








Keywords: Finance ; LSTM ; Deep learning
本文来自于爱斯维尔的Expert Systems With Applications期刊
ABSTRACT
长短期记忆 (LSTM) 网络是预测金融时间序列 (FTS) 变动的最先进模型之一。然而,现有的LSTM网络在具有急剧变化点的长期预测FTS中表现不佳,这显着影响了累积收益。本文提出了一种基于改进的自适应 LSTM 模型的 FTS 运动长期预测新方法。自适应网络主要由两个 LSTM 层组成,后跟一对批归一化 (BN) 层、一个 dropout 层和一个二元分类器。为了捕捉重要的利润点,我们建议使用自适应交叉熵损失函数,增强对急剧变化的预测能力,并淡化轻微波动。然后,我们对多个独立网络进行预测,并对它们的输出数据进行投票,以获得稳定的预测结果。考虑到 FTS 的时间相关性,引入继承训练策略来加速执行长期预测任务时的再训练过程。所提出的方法通过包括“标准普尔500指数”、“中证指数300”和“上证180”等股票指数数据集的数值实验进行了评估和验证。事实证明,预测性能有了显着提高。此外,所提出的混合预测框架可以推广到不同的 FTS 数据集和深度学习模型。
1. Introduction
然而,现实世界中的大多数 FTS 数据都是非平稳、非线性随机信号,且受到噪声的严重污染。因此,当FTS中出现急剧变化点时,LSTM网络表现不佳。此外,随着时间的推移,LSTM网络的预测能力逐渐下降。这些不利特征会显着影响累积回报。为了克服这些限制,本文开发了一种具有多路径结构的自适应 LSTM-BN 模型,以对 FTS 运动进行可靠且长期的预测。基于几种常用股票指数的实验表明预测性能有了显着的提高。本文的主要贡献有四个方面,简要描述如下。
首先,众所周知,FTS 的运动方向为买卖决策提供了重要信息。然而,准确的价格预测并不一定意味着准确的价格走势预测(Sezer et al., 2020)。因此,FTS 预测任务可以表述为分类问题来预测未来交易时刻的运动方向。过去,Margarit 和 Subramaniam(2016)提出了一种用于句子情感分类的 LSTM 神经网络架构,其中对每个 LSTM 单元的输入数据、隐藏状态和单元状态使用批量归一化(BN)以加速网络训练。此外,CNN中还使用BN层来处理卷积层的输出,以加速网络训练并提高网络性能(Ioffe&Szegedy,2015)。与之前的工作不同,我们使用 BN 层来处理每个 LSTM 层的输出,旨在实现网络更高的训练速度和更好的泛化能力。本文建立了一个深度二元分类网络,即LSTM-BN,根据历史数据预测FTS的上/下方向。特别是,我们将 LSTM 层与 BN 层、dropout 层和分类器连接在一起,以提高分类精度。
其次,准确预测FTS的急剧变化点比微小的变化或振荡更有价值。在 FTS 急剧变化的时刻做出正确的交易决策也很重要,因为它们可能会对收益产生重大影响。另一方面,金融市场平稳阶段的预测失误对全球回报影响不大。从信号处理的角度来看,急剧的变化对应于FTS曲线的高频成分,而微小的变化和平滑状态则对应于低频成分。传统的分类模型普遍使用交叉熵损失函数,不足以区分高频和低频分量(Dixon et al., 2017)。为了解决这个问题,基于原始FTS数据的幅度加权,设计了自适应交叉熵损失函数,强调急剧变化的影响,同时减少轻微振荡的影响。所提出的自适应损失函数有利于捕捉重要的盈利点,从而易于提高回报。
