






Learning to Transform Dynamically for Better Adversarial Transferability
本文 “Learning to Transform Dynamically for Better Adversarial Transferability” 提出了 Learning to Transform (L2T) 方法,将最优变换组合选择视为轨迹优化问题,利用强化学习动态选择最优输入变换,提高对抗样本的可迁移性,经实验验证效果显著。
摘要-Abstract
Adversarial examples, crafted by adding perturbations imperceptible to humans, can deceive neural networks. Recent studies identify the adversarial transferability across various models, i.e., the cross-model attack ability of adversarial samples. To enhance such adversarial transferability, existing input transformation-based methods diversify input data with transformation augmentation. However, their effectiveness is limited by the finite number of available transformations. In our study, we introduce a novel approach named Learning to Transform (L2T). L2T increases the diversity of transformed images by selecting the optimal combination of operations from a pool of candidates, consequently improving adversarial transferability. We conceptualize the selection of optimal transformation combinations as a trajectory optimization problem and employ a reinforcement learning strategy to effectively solve the problem. Comprehensive experiments on the ImageNet dataset, as well as practical tests with Google Vision and GPT-4V, reveal that L2T surpasses current methodologies in enhancing adversarial transferability, thereby confirming its effectiveness and practical significance. The code is available at https: //github.com/ZhangAIPI/TransferAttack.
对抗样本是通过添加人类无法察觉的扰动生成的,它能够欺骗神经网络。近期研究发现,对抗样本具有跨多种模型的可迁移性,即对抗样本的跨模型攻击能力。为了增强这种对抗可迁移性,现有的基于输入变换的方法通过变换增强来使输入数据多样化。然而,其有效性受到可用变换数量有限的限制。在我们的研究中,我们引入了一种名为“学习变换”(Learning to Transform,L2T)的新方法。L2T从候选操作池中选择最优的操作组合,增加了变换后图像的多样性,从而提高了对抗可迁移性。我们将最优变换组合的选择概念化为一个轨迹优化问题,并采用强化学习策略来有效解决该问题。在ImageNet数据集上进行的全面实验,以及在谷歌视觉(Google Vision)和GPT-4V上的实际测试表明,L2T在增强对抗可迁移性方面优于当前方法,从而证实了其有效性和实际意义。
引言-Introduction
该部分主要介绍了研究背景、问题提出和研究贡献,旨在说明神经网络易受对抗样本攻击,现有基于输入变换的方法存在局限性,进而提出L2T方法,具体内容如下:
- 研究背景:神经网络在人脸识别、自动驾驶、医疗诊断等领域广泛应用,但易受对抗样本攻击。在实际对抗攻击场景中,常利用替代模型生成对抗样本攻击目标模型,这种跨模型攻击能力被称为对抗迁移性。目前增强对抗迁移性的方法包括基于梯度、输入变换、架构和集成的方法,其中基于输入变换的方法因即插即用优势备受关注。
- 问题提出:现有基于输入变换的方法在生成对抗样本时采用固定变换,限制了变换操作的灵活性。虽然有研究尝试通过预计算增强策略或使用生成模型来改进,但仍受限于变换数量。为充分利用有限的变换,需要找到最优的变换组合,然而其搜索空间巨大,难以确定最有效的组合。
- 研究贡献:提出L2T框架,通过强化学习动态学习和应用最优输入变换,减少搜索空间,提高变换多样性和对抗迁移性;将最优变换组合选择问题转化为轨迹优化问题,有效解决了传统方法的局限性;在ImageNet数据集及谷歌视觉、GPT-4V等实际场景的实验中,L2T表现优于其他基线方法,验证了其有效性和实用性。
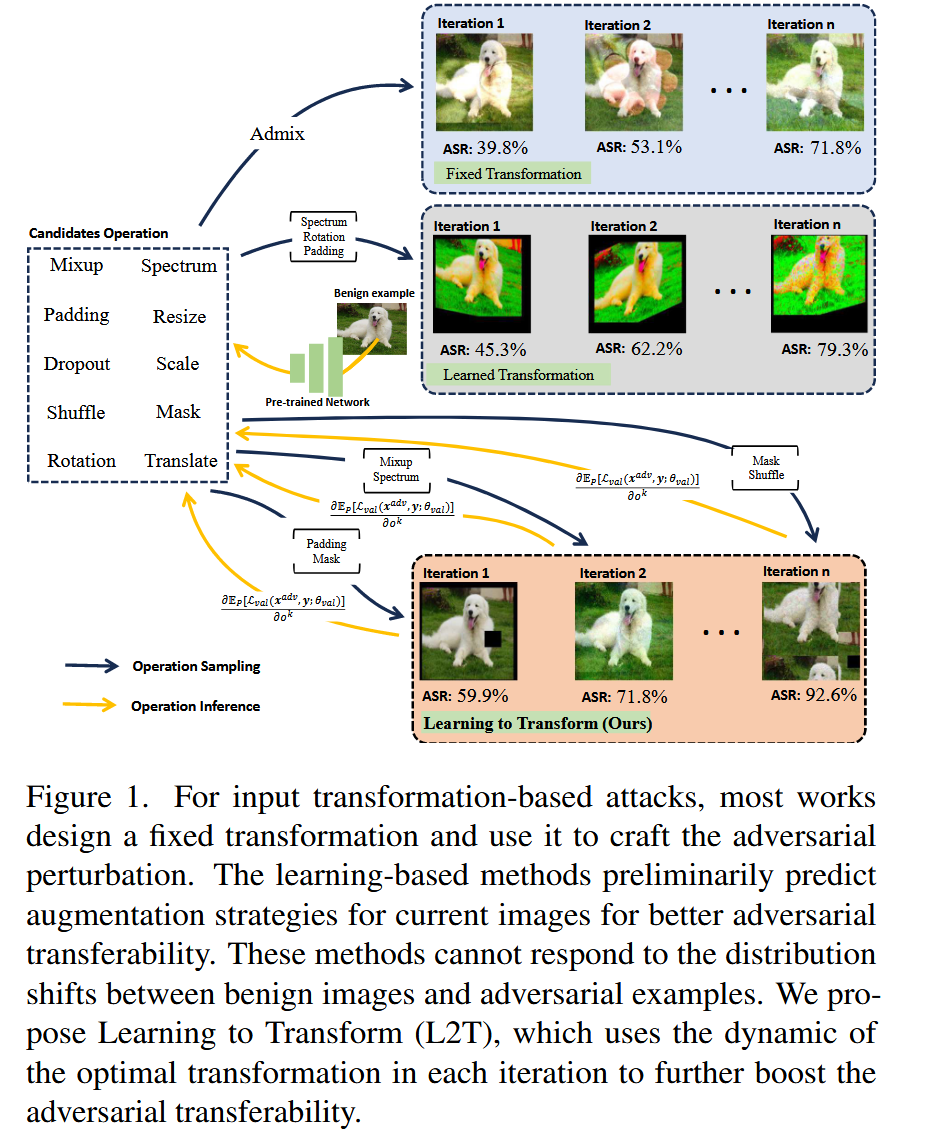
