






参考链接:
GitHub - ultralytics/yolov5: YOLOv5 🚀 in PyTorch > ONNX > CoreML > TFLite
TFLite,ONNX,CoreML,TensorRT Export -Ultralytics YOLO Docs
使用Neural Magic 的 DeepSparse 部署YOLOv5 -Ultralytics YOLO 文档
一、转化格式加速推理
1.YOLOv5 正式支持 12 种格式的推理:
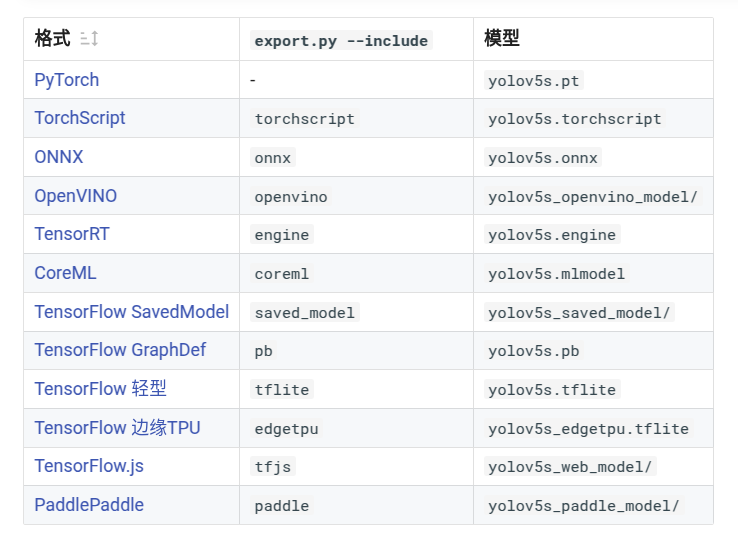
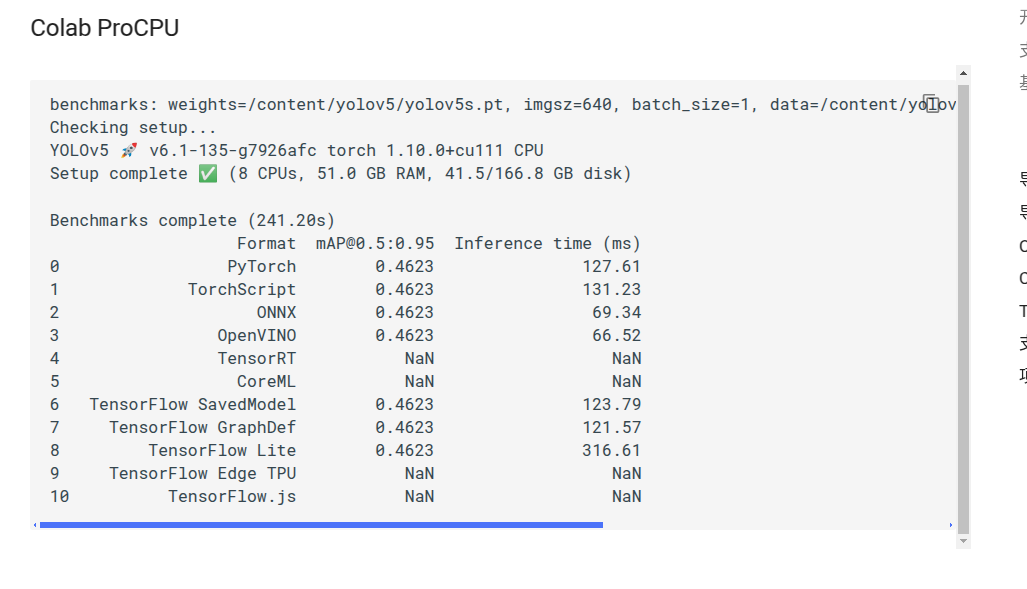
2.导出训练有素的YOLOv5 模型
将自己训练好的模型文件如yolov5s.pt导出为torchscript onnx。经过我的测试onnx和openvino是最快的。
python export.py --weights yolov5s.pt --include torchscript onnx3.导出后使用示例
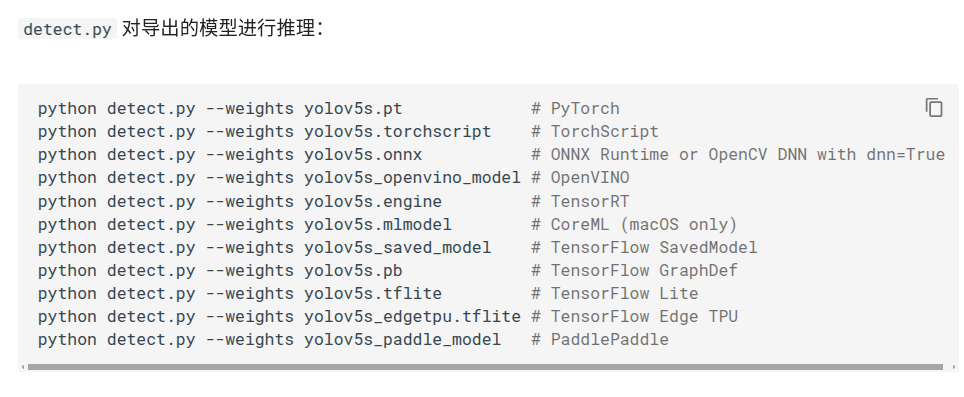
二、使用DeepSparse + onnx加速推理
1.安装 DeepSparse
pip install "deepsparse[server,yolo,onnxruntime]"2.Python 应用程序接口
将model_path替换为自己的onnx模型所在的位置。
import cv2
import time
from deepsparse import Pipeline
# 视频文件路径,需替换为你的实际视频路径
video_path = "/home/yzh/yolo_v5/yolov5/2.mp4"
cap = cv2.VideoCapture(video_path)
# create Pipeline
# 使用自定义 ONNX 模型路径
# model_path = "/home/yzh/yolo_v5/yolov5/runs/train/exp6/weights/best_1.onnx"
model_path = "/home/yzh/yolo_v5/yolov5/yolov5_runs/train/exp6/DeepSparse_Deployment/model.onnx"
yolo_pipeline = Pipeline.create(
task="yolo",
model_path=model_path,
# image_size=(320, 320), # 输入图像大小
# batch_size=32, # 批处理大小
)
prev_time = 0
# 初始化总推理时间和总推理次数
total_inference_time = 0
total_inference_count = 0
while cap.isOpened():
ret, frame = cap.read()
if not ret:
break
# 将 BGR 格式的 OpenCV 图像转换为 RGB 格式
rgb_frame = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
# 执行推理
start_time = time.time()
pipeline_outputs = yolo_pipeline(images=[rgb_frame], iou_thres=0.6, conf_thres=0.2)
end_time = time.time()
inference_time = (end_time - start_time) * 1000
print(f"推理时间: {inference_time:.2f} ms")
# 更新总推理时间和总推理次数
total_inference_time += inference_time
total_inference_count += 1
# 计算实时平均推理速度
average_inference_speed = total_inference_time / total_inference_count
