







目录
基于SV的验证方法学,目前市面上主要有三种,OVM(Open Verification Methodology)、VMM(Verification Methodology Manual)、UVM(Universal Verification Methodology)。OVM一开始就是开源的,它引入了factory机制,功能非常强大,但是它里面没有寄存器解决方案,这是它最大的短板。VMM中集成了寄存器解决方案RAL(Register Abstraction Layer)。
UVM在推出后得到了御三家Sysnopsys、Mentor和Cadence的支持,UVM几乎完全集成了OVM,在这基础上又采纳了Sysnopsys在VMM中的寄存器解决方案RAL。可以说UVM继承了VMM和OVM的优点又克服了各自的缺点,是验证方法学的发展方向。
对于UVM,一个验证工程师应该学会:
①如何使用UVM搭建验证平台,包括如何使用sequence机制、factory机制、callback机制、寄存器模型(register model)等。
②如何编写代码才能保证可重用性。如何保证自己在这个项目写的代码在下一个项目中依然可以使用,如何保证自己写出来的东西别人可以重用,如何保证子系统级的代码在系统级别依然可以使用。
③同样的一件事情有多种实现方式,这多种方式之间分别都有哪些优点和缺点,在权衡利弊之下哪种是最合理的。
工厂机制
UVM工厂的存在就是为了更方便地替换验证环境中的实例或者注册了的类型,同时工厂的注册机制也带来了配置的灵活性。
这里的实例或者类型替代,在UVM中称作覆盖(override),而被用来替换的对象或者类型,应该满足注册(regisration)和多态(polymorphism)的要求。UVM的验证环境构成可以分为两部分,一部分构成了环境的层次,这部分代码是通过uvm_component类完成的,另一部分构成了环境的属性(例如配置)和数据传输,这一部分通过uvm_object完成。
利用工厂可以完成对象的创建,创建对象之前需要对类进行注册。之所以对象要由工厂生产,是因为工厂的“生产模具”可灵活替代。这使得在不修改原有验证环境层次和验证包的同时,实现了对环境内部组件类型或者对象的覆盖。
uvm_component 和 uvm_object
在SV中学习到的一些组件的概念,验证环境的不动产:generator、stimulator、monitor、agent、checker、environment、test等,这些组件在uvm_component的子类中均有对应的组件。SV中的非固定资产,即一些TLM transaction,从generator流向stimulator的数据包,而这些类在UVM中统一由uvm_object表示。
UVM中绝大部分的类都是继承(extends)于uvm_object类型,凡是继承于object类型的类,第一步要做的事情就是“注册",注册使用了一个宏:`uvm_component_utils(类名) ,使用该宏就能够注册类,我们使用工厂的目的就是为了创建对象,而创建对象之前都需要注册。除此之外,如果是定义一个组件类的话,new函数的参数是固定的,有且仅有两个参数,参数必须是name和parent,这点和SV不一样。

上面代码段的"`uvm_component_utils(comp1)"和"super.new(name,parent)"都是固定的语法,在uvm中特别称为“范式”。
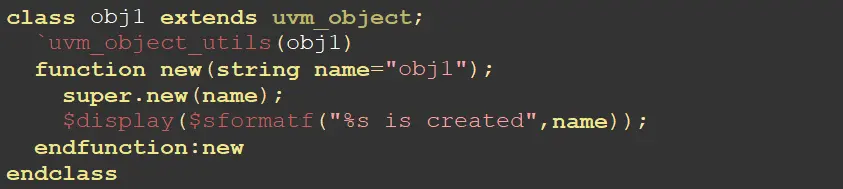
但是继承于uvm_object的类,注册方法和uvm_component一样,将中间关键词改为object就行,但是new函数和component不一样,且该格式固定不可修改,因此在定义类的时候,所定义的类是继承于uvm_object类还是uvm_component类要非常清楚,从而不会犯构建类(new)语法出错的情况。
总而言之,将类注册到工厂,就是三个步骤:①定义,extend;②注册,uvm_component/object_utils();③构建new函数。
uvm_component_utils和`uvm_object_utils两个宏做的事情都是将类注册到factory中,我们要知道,整个仿真中factory是独有的,有且仅有一个,这保证了所有类的注册都在一个“机构”中。
工厂创建对象的方法:
创建uvm_component对象时:

创建uvm_object对象时:

type_id就是你注册到工厂里面的类型。这里一句话里用到了两次两个冒号,第一个双冒号是在工厂里面找到我们注册的类,第二个双冒号用来创建对象,输入的内容根据定义类继承的父类情况选择传入name+uvm_component parent还是name。
uvm_coreservice_t类
该类内置了UVM世界核心的组件和方法,它们主要包括:
※ 唯一的uvm_factory,该组件用来注册、覆盖和例化;
※ 全局的report_server,该组件用来做消息统筹和报告;
※ 全局的tr_database,该组件用来记录transaction记录;
※ get_root()方法,用来返回当前UVM环境的结构顶层对象。
之所以要将该类单独的拉出来讲,是因为该类并不是uvm_component 或者 uvm_object,它也没有例化在UVM环境中,而是独立于UVM环境之外的。
uvm_coreservice_t 只会被UVM系统在仿真开始时例化一次。用户无需,也不应该自行再额外例化该核心服务组件。
覆盖方法(override)
覆盖机制可以将其原来所属的类型替换为另外一个新的类型。
在覆盖之后,原本用来创建原属类型的请求,将由工厂来创建新的替换类型。(无需再修改原始代码,继而保证了原有代码的封装性;新的替换类型必须与被替换类型相兼容,否则稍后的句柄赋值将失败,所以使用继承,即新定义的类型必须继承于原有的类型)
想要实现覆盖特性,原有类型和新类型均需要注册。
当使用create()来创建对象时:
※ 工厂会检查,是否原有类型被覆盖;
※ 如果是,那么它会创建一个新类型的对象;
※ 如果不是,那么它会创建一个原有类型的对象。
覆盖发生时,可以使用”类型覆盖“或者”实例覆盖“:
※ 类型覆盖指,UVM层次结构下的所有原有类型都被覆盖类型所替换;
※ 实例覆盖指,在某些位置中的原有类型会被覆盖类型所替换。(特别指定某些实例被替换)
覆盖方法set_type_override()

uvm_object_wrapper override_type并不是一个具体实例的句柄,而是注册过后的某一个类在工厂中注册时的句柄。怎么找到它呢?使用new_type::get_type()。
bit replace=1
1:如果已经有覆盖存在,那么新的覆盖会替代旧的覆盖。
0:如果已经有覆盖存在,那么该覆盖将不会生效。

覆盖方法 set_inst_override

string inst_path指向的是组件结构的路径字符串。
uvm_component parent=null;如果缺省,表示使用inst_path内容为绝对路径,如果有值传递,则使用 {parent.get_full_name(),"."inst_path} 来作为目标路径。

