







一、创建HSFPN.py代码
论文: https://arxiv.org/pdf/2401.00926.pdf
import torch
import torch.nn as nn
class MyChannelAttention_HSFPN(nn.Module):
def __init__(self, in_planes, ratio=4, flag=True):
super(MyChannelAttention_HSFPN, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.max_pool = nn.AdaptiveMaxPool2d(1)
self.conv1 = nn.Conv2d(in_planes, in_planes // ratio, 1, bias=False)
self.relu = nn.ReLU()
self.conv2 = nn.Conv2d(in_planes // ratio, in_planes, 1, bias=False)
self.flag = flag
self.sigmoid = nn.Sigmoid()
nn.init.xavier_uniform_(self.conv1.weight)
nn.init.xavier_uniform_(self.conv2.weight)
def forward(self, x):
avg_out = self.conv2(self.relu(self.conv1(self.avg_pool(x))))
max_out = self.conv2(self.relu(self.conv1(self.max_pool(x))))
out = avg_out + max_out
return self.sigmoid(out) * x if self.flag else self.sigmoid(out)
class Multiply(nn.Module):
def __init__(self) -> None:
super().__init__()
def forward(self, x):
return x[0] * x[1]
class Add(nn.Module):
def __init__(self):
super().__init__()
def forward(self, x):
return torch.sum(torch.stack(x, dim=0), dim=0)二、更改task.py(def parse_model(d, ch, verbose=True))
1.
from ultralytics.nn.modules.HSFPN import MyChannelAttention_HSFPN, Multiply, Add
2.加入nn.conv2d

编辑
3.
elif m is MyChannelAttention_HSFPN:
c2 = ch[f]
args = [c2, *args]
elif m is Multiply:
c2 = ch[f[0]]
elif m is Add:
c2 = ch[f[-1]]
三、配置网络
# Ultralytics YOLO 🚀, AGPL-3.0 license
# YOLO11 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect
# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolo11n.yaml' will call yolo11.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.50, 0.25, 1024] # summary: 319 layers, 2624080 parameters, 2624064 gradients, 6.6 GFLOPs
s: [0.50, 0.50, 1024] # summary: 319 layers, 9458752 parameters, 9458736 gradients, 21.7 GFLOPs
m: [0.50, 1.00, 512] # summary: 409 layers, 20114688 parameters, 20114672 gradients, 68.5 GFLOPs
l: [1.00, 1.00, 512] # summary: 631 layers, 25372160 parameters, 25372144 gradients, 87.6 GFLOPs
x: [1.00, 1.50, 512] # summary: 631 layers, 56966176 parameters, 56966160 gradients, 196.0 GFLOPs
# YOLO11n backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
- [-1, 2, C3k2, [256, False, 0.25]]
- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
- [-1, 2, C3k2, [512, False, 0.25]]
- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
- [-1, 2, C3k2, [512, True]]
- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
- [-1, 2, C3k2, [1024, True]]
- [-1, 1, SPPF, [1024, 5]] # 9
- [-1, 2, C2PSA, [1024]] # 10
# YOLO11n head
head:
- [-1, 1, MyChannelAttention_HSFPN, [4]] # 10
- [-1, 1, nn.Conv2d, [256, 1]] # 11
- [-1, 1, nn.ConvTranspose2d, [256, 3, 2, 1, 1]] # 12
- [6, 1, MyChannelAttention_HSFPN, [4]] # 13
- [-1, 1, nn.Conv2d, [256, 1]] # 14
- [13, 1, MyChannelAttention_HSFPN, [4, False]] # 15
- [[-1, -2], 1, Multiply, []] # 16
- [[-1, 13], 1, Add, []] # 17
- [-1, 2, C3k2, [256]] # 18 P4/16
- [13, 1, nn.ConvTranspose2d, [256, 3, 2, 1, 1]] # 19
- [4, 1, MyChannelAttention_HSFPN, [4]] # 20
- [-1, 1, nn.Conv2d, [256, 1]] # 21
- [20, 1, MyChannelAttention_HSFPN, [4, False]] # 22
- [[-1, -2], 1, Multiply, []] # 23
- [[-1, 20], 1, Add, []] # 24
- [-1, 2, C3k2, [256]] # 25 P3/16
- [[26, 19, 12], 1, Detect, [nc]] # Detect(P3, P4, P5)
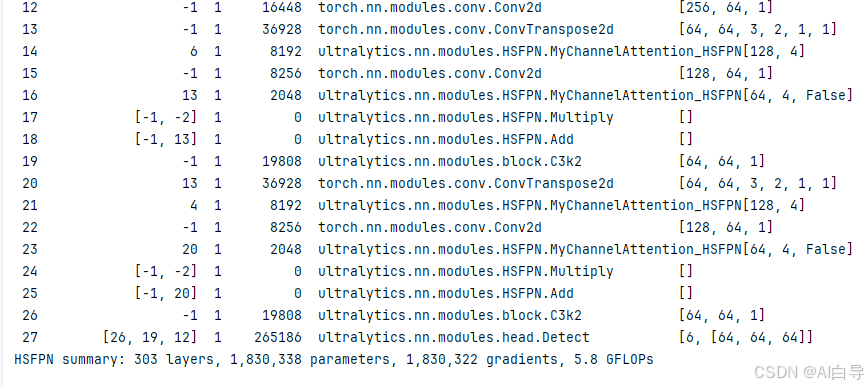
四、结果


















 685
685

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









