廉价RGBD传感器的发展,越来越多的RGBD数据集可用。额外的深度信息允许2D算法以更好的性能扩展到3D空间,如PointFusion[53]、Frustum PointNet[39]和VoteNet[38]。为此,我们将基于2D-KeyPoint的方法扩展到3D KeyPoint,以充分利用刚体物体的几何约束信息,显著提高了6DoF估计的精度。更具体地说,我们开发了一个深度3D关键点关节投票神经网络来学习逐点3D偏移量并投票给3D关键点,如图1所示。我们的主要观察是一个简单的几何属性,即3D空间中刚性对象的两个点之间的位置关系是固定的。因此,给定物体表面上的一个可见点,它的坐标和方向可以从深度图像中获得,其到选定关键点的平移偏移也是固定的和可学习的。同时,逐点学习的欧几里德偏移量对于网络来说是直观的,更容易优化。
为了处理多对象场景,我们还在网络中引入了实例语义分割模块,并结合关键点选择进行了联合优化。我们发现,联合训练这些任务可以提高彼此的表现。具体而言,语义信息通过识别点属于哪个部分来改进平移偏移学习,而平移偏移中包含的大小信息有助于模型区分外观相似但大小不同的对象。
综上所述,这项工作的主要贡献如下:
- 一种基于实例语义分割的深度3D关键点霍夫投票网络用于单幅RGBD图像的6DOF位姿估计。
- 在YCB和LineMOD数据集上最先进的6DoF位姿估计性能。
- 深入分析了基于3D-KeyPoint的位姿估计方法,并与以前的方法进行了比较,证明了3D-KeyPoint是提高六自由度位姿估计性能的关键因素。我们还表明,联合训练3D-KeyPoint和语义分割可以进一步提高性能。
Related Work
Holistic Methods
整体方法直接估计物体在给定图像中的三维位置和方向。经典的基于模板的方法构造刚性模板并扫描图像来计算最佳匹配姿势。这样的模板对集群场景不是很健壮。最近,一些基于深度神经网络(DNN)的方法被提出用来直接回归摄像机或物体的6维姿态。然而,旋转空间的非线性使得数据驱动的DNN难以学习和推广。为了解决这一问题,一些方法使用后细化过程来迭代地细化姿势,另一些方法离散旋转空间并将其简化为分类问题。对于后一种方法,仍然需要后期细化过程来补偿离散化所牺牲的精度。
Keypoint-based Methods
现有的基于关键点的方法首先检测图像中目标的2D关键点,然后利用PNP算法估计6D姿态。经典的方法[30,42,2]能够有效地检测出纹理丰富的物体的2D关键点。但是,它们不能处理无纹理的对象。随着深度学习技术的发展,人们提出了一些基于神经网络的二维关键点检测方法。[41,47,20]直接回归关键点的2D坐标,而[33,24,34]使用热图来定位2D关键点。为了更好地处理被截断和遮挡的场景,[37]提出了一种基于像素的投票网络来投票选择2D关键点位置。这些基于2D关键点的方法旨在最小化对象的2D投影误差。然而,在真实的3D世界中,投影中的小误差可能会很大。[46]从合成RGB图像的两个视图中提取3D关键点以恢复3D姿势。然而,它们只利用RGB图像,在RGB图像上,刚体物体的几何约束信息由于投影而部分丢失,并且投影到2D后,3D空间中的不同关键点可能重叠而难以区分。廉价的RGBD传感器的出现使我们能够利用捕获的深度图像在3D中做任何事情。