图1. 对于基于输入变换的攻击,大多数研究设计一种固定的变换,并使用它来生成对抗扰动。基于学习的方法会初步预测当前图像的增强策略,以提高对抗迁移性。但这些方法无法应对良性图像和对抗样本之间的分布变化。我们提出了学习变换(L2T)方法,该方法利用每次迭代中最优变换的动态特性,进一步提升对抗迁移性。
相关工作
该部分主要回顾了对抗攻击和对抗防御两方面的相关研究,为后续提出的L2T方法做铺垫,具体内容如下:
- 对抗攻击
- 多种攻击方式:存在基于梯度的攻击、基于输入变换的攻击等多种对抗攻击方法。其中基于变换的攻击因无需目标模型信息,在攻击现实中的深度模型时应用广泛,引发众多研究。
- 提升对抗迁移性的方法:为提升对抗迁移性,提出了多种基于动量的攻击方法,如 MI-FGSM、NI-FGSM 等。同时,也有不少输入变换方法,如 DIM、TIM 等,这些方法通过对用于对抗扰动计算的图像进行增强,提升对抗迁移性,且能与基于梯度的攻击结合提升性能。但多数基于输入变换的方法局限于设计固定变换,限制了图像变换的多样性和对抗迁移性。为此,部分研究尝试用预训练网络预测多种变换来增强图像,如AutoMA采用近端策略优化算法搜索强增强策略,ATTA 使用对抗变换网络建模有害失真,AITL 将不同图像变换整合到统一框架学习自适应变换 。
- 对抗防御:提出了多种防御方法,包括对抗训练、输入预处理、特征去噪、认证防御等。例如,Liao等人训练去噪自动编码器HGD净化对抗扰动;Xie等人提出随机调整图像大小和添加填充的R&P方法减轻对抗效果;Xu等人的比特深度减少(Bit-Red)方法通过减少像素比特数挤压扰动;Liu等人用基于JPEG的压缩方法防御;Cohen等人采用随机平滑(RS)训练可证明鲁棒的分类器;Naseer等人提出神经表示净化器NRP消除扰动。
L2T-Learning to Transform
任务定义-Task definition
该部分主要定义了对抗样本生成任务以及基于输入变换方法在其中的应用,为后续理解L2T方法奠定基础,具体内容如下:
- 对抗样本生成的迭代框架:对抗样本的制作通常采用迭代框架来更新对抗扰动。给定良性样本 x x x 及其标签 y y y,基于迁移的攻击利用替代分类器 f θ f_{\theta} fθ,迭代更新对抗样本 x a d v x^{adv} xadv,以最大化 f θ ( x a d v ) f_{\theta}(x^{adv}) fθ(xadv) 被误分类为 y y y 的损失。以I-FGSM为例,第 t t t 次迭代时的对抗样本 x t a d v x_{t}^{adv} xtadv 可表示为 x t a d v = x t − 1 a d v + α ⋅ s i g n ( ∇ x t − 1 a d v J ( f θ ( x t − 1 a d v , y ) ) ) x_{t}^{adv}=x_{t - 1}^{adv}+\alpha \cdot sign(\nabla_{x_{t - 1}^{adv}}J(f_{\theta}(x_{t - 1}^{adv}, y))) xtadv=xt−1adv+α⋅sign(∇xt−1advJ(fθ(xt−1adv,y))),其中 α \alpha α 为步长, J ( ⋅ , ⋅ ) J(\cdot, \cdot) J(⋅,⋅) 为分类损失函数。