第三,发现单个 LSTM-BN 网络有时对噪声和快速振荡敏感。即使网络在训练集上训练得很好,它也并不总是能在测试集上提供正确的预测。本文提出了一种多路径并行结构引入是为了提高LSTM-BN模型的稳定性。特别是,多个相同的 LSTM-BN 网络基于相同的训练集同时进行训练,但具有随机的初始化设置。由于初始化阶段涉及随机性,优化后的网络参数不一定相同。在测试阶段,所有这些LSTM-BN网络都会提供自己的预测结果,然后对最终决定进行投票。
最后,FTS 的时间相关性和特征可能会随着时间的推移而发生漂移。随着时间的推移,训练好的网络参数将会过期,从而导致预测性能下降。因此,提出了一种继承训练方法,当有足够的新数据可用时再次微调网络参数。为了减少重新训练过程的计算成本,网络将基于祖先网络参数进行微调。该方法产生了有意义的预测性能,并有效地加速了长期预测任务中的连续再训练过程。
本文将基于标准普尔500指数(S&P 500)、中证指数300(CSI 300)和上海证券交易所180(SSE 180)的股票指数数据集对所提出的预测方法进行评估和验证。总的来说,与标准LSTM网络相比,所提出的方法有效提高了运动方向的预测精度,从而获得更多的投资盈利能力。结果表明,在相同的交易策略下,所提出的方法可以在股票市场上获得更稳定和更高的平均回报。此外,还将详细讨论所提出的自适应交叉熵损失函数、投票方法和继承训练方法的效果。
本文的主要贡献总结如下:
首先,我们将 LSTM 层与 BN 层、dropout 层连接起来,以提高预测模型的分类精度和泛化能力。
其次,设计了自适应交叉熵函数来提高急剧变化点的预测性能。
第三,我们引入多路径并行结构和投票操作来提高预测模型的稳定性。
最后,开发了继承的训练方法,以在执行长期预测任务时有效地微调所提出的模型。
本文的其余部分安排如下。第 2 节回顾了 FTS 预测领域中一些广泛使用的深度学习模型。第 3 节描述了本文使用的数据集和数据预处理方法。第 4 节详细描述了我们的方法,包括提出的网络架构和预测方法。第 5 节描述了评估本文预测性能的指标。第 6 节介绍了实验设置、结果和分析。第七节总结了本文并讨论了未来的工作。
2. Related work
2.1. Deep multi-layer perceptron
2.2. Convolutional neural network
2.3. The LSTM network
3. Data preparation
3.1. Data resources
目前,一些研究人员建议预测股票市场指数,而不是预测单一股票的价格或走势。通常,与单一股票相比,股票市场指数的波动性较小,因为它们由来自不同地区的众多股票组成。股票指数更能反映金融市场的整体趋势和总体状况。 Bao、Yue、Rao 和 Boris(2017)表明,金融市场状况可能对所用模型的性能产生潜在影响。因此,在本文中,我们使用来自不同股票市场的三个指数的数据来证明所提出的预测方法的有效性。所选股指数据集通常用于 FTS 预测工作,即标准普尔 500、沪深 300 和上证 180(Sezer 等人,2020)。
标准普尔 500 指数由美国股市最大 500 家公司的股票组成。标准普尔500指数被普遍认为是美国股市的最佳表现指标,是发达金融市场的代表之一。相反,中国金融市场是全球最大的新兴市场,对国际金融市场的影响日益增强。为了证明所提方法的广泛适用性,我们还选择了中国沪深300和上证180指数作为实验数据集。上述三个股票指数提供了自然的设置来证明所提出的方法在不同金融市场条件下的稳健性。
