







在计算机视觉领域,Vision Transformer(ViT)近年来备受关注,但也存在一些问题。ViT 的核心组件 Self - Attention 缺乏明确的空间先验知识,且在对全局信息建模时具有二次计算复杂度,这在一定程度上限制了其应用范围。许多研究致力于解决这些问题,例如 Swin Transformer 通过窗口操作对用于自注意力的令牌进行分区,从而降低计算成本并引入空间先验;NAT 改变 Self - Attention 的感受野以匹配卷积形状,在降低成本的同时使模型能感知空间先验。在此背景下,本文作者受自然语言处理领域中 Retentive Network(RetNet)的启发,提出了 RMT。RetNet 利用距离相关的时间衰减矩阵为一维单向文本数据提供明确的时间先验,而 RMT 将这种思想扩展到视觉领域,旨在构建一种具有明确空间先验且能有效处理全局信息的通用视觉骨干网络,以提升在图像分类、目标检测、实例分割和语义分割等视觉任务上的性能。
上面是原模型,下面是改进模型


1. 曼哈顿自注意力机制MaSA介绍
Manhattan Self - Attention(MaSA)是 RMT 模型中的关键创新机制,旨在解决 Vision Transformer(ViT)中 Self - Attention 的不足,为视觉任务引入更有效的注意力机制。
1. 原理
