






文章目录
前言

你能想象到上面的动图(视频)是由几张图片在几分钟内生成的吗?
设计一张富有创意的家装设计图需要多久?过去,家装设计师需要先根据客户的需求寻找灵感,可能要去看看业内资讯,可能要去了解大师的作品……这一过程往往需要半天或者更多时间。但如今,AIGC时代来临,通过主流的AI绘画软件,例如SD(Stable Diffusion)和MJ(Midjourney)仅1小时即可生成上百张各式风格的图片。

如何将这些数据沉淀为数字资产,并以不同形式进行展示呢?
通过三维重建技术,我们可以利用素材与生成式AI转化为生产力,并一站式生成视频、和一些渲染后的视觉场景。
本次Intel 黑客松,我计划使用Intel AI 工具包,分析、实现、优化一个Gaussian Splatting的算法方案。
一、方案概述
通过参考学习3D Gaussian Splatting的论文,使用intel工具包实现一个简单的3D Gaussian Splatting。
生成式模型微调
目前比较主流的方案是ChatGLM-6B+LangChain训练及模型微调。这里采用生成式模型微调的作用是提供一个细分场景AI助手,帮助用户去定义家装行业的数字资产。
三维重建
三维重建是指用相机等传感器拍摄真实世界的物体、场景,并通过计算机视觉技术进行处理,从而得到物体的三维模型。
涉及的主要技术有:多视图立体几何、深度图估计、点云处理、网格重建和优化、纹理贴图、马尔科夫随机场、图割等。

