







在 ViT 时代来临前,Squeeze-and-Excitation(SE)机制率先将通道注意力引入计算机视觉领域,不过它存在着让所有特征图 token 共享相同门控信号、通道注意力缺乏灵活性及过于粗粒度等弊端。进入 ViT 时代,自注意力等全局 token 混合器改变了信息聚合格局,使得 SE 机制的不足愈发明显,而且 ViT 结构自身原本就缺少通道注意力。与此同时,研究发现 3×3 深度卷积可作为条件位置编码。鉴于此背景,作者深入思考通道混合器设计,进而提出 Convolutional GLU。它通过在 GLU 门控分支激活函数前添加 3×3 深度卷积,有效解决了 SE 机制的缺陷,满足了 ViT 模型对位置信息的需求,并且在计算复杂度方面也展现出明显优势。
上面是原模型,下面是改进模型


![]()
1. CGLU结构介绍
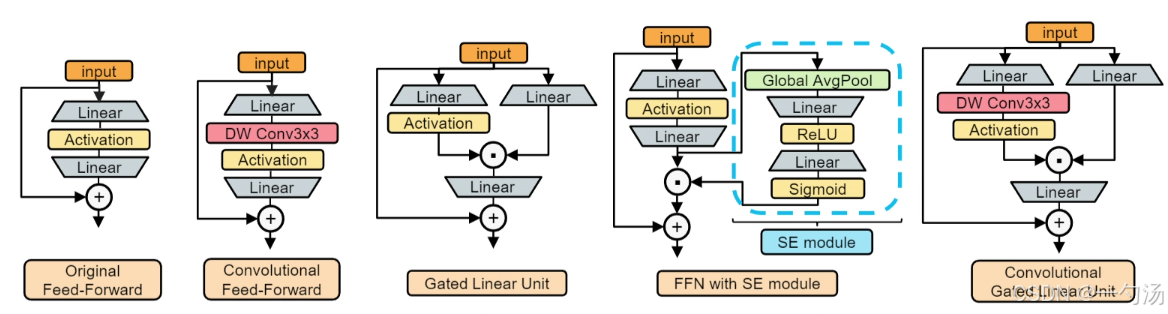