Dense Correspondence Methods
这些方法利用霍夫投票方案[28,44,12]以每像素预测投票最终结果。它们使用随机森林[3,32]或CNN[23,9,27,35,51]来提取特征并预测每个像素对应的3D对象坐标,然后投票给最终的姿势结果。这种密集的2D-3D对应使得这些方法在输出空间相当大的情况下对遮挡场景具有较强的鲁棒性。PVNet[37]对2D关键点使用每像素投票,以结合密集方法和基于关键点的方法的优点。我们进一步将该方法扩展到具有额外深度信息的3D关键点,并充分利用了刚体对象的几何约束。
Proposed Method
给定RGBD图像,6DOF姿势估计的任务是估计将物体从其物体-世界坐标系转换为相机-世界坐标系的刚性变换。这种变换由三维旋转R组成∈ 所以(3)和 ·平移 t∈ R3。
Overview
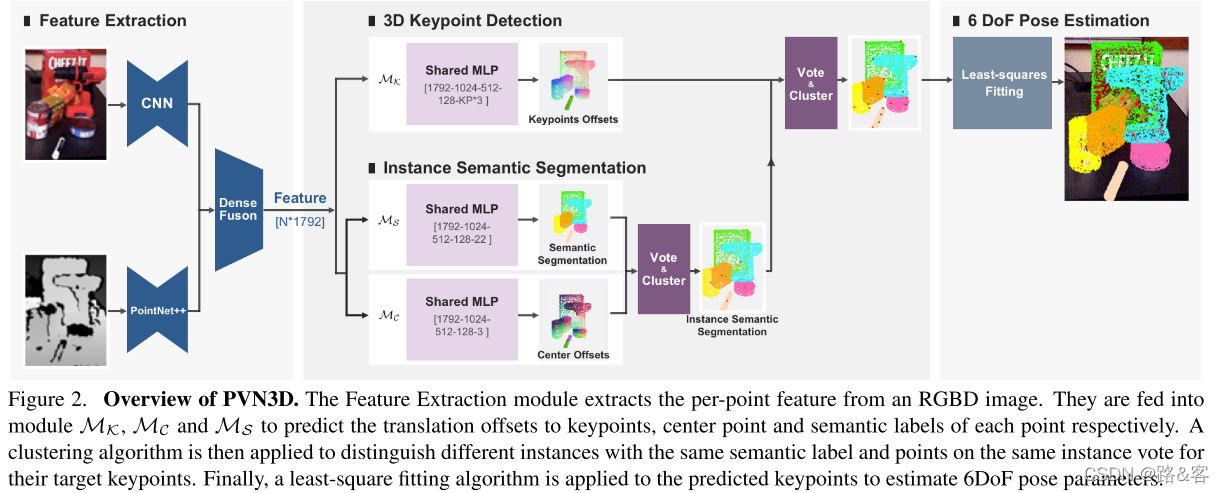
为了解决这一问题,我们开发了一种基于深度3D Hough投票网络的新方法,如图2所示。提出的方法是一个带有3D关键点检测的两级流水线,然后是姿势参数拟合模块。更具体地说,以RGBD图像为输入,使用特征提取模块对外观特征和几何信息进行融合。学习的特征将被馈送到3D关键点检测模块MK,该模块被训练以预测每个点的偏移量W.r.t关键点。此外,我们还包括用于多个对象处理的实例分割模块,其中语义分割模块MS预测每点语义标签,中心投票模块MC预测每点到对象中心的偏移量。利用学习的逐点偏移量,应用聚类算法来区分具有相同语义标签的不同实例,并且同一实例上的点投票给它们的目标关键点。最后,将最小二乘拟合法应用于预测关键点,估计出六自由度姿态参数。
Learning Algorithm
我们的学习算法的目标是训练一个用于偏移量预测的3D关键点检测模块MK,以及一个用于实例级分割的语义分割模块MS和中心投票模块MC。这自然使训练我们的网络成为多任务学习,这是通过我们设计的监督损失和我们采用的几个训练细节来实现的。
3D Keypoints Detection Module 如图2所示,利用特征提取模块提取的逐点特征,使用3D关键点检测模块MK来检测每个对象的3D关键点。具体地说,MK预测从可见点到目标关键点的逐点欧几里得平移偏移。这些可见的点,连同预测的偏移,然后投票给目标关键点。然后通过聚类算法收集投票的点,并选择聚类的中心作为投票的关键点。
