







 本文提出了一种结合3D高斯表达和基于tile的溅射技术的方法,实现实时渲染高分辨率图像。通过SfM校准和稀疏点云初始化,即使随机初始化也能生成高质量图像。优化3D高斯属性的同时,利用自适应密度控制进行动态调整,结合GPU排序和溅射策略,实现了快速且精确的渲染。
本文提出了一种结合3D高斯表达和基于tile的溅射技术的方法,实现实时渲染高分辨率图像。通过SfM校准和稀疏点云初始化,即使随机初始化也能生成高质量图像。优化3D高斯属性的同时,利用自适应密度控制进行动态调整,结合GPU排序和溅射策略,实现了快速且精确的渲染。
原文链接:https://arxiv.org/abs/2308.04079
初学者和不熟悉CUDA程序的人也能看懂的渲染部分代码解读:3D Gaussian Splatting部分原理介绍和CUDA代码解读
1. 引言
网孔和点是最常见的3D场景表达,因其是显式的且适合基于GPU/CUDA的快速栅格化。神经辐射场(NeRF)则建立连续的场景表达便于优化,但渲染时的随机采样耗时且引入噪声。本文的方法结合了上述两种方法的优点:使用3D高斯表达和基于tile的溅射,能实时地渲染高质量高分辨率图像。
首先建立3D高斯表达场景。从使用运动恢复结构(SfM)方法校准的相机出发,使用SfM过程中产生的稀疏点云初始化3D高斯集合。即使使用随机初始化,本文的方法也能达到高质量图像合成。3D高斯是可微体积表达,且可以通过投影到2D、并使用标准的 α \alpha α混合,使用NeRF一样的图像形成模型来实现高效栅格化。然后,优化的对象是3D高斯的属性:3D位置、不透明度 α \alpha α、各向异性协方差和球面谐波(SH)系数。该优化与自适应密度控制步骤(添加并偶尔移除3D高斯)交错进行。最后,使用快速GPU排序算法和基于tile的栅格化进行实时渲染。归因于排序和 α \alpha α混合,使用3D高斯表达能进行保留可见性顺序的各向异性溅射,且可通过跟踪尽可能多的排序后的溅射轨迹来实现快速而精确的反向传播。
2. 相关工作
基于点的
α
\alpha
α混合和NeRF体积渲染有相同的图像形成模型。NeRF的色彩
C
C
C由沿射线的体积渲染得到:
C
=
∑
i
=
1
N
T
i
α
i
c
i
,
α
i
=
1
−
exp
(
−
σ
i
δ
i
)
,
,
T
i
=
exp
(
−
∑
j
=
1
i
−
1
σ
j
δ
j
)
=
∏
j
=
1
j
−
1
(
1
−
α
j
)
C=\sum_{i=1}^NT_i\alpha_ic_i,\alpha_i=1-\exp(-\sigma_i\delta_i),,T_i=\exp(-\sum_{j=1}^{i-1}\sigma_j\delta_j)=\prod_{j=1}^{j-1}(1-\alpha_j)
C=i=1∑NTiαici,αi=1−exp(−σiδi),,Ti=exp(−j=1∑i−1σjδj)=j=1∏j−1(1−αj)
而典型的基于点的方法通过混合与像素重叠的
N
N
N个有序点来计算
C
C
C:
C
=
∑
i
=
1
N
c
i
α
i
∏
j
=
1
j
−
1
(
1
−
α
j
)
C=\sum_{i=1}^Nc_i\alpha_i\prod_{j=1}^{j-1}(1-\alpha_j)
C=i=1∑Nciαij=1∏j−1(1−αj)其中
α
i
\alpha_i
αi为协方差为
Σ
\Sigma
Σ的2D高斯与学习到的各点不透明度之积。
3. 总览
本文方法如下图所示。本文方法的输入为静态场景的图像,和通过SfM校准的相机(校准同时产生稀疏点云)。从这些点生成3D高斯集合,每个高斯由位置(均值)、协方差矩阵和不透明度
α
\alpha
α定义,以实现3D场景的紧凑表达。辐射场的方向性外观分量(色彩)通过球面谐波表达。通过交替进行3D高斯参数优化和自适应高斯密度控制,建立神经场表达。本文方法高效的关键是基于tile的栅格化,允许各向异性溅射的
α
\alpha
α混合,并通过快速排序保留可视顺序。通过跟踪积累的
α
\alpha
α值,可以在不限制接收梯度的高斯数量的情况下快速反向传播。