- 基于输入变换的方法:基于输入变换的方法是提升对抗迁移性的有效手段之一。在该方法中,对抗样本首先会经过一组图像变换操作 φ \varphi φ( φ = { o i ∣ i ∈ { 1 , 2 , … , k } } \varphi = \{o^{i} | i \in \{1, 2, \ldots, k\}\} φ={oi∣i∈{1,2,…,k}}, o i o^{i} oi 为具体的图像变换操作),然后再进行梯度计算。在第 t t t 次迭代时,对抗样本 x t a d v x_{t}^{adv} xtadv 会按顺序经过 φ \varphi φ 中的操作变换,即 φ ( x t a d v ) = o k ⊕ o k − 1 ⊕ ⋯ ⊕ o 1 ( x t a d v ) \varphi(x_{t}^{adv}) = o^{k} \oplus o^{k - 1} \oplus \cdots \oplus o^{1}(x_{t}^{adv}) φ(xtadv)=ok⊕ok−1⊕⋯⊕o1(xtadv) ,之后利用 φ ( x t a d v ) \varphi(x_{t}^{adv}) φ(xtadv) 关于损失函数的梯度,按照上述I-FGSM的公式更新对抗扰动。
- 选择操作集的两类方法:以往研究中选择操作集 φ \varphi φ 主要有两类方法。一类是设计固定变换的方法,使用预定义的变换 φ \varphi φ,如 Admix 选择mixup和scaling作为变换操作;另一类是基于学习的变换方法,通常使用生成模型直接生成变换后的 φ ( x ) \varphi(x) φ(x)。相比之下,基于学习的方法生成的变换图像具有更多样性,在对抗迁移性方面表现更优,本文重点研究这类方法。
动机-Motivation
该部分主要阐述了研究L2T方法的动机,通过实验分析发现增加变换图像数量不一定能提升对抗迁移性,进而引出寻找最优变换组合的问题,具体内容如下:
- 增加变换图像数量的局限性:以往研究设计了多种变换来提高图像多样性,引导对抗攻击聚焦于不变的鲁棒特征。但并非增加变换图像数量就一定能提升对抗迁移性,因为某些变换组合可能会破坏原始样本,导致用于可迁移攻击的信息大量丢失。
- 不同迭代次数下的实验分析
- 一次迭代实验:以ResNet-18生成对抗样本攻击其他9个模型为例,选取裁剪、旋转、打乱、缩放和混合(crop、rotation、shuffle、scaling、mix-up)5种输入变换操作,对5张图像进行攻击并记录被误导的模型数量。结果表明,在一张狗的图像上,使用打乱操作能达到最大的可迁移攻击成功率,说明在这5种可能的操作中存在针对该图像的最优变换。