print(f"实时平均推理速度: {average_inference_speed:.2f} ms")
# 获取检测结果
boxes = pipeline_outputs.boxes[0] # 假设只有一个图像输入
scores = pipeline_outputs.scores[0]
labels = pipeline_outputs.labels[0]
# 绘制边界框和标签
for box, score, label in zip(boxes, scores, labels):
x1, y1, x2, y2 = map(int, box)
confidence = float(score)
class_id = int(label)
# 绘制边界框
cv2.rectangle(frame, (x1, y1), (x2, y2), (0, 255, 0), 2)
# 绘制标签和置信度
label_text = f"{class_id}: {confidence:.2f}"
cv2.putText(frame, label_text, (x1, y1 - 10), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0, 255, 0), 2)
# 计算 FPS
fps = 1 / (end_time - start_time)
prev_time = end_time
# 在帧上绘制 FPS
cv2.putText(frame, f"FPS: {fps:.2f}", (10, 30), cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 255, 0), 2)
# 显示帧
cv2.imshow('Video Inference', frame)
# 按 'q' 键退出循环
if cv2.waitKey(1) & 0xFF == ord('q'):
break
# 释放资源
cap.release()
cv2.destroyAllWindows()
之后直接运行这个脚本那文件,就可以使用DeepSparse加速了。加速效果明显,大概1.5倍。
三、DeepSparse 稀疏性能
文档上介绍效率很高,但是我实际使用感觉除了模型变小了一点,其他没有什么太大区别。
1.安装python库文件
pip install "sparseml[yolov5]"2.开始训练
(1)语法

(2)一个例子
recipe_type 这个是稀疏化的配置直接从官网下,weights这个稀疏化权重也是直接从官网下,你只需要把--data改成自己的数据集的配置文件就可以了。如果太卡,还要改--batchsize。
sparseml.yolov5.train \
--weights zoo:cv/detection/yolov5-s/pytorch/ultralytics/coco/pruned75_quant-none?recipe_type=transfer_learn \
--recipe zoo:cv/detection/yolov5-s/pytorch/ultralytics/coco/pruned75_quant-none?recipe_type=transfer_learn \
--data VOC.yaml \
--patience 0 \
--cfg yolov5s.yaml \
--hyp hyps/hyp.finetune.yaml3.导出模型
sparseml.yolov5.export_onnx \
--weights yolov5_runs/train/exp/weights/last.pt \
--dynamic模型导出后,将onnx的路径加到上述二的脚本文件里面,直接运行。但是确实效率没提升多少,onnx的规模确实是下降了。

















 767
767

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