我们对MK有更深一层的认识,具体如下。给定一组可见种子点{pi}N{kpj}mi=1和一组属于相同对象实例i的所选关键点j=1,我们用xi表示pi=[xi;fi],并用xi表示提取的特征。我们用Yj表示KPj=[Yj],即关键点的3D坐标。MK吸收每个种子点的特征fi并为它们生成平移偏移{ofj i},其中ofj表示从第i个种子点到第j个关键点的平移偏移。那么投票的关键点可以表示为vkpji=xi+ofji。为了监督ofji的学习,我们应用L1损失:
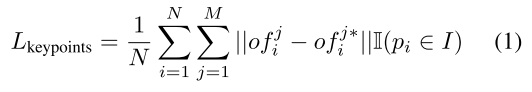
其中,ofj∗i是地面实值平移偏移量;M是所选目标关键点的总数;N是种子总数,i是仅当点pi属于实例i时才等于1的指示函数,否则为0。
Instance Semantic Segmentation Module 为了处理具有多个对象的场景,先前的方法[50,53,39]利用现有的检测或语义分割架构来预处理图像并获得仅包含单个对象的ROIs(感兴趣区域)。然后使用提取的ROIs作为输入来构建姿势估计模型以简化问题。然而,由于我们已经制定了姿势估计问题来首先检测具有向关键点学习模块的平移偏移的对象的关键点,我们相信这两个任务可以增强彼此的性能。一方面,语义分割模块提取全局和局部特征,以区分不同的对象,这有助于在对象上定位点,并且对关键点偏移推理过程很好。另一方面,学习用于预测关键点偏移的大小信息有助于区分具有相似外观但大小不同的对象。在这样的观察下,我们在网络中引入了一个逐点实例语义分割模块MS,并与moduleMK进行了优化。
具体地说,在给定每点提取的特征的情况下,语义分割模块MS预测每点语义标签。我们监督此模块的焦点损失[29]:
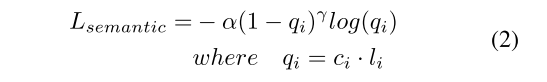
其中α为α-Balance参数,γ为聚焦参数,Ci为第i个点的预测置信度属于每个类别,Li为地面真实类别标签的单热点表示。
同时,应用中心投票模块MC对不同对象的中心进行投票,以区分不同的实例。我们在CenterNet[10]的启发下提出了这样的模型,但将2D中心点进一步扩展到3D。与2D中心点相比,3D中的不同中心点不会因为某些视点上的相机投影而受到遮挡。由于我们可以将中心点视为对象的一个特殊关键点,因此模块MC类似于3D关键点检测模块MK。它吸收逐点特征,但预测到其所属对象中心的欧几里得平移偏移∆xi。∆Xi的学习也受到L1损失的监督:
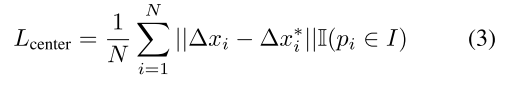
其中,N表示对象曲面上种子点的总数,∆x*i表示从种子pi到实例中心的地面真实平移偏移。II是指示点pi是否属于该实例的指示函数。
Multi-task loss 我们共同监督模块MK、MS和MC的学习,但存在多任务损失:
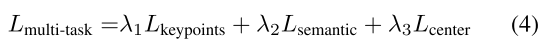
其中,λ1、λ2和λ3是每个任务的权重。实验结果表明,联合训练这些任务可以提高彼此的成绩。