- 两次迭代实验:同样的设置下,第一次迭代选择裁剪,第二次迭代选择缩放,能成功误导9个模型中的6个。而一次迭代中的最优变换打乱,在两次迭代场景下平均误导模型的数量比裁剪少0.2,无法保持最优性能。

图2. 不同操作在提升对抗迁移性方面的比较。方框中的数字表示被误导的模型数量(最大值为9)。在图(a)中,横轴表示不同的变换操作,纵轴表示不同的良性样本。在图(b)中,纵轴表示第一次迭代中使用的变换,横轴表示第二次迭代中使用的变换。 - 三次迭代实验:只采用一种操作作为图像变换进行攻击,存在多种可能的变换轨迹。例如,先打乱、再旋转、最后再打乱的轨迹能达到最佳性能;但像每次迭代分别采用缩放、打乱和旋转的轨迹,攻击成功率却是最差的。这表明增加变换数量以提高多样性并不总能带来最佳性能。
- 提出寻找最优变换轨迹的问题:综合上述实验,为了获得最佳的对抗迁移性,需要确定一个最优变换轨迹
T
\mathcal{T}
T,它是每次迭代中使用的变换序列
(
φ
1
,
φ
2
,
…
,
φ
T
)
(\varphi_{1}, \varphi_{2}, \ldots, \varphi_{T})
(φ1,φ2,…,φT)。然而,寻找
T
∗
=
a
r
g
m
a
x
T
(
E
[
L
(
f
θ
(
x
T
a
d
v
)
,
y
)
]
)
\mathcal{T}^{*}=\underset{\mathcal{T}}{argmax}(\mathbb{E}[\mathcal{L}(f_{\theta}(x_{\mathcal{T}}^{adv}), y)])
T∗=Targmax(E[L(fθ(xTadv),y)]) 面临诸多困难,如搜索空间大(假设5种候选变换,10次迭代就有
5
10
5^{10}
510种可能的搜索空间)、无法访问黑盒模型难以直接优化公式,且不同图像的最优变换不同,不存在通用的最优变换轨迹。
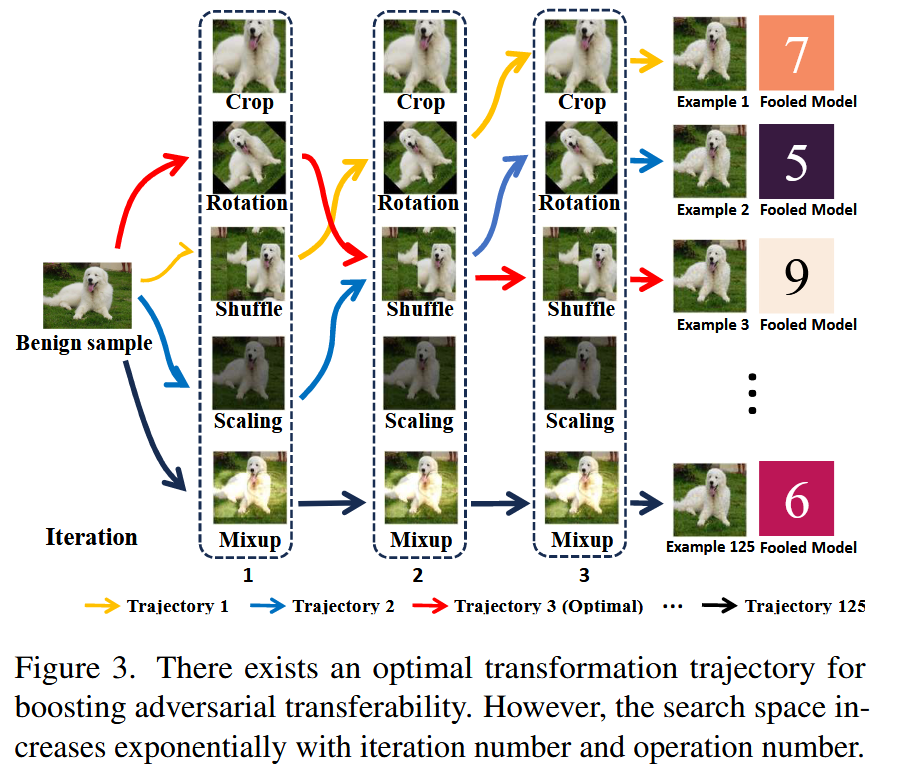
图3. 存在一种能提升对抗迁移性的最优变换轨迹。然而,搜索空间会随着迭代次数和操作数量的增加呈指数级增长。
方法-Methodology
该部分主要介绍了L2T方法的具体实现,将寻找最优变换轨迹问题转化为强化学习问题,通过动态优化采样概率来提高对抗迁移性,具体内容如下:
- 转化为强化学习问题:将寻找最优变换轨迹的问题转化为最优轨迹搜索问题,采用强化学习方法求解。假设有 M M M 个操作 o 1 , o 2 , … , o M {o^{1}, o^{2}, \ldots, o^{M}} o1,o2,…,oM,最优变换轨迹 T \mathcal{T} T 是不同操作组合的时间序列。每次迭代的采样概率 P P P 包含 M M M 种可能性 p o 1 , p o 2 , … , p o M {p_{o^{1}}, p_{o^{2}}, \ldots, p_{o^{M}}} po1,po2,…,poM,且 ∑ m = 1 M p o m = 1 \sum_{m = 1}^{M} p_{o^{m}} = 1 ∑m=1Mpom=1。一个变换 φ \varphi φ 由 K K K 个操作 o k o^{k} ok 组成,从 p p p 中采样 K K K 个操作得到变换 φ \varphi φ 的概率为 P ( φ ) = ∏ k = 1 K p o k P(\varphi)=\prod_{k = 1}^{K} p_{o^{k}} P(φ)=∏k=1Kpok 。
- 优化采样分布:为得到最优轨迹 T = ( φ 1 , … , φ T ) \mathcal{T}=(\varphi_{1}, \ldots, \varphi_{T}) T=(φ1,…,φT),需要在每次迭代 t t t 中动态优化采样分布 p p p。将每次迭代中搜索最优 p ∗ p^{*} p∗ 的问题表述为一个双层优化问题,内层优化目标是优化对抗样本,外层优化试图找到最优采样概率。采用一步优化策略得到近似的 p ∗ p^{*} p∗ ,即 p ∗ ≈ p + ρ ⋅ g p p^{*} \approx p+\rho \cdot g_{p} p∗≈p+ρ⋅gp,其中 ρ \rho ρ 是学习率, g p g_{p} gp 是 p p p 的梯度。
- 实现细节:首先,根据采样分布 P P P 采样 L L L 个变换序列 φ t l \varphi_{t}^{l} φtl ;接着,对对抗样本进行变换得到 φ t l ( x t a d v ) \varphi_{t}^{l}(x_{t}^{adv}) φtl(xtadv);然后,利用 L L L 个变换后样本与对应标签的损失计算梯度,依据梯度更新对抗样本;最后,更新对抗样本后重新计算近似的 P P P ,具体通过计算每个采样操作 o k o^{k} ok 的梯度 g o k g_{o^{k}} gok,将其拼接得到 g p g_{p} gp,使用梯度上升法以学习率 ρ \rho ρ 更新 p p p 。

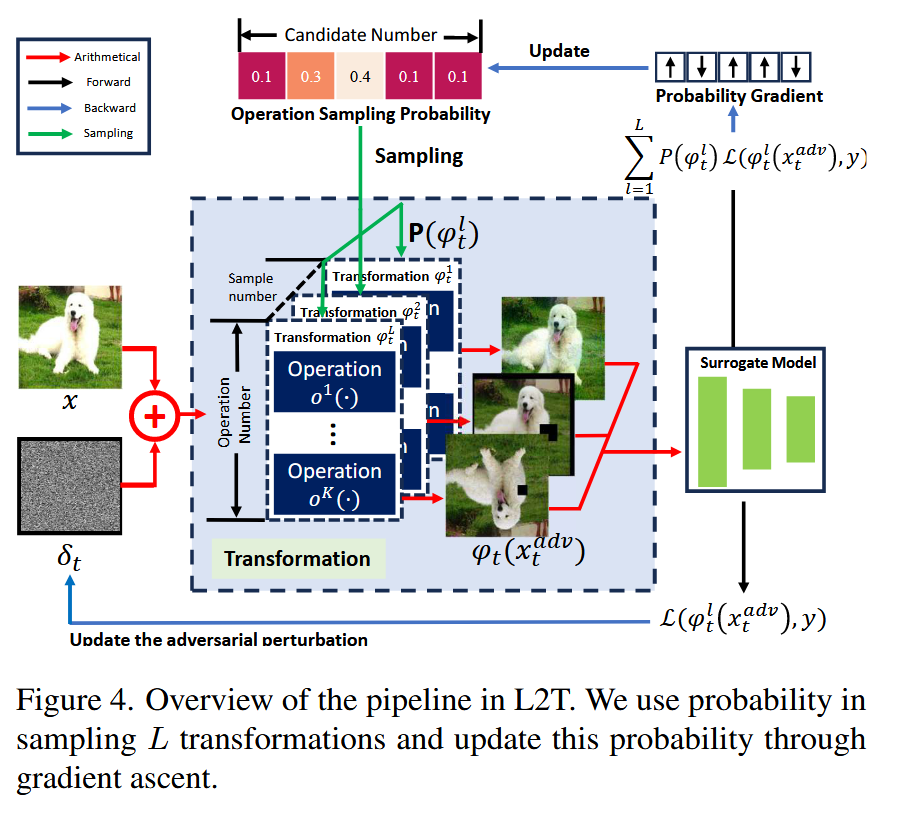
图4. L2T方法流程概述。我们通过概率采样
L
L
L 个变换,并利用梯度上升法更新该概率。
实验-Experiments
该部分主要介绍了文章中关于L2T方法的实验设置、评估结果和消融研究,以验证L2T在提升对抗样本可迁移性方面的有效性和性能,具体内容如下:
- 实验设置
- 目标模型:选用三类目标模型,包括在ImageNet数据集上预训练的十个知名模型,如ResNet18、ResNet - 101等;采用对抗训练(AT)、高维表示引导去噪器(HGD)等四种防御方法训练的模型;以及Google Vision、Azure AI、GPT - 4V和Bard等流行视觉API。