4. 可微3D高斯溅射
需要继承可微体积表达的优势,且同时满足非结构化和显式表达的条件以进行快速渲染。本文选择3D高斯,其可微且易于投影为2D溅射,从而进行快速的 α \alpha α混合。
设世界坐标系下的3D高斯中心点(均值)为
μ
\mu
μ,完全3D协方差矩阵为
Σ
\Sigma
Σ:
G
(
x
)
=
e
−
1
2
x
T
Σ
−
1
x
G(x)=e^{-\frac{1}{2}x^T\Sigma^{-1}x}
G(x)=e−21xTΣ−1x在混合时该高斯会乘以
α
\alpha
α。
渲染时,需要将3D高斯投影到2D。给定视角变换
W
W
W,相机坐标系下的协方差矩阵
Σ
′
\Sigma'
Σ′为
Σ
′
=
J
W
Σ
W
T
J
T
\Sigma'=JW\Sigma W^TJ^T
Σ′=JWΣWTJT其中
J
J
J为投影变换仿射近似的雅可比矩阵。
直接优化3D高斯协方差不可行,因为协方差矩阵仅当在半正定情况下有意义,而对所有元素进行梯度下降的优化不能保证这个条件。因此,本文使用另一方法,将协方差矩阵分解为缩放矩阵
S
S
S和旋转矩阵
R
R
R:
Σ
=
R
S
S
T
R
T
\Sigma=RSS^TR^T
Σ=RSSTRT将
S
S
S表达为3D向量
s
s
s,
R
R
R表达为四元数
q
q
q,这样只需通过归一化保证
q
q
q满足单位四元数的条件。
此外,为避免自动计算梯度带来额外开销,本文还推导了所有参数显式的梯度(见附录A)。
5. 3D高斯的优化和自适应密度控制
除了位置 p , α p,\alpha p,α和协方差 Σ \Sigma Σ,本文还优化表达高斯色彩 c c c的球面谐波(SH)系数,以捕捉场景视角相关的外观。参数优化和高斯的密度控制交替进行,以更好地表达场景。
5.1 优化
本文使用随机梯度下降,利用标准GPU加速框架,并为某些操作添加自定义CUDA核。对 α \alpha α使用sigmoid函数使其限制在 [ 0 , 1 ) [0,1) [0,1)内,对协方差的缩放因数使用指数激活函数以保证光滑梯度。
将协方差初始化为各向同性高斯,其轴线长度与最近3点的距离均值相同。对高斯的位置使用标准的指数衰减调度技术。损失函数为
L
1
L_1
L1损失和D-SSIM项:
L
=
(
1
−
λ
)
L
1
+
λ
L
D-SSIM
\mathcal{L}=(1-\lambda)\mathcal{L}_1+\lambda\mathcal{L}_\text{D-SSIM}
L=(1−λ)L1+λLD-SSIM
5.2 高斯的自适应控制
从初始SfM点集开始,逐渐密集化高斯以更好地表达场景。本文在优化热启动后,每隔一定迭代次数就密集化高斯,同时移除 α \alpha α值小于阈值 ϵ α \epsilon_\alpha ϵα的透明高斯。
高斯的自适应控制需要填充空白区域。该操作关注缺失几何特征的区域(欠重建)和高斯覆盖较大的区域(过重建),因为二者有较大的位置梯度。本文使用(大于阈值 τ pos \tau_\text{pos} τpos的)梯度的平均值来密集化高斯。
如下图所示,对于欠重建区域的小高斯,需要创建新几何。本文通过复制已有高斯并沿位置梯度方向移动实现。对于大高斯,本文将其分裂为两个更小的高斯,缩放因数变为原来的 1 / ϕ 1/\phi 1/ϕ。通过使用原始3D高斯PDF进行采样,得到新高斯的位置。
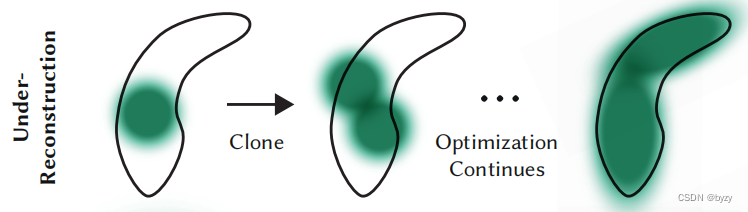