Training and Implementation
Network Architecture 图2中的第一部分是特征提取模块。在该模块中,应用具有ImageNet预先训练的ResNet34的PSPNet来提取RGB图像中的外观信息。PointNet++提取点云及其法线贴图中的几何信息。它们通过DenseFusion块进一步融合,以获得每个点的组合特征。在此模块的处理之后,每个点pi具有C维的特征fi∈Rc。以下模块MK、MS和MC由图2所示的共享多层感知器(MLP)组成。我们对RGBD图像的每一帧采样N=12288点(像素),并在公式4中设置λ1=λ2=λ3=1.0。
Keypoint Selection 3D关键点是从3D对象模型中选择的。在3D对象检测算法[39、53、38]中,选择3D边界框的八个角。然而,这些边界框角点是远离对象上的点的虚拟点,使得基于点的网络难以聚集它们附近的场景上下文。距离目标点越远,定位误差越大,这可能对六维位姿参数的计算造成不利影响。取而代之的是,从对象曲面选择的点会非常好。因此,我们遵循[37]并使用最远点采样(FPS)算法来选择网格上的关键点。具体地说,我们通过将对象模型的中心点添加到空的关键点集中来启动选择过程。然后通过在网格上重复添加距离所有选定关键点最远的新点来更新它,直到获得M个关键点。
Least-Squares Fitting 给定对象的两个点集,一个来自相机坐标系中的M个检测关键点{kpj}Mj=1,另一个来自其在对象坐标系中的对应点{Kp‘j}Mj=1,6D姿势估计模块利用最小二乘拟合算法计算姿势参数(R,t),该算法通过最小化以下平方损失来找到R和t:
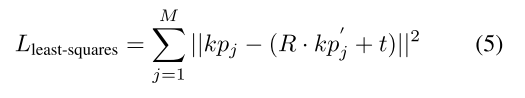
其中,M是对象的选定关键点的数量。
Experiments
Datasets
我们在两个基准数据集上对我们的方法进行了评估。
YCB-Video Dataset: YCB-视频数据集包含21个形状和纹理不同的YCB[4]对象。捕获了92个对象子集的RGBD视频,并使用6D姿势和实例语义掩码进行标注。不断变化的光照条件、显著的图像噪声和遮挡使得该数据集变得越来越长。我们遵循[52]并将数据集分割为 80个视频用于训练 ,并从剩余的12个视频中选择另外2949个关键帧用于测试。在[52]之后,我们将合成图像添加到我们的训练集中。还应用了孔完成算法[25]来改善深度图像的质量。
LineMOD Dataset: LineMOD数据集[18]由13个视频中的13个低纹理对象组成,带有注释的6D姿势和实例掩码。这个数据集的主要挑战是杂乱的场景、纹理较少的对象和光照变化。我们遵循先前的工作[52],将训练和测试集分开。此外,我们遵循[37],并将合成图像添加到我们的训练集中。
Evaluation Metrics