覆盖举例:假设有一个comp1类型,然后我们想用comp2来替代comp1
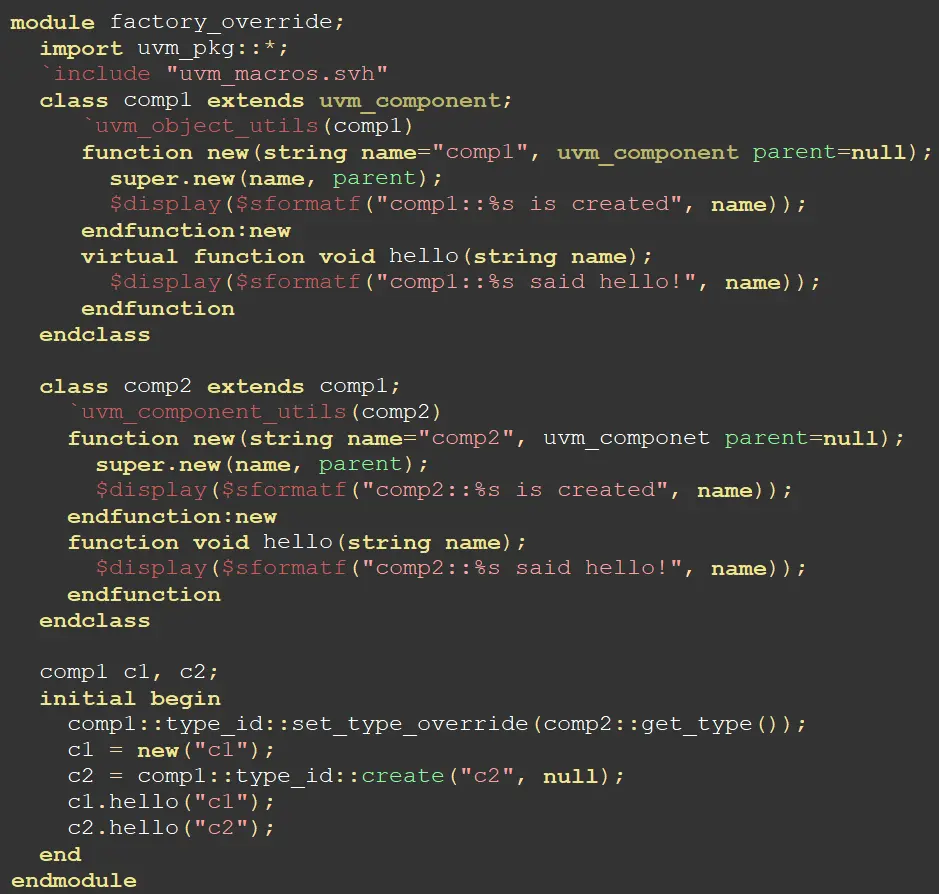
在代码段的最后一段,声明了c1、c2为父类句柄,因为在initial语句块第一行,声明将comp1覆盖为comp2,所以后续凡是工厂创建的comp1都是comp2类型。如果想要做覆盖,那么覆盖代码行一定要在创建代码行之前。但是如果多个地方对同一个类做了多次覆盖,那么采取parent win模式,层次越高的、覆盖优先级越高。
这里还有要注意的一点是,hello函数是一个虚方法(virtual function)。
在这条等式的右侧:c2 = comp1::type_id::create("c2", null);创建的句柄是一个子类的句柄(因为comp2继承于comp1,所以comp2是comp1的子类),但是将子类的句柄赋值给了父类(comp1)的句柄,所以在不使用virtual function的情况下,直接调用hello函数,调用的是父类的函数,但是如果使用了virtual function,则c2.hello 调用的是子类的hello函数。(关于虚方法可以看之前的专栏,有详细介绍)
核心基类 uvm_object
UVM世界中的类最初都是从一个uvm_void根类(root class)继承来的,而实际上这个类并没有成员变量和方法。uvm_void只是一个虚类(virtual class)。在继承于uvm_void的子类中,有两个类,一个为uvm_object类,另外一个为uvm_port_base类。
在UVM世界中,除了事务接口(transaction interface)类继承于uvm_port_base,其它所有的类都是从uvm_objec类一步步继承而来的。
域的自动化(field automation)
UVM通过域的自动化,使得用户在注册UVM类的同时,也可以声明今后会参与到对象拷贝、克隆、打印等操作的成员变量。
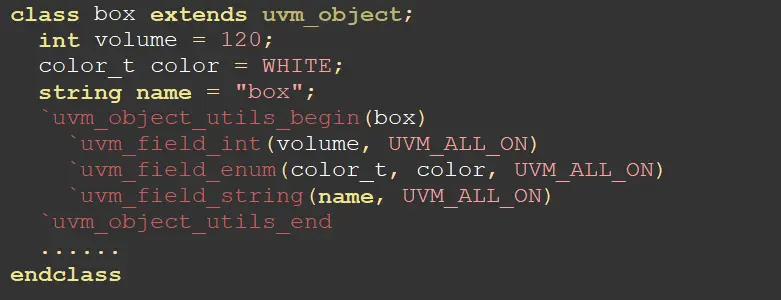
图中,由宏定义`uvm_object_utils_begin和`uvm_object_utils_end包起来的部分,为域自动化部分。UVM_ALL_ON是一个用于数据操作的内容,
为什么要做域的自动化声明?因为用了域的自动化声明,把变量声明后,那么接下来的一些操作例如copy,clone,compare等函数都不需要自己实现,UVM可以自动的调用函数帮你实现,而不需要像SV一样,在类中定义function。
掌握了域的自动化后,对于代码撰写效率、代码的维护都有很大帮助,因此在coding时最好养成习惯:
①在注册component或者object的时候,使用`uvm_{component,object}_utils_begin和`uvm_{component,object}_utils_end 来配对包裹接下来的域自动化。
②域的自动化的相关宏都是`uvm_field_{int,object,string,enum,event,real..}(ARG,FLAG)。ARG表示成员变量,FLAG表示用来标记的数据操作。通常情况下,对FLAG都默认采取UVM_ALL_ON或者UVM_DEFAULT,即将所有的数据操作方法都打开。
核心基类
拷贝(copy)
在UVM的数据操作中,需要对copy和clone加以区分;前者默认已经创建好对象,只需要对数据进行拷贝;后者则会自动创建对象并对source object 进行数据拷贝,再返回target object句柄。无论是copy还是clone,都需要对数据进行复制。
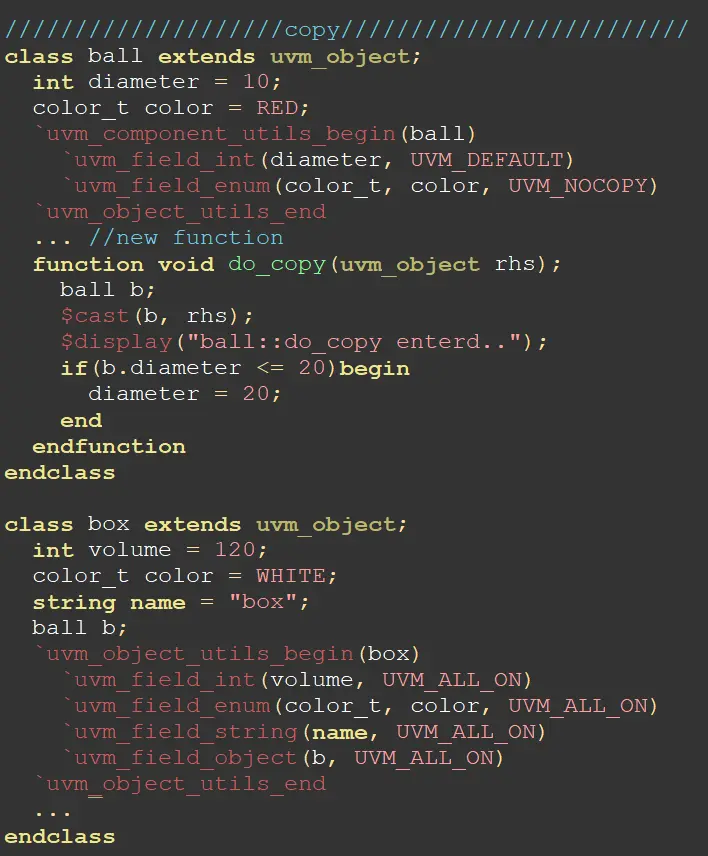
do_copy()是copy()的回调函数(callback),只要你定义了do_copy函数,那么在你调用copy()函数的时候,UVM就会自动的帮你调用do_copy函数。默认情况下,拷贝的方式是深拷贝。如果用户没有定义do_copy函数,那么在copy完之后不会执行额外的数据操作。
假设用box声明了两个句柄,分别为box1和box2,其内部各自声明了句柄设为b1和b2,那么在将box1 copy给 box2时,不仅仅会将box1和box2内部定义的变量copy过去,还会将b1和b2指向的对象的内容copy过去,更进一步的再调用do_copy函数深拷贝。(在声明变量时,如果声明UVM_NOCOPY则不会进行拷贝操作)
比较(compare)
function bit compare(uvm_object rhs, uvm_compare comparer=null);
默认情况下,如果不对比较情况做出额外配置,用户调用compare()方法时,省略第二项参数,即采用默认的比较配置。
比较方法经常会在两个数据类中进行。例如从generator产生的一个transaction(数据类),和在设计输出捕捉的transaction(数据类),如果它们为同一类型,除了可以自定义数据比较之外,也可以直接用uvm_objec::compare()函数来实现数据比较和消息打印。