原理:Gated Linear Unit(GLU)由两个线性投影通过元素相乘构成,其中一个投影由门控函数激活。与 SE 机制不同,GLU 每个 token 的门控信号源于 token 自身,且其门控分支的感受野并不比值分支大。在此基础上,作者发现于 GLU 门控分支的激活函数前添加最小形式的 3×3 深度卷积,能使结构契合门控通道注意力的设计理念,转化为基于最近邻特征的门控通道注意力机制。在 Convolutional GLU 中,每个 token 依据其最近的细粒度特征拥有独特的门控信号,克服了 SE 机制中全局平均池化过于粗粒度的缺点,满足了部分无位置编码设计的 ViT 模型对深度卷积提供位置信息的需求,同时其值分支保持与 MLP 和 GLU 相同的深度,利于反向传播。
结构: CGLU 主要由输入的线性变换、深度卷积、激活函数以及元素相乘等操作构成。首先,输入数据会经过两个不同的线性变换分支,一个分支产生的结果(记为分支一结果)会直接用于后续计算,另一个分支产生的结果(记为分支二结果)会先进行 3×3 深度卷积操作,然后通过 GELU 激活函数进行激活。之后,激活后的分支二结果与分支一结果进行元素相乘,最终得到 Convolutional GLU 的输出。这种结构设计使得它能够利用深度卷积提取的局部特征信息来调整门控信号,从而实现基于最近邻特征的门控通道注意力机制,有效提升模型性能。
2. YOLOv11与通道混合器 CGLU的结合
在yolo目标检测模型中,为了增强backbone的通道融合,本文将其与C2PSA相结合,提升YOLOv11模型的精度。
3. 通道混合器 CGLU代码部分
YOLOv8_improve/YOLOv11.md at master · tgf123/YOLOv8_improve · GitHub
视频讲解:YOLOv11模型改进讲解,教您如何修改YOLOv11_哔哩哔哩_bilibili
YOLOv11模型改进讲解,教您如何根据自己的数据集选择最优的模块提升精度_哔哩哔哩_bilibili
YOLOv11全部代码,现有几十种改进机制。
4. 将高效多尺度注意力EMA引入到YOLOv11中
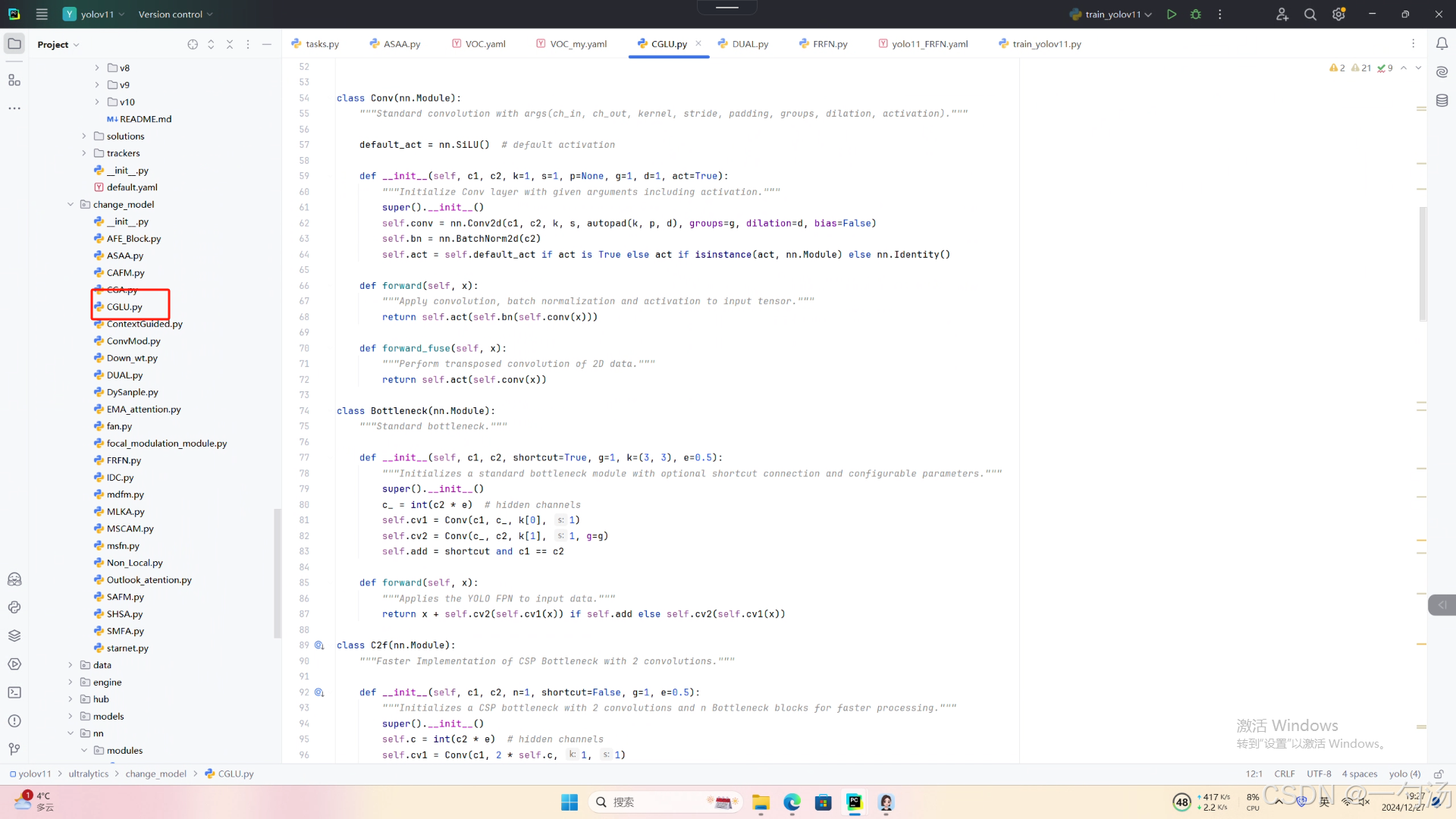