我们遵循[52],并使用平均距离Add和Add-S度量[52]来评估我们的方法。平均距离相加度量[19]评估由预测的6D姿势[R,t]和地面真实姿势[R∗,t∗]变换的对象顶点之间的平均成对距离:
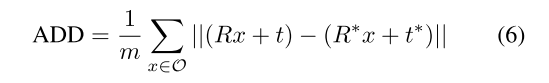
其中x是对象网格O上总共m个顶点的顶点。
Add-S度量是为对称对象设计的,平均距离是基于最近的点距离计算的:
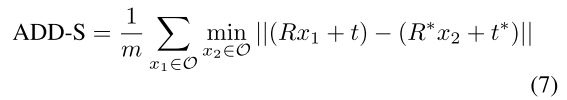
为了评估,我们遵循[52,50]并计算ADD-S AUC,即通过改变评估中的距离阈值获得的准确度阈值曲线下的面积。ADD(S)[19]AUC以类似的方式计算,但计算非对称对象的附加距离并增加对称对象的距离。
Evaluation onYCB-Video&LineMOD Dataset
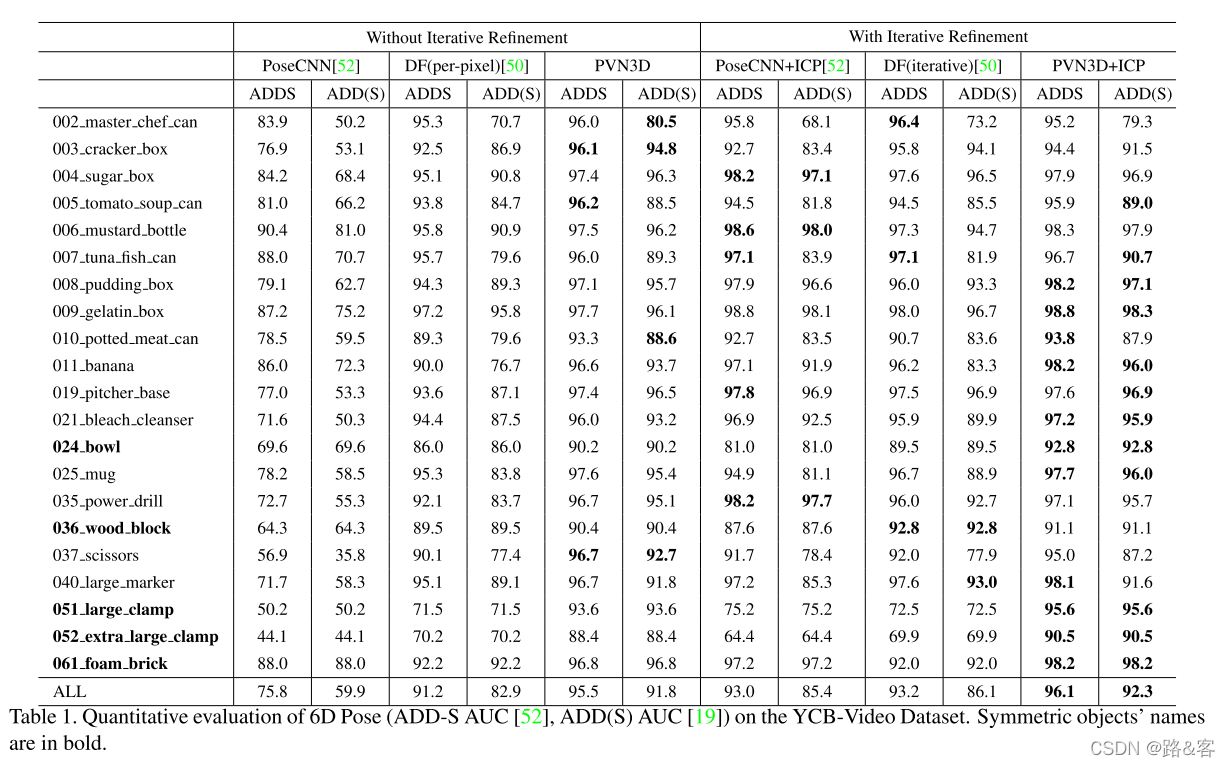
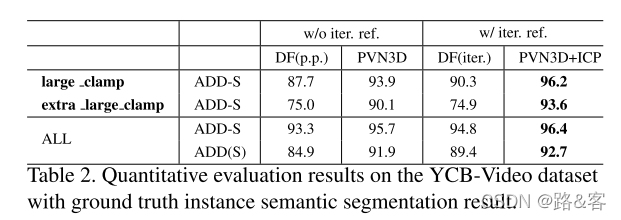
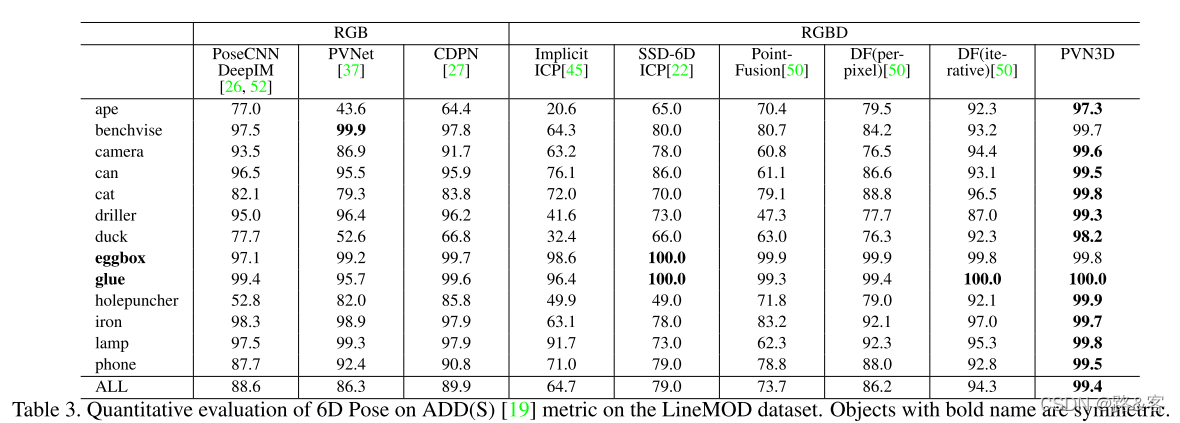
表1显示了YCB-Video数据集中所有21个对象的评估结果。我们将我们的模型与其他单视图方法进行了比较。如表所示,我们的模型没有任何迭代求精过程(PVN3D),远远超过所有其他方法,即使它们是迭代求精的。在ADD(S)度量上,我们的模型比PoseCNN+ICP[52]高6.4%,比DF(迭代)[50]高5.7%。通过迭代求精,我们的模型(PVN3D+ICP)获得了更好的性能。注意,该数据集的一个挑战是区分大夹具和超大夹具,在这些夹具上,以前的方法[50,52]的检测结果较差。我们还在表2中报告了使用基本事实分割的评估结果,这表明我们的PVN3D仍然达到了最佳性能。图3显示了一些定性结果。表3展示了对LineMOD数据集的评估结果。我们的模型也取得了最好的性能。
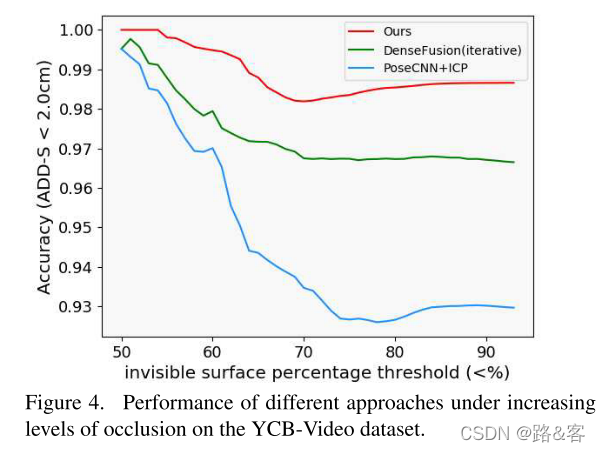
Robust to Occlusion Scenes 我们基于3D关键点的方法的最大优势之一是它对自然遮挡是健壮的。为了探索不同的遮挡程度如何影响不同的方法,我们遵循[50]并计算对象表面上不可见点的百分比。图4显示了不同不可见表面百分比下ADD-S < 2 cm的精度。当50%的点不可见时,不同方法的性能非常接近。然而,随着无形部分比例的增加,DenseFusion和PoseCNN+ICP下降的速度比我们的更快。图3显示,即使在对象严重遮挡的情况下,我们的模型也能很好地执行。

Ablation Study
在这一部分中,我们探讨了不同的公式对六自由度位姿估计的影响以及关键点选择方法的效果。我们还探讨了多任务学习的效果。