打印(print)
打印方法是核心基类提供的另外一种便于开发和调试的功能,通过field automation
,使得声明之后的各个成员域会在调用uvm_object::print()函数时自动打印出来。
只要在field automation中声明过的域,在稍后的print()函数执行时,都将打印出它们的类型、大小和数值。如果用户不对打印的格式做出修改,那么在打印时,UVM会按照UVM_default_printer规定的格式来打印。
uvm_pkg所包含的用于打印的全局对象,它们分别是:
※ uvm_default_tree_printer: 可以将对象按照树状结构打印。
※ uvm_default_line_printer: 可以将对象数据打印到一行上面。
※ uvm_default_table_printer: 可以将对象按照表格的方式打印。
※ uvm_default_printer: UVM环境默认的打印设置,该句柄默认指向了uvm_default_table_printer。
通过给全局打印机uvm_default_printer赋予不同的打印机句柄,就可以调用任何uvm_object的print()方法时,得到不同的打印格式。
phase机制
SV的验证环境构建中,我们可以发现在传统的硬件设计模型在仿真开始之前就已经完成例化和连接了;而SV的软件部分对象例化则需要在仿真开始后执行。
虽然对象例化通过构建调用new()函数实现,但是无法解决验证环境在实现层次化时,如果保证例化的先后关系,以及各个组件在例化后的连接问题。因此UVM在验证环境构建时,引入了phase机制,通过该机制我们可以清晰地将UVM仿真阶段层次化。这里的层次化,不仅仅是phase的先后执行顺序,而且处于同一phase中的层次化组件之间的phase也有先后关系。
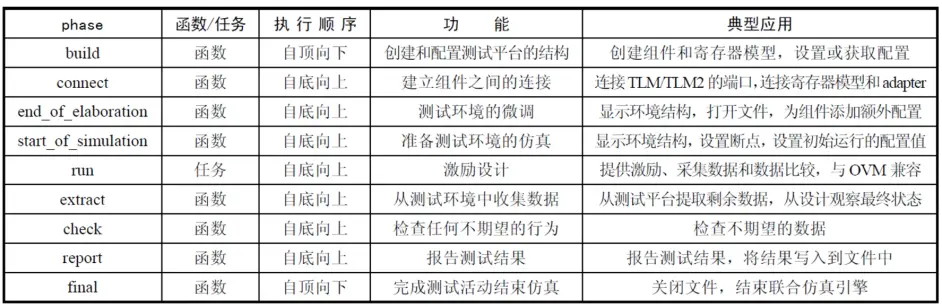
这个phase机制是uvm_component才具备的。用的比较多的就是build创建、配置测试平台;connect建立组件之间的连接;run,激励设计;report报告测试结果。这9个phase机制里只有run是task,其它8个都是function。
以上的9个phase机制,是顺序执行的,执行完上一个phase才会执行下一个phase。但是run phase中又可以分为12个分支phase,12个分支phase之间是串行执行的,相对于run phase是并行执行的,只有12个分支phase执行完了,run phase才执行完,才能进行下一步extract phase。
UVM编译和运行顺序:
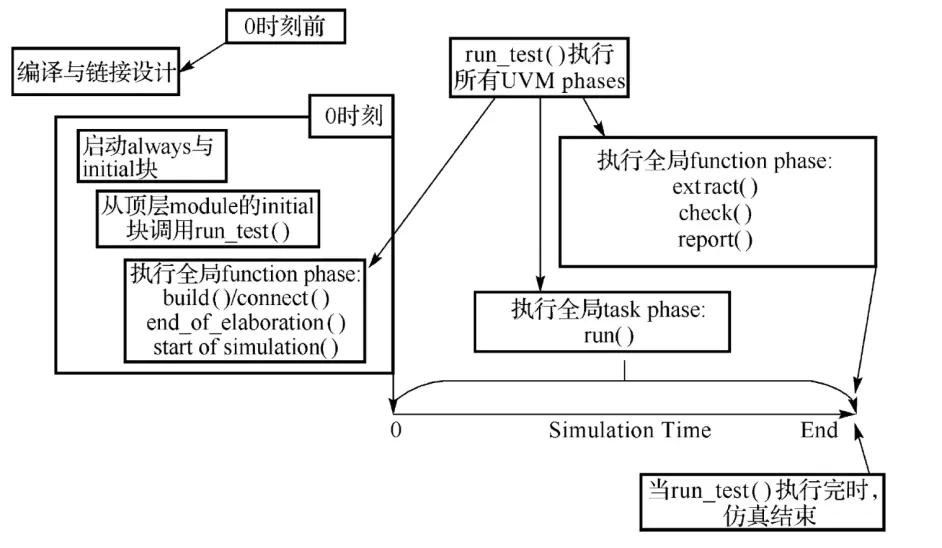
在仿真时,输入run 0,顶层模块的例化、initial块、调用run_test等都会执行完毕。
UVM仿真开始
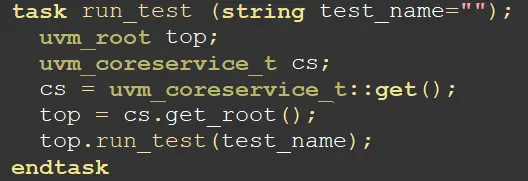
首先,拿到coreservice;然后通过coreservice拿到全局的顶层get_root();拿到顶层后在运行顶层的run_test();整个任务就是让root来创建一个test。
通过uvm_top调用方法run_test(test_name),uvm_top做了如下初始化:
① 得到正确的test_name;② 初始化objection机制(用于控制仿真退出); ③ 创建uvm_test_top实例;④ 调用phase控制方法,安排所有组件的phase方法执行顺序;⑤ 等待所有phase执行结束,关闭phase控制进程;⑥报告总结和结束仿真。
UVM1.1之后,结束仿真的机制有且仅有一种,就是利用objection挂起机制来控制仿真结束。uvm_objection类提供了一种所有component和sequence共享的计数器。如果有组件来挂起objection,那么它还应该记得落下objection。
任何一个组件在仿真的时候都能够选择挂起objection:
※ raise_objection(uvm_object obj=null,string description = "", int count=1)挂起objection
※ drop_objection(uvm_object obj=null,string description = "", int count=1)落下objection
※ set_drain_time(uvm_object obj=null, time drain)设置退出时间。
这个objection机制非常重要,在仿真的过程中,至少要有一个component挂起objection来防止仿真结束,这是UVM的范式。如果进入到run_phase阶段,没有组件把objection拉高,那么UVM就会立即退出run_phase而进入下一个阶段,这是UVM比较特殊的地方。