从单向到双向衰减:在 RetNet 中,由于文本数据的因果性,其保留机制是单向的,即每个 token 只能关注前面的 token。但在图像识别等任务中,这种单向性并不适用。因此,MaSA 首先将其扩展为双向形式,即 BiRetention。通过将单向的时间衰减转换为双向的形式,使得模型能够更全面地捕捉 token 之间的关系,增强了信息交互的能力。
从一维到二维衰减:虽然 BiRetention 实现了双向建模,但它仍然局限于一维层面,对于二维图像来说是不够的。在图像中,每个 token 都有二维坐标。为了适应图像的二维特性,MaSA 进一步将一维的保留机制扩展到二维。重新定义空间衰减矩阵,该矩阵基于 token 之间的曼哈顿距离,使得对于一个目标 token,周围 token 距离越远,其注意力得分的衰减程度越大。这使得目标 token 在感知全局信息时,能够根据距离远近分配不同程度的注意力,从而更好地捕捉图像中的空间信息。
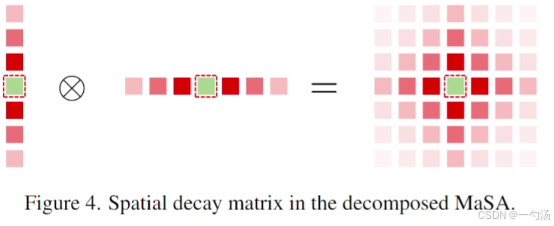
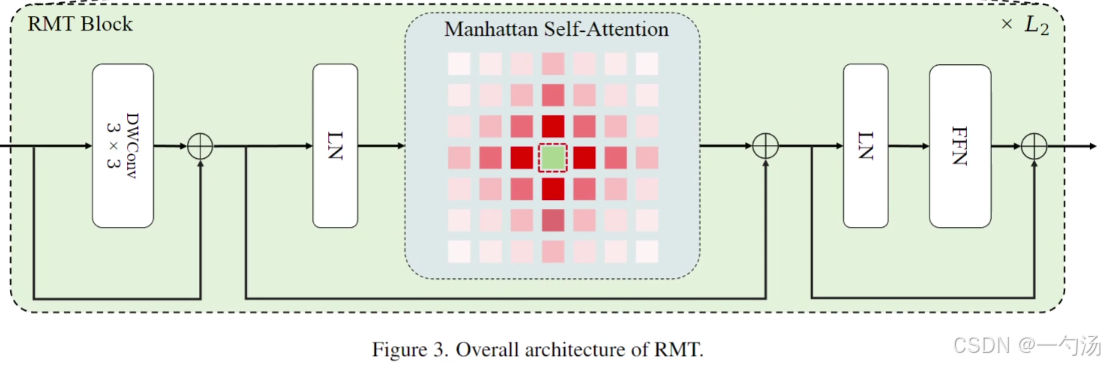
2. 结构:
在结构上,MaSA 在计算注意力时,需要对输入的图像 token 进行处理。首先通过线性变换得到 Query、Key和 Value,然后根据上述的二维空间衰减矩阵计算注意力权重,并与进行加权求和得到最终的输出。在 RMT 的整体架构中,前三个阶段使用分解后的 MaSA,最后一个阶段使用原始的 MaSA,这种结构设计有助于在不同阶段平衡计算复杂度和模型性能,更好地提取图像特征。