Comparisons to Directly Regressing Pose 为了将我们基于3D关键点的公式与直接回归对象的6D姿势参数[R,t]的公式进行比较,我们只需修改3D关键点投票模块Mk即可直接回归每个点的四元数旋转R和平移参数t。我们还在DenseFusion之后添加了一个置信度标题,并选择置信度最高的姿势作为最终提议的姿势。我们使用形状匹配损失[52] 和密集融合后的置信正则化项[50] 监督训练过程。表4中的实验结果表明,我们的3D关键点公式表现得更好。
为了消除不同网络结构的影响,我们还修改了DenseFusion的头(每像素)来预测每点的平移偏移,并根据关键点投票和最小二乘拟合过程计算6D姿势。表4显示,表中的3D关键点公式DF(3D Kp)比RT回归公式DF(RT)执行得更好。这是因为3D关键点偏移搜索空间比旋转空间的非线性小,这对神经网络来说更容易学习,使它们更具泛化能力。

Comparisons to 2D Keypoints 为了对比2D和3D关键点的影响,我们使用摄像机内参数将投票的3D关键点投影回2D。然后应用随机样本一致性PNP算法(RANSAC)计算6维姿态参数。表4显示,在Add-S度量下,具有3D关键点公式的算法(在表中表示为OURS(3D Kp))的性能比在表中表示为OURS(2D Kp)的2D KeyPoint(2D Kp)高13.7%。这是因为PNP算法的目标是最小化投影误差。然而,在3D真实世界中,投影中较小的位姿估计误差可能会相当大。
为了比较实例语义分割模块中2D和3D中心点之间的影响,我们还在实例语义分割模块(Ours(2D KPC))中将投票后的3D中心点投影到2D上。我们采用一种相似的均值漂移算法对投票后的2D中心点进行聚类,以区分不同的实例,发现在遮挡场景中,不同的实例在投影到2D上后,当它们的中心彼此接近时,很难区分,而在3D现实世界中,它们彼此远离,很容易区分。注意,其他现有的2D关键点检测方法,例如热图[33,24,34]和矢量投票[37]模型也可能受到关键点重叠的影响。根据定义,我们日常生活中的大多数对象的中心不会重叠,因为它们通常位于对象内部,而在投影到2D后,它们可能会重叠。总之,物体的世界是3D的,我们认为在3D上建立模型是相当重要的。
Comparisons to Dense Correspondence Exploring 我们修改了我们的3D关键点偏移模块MK,以输出物体坐标系中每个点对应的3D坐标,并应用最小二乘拟合算法来计算6自由度位姿。应用类似于公式3的L1损失来监督相应3D坐标的训练。评估结果显示为我们的(CORR)表4,这表明我们的3D关键点公式仍然执行得很好。我们认为,回归对象坐标比关键点检测更困难。因为模型必须识别图像中网格的每个点,并记住其在对象坐标系中的坐标。然而,在摄像机系统中检测对象上的关键点更容易,因为许多关键点是可见的,并且该模型可以聚集它们附近的场景上下文。