正如我们之前提到的,股指有不同的行为或状态,包括急剧变化、小幅振荡、上涨和下跌。因此,在下面的实验中,我们选择了包含各种行为的三个股票指数的周期。具体来说,由于数据集的限制,许多先前的工作使用多年的价值数据作为训练集来训练他们的预测模型。包等人。 (2017)使用过去两年的股指价格数据来训练他们的模型,并测试下一季度模型的性能。在本工作的模拟部分,我们使用所选测试周期之前3年的指标数据作为训练集。
3.2. Data preprocessing
数据预处理是深度学习方法中非常重要的一步,对最终结果有重大影响。常用的数据预处理方法包括归一化、标准化和主成分分析。设X代表指数价格的原始数据集,Xi是数据集X中的第i个元素,代表第i天的指数价格。那么,第 i 天的收益定义为
![]()
为了加快训练速度并加强网络的泛化能力,对原始数据采用以下标准化方法:

其中μR和σR分别是R的平均值和标准差。 P 是标准化收益的数据集,用作所提出的预测模型的输入数据。标准化方法可以将原始数据集转化为标准高斯分布。例如,图1(a)显示了沪深300指数的原始价格数据集,图1(b)显示了相应的原始收益数据集,图1(c)显示了标准化收益。
4. Methodology
我们的方法由四个小部分组成。首先,定义并介绍原始LSTM网络。其次,提出了并行LSTM-BN网络。第三,开发了自适应交叉熵损失函数。最后,描述了自适应LSTM-BN模型的继承训练方法。本节的其余部分遵循上述四个步骤。
4.1. Structure of primitive LSTM network
4.2. Proposed LSTM-BN network
4.2.1. Basic structure of LSTM-BN network
过拟合是 FTS 预测任务中的一个严重问题。也就是说,训练后的模型可能非常适合训练集,但在测试集上的表现却不尽如人意。为了避免这个问题,需要较低的学习率和仔细的参数初始化培训程序。最近,许多技术被提出来解决这个问题,例如“dropout技术”和“BN变换”(Ioffe & Szegedy, 2015; Krizhevsky, Sutskever, & Hinton, 2012)。众所周知,4.1节中介绍的原始LSTM网络不使用BN层和dropout层。
Dropout是一种广泛使用的防止深度神经网络过拟合的方法(Krizhevsky et al., 2012)。在网络的前向传播中,dropout层以预设的速率随机禁用一些隐藏节点。禁用节点的输出值设置为零。在训练阶段的反向传播中,禁用节点的权重不会更新。 Ioffe 和 Szegedy (2015) 提出了 BN 变换来加快训练速度并提高卷积神经网络的泛化能力。值得注意的是,训练深度神经网络很复杂,因为每层输入的分布总是随着前一层参数的变化而变化。在训练和测试过程中,在激活函数之前使用BN变换对隐藏层的输出数据进行归一化,从而可以有效防止参数的不稳定变化。也就是说,BN变换可以保持隐藏层输出数据的相同分布,并有效加速模型训练过程(Ioffe&Szegedy,2015)。
为了克服FTS预测中的过拟合问题,需要在原始LSTM网络中添加BN层和dropout层。基于这一原理,论文提出了LSTMBN网络,它是在原始LSTM框架基础上修改而成的二元分类网络。图 3 说明了所提出的 LSTM-BN 网络的基本结构。它由五种层组成,包括一个输入层、两个LSTM层、两个BN层、一个dropout层和一个Softmax层。