如果在上面的代码段里没有raise_objection,那么在run_phase阶段,进入到这个run_phase task中后,因为没有挂起objection,UVM会直接退出,只会执行进入run_phas0时刻时的`uvm_info执行,延迟1us后的uvm_info不会执行。

哪怕在run_phase中,有raise_objection,但是UVM在检查的时候,只会在进入run_phase task的时刻,检查是否有objection挂起,因此延迟1ps都是不被允许的。
config机制
在验证环境的创建过程中build phase中,除了组件的实例化,配置也是必不可少的。为了验证环境的复用性,通过外部的参数配置,使得环境在创建时可以根据不同参数来选择创建的组件类型、组件实例数目、组件之间的连接以及组件的运行模式等;更细致的,还能调节例如for-loop的阈值、字符串名称、随机变量生成比重等。
UVM提供了uvm_config_db配置类以及几种方便的变量设置方法来实现仿真时的环境控制,常见的uvm_config_db类的使用方式包括:
※ 传递virtual interface到环境中;
※ 设置单一变量值,例如int、string、enum等;
※ 传递配置对象(config object)到环境。
![]()
interface传递
interface的传递可以很好的解决连接软件和硬件的问题。在SV验证模块中,虽然SV可以通过层次化的interface的索引来完成了传递,但是这种方式不利于软件环境的封装和复用。
UVM的uvm_config_db使得接口的传递和获取彻底分离开来。
实现接口传递的过程应该注意:
※ 接口传递应该发生在run_test()之前;这保证了进入build phase之前, viritual interface已经被传递到uvm_config_db之中。
※ 用户应该把interface和virtual interface的声明区分开来,在传递过程中的类型应当为virtual interface,即实际接口的句柄。
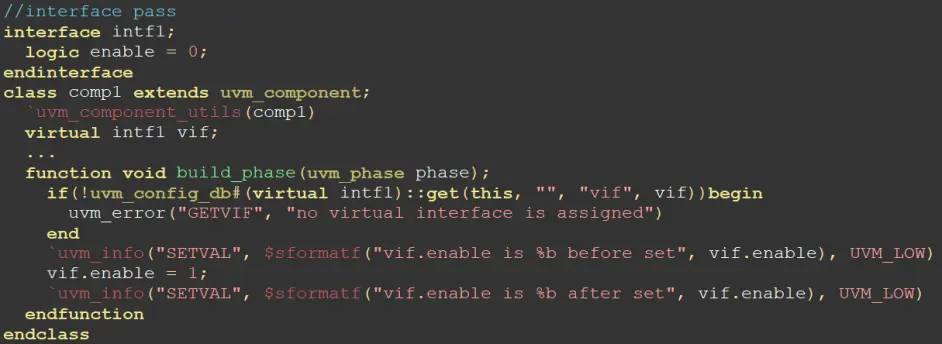
上图的uvm_config_db的使用其实就符合下面这个模板来的,T是参数类,上面的T写的为virtual interface类型的句柄。组件选择的是当前组件,实例名为无,因为已经是当前实例了,变量名选择了vif,赋值interface的名字为vif。