Effect of3D Keypoints Selection 在这一部分中,我们选择了3D边界框的8个角点,并将它们与FPS算法中选择的点进行了比较。此外,还考虑了FPS生成的不同数量的关键点。表5显示了FPS算法在对象上选择的关键点使我们的模型能够更好地执行。这是因为边界框角是远离对象上的点的虚拟点。因此,基于点的网络很难聚合这些虚拟角点附近的场景上下文。此外,从FPS算法中选择8个关键点是一个很好的选择,适合我们的网络学习。当在最小二乘拟合模块中恢复姿势时,关键点越多可能会更好地消除误差,但对于网络来说,由于输出空间更大,学习起来更困难。 选择8个关键点是一个很好的权衡。

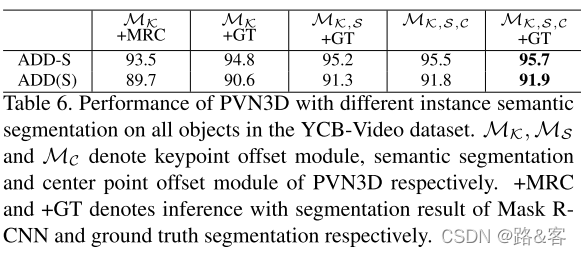
Effect of Multi-task learning 在这一部分中,我们讨论了语义切分和关键点(中心)平移的联合学习如何提高性能。在表6中,我们探索了语义分割如何增强关键点偏移学习。我们去掉了语义分割和中心投票模块MS、MC,并单独训练我们的关键点投票模块MK。在推理过程中,应用了MASK RCNN[15] (MK+MRC)预测的实例语义分割和基本真实值(MK+GT)。实验结果表明,结合语义分割(MK,S+GT)的联合训练提高了关键点偏移量投票的性能,并在ADD(S)度量上将6D姿态估计的精度提高了0.7%。我们认为,语义模块提取全局和局部特征来区分不同的对象。这些特征还有助于模型识别一个点属于对象的哪个部分,并改进偏移预测。
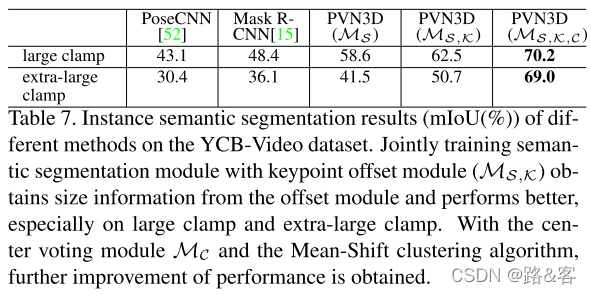
在表7中,我们探索了关键点和中心点偏移学习如何提高实例语义分割结果。并集上的点平均交集(MIOU)作为评价指标。我们在YCB-Video数据集中报告了具有挑战性的大夹子和超大夹子的结果。它们在外观上看起来一样,但大小不同,如图5所示。我们用推荐的设置作为简单的基线训练MASK R-CNN(ResNeXt-50-FPN)[15],发现它完全被这两个对象搞混了。有了额外的深度信息,我们单独训练的语义分割模块(PVN3D(MS))也表现不佳。然而,与我们的KeyPoint Offset投票模块(PVN3D(MS,K))联合训练后,MIUU在超大夹具上提高了9.2%。通过中心投票模块MC获得的投票中心,我们可以使用均值漂移聚类算法对对象进行分割,并将点分配到其最近的对象簇。通过这种方式,超大夹具的MIOU值进一步提高了18.3%。图5显示了一些定性结果。

Conclusion
提出了一种新的基于实例语义分割的深层3D关键点投票网络用于6DoF姿态估计,在多个数据集上的性能明显优于已有的方法。我们还表明,联合训练3D关键点和语义分割可以提高彼此的性能。我们认为,基于三维关键点的位姿估计方法是解决六自由度位姿估计问题的一个很有前途的方向。

















 2112
2112

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









