







目录
一、范式化 vs 反范式化:核心理念对比
| 维度 | 范式化设计 (3NF+) | 反范式化设计 |
|---|---|---|
| 数据冗余 | 几乎无冗余 | 允许合理冗余 |
| 查询性能 | 多表JOIN可能较慢 | 单表查询更快 |
| 写入效率 | 更新效率高 | 更新成本可能增加 |
| 适用场景 | OLTP系统、数据一致性要求高 | OLAP系统、读密集型场景 |
| 维护复杂度 | 表结构复杂 | 结构简单但需处理冗余一致性 |
二、反范式化的典型应用场景
1. 统计报表加速
场景:每日订单总额统计
范式化设计:
-- 需要多表关联
SELECT
DATE(o.create_time) AS day,
SUM(oi.quantity * p.price) AS total
FROM orders o
JOIN order_items oi ON o.id = oi.order_id
JOIN products p ON oi.product_id = p.id
GROUP BY day;反范式化优化:
-- 订单表冗余金额字段
ALTER TABLE orders ADD COLUMN total_amount DECIMAL(12,2);
-- 查询简化为
SELECT
DATE(create_time) AS day,
SUM(total_amount) AS total
FROM orders
GROUP BY day;2. 高频查询优化
场景:社交网络用户主页展示
-- 原始范式化设计
SELECT
u.username,
u.avatar,
COUNT(p.id) AS post_count,
COUNT(f.follower_id) AS followers
FROM users u
LEFT JOIN posts p ON u.id = p.user_id
LEFT JOIN followers f ON u.id = f.user_id
WHERE u.id = 123;
-- 反范式化设计
ALTER TABLE users ADD COLUMN (
post_count INT DEFAULT 0,
follower_count INT DEFAULT 0
);
-- 优化后查询
SELECT username, avatar, post_count, follower_count
FROM users
WHERE id = 123;三、反范式化实现策略
1. 触发器同步方案
-- 维护冗余的点赞计数器
CREATE TRIGGER update_like_count
AFTER INSERT ON article_likes
FOR EACH ROW
BEGIN
UPDATE articles
SET like_count = like_count + 1
WHERE id = NEW.article_id;
END;2. 应用程序层控制
# 订单创建时同步更新冗余字段
def create_order(order_data):
with transaction.atomic():
order = Order.objects.create(**order_data)
user = order.user
user.total_orders += 1
user.total_spent += order.amount
user.save()3. 物化视图(MySQL 8.0+)
-- 创建预聚合视图
CREATE MATERIALIZED VIEW sales_summary
AS
SELECT
product_id,
SUM(quantity) AS total_sold,
SUM(amount) AS total_revenue
FROM order_items
GROUP BY product_id
WITH DATA;
-- 定期刷新(可配置定时任务)
REFRESH MATERIALIZED VIEW sales_summary;四、数据建模实战步骤
1. 需求分析阶段
-
读写比例:7:3的读多场景适合反范式化
-
数据一致性要求:金融交易系统需谨慎使用
-
查询模式分析:识别TOP 10慢查询
2. 混合建模流程
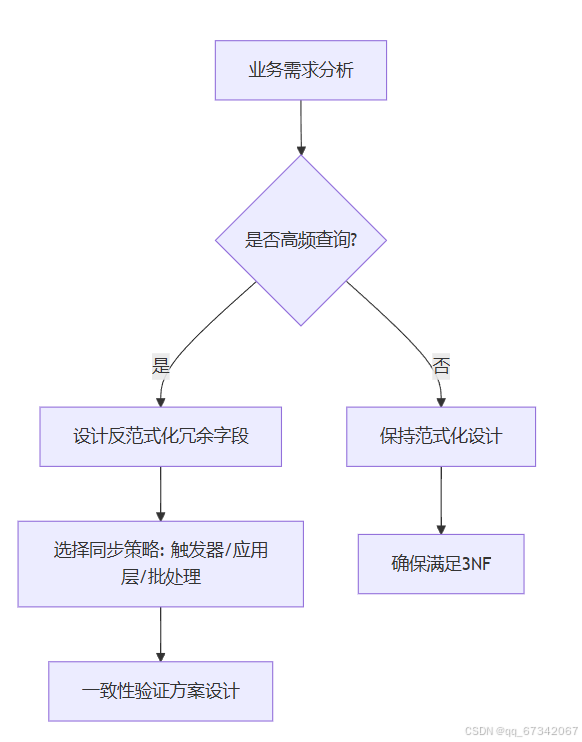
3. 建模工具实践
