






 本文介绍了全维动态卷积ODConv,一种通过学习卷积核空间所有维度的注意力的改进动态卷积,它在轻量级和大型CNN架构上都能提供显著的准确性提升。ODConv通过多维注意力机制和并行策略,易于集成到现有模型,实验结果展示了其在ImageNet和MS-COCO上的优秀性能。
本文介绍了全维动态卷积ODConv,一种通过学习卷积核空间所有维度的注意力的改进动态卷积,它在轻量级和大型CNN架构上都能提供显著的准确性提升。ODConv通过多维注意力机制和并行策略,易于集成到现有模型,实验结果展示了其在ImageNet和MS-COCO上的优秀性能。

目录
01 介绍
1.1 简单介绍
动态卷积的始祖是CondConv,其基于普通卷积改进。常规卷积只有一个静态卷积核且与输入样本无关,且会用到所有数据集上。此外,卷积神经网络的特点是,通过扩展宽度、深度、分辨率来提升网络模型的表现。在以往的注意力模型中,注意力主要是应用到特征图上。比如在特征图不同的通道上进行加权(SE Net),在特征图不同的空间位置加权(Spatial attention)。对于动态卷积来说,它对多个卷积核进行线性加权,而加权值则与输入有关,这就使得动态卷积具有输入依赖性。也就是说,对于不同的输入,我们使用不同的卷积核。之后对这些不同的卷积核,进行注意力加权。
DConv,该方法通过并行策略采用多维注意力机制沿核空间的四个维度学习互补性注意力。作为一种“即插即用”的操作,它可以轻易的嵌入到现有YOLO网络中。并且实验结果表明它可提升大模型的性能,又可提升轻量型模型的性能,非常好用!
1.2 论文摘要
现代卷积神经网络(CNNs)的常见训练范式是在每个卷积层中学习单个静态卷积核。然而,最近的动态卷积研究表明,通过学习由n个卷积核组成的线性组合,这些卷积核根据它们的输入相关关注度进行加权,可以显著提高轻量级CNN的准确性,同时保持高效的推断。然而,我们观察到现有的工作通过卷积核空间的一个维度(关于卷积核数量)赋予卷积核动态属性,但忽略了卷积核空间的其他三个维度(关于空间尺寸、输入通道数量和每个卷积核的输出通道数量)。受此启发,我们提出了全维动态卷积(ODConv),这是一种更通用但优雅的动态卷积设计,以推进这一研究方向。ODConv利用一种新颖的多维注意力机制和并行策略,以学习卷积核空间的所有四个维度上的卷积核的互补注意力。作为常规卷积的替代品,ODConv可以嵌入到许多CNN架构中。在ImageNet和MS-COCO数据集上的大量实验表明,ODConv为各种流行的CNN骨干架构,包括轻量级和大型架构,提供了坚实的准确性提升,例如,在ImageNet数据集上MobivleNetV2|ResNet家族的绝对top-1准确性提升为3.77%∼5.71%|1.86%∼3.72%。有趣的是,由于其改进的特征学习能力,即使只有一个单一卷积核,ODConv也可以与现有的具有多个卷积核的动态卷积方法竞争或超越,从而大大减少额外的参数。此外,ODConv还优于用于调制输出特征或卷积权重的其他注意力模块。代码和模型可在GitHub - OSVAI/ODConv: The official project website of "Omni-Dimensional Dynamic Convolution" (ODConv for short, spotlight in ICLR 2022). 获取。
02 代码
以下是ODConv代码,包括我们多注意力卷积ODConv_3rd和二维卷积ODConv2d_3rd。
2.1 创建ODConv代码
其中ODConv_3rd是我们的ODConv卷积的类,因为他是可以是一个卷积也可以是一个模块,将下列代码放在Block.py或者conv.py中,路径分别是ultralytics/nn/modules/block.py和conv.py。我们把它放在block.py中。
import torch
import torch.nn as nn
import torch.nn.functional as F
import numpy as np
def autopad(k, p=None, d=1): # kernel, padding, dilation
"""Pad to 'same' shape outputs."""