- 数据集:从ILSVRC 2012验证集中随机选取1,000张被模型正确分类的图像。
- 对比基线:将L2T与两类基于输入变换的对抗方法对比,一类是固定变换攻击方法,如TIM、SIM等;另一类是学习变换攻击方法,如AutoMA、ATTA等,这些方法均与MI - FGSM结合生成对抗样本。
- 评估设置:遵循MI - FGSM的超参数设置,如扰动预算 ϵ = 16 \epsilon = 16 ϵ=16 ,迭代次数 T = 10 T = 10 T=10 等。L2T的超参数设置为操作数 K = 2 K = 2 K=2,样本数 L = 10 L = 10 L=10 ,学习率 ρ = 0.01 \rho = 0.01 ρ=0.01,候选操作包含十类变换,每类有十个不同参数的具体操作。
- 评估结果
- 单模型评估:以单个模型为替代模型,评估平均攻击成功率(ASR)。L2T在所有替代模型上的表现均优于其他攻击者,即使在最差情况下,也比最强基线方法的ASR高2.1%,平均高出22.9%。
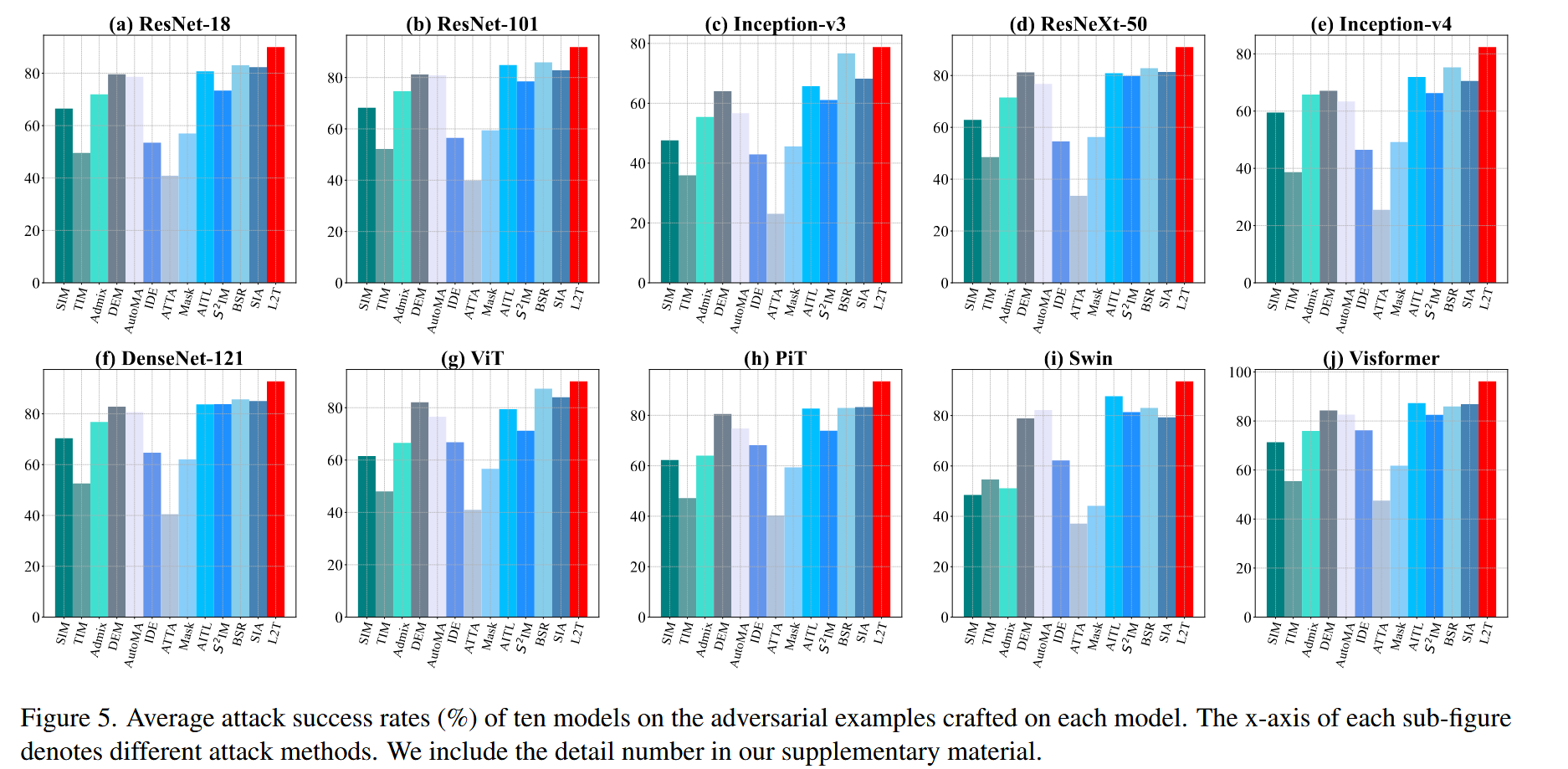
图5. 十个模型对基于每个模型生成的对抗样本的平均攻击成功率(%)。每个子图的x轴表示不同的攻击方法。详细数据包含在我们的补充材料中。 - 防御方法评估:在攻击采用多种防御机制的模型时,L2T依然有效。在对抗AT、HGD、NRP和RS防御时,其攻击成功率分别达到47.9%、98.5%、87.2%和46.7%,在认证防御RS上比最佳基线方法AITL高4.6%。
- 视觉API评估:在模拟现实场景的视觉API测试中,L2T表现最佳。在仅视觉API上,比最强基线方法分别高出8.7%和12.6%;在基础模型API(如GPT - 4V和Gemini)上,攻击成功率接近100%。
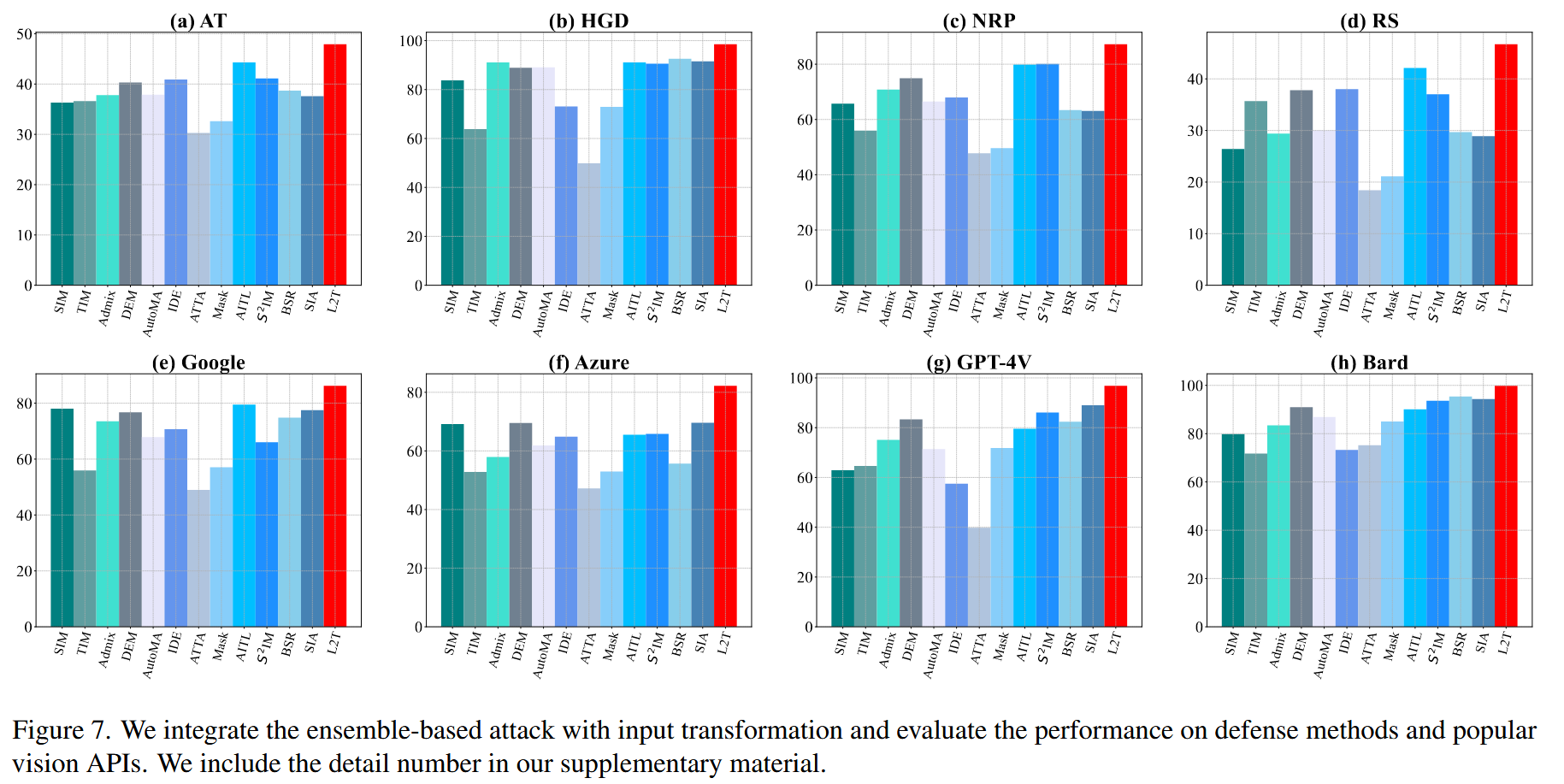
图7. 我们将基于集成的攻击与输入变换相结合,并评估其在防御方法和流行视觉API上的性能。详细数据包含在我们的补充材料中。
- 单模型评估:以单个模型为替代模型,评估平均攻击成功率(ASR)。L2T在所有替代模型上的表现均优于其他攻击者,即使在最差情况下,也比最强基线方法的ASR高2.1%,平均高出22.9%。
- 消融研究
- 操作数
K
K
K 的影响:研究发现,
K
K
K 从1增加到2时,平均攻击成功率显著提升8.09% ,但
K
≥
3
K\geq3
K≥3 时提升幅度变小,因此建议
K
K
K 适中设置为2。
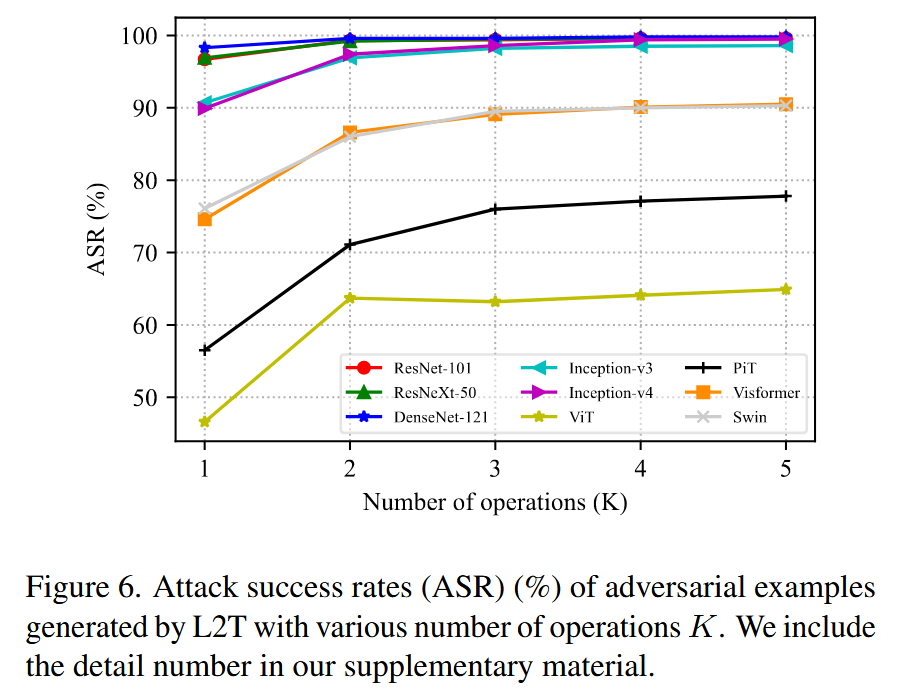
图6. 使用不同操作数量 K K K 时,L2T生成的对抗样本的攻击成功率(ASR,%)。详细数据见补充材料。 - 变换数
L
L
