







传统全局自注意力在处理高分辨率图像时,计算量随图像尺寸呈平方级增长,导致显存占用和推理延迟显著增加。例如,一张 1024×1024 的图像需要计算约 10^6 个 token 的交互,这在实际应用中难以承受。同时,卷积神经网络(CNN)虽通过局部感受野降低计算量,但其参数依赖型感受野扩展(如 3×3 卷积堆叠)和内容无关的交互(固定权重)限制了对复杂视觉模式的捕捉能力。
HaloNet 提出分块局部自注意力,将图像划分为非重叠块,每个块仅与周围扩展的 Halo 区域进行交互。这种设计既保留了自注意力的内容敏感特性,又通过分块策略大幅降低计算量,同时通过 Halo 区域扩展感受野,实现全局信息的有效传递。
上面是原模型,下面是改进模型
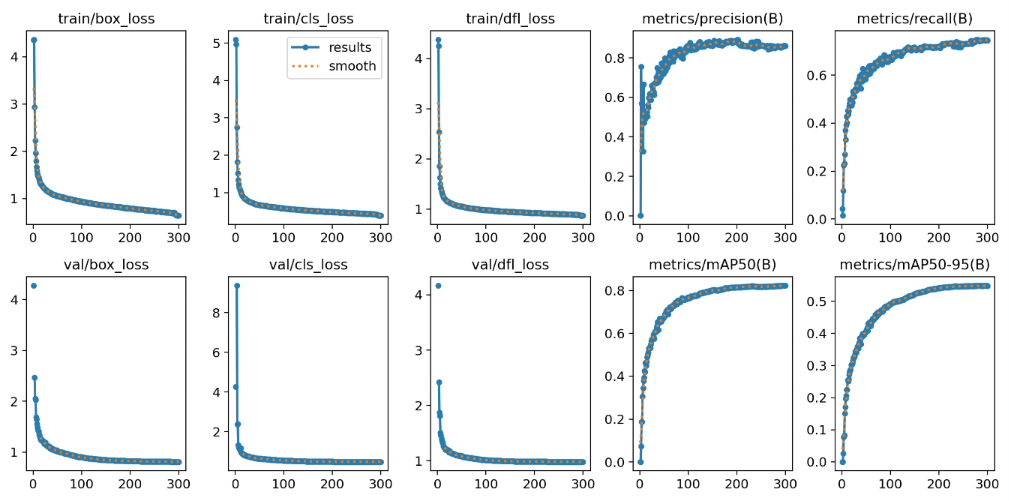
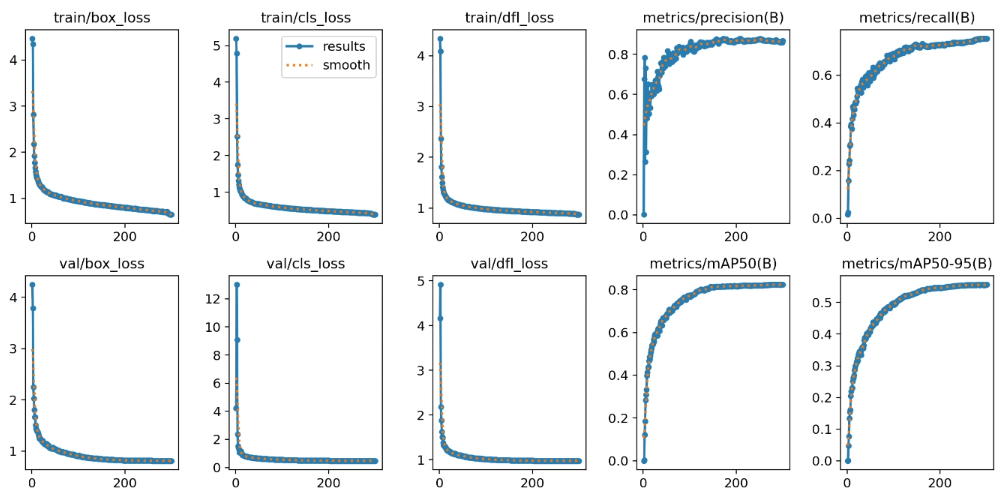
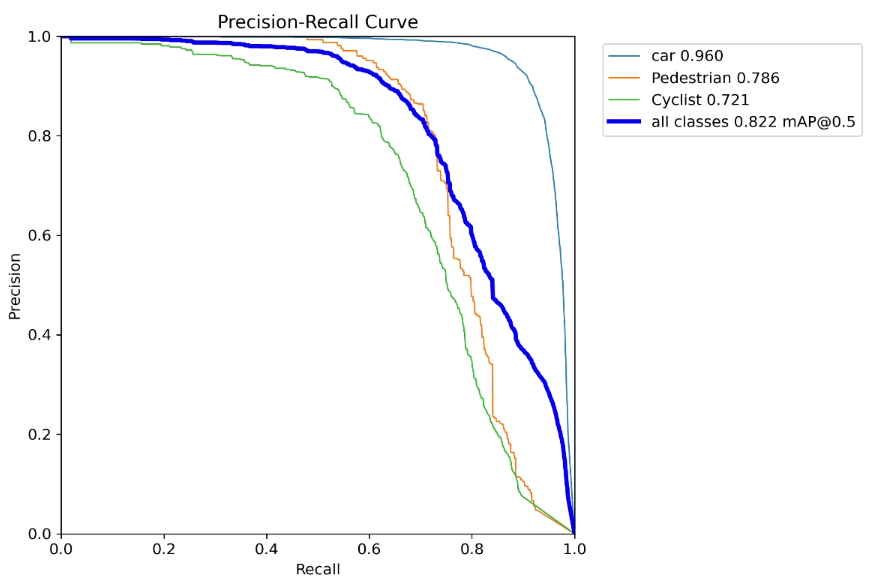