第一: 将下面的核心代码复制到D:\model\yolov11\ultralytics\change_model路径下,如下图所示。
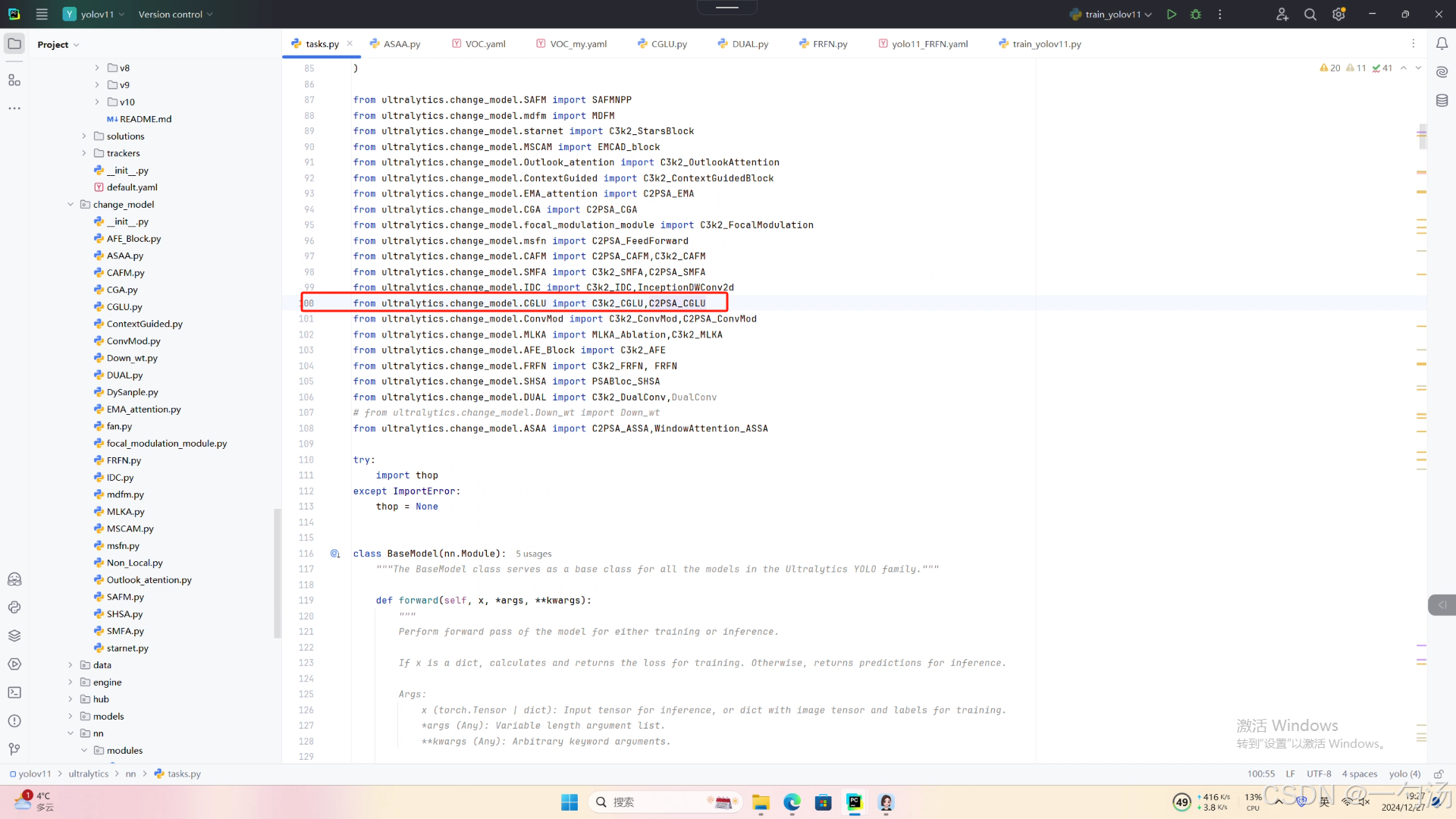
第二:在task.py中导入包
第三:在task.py中的模型配置部分下面代码
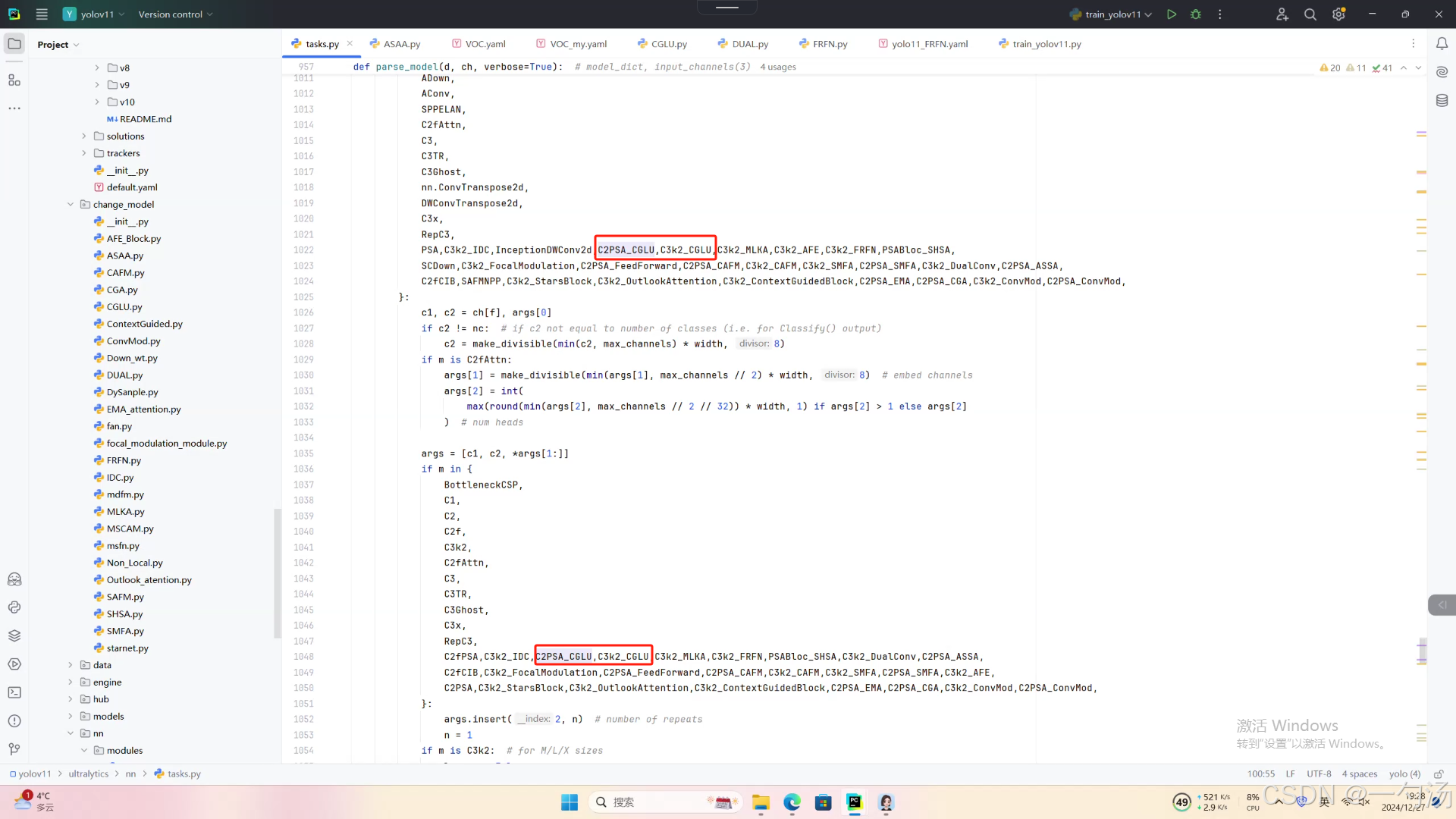
第四:将模型配置文件复制到YOLOV11.YAMY文件中
第五:运行成功
from ultralytics.models import NAS, RTDETR, SAM, YOLO, FastSAM, YOLOWorld
if __name__=="__main__":
# 使用自己的YOLOv8.yamy文件搭建模型并加载预训练权重训练模型
model = YOLO(r"D:\model\yolov11\ultralytics\cfg\models\11\yolo11_CGLU.yaml")\