使用Navicat进行可视化设计:
标记反范式化字段(红色边框)
添加注释说明同步策略
生成DDL时自动包含维护逻辑
五、典型案例分析
案例1:电商商品信息存储
范式化设计:
CREATE TABLE products (
id INT PRIMARY KEY,
name VARCHAR(255),
category_id INT
);
CREATE TABLE categories (
id INT PRIMARY KEY,
name VARCHAR(50)
);反范式化改进:
-- 冗余分类名称到商品表
ALTER TABLE products ADD COLUMN category_name VARCHAR(50);
-- 通过触发器维护一致性
CREATE TRIGGER sync_category_name
AFTER UPDATE ON categories
FOR EACH ROW
BEGIN
UPDATE products
SET category_name = NEW.name
WHERE category_id = NEW.id;
END;案例2:游戏玩家数据统计
-- 原始设计需要实时计算
SELECT
player_id,
COUNT(DISTINCT dungeon_id) AS dungeons_cleared,
SUM(play_time) AS total_play_time
FROM game_logs
GROUP BY player_id;
-- 反范式化设计
CREATE TABLE player_stats (
player_id INT PRIMARY KEY,
dungeons_cleared INT DEFAULT 0,
total_play_time INT DEFAULT 0,
last_updated TIMESTAMP
);
-- 每日定时任务更新
CREATE EVENT update_player_stats
ON SCHEDULE EVERY 1 DAY
DO
BEGIN
REPLACE INTO player_stats
SELECT
player_id,
COUNT(DISTINCT dungeon_id),
SUM(play_time),
NOW()
FROM game_logs
WHERE log_date > CURDATE() - INTERVAL 7 DAY
GROUP BY player_id;
END;六、性能对比测试
测试环境
-
数据量:100万用户,5000万订单记录
-
硬件:8核CPU / 32GB内存 / SSD
| 查询类型 | 范式化执行时间 | 反范式化执行时间 | 提升比例 |
|---|---|---|---|
| 单用户订单查询 | 120ms | 15ms | 8倍 |
| 每日销售统计 | 850ms | 50ms | 17倍 |
| 更新用户信息 | 5ms | 8ms | -60% |
七、注意事项与常见问题
1. 数据一致性保障
-
最终一致性:允许短暂延迟的场景使用异步更新
-
强一致性:使用事务保证多表更新原子性
START TRANSACTION;
UPDATE orders SET total_amount = ...;
UPDATE order_items SET ...;
COMMIT;2. 常见陷阱
-
过度冗余:导致存储空间浪费
-
同步逻辑漏洞:漏掉部分更新路径
-
历史数据处理:存量数据初始化方案缺失
3. 校验方案
-- 定期检查冗余一致性
SELECT
p.id,
p.category_name,
c.name AS real_name
FROM products p
JOIN categories c ON p.category_id = c.id
WHERE p.category_name != c.name;八、总结与最佳实践
渐进式优化:从范式化开始,按需引入反范式化
文档化设计:明确记录每个冗余字段的维护逻辑
监控指标:
冗余字段更新延迟
存储空间增长率
查询性能提升比例
决策流程图:
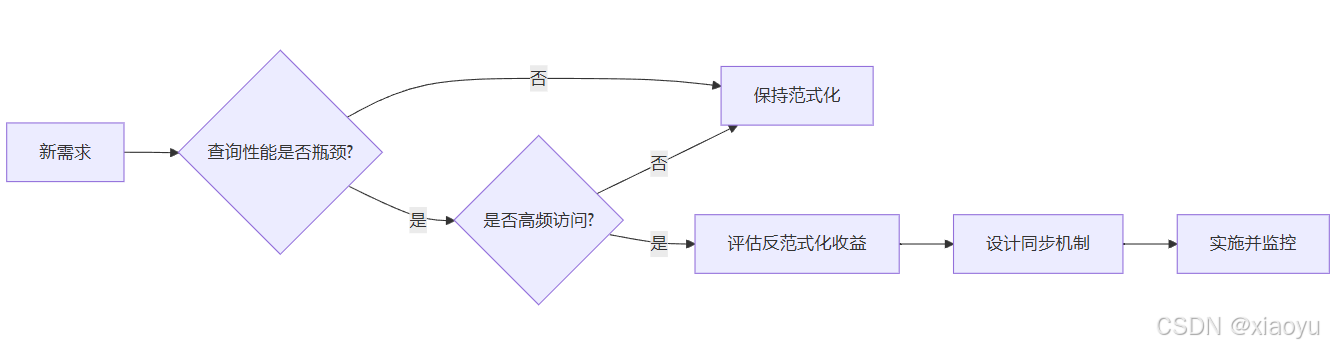


















 591
591

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