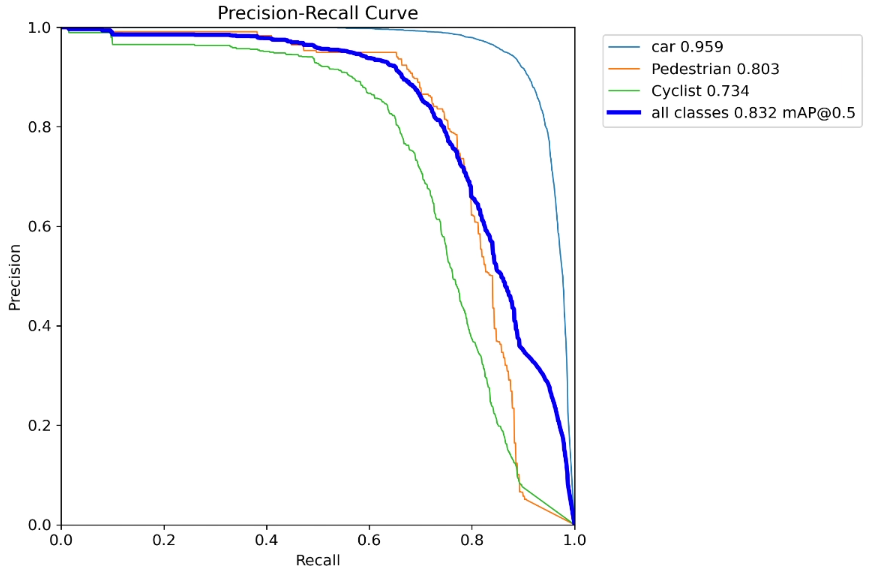
1. HaloAttention介绍
-
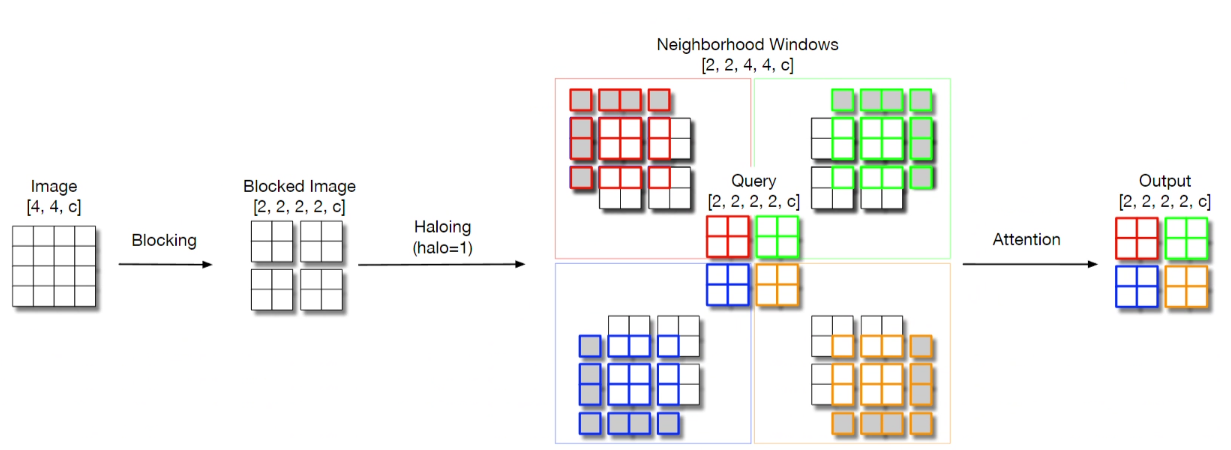
分块局部自注意力(Blocked Local Self-Attention)
该方法将计算复杂度从 O (N²) 降至 O (B²),同时通过 Halo 区域实现跨块信息传递,平衡了局部细节与全局上下文。
-
分块策略:将图像划分为 B×B 的非重叠块,每个块作为查询区域(Query Block)。
-
Halo 区域扩展:每个查询块周围扩展 H×H 的 Halo 区域,形成 (B+2H)×(B+2H) 的邻域块(Key/Value Block)。Halo 区域允许相邻块的信息交互,扩大感受野。
-
注意力计算:在每个查询块的 Halo 邻域内计算自注意力,仅关注块内和 Halo 区域的像素,而非全局所有像素。
-
-
Strided 自注意力下采样