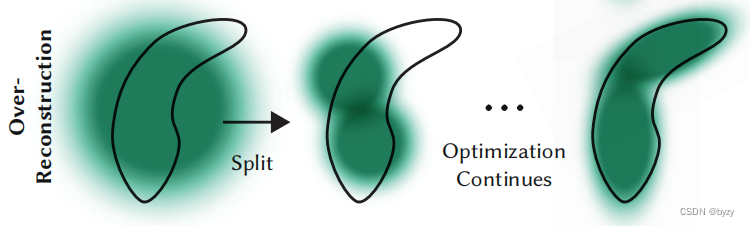
与其余体积表达类似,本文方法的优化会受到相机附近漂浮物的影响而卡住。本文每隔 N N N次迭代就将 α \alpha α设置为接近0的数,需要的高斯 α \alpha α会通过优化增大,不需要的高斯则会因为 α < ϵ α \alpha<\epsilon_\alpha α<ϵα而移除。此外,还会定期去除很大的高斯。
6. 高斯的快速可微栅格化
本文设计了基于tile的高斯溅射栅格化方法,预先排序高斯,且可以对任意数量的混合高斯反向传播,其每个像素的计算开销为常数。该栅格化方法完全可微且可栅格化各向异性溅射。
首先将区域划分为若干tile,然后挑选出视锥内在各tile内的3D高斯(与视锥相交的置信区间为99%以上)。然后拒绝极端位置(如靠近近平面)的高斯,因其2D的投影协方差不稳定。根据相交的tile数量,为每个高斯分配深度与tile ID组合的键。然后使用快速GPU Radix排序,基于上述键对高斯进行排序,随后基于此顺序进行混合。
为每个tile分配一个线程块,各线程块共同将高斯读取到共享内存中,然后从前往后遍历高斯,得到像素的颜色和 α \alpha α值。当像素的 α \alpha α值饱和,相应线程停止。tile中的线程会定期被查询,直到所有像素的 α \alpha α饱和(达到1)。
为了实现反向传播,本文重新利用各tile排序的高斯列表,从后往前遍历。遍历从影响像素的最后一个点开始,将前向传播中积累的不透明度值除以 α \alpha α以得到梯度计算的系数。
7. 实施、结果与评估
7.1 实施
实施细节:首先在低分辨率下预热优化,然后逐步上采样到原始分辨率下。球面谐波系数的优化从零阶分量开始(因为该值的预测最为困难),然后逐步增加波段。
7.2 结果与评估
真实世界场景:本文的方法能达到甚至超过SotA的性能,且所需要的训练时间大大减少。此外,可视化表明,本文的方法能保留远处清晰的细节。
合成的有界场景:在精确的相机参数下,本文可以通过随机初始化覆盖整个空间的高斯达到SotA性能(训练过程中,模型会快速通过剪枝保留少量的有用高斯)。
7.3 消融
从SfM初始化:与从随机点云初始化相比,从SfM初始化能保留背景细节。
密集化:实验表明,分割大高斯对背景重建有帮助,复制小高斯能使模型更快更好地收敛(特别是当薄结构存在时)。
不限制深度复杂度的带梯度溅射:若限制接收梯度的点数,会导致不稳定优化,因为梯度计算有严重的近似。
各向异性协方差:若改为优化单一的高斯半径值(此时为各向同性高斯),会严重降低图像质量。因为各向异性高斯能更好地对齐表面。
球面谐波:使用球面谐波能提高性能,因为其补充了视图依赖效果。
7.4 局限性
本文的方法有时候仍然会产生伪影。
虽然与基于点的方法相比,本文的方法较为紧凑,但与基于NeRF的方法相比,存储占用仍然有很大的差距。
8. 讨论与结论
本文的工作表明,场景的连续表达对高质量而快速的神经场训练来说不是严格必要的。
附录
B. 优化与密集化算法

C. 栅格化细节

数值稳定性:由于积累不透明度除以
α
\alpha
α容易因为除以0造成数值不稳定,本文在前向和反向传播时跳过
α
<
ϵ
\alpha<\epsilon
α<ϵ的混合更新,并在前向传播混合前计算高斯的累积不透明度,该值达到接近1时停止混合。


















 1187
1187

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