if d > 1:
k = d * (k - 1) + 1 if isinstance(k, int) else [d * (x - 1) + 1 for x in k] # actual kernel-size
if p is None:
p = k // 2 if isinstance(k, int) else [x // 2 for x in k] # auto-pad
return p
class ODConv2d_3rd(nn.Conv2d):
def __init__(self, in_channels, out_channels, kernel_size,
stride=1, padding=0, dilation=1, groups=1, bias=True,
K=4, r=1 / 16, save_parameters=False,
padding_mode='zeros', device=None, dtype=None) -> None:
factory_kwargs = {'device': device, 'dtype': dtype}
self.K = K
self.r = r
self.save_parameters = save_parameters
super().__init__(in_channels, out_channels, kernel_size, stride,
padding, dilation, groups, bias, padding_mode)
del self.weight
self.weight = nn.Parameter(torch.empty((
K,
out_channels,
in_channels // groups,
*self.kernel_size,
), **factory_kwargs))
if bias:
del self.bias
self.bias = nn.Parameter(torch.empty(K, out_channels, **factory_kwargs))
hidden_dim = max(int(in_channels * r), 16) #设置下限为16
self.gap = nn.AdaptiveAvgPool2d(1)
self.reduction = nn.Linear(in_channels, hidden_dim)
self.fc = nn.Conv2d(in_channels, hidden_dim, 1, bias = False)
self.bn = nn.BatchNorm2d(hidden_dim)
self.act = nn.ReLU(inplace=True)
# self.act = nn.SiLU(inplace=True)
self.fc_f = nn.Linear(hidden_dim, out_channels)
if not save_parameters or self.kernel_size[0] * self.kernel_size[1] > 1:
self.fc_s = nn.Linear(hidden_dim, self.kernel_size[0] * self.kernel_size[1])
if not save_parameters or in_channels // groups > 1:
self.fc_c = nn.Linear(hidden_dim, in_channels // groups)
if not save_parameters or K > 1:
self.fc_w = nn.Linear(hidden_dim, K)
self.reset_parameters()
def reset_parameters(self) -> None:
fan_out = self.kernel_size[0] * self.kernel_size[1] * self.out_channels // self.groups
for i in range(self.K):
self.weight.data[i].normal_(0, math.sqrt(2.0 / fan_out))
if self.bias is not None:
self.bias.data.zero_()
def extra_repr(self):
return super().extra_repr() + f', K={self.K}, r={self.r:.4}'
def get_weight_bias(self, context):
B, C, H, W = context.shape
if C != self.in_channels:
raise ValueError(
f"Expected context{[B, C, H, W]} to have {self.in_channels} channels, but got {C} channels instead")
# x = self.gap(context).squeeze(-1).squeeze(-1) # B, c_in
# x = self.reduction(x) # B, hidden_dim
x = self.gap(context)
x = self.fc(x)
if x.size(0)>1:
x = self.bn(x)
x = x.squeeze(-1).squeeze(-1)
x = self.act(x)
attn_f = self.fc_f(x).sigmoid() # B, c_out
attn = attn_f.view(B, 1, -1, 1, 1, 1) # B, 1, c_out, 1, 1, 1
if hasattr(self, 'fc_s'):
attn_s = self.fc_s(x).sigmoid() # B, k * k
attn = attn * attn_s.view(B, 1, 1, 1, *self.kernel_size) # B, 1, c_out, 1, k, k
if hasattr(self, 'fc_c'):
attn_c = self.fc_c(x).sigmoid() # B, c_in // groups
attn = attn * attn_c.view(B, 1, 1, -1, 1, 1) # B, 1, c_out, c_in // groups, k, k
if hasattr(self, 'fc_w'):
attn_w = self.fc_w(x).softmax(-1) # B, n
attn = attn * attn_w.view(B, -1, 1, 1, 1, 1) # B, n, c_out, c_in // groups, k, k
weight = (attn * self.weight).sum(1) # B, c_out, c_in // groups, k, k
weight = weight.view(-1, self.in_channels // self.groups, *self.kernel_size) # B * c_out, c_in // groups, k, k
bias = None
if self.bias is not None:
if hasattr(self, 'fc_w'):