HaloNet 采用Strided 自注意力层替代传统的卷积下采样。具体来说,通过调整查询块的步长(Stride)实现特征图的降采样,同时保持自注意力的内容敏感性。这种设计避免了传统卷积下采样的信息丢失,且减少了 4 倍的计算量(如摘要 9 所述)。 -
放松平移等变性
传统自注意力要求严格的平移等变性(即特征图平移后输出不变),但这会限制硬件利用率。HaloNet 通过分块和 Halo 区域设计,允许块内和 Halo 区域的局部交互,放松平移等变性,从而提升计算效率和模型准确率。
2. YOLOv12与HaloAttention的结合
HSM - SSD 与 YOLOv12 结合,借助其线性计算复杂度和全局建模能力,在提升检测精度的同时保持高效推理,尤其利于小目标和高分辨率场景。
3. HaloAttention代码部分
https://github.com/tgf123/YOLOv8_improve/blob/master/YOLOV12.md
4. 将HaloAttention引入到YOLOv12中
第一: 先新建一个change_model,将下面的核心代码复制到下面这个路径当中,如下图如所示。YOLOv12\ultralytics\change_model。
第二:在task.py中导入包
第三:在task.py中的模型配置部分下面代码
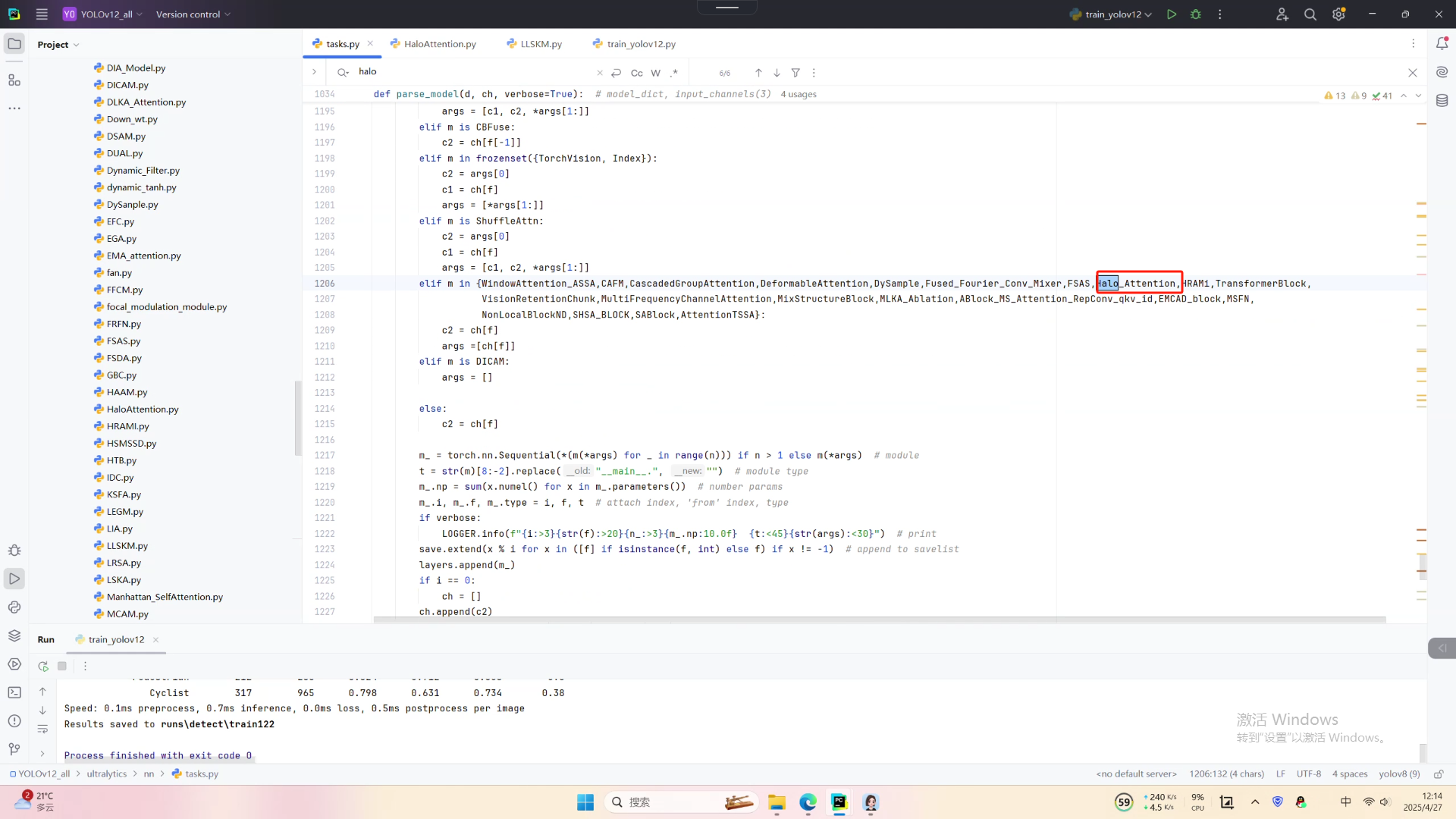
第四:将模型配置文件复制到YOLOV12.YAMY文件中
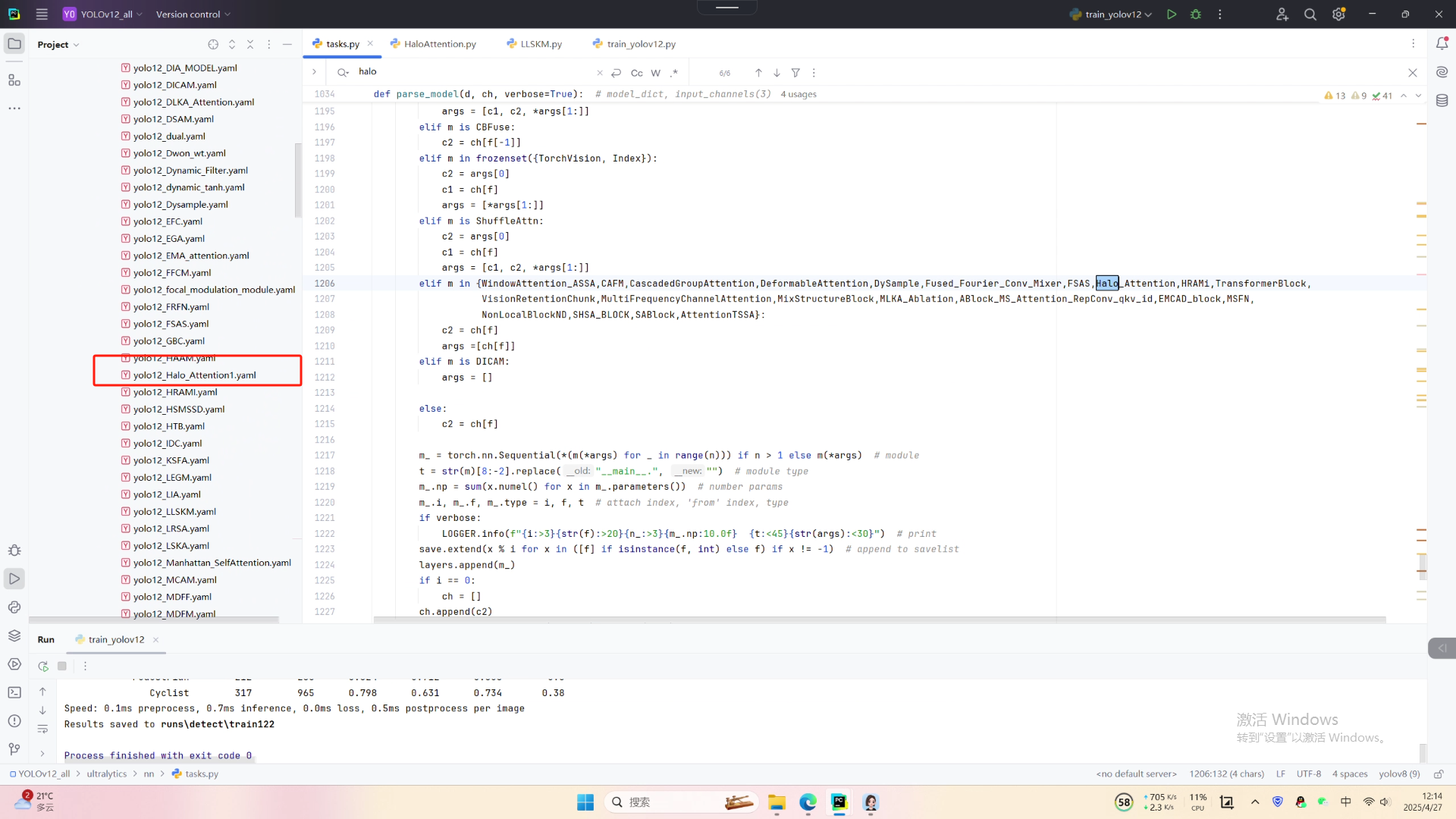
第五:运行代码
from ultralytics.models import NAS, RTDETR, SAM, YOLO, FastSAM, YOLOWorld
if __name__=="__main__":
# 使用自己的YOLOv12.yamy文件搭建模型并加载预训练权重训练模型
model = YOLO(r"E:\Part_time_job_orders\YOLO_NEW\YOLOv12_all\ultralytics\cfg\models\12\yolo12_Halo_Attention.yaml")
# .load(r'E:\Part_time_job_orders\YOLO_NEW\YOLOv12\yolo12n.pt') # build from YAML and transfer weights
results = model.train(data=r'E:\Part_time_job_orders\YOLO\YOLOv12\ultralytics\cfg\datasets\VOC_my.yaml',
epochs=300,
imgsz=640,
batch=64,
# cache = False,
# single_cls = False, # 是否是单类别检测
# workers = 0,
# resume=r'D:/model/yolov8/runs/detect/train/weights/last.pt',
amp = True
)

















 992
992

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