2. YOLOv11与MaSA 的结合
可以在YOLOv11原有的局部特征基础上,本文将MaSA 与C2PSA相结合。
3. LLSKM代码部分
YOLOv8_improve/YOLOv11.md at master · tgf123/YOLOv8_improve · GitHub
视频讲解:YOLOv11模型改进讲解,教您如何修改YOLOv11_哔哩哔哩_bilibili
YOLOv11模型改进讲解,教您如何根据自己的数据集选择最优的模块提升精度_哔哩哔哩_bilibili
YOLOv11全部代码,现有几十种改进机制。
4. 将MaSA 引入到YOLOv11中
第一: 将下面的核心代码复制到D:\model\yolov11\ultralytics\change_model路径下,如下图所示。
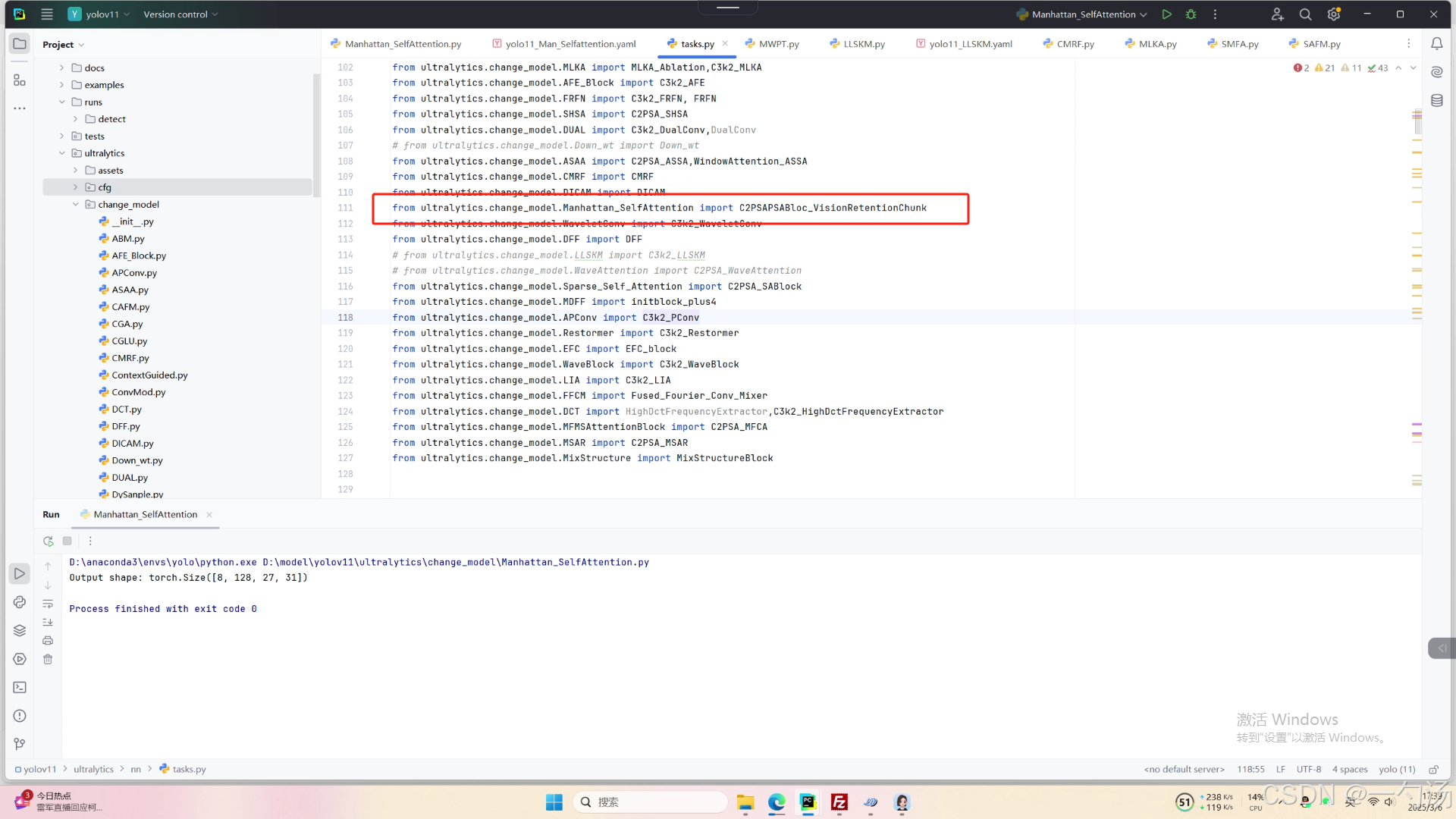
第二:在task.py中导入包
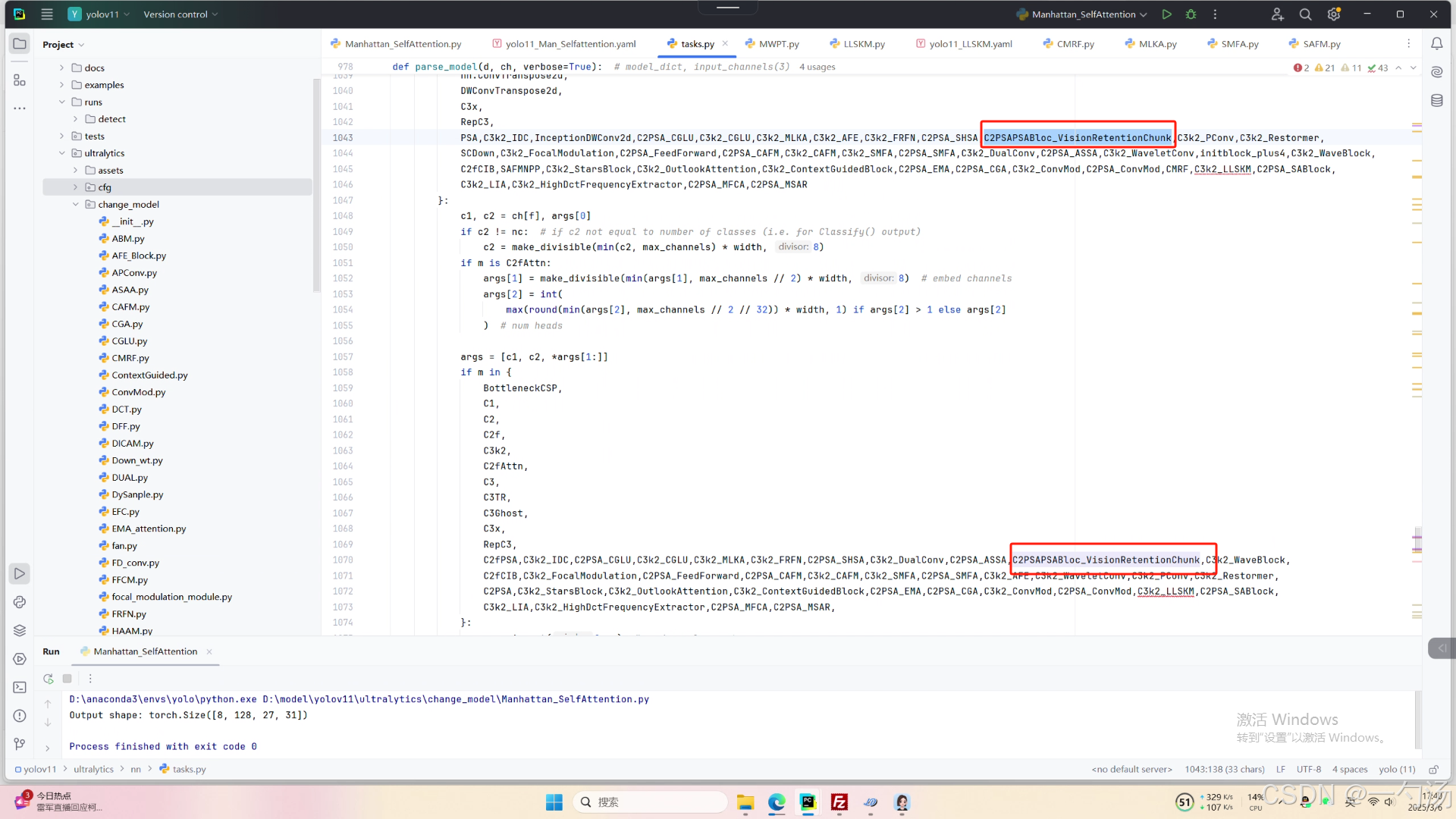
第三:在task.py中的模型配置部分下面代码
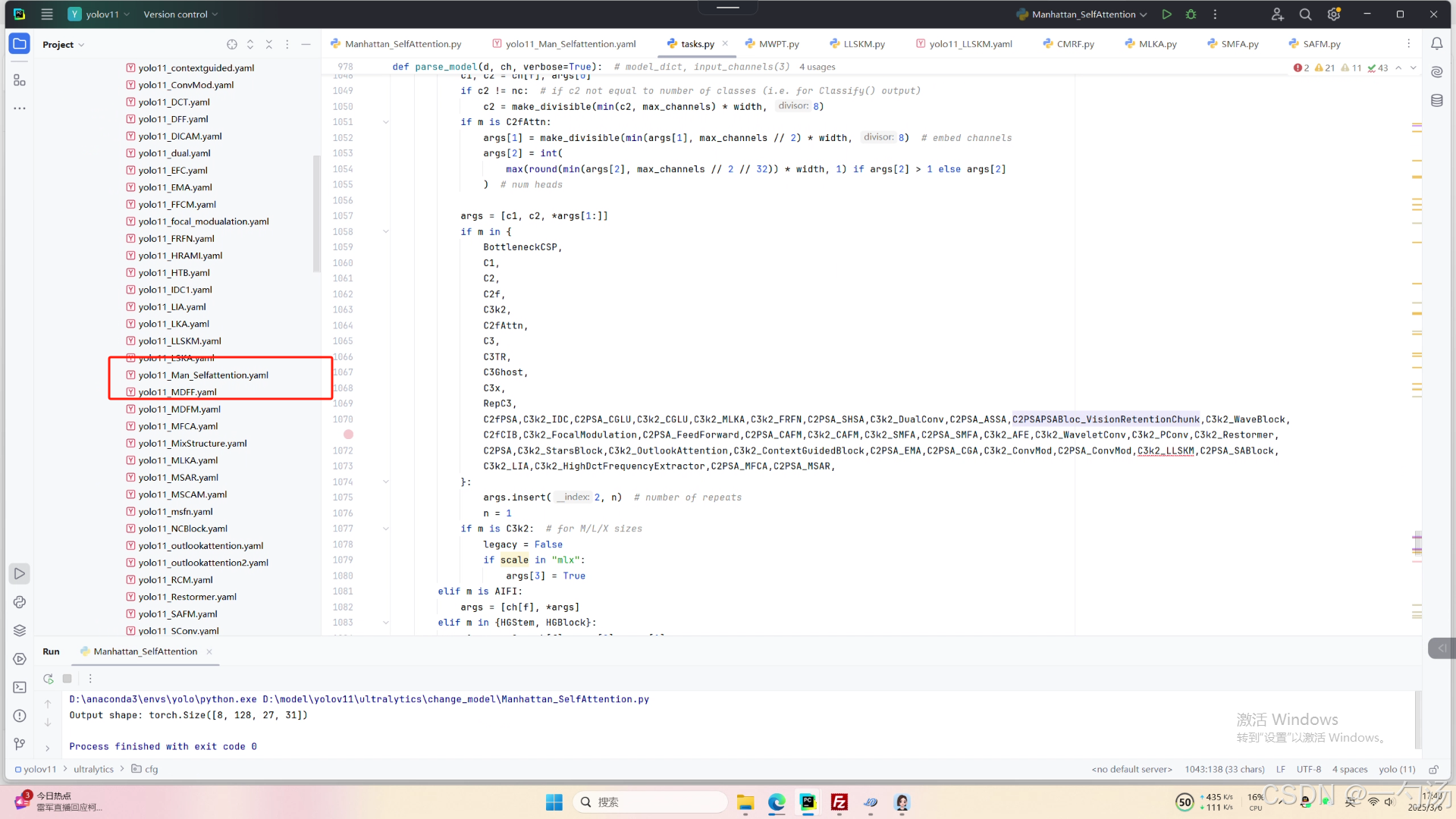
第四:将模型配置文件复制到YOLOV11.YAMY文件中
第五:运行成功
from ultralytics.models import NAS, RTDETR, SAM, YOLO, FastSAM, YOLOWorld
if __name__=="__main__":
# 使用自己的YOLOv8.yamy文件搭建模型并加载预训练权重训练模型
model = YOLO(r"D:\model\yolov11\ultralytics\cfg\models\11\yolo11_LLSKM.yaml")\
.load(r'D:\model\yolov11\yolo11n.pt') # build from YAML and transfer weights
results = model.train(data=r'D:\model\yolov11\ultralytics\cfg\datasets\VOC_my.yaml',
epochs=300,
imgsz=640,
batch=64,
# cache = False,
# single_cls = False, # 是否是单类别检测
# workers = 0,
# resume=r'D:/model/yolov8/runs/detect/train/weights/last.pt',
# amp = True
)

















 3829
3829

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