输入层是一个全连接层,有k个神经元,每个神经元对应输入特征的一个元素。即每个训练样本包含k个连续的时间步数据。第一个 LSTM 层包含 h1 个隐藏神经元,第二个 LSTM 层包含 h2 个隐藏神经元。每个 LSTM 层后面都有一个 BN 层。第二BN层连接到dropout层,其中dropout率为g。在dropout层之后,使用Softmax层作为最终输出层来计算预测结果。值得注意的是,所提出的 LSTM-BN 网络执行二元分类来预测股票指数的上下波动。因此,Softmax层的神经元数量为c = 2,对应于分类中的两个类别。在上述网络模型中,k、h1、h2和g的值被视为超参数。
令 P k i 为小批量的输入样本,它是标准化 FTS 数据 P 从时间步长 t = i 到时间步长 t = i + k 的子部分,其中 P 在等式中定义。 (2)。样本 P k i 有一个对应的标签 yi+k+1,它代表原始指数价格 X 在下一个时间步 t = i + k + 1 的移动方向。 (1) yi+k+1 可表示为

其中 1 表示向上类别(价格上涨),0 表示向下类别(价格下降)。当输入样本P k i 进入LSTM-BN网络时,它将依次经过图3所示的各层。
具体来说,令 e = (e1, ... , ec ) 为 Softmax 层的输入值。根据 Joulin、Cissé、Grangier、Jégou 等人的说法。 (2017),Softmax 层第 i 个神经元的输出值可表示为

如果Ei是Softmax层的最大输出值,那么当前输入样本应该属于第i类。
4.2.2. Parallel LSTM-BN networks
具有适当超参数设置的单个 LSTM-BN 模型可以很好地拟合训练集。但由于FTS的随机特性,无法保证训练模型在测试集上的分类精度和预测稳定性。换句话说,经过训练的网络可能会退化为测试集上的“弱分类器”。为了将训练好的模型提升为测试集上的“强分类器”,我们提出了一种带有投票操作的并行 LSTM-BN 网络结构,以提高预测性能。图4展示了并行LSTM-BN网络的示意图,如下所述。
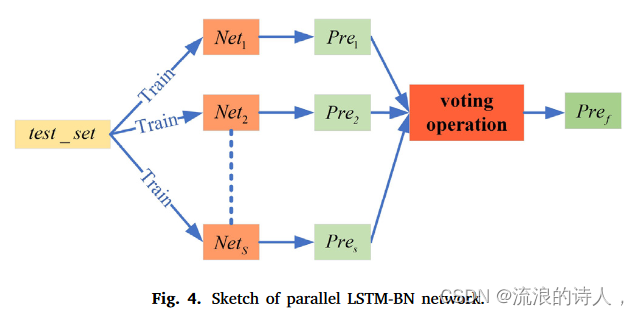
1.建立多个相同的 LSTM-BN 模型,即 Net1, ... , NetS ,其中 S 是大于 1 的奇数。使用相同的训练集,但使用不同的随机初始网络独立训练所有这些 LSTM-BN 模型参数。
2.使用所有这些网络独立地进行预测,并获得S个预测决策,表示为P re1,…,P reS 。值得注意的是,S 个预测决策可能不相同,因为网络参数是随机初始化的。
3.对 P re1, ... , P reS 执行投票操作,它们是同一时间步的预测决策。根据方程。 (9) 可知每个预测结果 Pres ∈ {0, 1}。因此,最终的预测决策 P ref 由下式给出
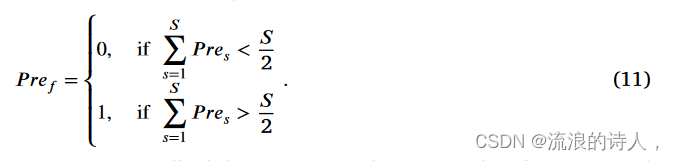
4.对于所有的测试样本,重复上述投票操作,即可得到一系列连续的预测决策。
4.3. Adaptive cross-entropy loss function
交叉熵损失函数广泛用于训练深度学习分类网络(Sezer et al., 2020)。对于具有 N 个训练样本 {x1, ... xN } 的小批量训练数据,交叉熵损失函数定义为

其中yn是第n个训练样本xn对应的分类标签,yn在式(1)中定义。 (9); En 是 Softmax 层的输出,其定义如式(1)所示。 (10)。显然,总损失是总和所有N个训练样本的损失值的总和,分类精度会随着损失值的减小而增加。