下面这个代码段在set的时候和上面的有所区别,但还是满足上面使用uvm_config_db做set和get的模板。
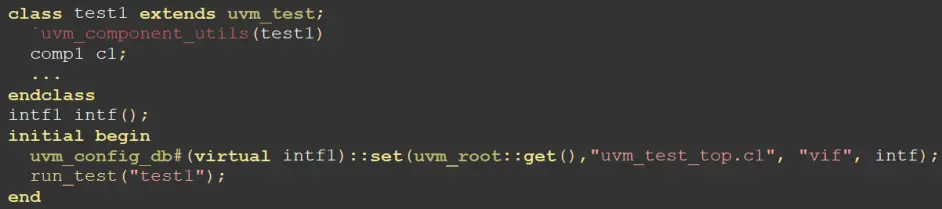
在initial语句块中,有run_test语句,在构建UVM环境的时候,必须要进行run_test("name")另外要注意interface的set和get的路径要保持一致,类型(参数类的类型)也要保持一致。
变量传递设置
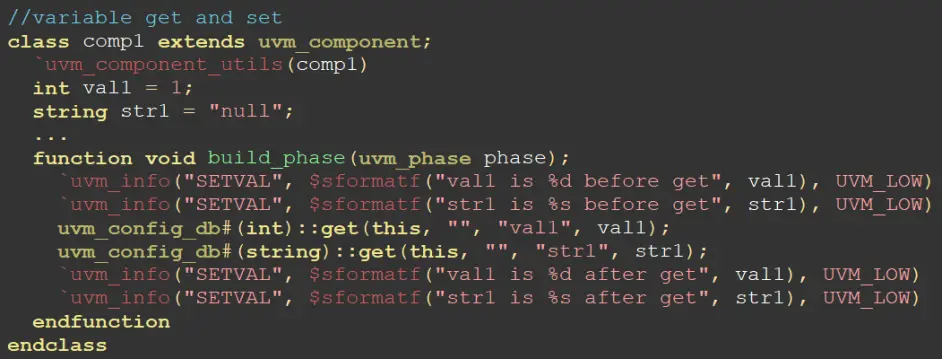
变量参数的设置模板也和之前一致,调用方法和前面interface传递一致。
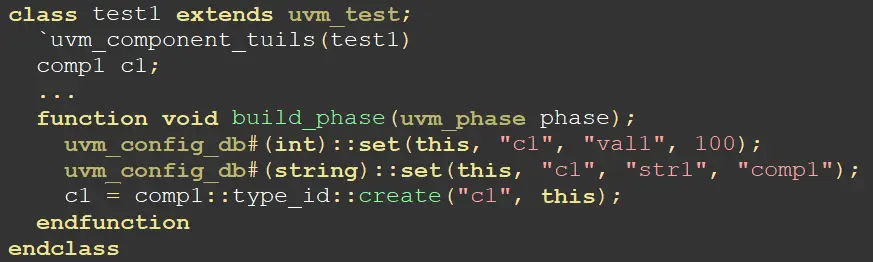
这里注意,set要在create之前,这是为了保证进入build phase之前,参数已经被传递到uvm_config_db之中。
uvm_config_db::set()通过层次和变量名,将这些信息放置到uvm_pkg唯一的全局变量uvm_pkg::uvm_resource。在使用uvm_config_db::get()方法时,通过传递的参数构成索引层次,然后再uvm_resource已有的配置信息池中索引该配置,如果索引到,方法返回1,否则返回0。
使用注意事项:
在使用set()/get()方法时,传递的参数类型应当上下保持一致。对于uvm_object等实例的传递,如果get类型与set类型不一致,应当首先通过$cast()完成类型转换,再对类型转化后的对象进行操作。譬如set进来一个子类的句柄,get进来是一个父类的句柄,那一定要做类型的转换。
总结:set/get配对、传递类型一致、传递路径一致、先做set再做get。
消息管理
在UVM环境中或者环境外,只要引入uvm_pkg,均可以通过下面的方法来按照消息的严重级别和冗余度来打印消息:

总共有四个严重级别(severity):UVM_INFO、UVM_WARNING、UVM_ERROR、UVM_FATAL,不同严重级别在打印的消息中也会有不同的指示来区别。
冗余度(verbosity):冗余度与消息处理中的过滤直接相关。冗余度的设置如果低于过滤的开关,那么该消息会打印出来,否则不会被打印出来。但是无论信息是否会被打印出来,这都与对消息采取的其它措施没有关系,例如仿真停止。
通常情况下,消息处理的方式是同消息的严重级别相对应的。如果用户有额外的需求,可以修改对各个严重级别的消息处理方式。
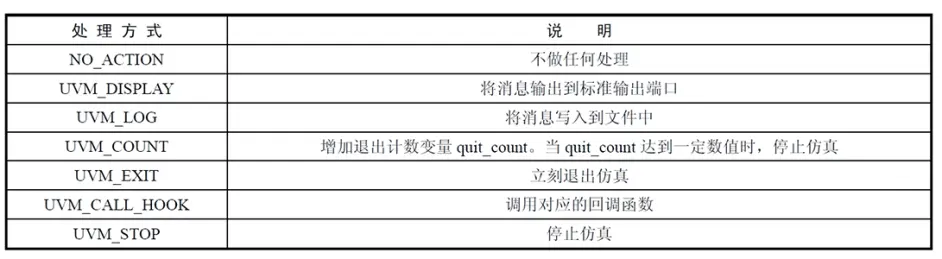
默认情况下,在不对严重程度进行声明时,默认的严重程度是LOW,一个比较高的严重等级,NONE为最高严重等级。