.load(r'D:\model\yolov11\yolo11n.pt') # build from YAML and transfer weights
results = model.train(data=r'D:\model\yolov11\ultralytics\cfg\datasets\VOC_my.yaml',
epochs=300,
imgsz=640,
batch=64,
# cache = False,
# single_cls = False, # 是否是单类别检测
# workers = 0,
# resume=r'D:/model/yolov8/runs/detect/train/weights/last.pt',
# amp = True
)

















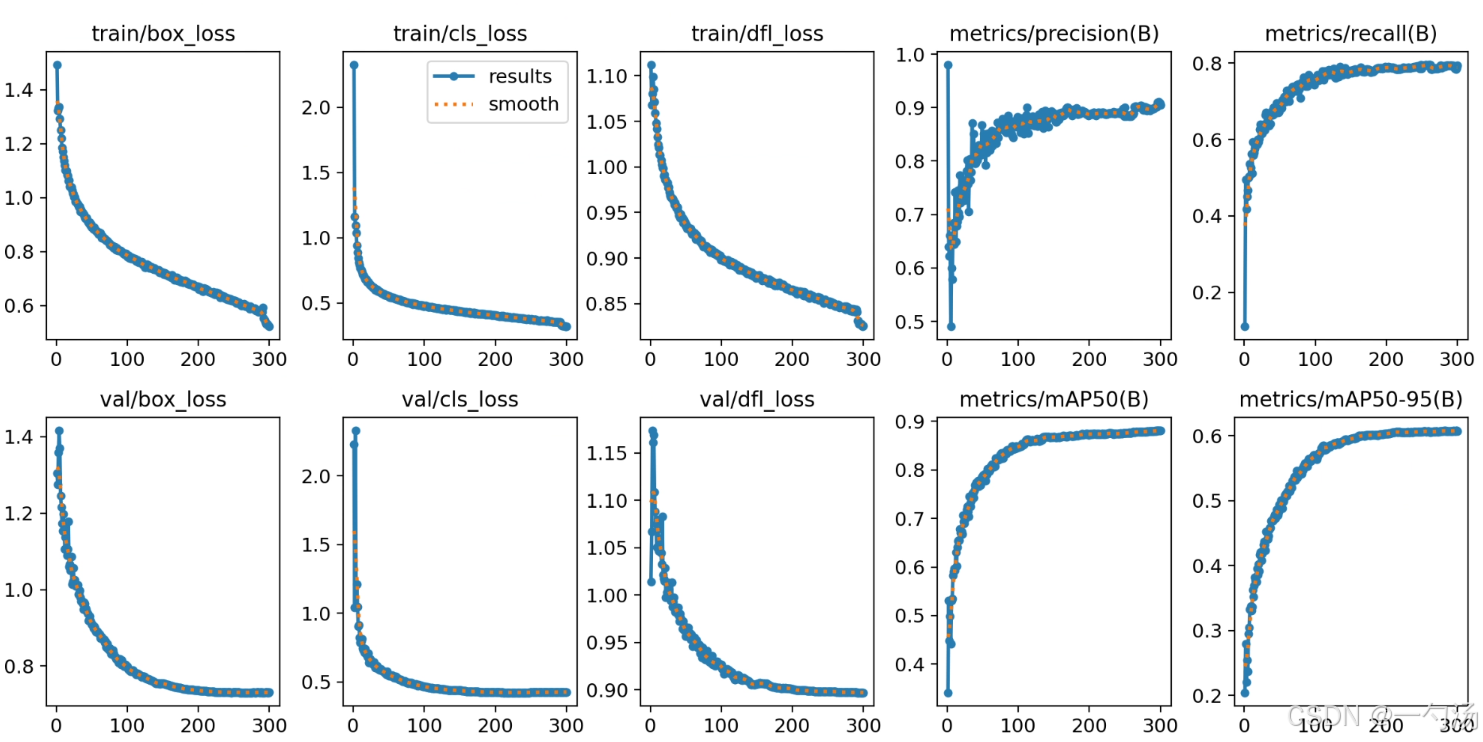
 713
713

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