L 的影响:随着
L
L
L 从1增加到20,对抗迁移性稳步提升,平均攻击成功率从75.7%提升到91.1% ,超过20后提升不明显,为平衡计算效率和对抗迁移性,建议
L
L
L 设为20。
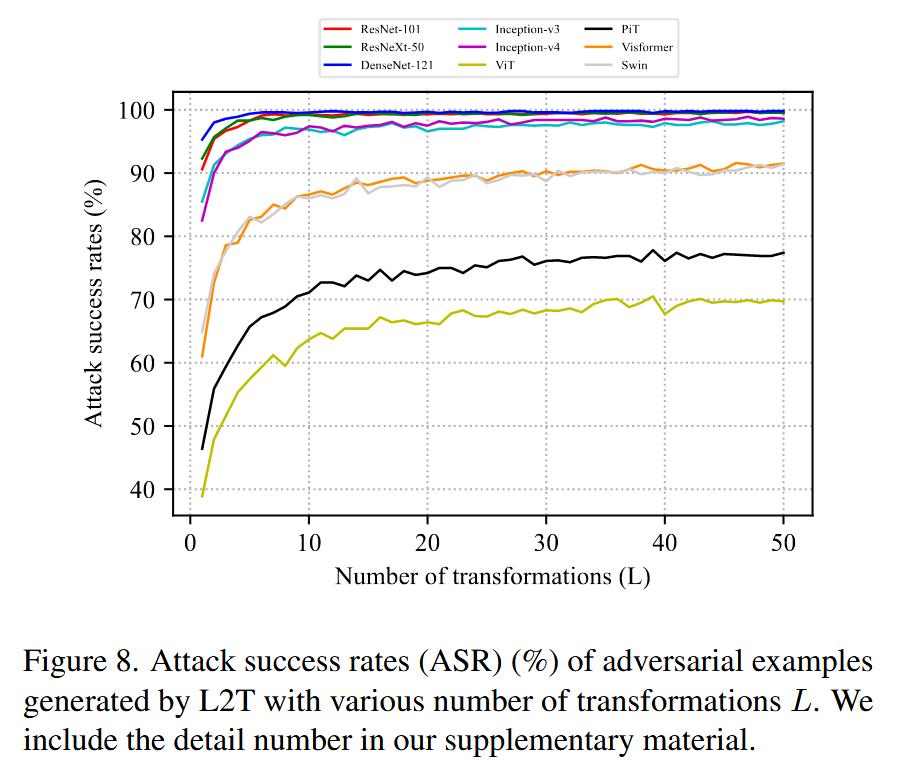
图8. 使用不同变换数量 L L L 时,L2T生成的对抗样本的攻击成功率(ASR,%)。详细数据见我们的补充材料。 - 迭代次数
T
T
T 的影响:所有攻击方法在前10次迭代中攻击成功率稳步上升,L2T提升速度最快,10次迭代时达到89.47% 。10次迭代后,多数方法难以提升,而L2T仍能稳定上升,从89.47%提升到94.77%。
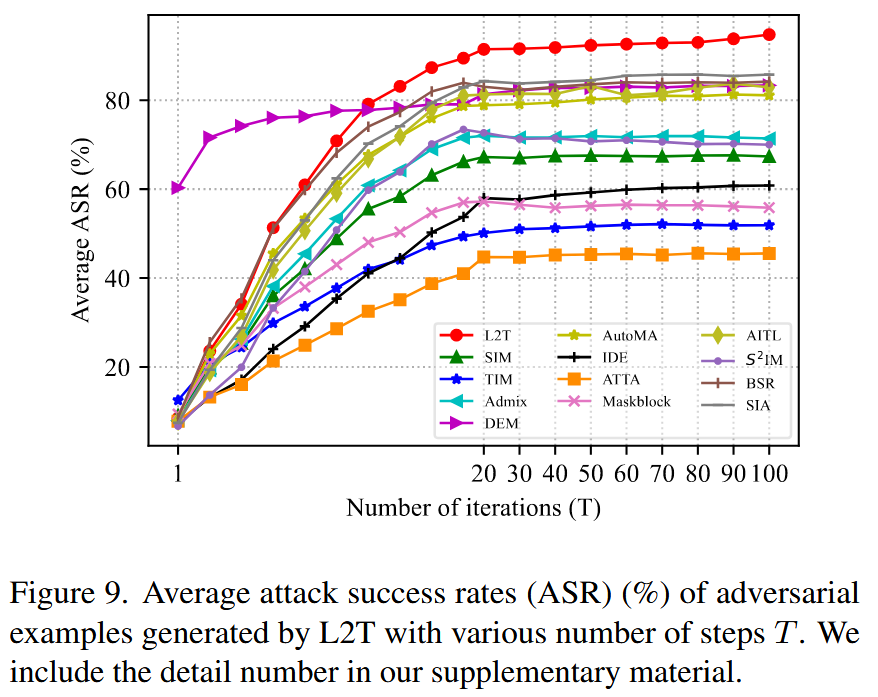
图9. 使用不同迭代步数 T T T 时,L2T生成的对抗样本的平均攻击成功率(ASR,%)。详细数据见我们的补充材料。 - 与随机采样对比:随机采样的攻击成功率与L2T梯度引导采样差距明显,最小差距为31.12%,表明随机采样无法有效选择最佳变换轨迹。
表1. L2T与Rand(每次迭代中随机选择变换)生成的对抗样本的攻击成功率(%)。

- 操作候选分析:对操作候选进行消融研究,减去任何一个操作都会导致L2T性能下降,如减去缩放操作性能下降23.5%,减去混合和变换操作分别下降3.1%.
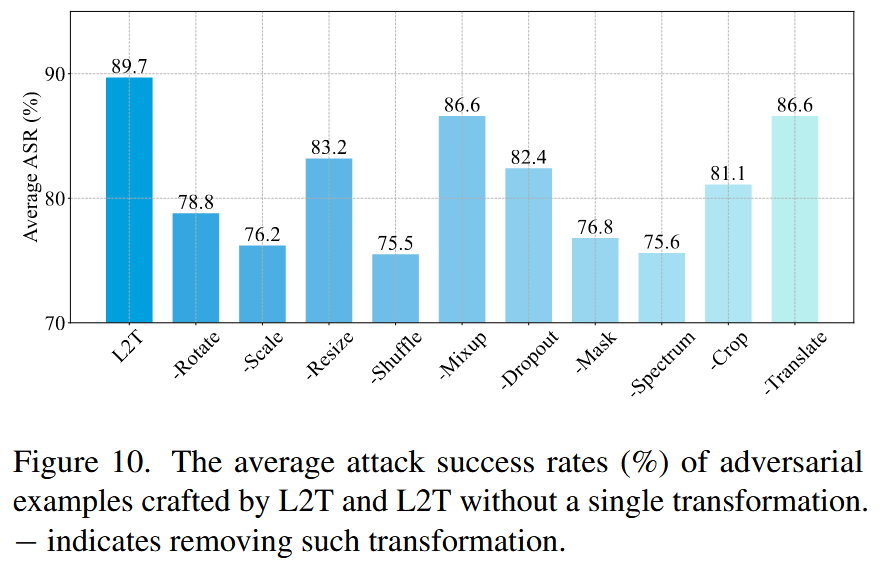
图10. 使用L2T方法以及去除单一变换的L2T方法所生成对抗样本的平均攻击成功率(%)。“−”表示去除相应的变换。
- 操作数
K
K
K 的影响:研究发现,
K
K
K 从1增加到2时,平均攻击成功率显著提升8.09% ,但
K
≥
3
K\geq3
K≥3 时提升幅度变小,因此建议
K
K
K 适中设置为2。
结论-Conclusion
该部分对文章的研究内容进行了总结,强调了L2T方法的核心要点、实验验证效果以及研究的创新性,具体如下:
- 方法核心:文章聚焦于输入变换的动态特性展开研究,在此基础上提出L2T方法。该方法的关键在于在每次迭代中对输入变换进行优化,通过更新采样概率,为输入变换优化提供了一种近似解决方案。
- 实验验证:通过一系列实验,全面探究了L2T方法的有效性。实验结果表明,L2T在不同类型的目标模型上,均展现出了稳定且优异的性能,切实证明了该方法在提升对抗样本迁移性方面的有效性。
- 研究创新:本文为理解对抗样本的迁移性提供了全新的视角。L2T方法打破了传统输入变换方法的局限,利用动态特性优化变换过程,这种创新的思路为后续相关研究开拓了新的方向,有助于推动对抗攻击与防御领域的进一步发展。


















 864
864

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