对于UVM_ERROR,当UVM_ERROR出现之后,仿真默认会停止,这是由于设置了UVM_ERROR的处理方式是UVM_COUNT数量达到上限(默认为1),即停止仿真。可以通过set_max_quit_count来修改UVM_COUNT值。
对于UVM_FATAL,遇到后会立即停止仿真。
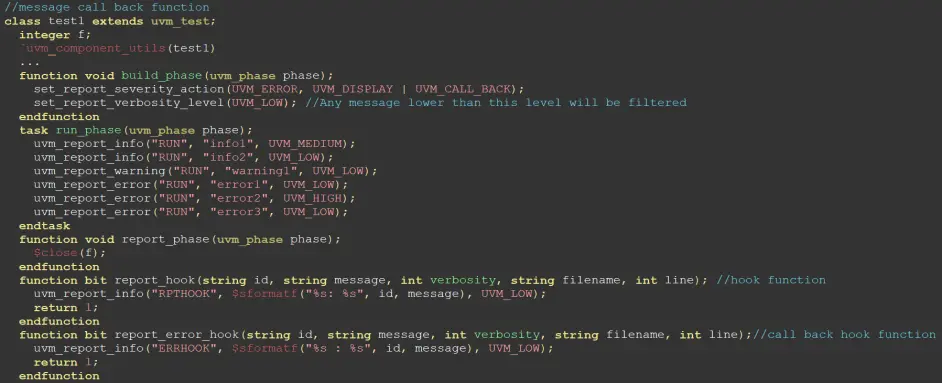
设置严重程度,set_report_verbosity_level(UVM_LOW)把严重程度的过滤设置为UVM_LOW



















 429
429

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