本文主要介绍通过基于3D-R2N2的点云资产,和基于NeRF 的静态场景资产,然后参考Splatting进行优化
二、技术方案
1.3D-R2N2 介绍
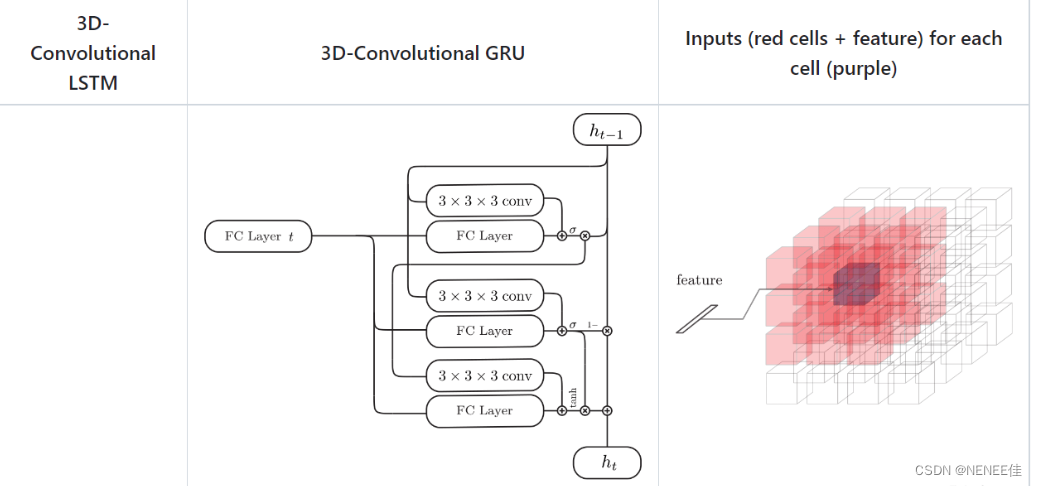
3D-R2N2模型是一种新颖的循环神经网络体系结构,用于实现鲁棒的三维重建。该模型建立在标准LSTM和GR|U的基础上,并由三个部分组成:二维卷积神经网络(2D-CNN)、新型结构3D卷积LSTM(3D-LSTM)和三维反卷积神经网络(3D-DCNN)。3D-R2N2模型的目标是同时执行单视图和多视图3D重建,其主要思想是利用LSTM的能力来保留先前的观测值,并随着更多观测值的增加而逐渐细化输出重建。
2.神经辐射场(NeRF)介绍
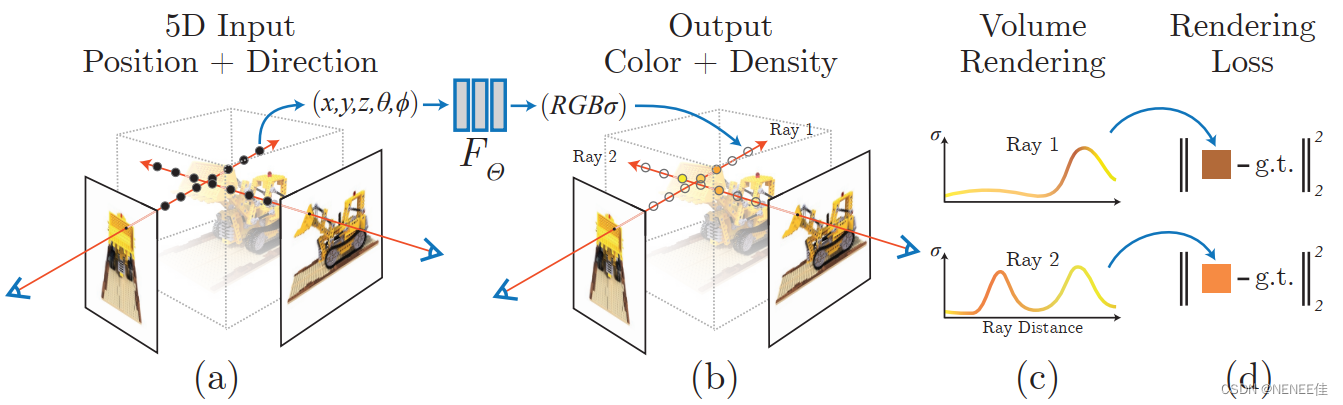
NeRF的研究目的是合成同一场景不同视角下的图像。方法很简单,根据给定一个场景的若干张图片,重构出这个场景的3D表示,然后推理的时候输入不同视角就可以合成(渲染)这个视角下的图像了。
神经辐射场场景表示和可微分渲染过程:
1 通过沿着相机射线采样5D坐标(位置和观看方向)来合成图像;
2 将这些位置输入MLP以产生颜色和体积密度;
3 并使用体积渲染技术将这些值合成图像;
4 该渲染函数是可微分的,因此可以通过最小化合成图像和真实观测图像之间的残差来优化场景表示。
3.Intel AI Analytics Toolkit
Intel ® Extension for PyTorch是一个基于PyTorch的扩展库,用于在Intel处理器上加速机器学习任务。通过使用Intel PyTorch,可以充分利用Intel处理器的并行处理能力和优化指令,从而提高机器学习模型的训练和推理速度。此外,Intel PyTorch还提供了一些高级功能,如混合精度训练和自动微分,以帮助用户更快速地训练大型模型并获得更好的性能。
4.3D Gaussian Splatting
3D Gaussian Splatting是一种用一组2d图像创建3d场景的方法,你只需要一个场景的视频或者一组照片就可以获得这个场景的高质量3d表示,使你可以从任何角度渲染它。它们是一类辐射场方法(如NeRF),但同时训练速度更快(同等质量)、渲染速度更快,并达到更好或相似的质量。3D Gaussian Splatting可以实现无界且完整的场景1080p分辨率下进行高质量实时(≥ 100 fps)视图合成。
三、3D-R2N2生成点云资产
1.模型定义
定义3D-R2N2模型。模型的定义比较复杂,因此在这里我们实现一个简化的版本:
import torch
import torch.nn as nn
class Simple3DR2N2(nn.Module):
def __init__(self):
super(Simple3DR2N2, self).__init__()
self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3)
self.pool1 = nn.MaxPool2d(kernel_size=2, stride=2)
self.conv2 = nn.Conv2d(64, 128, kernel_size=5, stride=2, padding=2)
self.pool2 = nn.MaxPool2d(kernel_size=2, stride=2)
self.fc1 = nn.Linear(128 * 7 * 7, 1024)
self.fc2 = nn.Linear(1024, 4096)
self.fc3 = nn.Linear(4096, 32768) # 输出一个16x16x16的体素网格
def forward(self, x):
x = self.pool1(F.relu(self.conv1(x)))
x = self.pool2(F.relu(self.conv2(x)))
x = x.view(-1, 128 * 7 * 7)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = torch.sigmoid(self.fc3(x))
return x.view(-1, 16, 16, 16)
2.环境搭建
实际使用我们还是下载一个预训练的3D-R2N2,
首先下载代码
git clone https://github.com/chrischoy/3D-R2N2.git
安装anaconda,百度上安装anaconda教程很多就不展开讲解了。
cd 3D-R2N2
conda create -n py3-theano python=3.6
source activate py3-theano
conda install pygpu
pip install -r requirements.txt
运行官方代码
python demo.py prediction.obj