FTS具有不同的运动趋势,即急剧的变化点和轻微的振荡。如上所述,在急剧变化点的正确预测比在微小变化点的正确预测产生更多的回报。因此,为了获得更多的投资回报,我们希望提高急剧变化点的预测精度。然而,交叉熵损失函数对所有运动趋势一视同仁。它在训练过程中没有针对不同类型的样本自适应地进行梯度更新,削弱了对急剧变化点的预测能力。基于上述分析,我们提出了一种自适应交叉熵损失函数,它强调FTS中急剧变化的行为,而不强调轻微的振荡。给定 N 个训练样本 {x1, ... xN },自适应交叉熵损失函数定义为

其中 yn 和 En 对应于等式 1 中定义的第 n 个训练样本。 (12); Rn* 是下一个时间步的回报,其定义在式(1)中。 (1).与传统的交叉熵损失函数不同,自适应交叉熵损失函数利用下一次返回的数据来修正每个训练样本造成的损失值的大小。接下来解释自适应交叉熵函数的效果。
根据方程。 (13) 训练样本在急剧变化点的错误预测决策比在微小变化点的错误决策导致更大的损失惩罚。根据反向传播算法,损失值越大,网络参数的更新梯度越大。因此,当我们用自适应交叉熵函数训练预测模型时,网络参数将趋近于使模型在急剧变化点具有更强预测能力的状态。
一般来说,自适应交叉熵函数会考虑第1节中提到的不同类型的训练样本,使网络更好地学习股票指数的变化规律。此外,为了进一步避免过拟合现象,我们不强制预测模型完美拟合所有训练数据。即训练过程的分类准确率没有达到100%。相反,当训练集上的分类准确率达到预定义阈值(例如 Z = 95%)时,我们终止训练过程。
4.4. Inherited training method
本文使用的数据集是从真实的股票指数中收集的,具有时间相关性特征。对于FTS,未来趋势与过去的信息相关。很自然地假设过去时间步长中的数据样本与未来数据样本的相关性应该较低。另一方面,最近的过去时间步中的数据样本应该与未来的数据样本更紧密地相关。由于时间相关性随着时间间隔的增加而衰减,我们发现随着时间的推移,训练好的网络参数会“过时”,从而导致退化的预测性能。在这里,我们提出了一种继承的训练方法,当有足够的新股指数据可用时,再次微调网络参数。在fine-tune过程中,使用最新的新数据作为训练集来更新网络参数。为了降低计算成本,我们不想从随机初始设置再次训练网络参数。相反,当前的网络参数将被继承为微调过程中的初始设置,以更新网络模型。图5展示了继承训练过程的流程图,其中蓝色箭头表示训练过程,红色箭头表示测试过程,绿色箭头表示预测结果的串联。
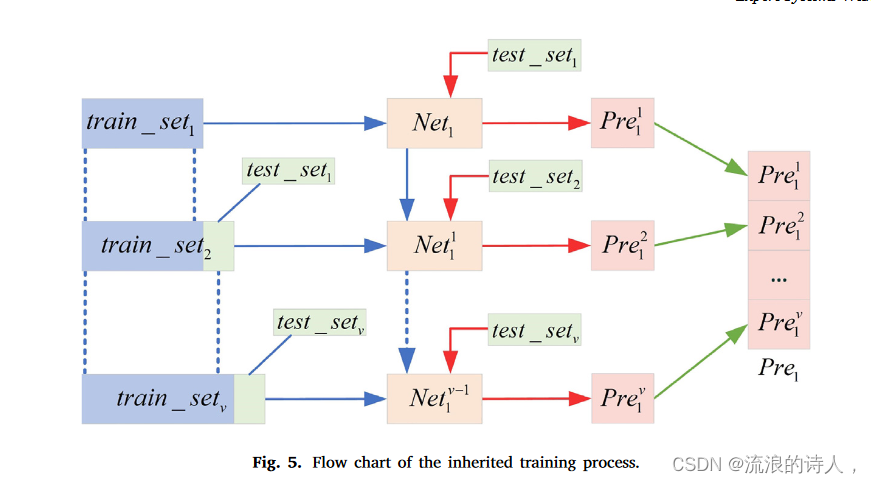
接下来,我们以单个LSTM-BN模型Net1为例来描述继承训练方法的工作流程。值得注意的是,继承的训练方法也适用于并行 LSTM-BN 网络 Net1, ... , NetS。接下来描述继承的训练方法。
1.随机初始化Net1的网络参数。然后,使用训练集train_set1和自适应交叉熵损失函数来训练Net1中的参数,训练后的模型记为Net1 1。
2.使用模型Net1 1对第一个测试集test_set1进行预测,该测试集包含d(d≪N)个样本。该组预测结果记为P re1。此外,train_set1和test_set1在时域上是连续的。
3.随着时间的推移,我们将从股市中获取test_set1的真实值。然后,将test_set1的真实值连接到train_set1的末尾,从而生成新的训练集train_set2。另外,我们将接下来一段时间的股指数据作为第二个测试集,记为test_set2。数据集test_set2也包含d个样本,并且train_set2和test_set2在时域上是连续的。