bias = attn_w @ self.bias
else:
bias = self.bias.tile(B, 1)
bias = bias.view(-1) # B * c_out
return weight, bias
def forward(self, input, context=None):
B, C, H, W = input.shape
if C != self.in_channels:
raise ValueError(
f"Expected input{[B, C, H, W]} to have {self.in_channels} channels, but got {C} channels instead")
weight, bias = self.get_weight_bias(context or input)
output = nn.functional.conv2d(
input.view(1, B * C, H, W), weight, bias,
self.stride, self.padding, self.dilation, B * self.groups) # 1, B * c_out, h_out, w_out
output = output.view(B, self.out_channels, *output.shape[2:])
return output
def debug(self, input, context=None):
B, C, H, W = input.shape
if C != self.in_channels:
raise ValueError(
f"Expected input{[B, C, H, W]} to have {self.in_channels} channels, but got {C} channels instead")
output_size = [
((H, W)[i] + 2 * self.padding[i] - self.dilation[i] * (self.kernel_size[i] - 1) - 1) // self.stride[i] + 1
for i in range(2)
]
weight, bias = self.get_weight_bias(context or input)
weight = weight.view(B, self.groups, self.out_channels // self.groups, -1) # B, groups, c_out // groups, c_in // groups * k * k
unfold = nn.functional.unfold(
input, self.kernel_size, self.dilation, self.padding, self.stride) # B, c_in * k * k, H_out * W_out
unfold = unfold.view(B, self.groups, -1, output_size[0] * output_size[1]) # B, groups, c_in // groups * k * k, H_out * W_out
output = weight @ unfold # B, groups, c_out // groups, H_out * W_out
output = output.view(B, self.out_channels, *output_size) # B, c_out, H_out * W_out
if bias is not None:
output = output + bias.view(B, self.out_channels, 1, 1)
return output
class ODConv_3rd(nn.Module):
# Standard convolution
def __init__(self, c1, c2, k=1, s=1, kerNums=1, g=1, p=None, act=True): # ch_in, ch_out, kernel, stride, padding, groups
super().__init__()
self.conv = ODConv2d_3rd(c1, c2, k, s, autopad(k, p), groups=g, K=kerNums)
self.bn = nn.BatchNorm2d(c2)
self.act = nn.SiLU() if act is True else (act if isinstance(act, nn.Module) else nn.Identity())
def forward(self, x):
return self.act(self.bn(self.conv(x)))
def forward_fuse(self, x):
return self.act(self.conv(x))03 直接单独使用ODConv_3rd
3.1 添加调用名
3.1.1 在block或conv.py中添加
我在block.py路径,找到以下代码,将我们添加的'ODConv_3rd'加入其中。
__all__ = [
'DFL', 'HGBlock', 'HGStem', 'SPP', 'SPPF', 'C1', 'C2', 'C3', 'C2f', 'C3x', 'C3TR', 'C3Ghost', 'GhostBottleneck',
'Bottleneck', 'BottleneckCSP', 'Proto', 'RepC3',
'C2f_DCN','C2f_DSConv','SPPF_Biformer','Bottleneck_DBB','C2f_DBB','EVCBlock','C2f_EMA','ODConv_3rd']3.1.2 在init加载函数中添加到modules中
路径在ultralytics/nn/modules/__init__.py,因为我们把他放在了block中,所以在block中添加导入的ODConv_3rd。
from .block import (C1, C2, C3, C3TR, DFL, SPP, SPPF, Bottleneck, BottleneckCSP, C2f, C3Ghost, C3x, GhostBottleneck,
HGBlock, HGStem, Proto, RepC3,
C2f_DCN,C2f_DSConv,SPPF_Biformer,C2f_DBB,Bottleneck_DBB,EVCBlock, C2f_EMA,ODConv_3rd)#自己加的在下方all中也加入ODConv_3rd。
__all__ = [
'Conv', 'LightConv', 'RepConv', 'DWConv', 'DWConvTranspose2d', 'ConvTranspose', 'Focus', 'GhostConv',
'ChannelAttention', 'SpatialAttention', 'CBAM', 'Concat', 'TransformerLayer', 'TransformerBlock', 'MLPBlock',