修改demo,思路过程:
1、附加参数初始化,
2、train_net()修改
3、train_net()中的main()重写
4、train_net()中的train_net(),读取网络类型参数值为cfg.CONST.NETWORK_CLASS,通过函数make_data_processes读取测试数据,调用solver中的train函数
使用intel 拓展pytorch,记得切到自己的conda环境。
pip install torch torchvision
pip install intel_pytorch_extension
2.图像转换
下面是部分代码
import intel_pytorch_extension as ipex
# 启用 Intel® Extension for PyTorch
torch.backends.quantized.engine = "qnnpack"
# 加载预训练的3D-R2N2模型
model = Simple3DR2N2()
model.load_state_dict(torch.load("3dr2n2model.pth"))
model = model.to(ipex.DEVICE)
# 定义图像预处理
transform = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
])
# 2D图像转3D模型
def image_to_3d(image_path):
img = Image.open(image_path)
img_t = transform(img)
batch_t = torch.unsqueeze(img_t, 0).to(ipex.DEVICE)
model.eval()
with torch.no_grad():
voxel_grid = model(batch_t)
return voxel_grid.cpu().numpy()
3D-R2N2模型通过结合CNN和RNN,能够实现对多个点云数据进行三维重建,具有较好的效果和泛化性能。
这个过程中:
首先,通过一个三维卷积神经网络(CNN)对输入的多个三维点云数据进行特征提取,得到每个点云数据的特征向量。
然后,将这些特征向量作为输入,递归地传递到一个递归神经网络(RNN)中。
在RNN中,每个点云数据的特点会被逐步地聚合到一起,形成越来越完整的三维模型。
最后,通过一个反卷积层(transpose convolutional layer),将RNN输出的特征图转换为三维网格模型。
四、基于 NeRF 的静态场景资产
nerf-pytorch
这里我们之间使用开源的nerf-pytorch进行开发
(1)搭建环境
创建虚拟环境:
conda create -n nerfpy37 python=3.7
conda activate nerfpy37
安装:
git clone https://github.com/yenchenlin/nerf-pytorch.git
cd nerf-pytorch
pip install -r requirements.txt
(2) 运行demo
下载数据集 lego和 fern :
bash download_example_data.sh
训练一个低分辨率的 lego NeRF:
python run_nerf.py --config configs/lego.txt