4.使用训练集 train_set2 训练模型 Net1 1。该训练过程的损失函数如式(1)所示。 (14),

其中 LALF 是自适应交叉熵损失项; pe(λ, θ1) 是惩罚项; λ 是约束优化参数与继承参数之间距离的惩罚权重; K是网络参数的数量; θk 1 是N et1 1 的第k个网络参数。惩罚项有助于避免过拟合。一般来说,当基于train_setp和Netp−1 1 训练第p个网络Netp 1 (p>1)时,损失函数定义为

使用train_step和Lp In进行训练后,模型Nesp−1 1更新为Netp 1。
5.使用模型Netp 1对第p个测试集test_setp进行预测。预测结果集记为 Prep
6.对于接下来的时间间隔,重复步骤3到步骤5,不断更新训练集train_set3,...,train_setv,并生成相应的预测结果P re3,...,P rev。然后,我们可以连接所有的预测结果来完成长期预测任务。
当我们处理test_setp时,test_setp−1可以被视为已知信息,因此将test_setp−1添加到训练集train_setp中是合理的。因此,继承的训练方法在实践中是可行的,并且可以增强LSTM-BN模型的长期预测能力。由于微调过程总是继承上一个时间间隔的网络参数,因此继承的训练过程的收敛速度非常快。
5. Metrics of forecasting performance
5.1. Forecasting accuracy
5.2. Returns ratio
6. Experiment results and analysis
7. Conclusion
本文开发了一种新颖的自适应 LSTM-BN 深度学习模型来预测 FTS 数据中的一步收盘价的运动方向。这项工作的主要贡献有四个方面,如下所述。首先,引入BN层和dropout层来修改原始LSTM网络,以避免运动方向预测中的过拟合问题。其次,提出了自适应交叉熵函数来增强急剧变化点的预测性能。第三,引入多路径并行结构和投票操作,提高预测模型的稳定性。最后,开发了继承训练方法,以随着时间的推移有效地更新网络参数,从而成功地保留了长期预测任务的预测性能。通过使用不同股票指数的一组数值实验验证了所提出的预测模型的有效性和鲁棒性。我们将所提出的预测模型与标准 LSTM 网络和其他两种深度学习模型在分类精度和盈利性能方面进行比较,并得到以下观察结果。首先,在提供的实验中,所提出的模型V平均可以优于采用“买入并持有”交易策略的金融市场,而某些预测模型在某些牛市时期可能不如金融市场。其次,Model V 总体优于其他竞争深度学习模型,以在选定的交易时段内获得更高的平均预测精度和收益率。最后,对第4节中提出的方法的效果和改进进行了研究和验证。请注意,所提出的预测模型可以推广到不同的 FTS 数据集。具体来说,所提出的方法有利于提高预测结果的稳健性并提高预测性能。未来,我们计划研究数据融合方法,将宏观经济数据和微观经济数据纳入预测模型,进一步提高盈利绩效。此外,还将通过在网络架构中引入最先进的深度学习模块来研究更先进的运动预测模型。















 1049
1049











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