'LayerNorm2d', 'DFL', 'HGBlock', 'HGStem', 'SPP', 'SPPF', 'C1', 'C2', 'C3', 'C2f', 'C3x', 'C3TR', 'C3Ghost',
'GhostBottleneck', 'Bottleneck', 'BottleneckCSP', 'Proto', 'Detect', 'Segment', 'Pose', 'Classify',
'TransformerEncoderLayer', 'RepC3', 'RTDETRDecoder', 'AIFI', 'DeformableTransformerDecoder',
'DeformableTransformerDecoderLayer', 'MSDeformAttn', 'MLP','deattn',
'DCNv2','ODConv_3rd',
'C2f_DCN','C2f_DSConv','C2f_Biformer','DiverseBranchBlock','Bottleneck_DBB','C2f_DBB','EVCBlock','C2f_EMA','C2f_ODConv']3.1.3 在tasks.py中添加名并设置通道导入
在ultralytics/nn/tasks.py路径下,添加导入的模块
from ultralytics.nn.modules import (AIFI, C1, C2, C3, C3TR, SPP, SPPF, Bottleneck, BottleneckCSP, C2f, C3Ghost, C3x,
Classify, Concat, Conv, ConvTranspose, Detect, DWConv, DWConvTranspose2d, Focus,
GhostBottleneck, GhostConv, HGBlock, HGStem, Pose, RepC3, RepConv, RTDETRDecoder,
DCNv2,
Segment,CBAM,C2f_DCN,C2f_DSConv,SPPF_Biformer,C2f_DBB, C2f_EMA,EVCBlock,
ODConv_3rd)将模块使用通道数,添加到通道中,找到以下代码,名称添加进去。
if m in (Classify, Conv, ConvTranspose, GhostConv, Bottleneck, GhostBottleneck, SPP, SPPF, DWConv, Focus,DCNv2,
BottleneckCSP, C1, C2, C2f, C3, C3TR, C3Ghost, nn.ConvTranspose2d, DWConvTranspose2d, C3x, RepC3,BasicRFB_a,BasicRFB,
C2f_DCN,C2f_DSConv,SPPF_Biformer,C2f_DBB,EVCBlock,BoT3, C2f_EMA,ODConv_3rd):
c1, c2 = ch[f], args[0] #赋值c1c2通道
if c2 != nc: # if c2 not equal to number of classes (i.e. for Classify() output) #通道数不等于类别数
c2 = make_divisible(min(c2, max_channels) * width, 8) #设置为最小的整除8的数
args = [c1, c2, *args[1:]]#参数列表排序3.2 修改ymal配置文件
我们是使用ODConv_3rd卷积替换一层正常的Conv,在电脑允许情况下,可以自己尝试把其他的Conv也替换。
backbone:
# [from, repeats, module, args] 640*640*3
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2 320*320*64 *w
- [-1, 1, ODConv_3rd, [128, 3, 2]] # 1-P2/4 160*160*128 *w
- [-1, 3, C2f, [128, True]] # 160*160*128 *w
- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8 80*80*256 *w
- [-1, 6, C2f, [256, True]] # 80*80*256 *w
- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16 40*40*512 *w
- [-1, 6, C2f, [512, True]] # 40*40*512 *w
- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32 20*20*512 *w*r
- [-1, 3, C2f, [1024, True]] # 20*20*512 w*r
- [-1, 1, SPPF, [1024]] # 9 # 20*20*1024 w*r
# YOLOv8.0n head
head:
- [-1, 1, nn.Upsample, [None, 2, 'nearest']] # 40*40*512 w*r
- [[-1, 6], 1, Concat, [1]] # cat backbone P4 11 40*40*512 *(w+wr)
- [-1, 3, C2f, [512]] # 12 # 40*40*512 *w
- [-1, 1, nn.Upsample, [None, 2, 'nearest']] # 80*80*256 *w
- [[-1, 4], 1, Concat, [1]] # cat backbone P3 80*80*512 *w
- [-1, 3, C2f, [256]] # 15 (P3/8-small) 80*80*256 *w --Detect
- [-1, 1, Conv, [256, 3, 2]] # 40*40*256 *w
- [[-1, 12], 1, Concat, [1]] # cat head P4 # 40*40*512 *w
- [-1, 3, C2f, [512]] # 18 (P4/16-medium) # 40*40*512 *w --Detect
- [-1, 1, Conv, [512, 3, 2]] # 20*20*512 *w
- [[-1, 9], 1, Concat, [1]] # cat head P5 # 20*20*512 *(w+wr)
- [-1, 3, C2f, [1024]] # 21 (P5/32-large) # 20*20*512 *w --Detect
- [[15, 18, 21], 1, Detect, [nc]] # Detect(P3=80*80*256 *w, P4=40*40*512 *w, P5=20*20*512)3.3 模型运行
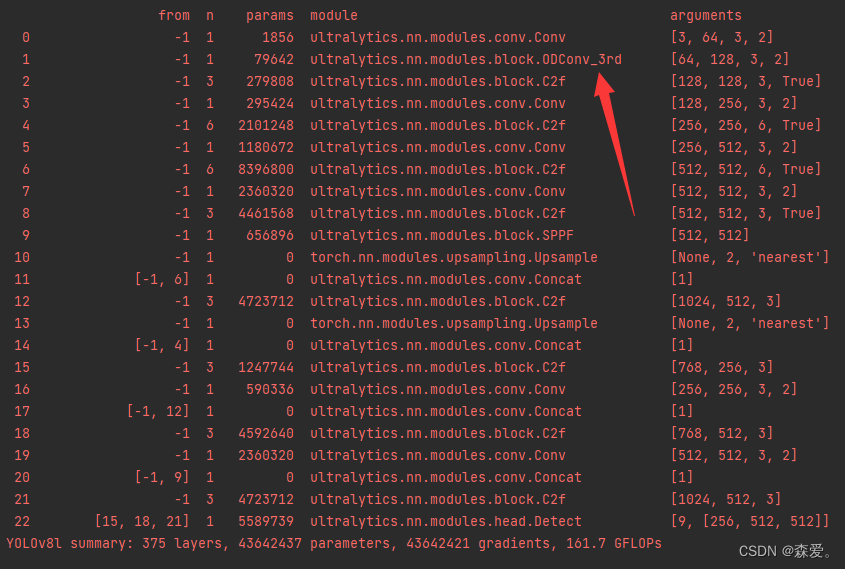
我们可以看到加入ODConv_3rd能够进行正常训练。
04 将ODConv加入C2f中
4.1

















 659
659

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