训练lego
可以在run_nerf.py里面修改训练次数,默认训练次数为200k次,为了更快出结果,可以减小这个值。
N_iters = 100000 + 1
# N_iters = 200000 + 1
训练:python run_nerf.py --config configs/lego.txt
configs/lego.txt如下:
expname = blender_paper_lego
basedir = ./logs
datadir = ./data/nerf_synthetic/lego
dataset_type = blender
no_batching = True
use_viewdirs = True
white_bkgd = True
lrate_decay = 500
N_samples = 64
N_importance = 128
N_rand = 1024
precrop_iters = 500
precrop_frac = 0.5
half_res = True
Intel PyTorch 优化
- 使用量化模型:nerf-pytorch使用了quantize函数将模型量化到8位整数精度。它减少了模型的大小并提高了推理速度。我们使用Intel Extension for PyTorch的量化库来进一步优化这个过程。
# 加载已经量化过的模型权重
model = torch.load('quantized_model.pth')
# 使用Intel Extension的量化函数转换模型
model = iquantize(model, num_bits=8, scale_factor=None)
# 将模型移动到GPU
model.to(device)
- 加速矩阵运算:在计算密集型任务中,在NeRF渲染过程中,优化代码可以显著提高性能。我们可以使用Intel更快的向量化操作
# 将数据类型转换为BFloat16
x = x.to(BFloat16)
y = y.to(BFloat16)
# 使用Intel Extension的矩阵乘法函数
z = matmul(x, y)
# 使用Intel Extension的元素级加法函数
z = add(z, z)
- 使用并行化:除此之外我们可以使用并行化来同时处理多个任务或数据点。
# 启用并行计算模式
parallel_mode()
# 使用Intel Extension的并行线性层函数
linear = ParallelLinear(in_features, out_features)
x = torch.randn(in_features)
y = linear(x)
# 使用Intel Extension的并行卷积层函数
conv = ParallelConv2d(in_channels, out_channels, kernel_size)
x = torch.randn(batch_size, in_channels, height, width)
y = conv(x)
五、基于Instant-ngp的开销提升替代方案
Instant-ngp主要用于解决NeRF在对全连接神经网络进行参数化时的效率问题。该方法提出一种编码方式,使得可以使用一个较小规模的网络来实现NeRF同时不会产生精度的损失。该网络由特征向量的多分辨率哈希表实现增强,基于随机梯度下降执行优化。多分辨率结构有助于GPU并行,能够通过消除哈希冲突减少计算。该方法最大的亮点是将NeRF以小时计的时间开销提升到秒级。
通过使用Instant-ngp替代nerf-pytorch,可以实现工业化场景的开销速度。
六、Gaussian Splatting
tile-based 渲染的投影高斯算法
基于点的方法(即点云)有效地渲染了断开的和非结构化的几何样本。点采样渲染栅格化具有固定大小的非结构化点集,它可以利用本地支持的点类型的图形api或并行软件栅格化。虽然对于底层数据,点样本呈现存在漏洞,导致混叠,并且是严格不连续的。在高质量的基于点的渲染方面的开创性工作通过“spliting”范围大于像素的点来解决这些问题,例如,圆或椭圆盘、椭球体或表面。
基于点的𝛼混合和nerf风格的体积渲染本质上共享相同的图像形成模型。具体来说,颜色𝐶是通过沿着光线的体积渲染来给出的:
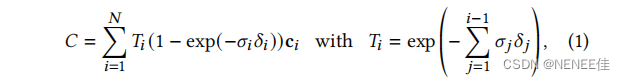
其中密度𝜎、透射率𝑇和颜色c的样品沿射线间隔𝛿𝑖。这可以被重写为
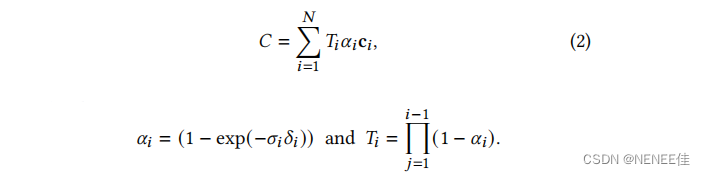
一种典型的基于神经点的方法,通过混合重叠于像素上的N个有序点来计算一个像素的颜色𝐶(其中c𝑖 是每个点的颜色,𝛼𝑖是通过计算协方差Σ的二维高斯分布,乘以学习的每点不透明度给出的):
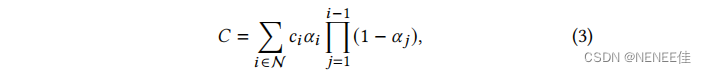
Gaussian Splatting 使用三维高斯算法来进行更灵活的场景表示,避免了MVS几何的需要,并实现了实时渲染,归功于 tile-based 渲染的投影高斯算法。
引入三维高斯分布
那么基于高斯投影算法和Intel 分析工具自带的一些底层优化的数学库,我们可以动手进行下面的优化。
引入三维高斯分布作为场景表示。与 nerf 方法相同的输入开始,即使用运动结构(SfM)校准的相机,并使用SfM过程中免费产生的稀疏点云初始化三维高斯数集。与大多数需要多视图立体声(MVS)数据的基于点的解决方案相比,仅以SfM点作为输入就获得了高质量的结果
Gaussian Splatting的输入是一组静态场景的图像,以及由SfM校准的相应摄像机,它产生一个稀疏点云作为衍生物。从稀疏点上,我们创建一组三维高斯分布,由位置(均值)、协方差矩阵和不透明度𝛼定义,允许一个非常灵活的优化机制。整体概述如图所示
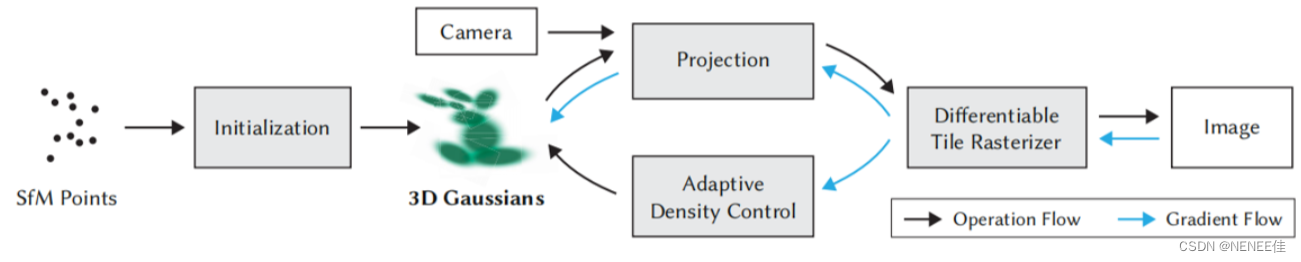
使用Intel®Neural Compressor加速训练自适应密度控制的优化
在上述实现的基础上优化基于连续的渲染迭代:将生成的图像与训练视图进行比较。
由于三维到二维投影的歧义,几何图形可能会被错误地放置。因此,优化需要能够创建几何,也破坏或移动几何(如果定位错误)。
使用随机梯度下降进行优化,利用Intel gpu加速框架。快速栅格对我们的优化效率至关重要,因为它是优化的主要计算瓶颈。
pip install neural-compressor -i https://pypi.tuna.tsinghua.edu.cn/simple/
使用sigmoid 函数 将 𝛼 约束在[0−1)范围内,得到平滑的梯度。由于类似的原因,对协方差尺度的使用指数激活函数。
协方差矩阵初始化为一个各向同性高斯矩阵,其轴等于到最近的三个点的距离的平均值。我们使用一种类似于 Plenoxels 的标准指数衰减调度技术,但只针对位置。损失函数是L1和D-SSIM项相结合(λ=0.2):
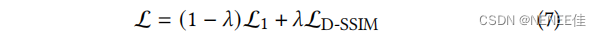
高斯的自适应控制
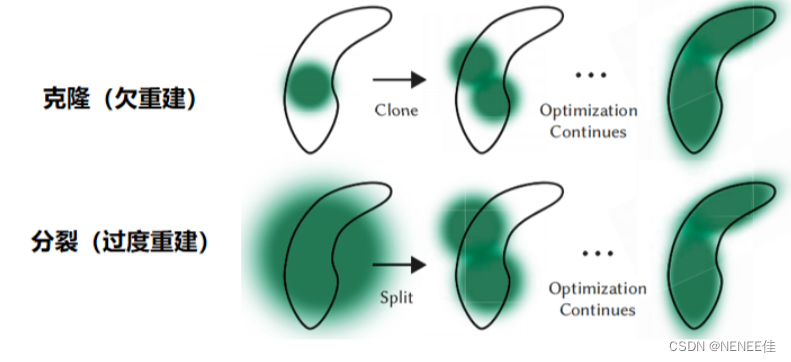
从SfM估计的初始稀疏点开始,然后自适应控制高斯分布的数量及其密度(单位体积),允许我们从初始稀疏的高斯集密集,更好地代表场景。warm-up之后,每100次迭代一次,删除透明的高斯分布(α小于阈值 εα) 。
总结

我们通过使用Intel ® Extension for PyTorch 实现并优化了一个 3D-R2N2、并且 将nerf-pytorch 加入了Intel PyTorch优化。在此基础上,我们参考3D Gaussian Splatting实现了Splatting的简化版。
开销上,优化版本nerf-pytorch,在原有nerf运行速度提高 1.5 倍,在原有nerf-pytorch速度提高 1.15倍。Splatting在图像合成速度上具有超高优势,
单图 Evaluate test results
SSIM : 0.8516315
PSNR : 24.3630562
LPIPS: 0.1731234
满足对于点云、体素、静态场景等资产的生成。

















 2729
2729











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











