









大家好,我是不是小upper~
在13号的时候给大家分享了一篇关于PCA的内容,曝光量还不错。有兴趣的读者可以点下方链接查看:
结合大家给到我私信的内容,今儿和大家分享的是关于KNN的内容,K-近邻在大家印象中一定是是一种简单又常用的机器学习算法。常常用于分类和回归任务。 具体它是怎么工作的呢?请读者们听我慢慢道来~~~
KNN(K - 近邻算法)是一种简单直观的机器学习方法,核心思想是 “近朱者赤,近墨者黑”—— 通过分析新数据点周围最接近的 K 个已知数据点(邻居)的标签,来判断新数据点的类别或预测其数值。
一、核心工作原理
KNN 无需提前训练模型,直接利用全部训练数据进行预测,核心步骤如下:
1. 确定邻居数量 K
K 是人为设定的超参数,表示选择 “最接近的 K 个邻居” 参与决策。
- K=1:只听最近一个邻居的意见(容易受异常值影响)
- K 较大:综合更多邻居意见(降低噪声影响,但可能模糊局部特征) 通常通过实验或交叉验证选择最优 K 值(如 K=3、5、7 等奇数,避免平局)。
2. 计算数据点间的距离
衡量两个数据点的 “相似度”,常用距离公式:
- 欧几里得距离(适用于连续特征): 例如二维点 (x1,y1) 和 (x2,y2) 的直线距离。
- 曼哈顿距离(适用于网格数据):
3. 筛选 K 个最近邻居
根据距离从小到大排序,选出距离新数据点最近的 K 个训练数据点。
4. 分类与回归决策
- 分类任务(如垃圾邮件识别): 统计 K 个邻居中出现次数最多的类别,作为新数据点的类别(多数表决)。
- 回归任务(如房价预测): 计算 K 个邻居数值的平均值,作为新数据点的预测值。
二、算法流程详解
-
数据准备: 准备包含特征向量和标签的训练数据集
,其中
是特征(如水果的大小、颜色),
是标签(如 “苹果”“橙子”)。
-
参数选择: 确定 K 值(如 K=3)。
-
距离计算: 对新数据点
,计算其与所有训练数据点的距离。例如二维特征下,新点
与训练点
的欧几里得距离为
。
-
邻居筛选: 按距离从小到大排序,取前 K 个数据点。
-
结果预测:
- 分类:统计 K 个邻居的标签,选出现次数最多的类别(如 2 个 “苹果”、1 个 “橙子”,则判为 “苹果”)。
- 回归:计算 K 个邻居数值的平均值(如邻居房价为 [200 万,300 万,250 万],预测值为 250 万)。
三、数学原理与公式
1. 距离度量公式(以 n 维特征为例)
- 欧几里得距离:
- 曼哈顿距离:
2. 分类决策
假设 K 个邻居的标签为 ,预测类别为出现次数最多的标签:
3. 回归决策
假设 K 个邻居的数值为 ,预测值为平均值:
四、具体示例:二维数据分类
训练数据:
| 数据点 | 坐标 (x, y) | 类别 |
|---|---|---|
| 点 A | (1, 2) | 0 |
| 点 B | (2, 3) | 0 |
| 点 C | (3, 3) | 1 |
| 点 D | (6, 5) | 1 |
新数据点:,选择 K=3。
-
计算距离:
- 点 A:
- 点 B:
- 点 C:
- 点 D:
- 点 A:
-
筛选最近 3 个邻居:点 A(距离 1)、点 B(距离 1)、点 C(距离 1.414),对应类别为 0、0、1。
-
分类决策:0 出现 2 次,1 出现 1 次,预测新数据点类别为 0。
五、适用场景与优缺点
- 优点:
- 无需训练,直接使用原始数据,简单易实现。
- 可解释性强,预测结果可追溯到具体邻居。
- 缺点:
- 数据量大时计算慢(每次预测需遍历全数据集)。
- 高维数据中距离度量失效(维度灾难)。
- 适合场景:
- 小规模数据集的分类 / 回归任务(如手写数字识别基线模型)。
- 探索性分析,快速验证数据是否存在局部聚集特征。
综上所述哈,咱今儿个通过调整 K 值和距离度量方式,KNN 能灵活适应多种简单场景,是理解机器学习 “数据驱动决策” 的绝佳入门算法。
完整案例:KNN 算法在鸢尾花分类中的应用与优化
步骤 1:数据准备与可视化
鸢尾花数据集是经典的多分类数据集,包含 150 个样本,每个样本有 4 个特征(花萼长度、宽度,花瓣长度、宽度),目标是将鸢尾花分为 3 类(Setosa、Versicolour、Virginica)。
import numpy as np
import pandas as pd
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import accuracy_score, classification_report, confusion_matrix
import matplotlib.pyplot as plt
import seaborn as sns
# 加载数据集并转换为DataFrame
iris = datasets.load_iris()
X = iris.data # 特征矩阵(4维)
y = iris.target # 类别标签(0/1/2)
df = pd.DataFrame(data=np.c_[X, y], columns=iris.feature_names + ['target'])
# 可视化数据分布(特征两两组合的散点图矩阵)
sns.pairplot(df, hue='target', markers=["o", "s", "D"], height=3)
plt.title("鸢尾花数据集特征分布可视化")
plt.show()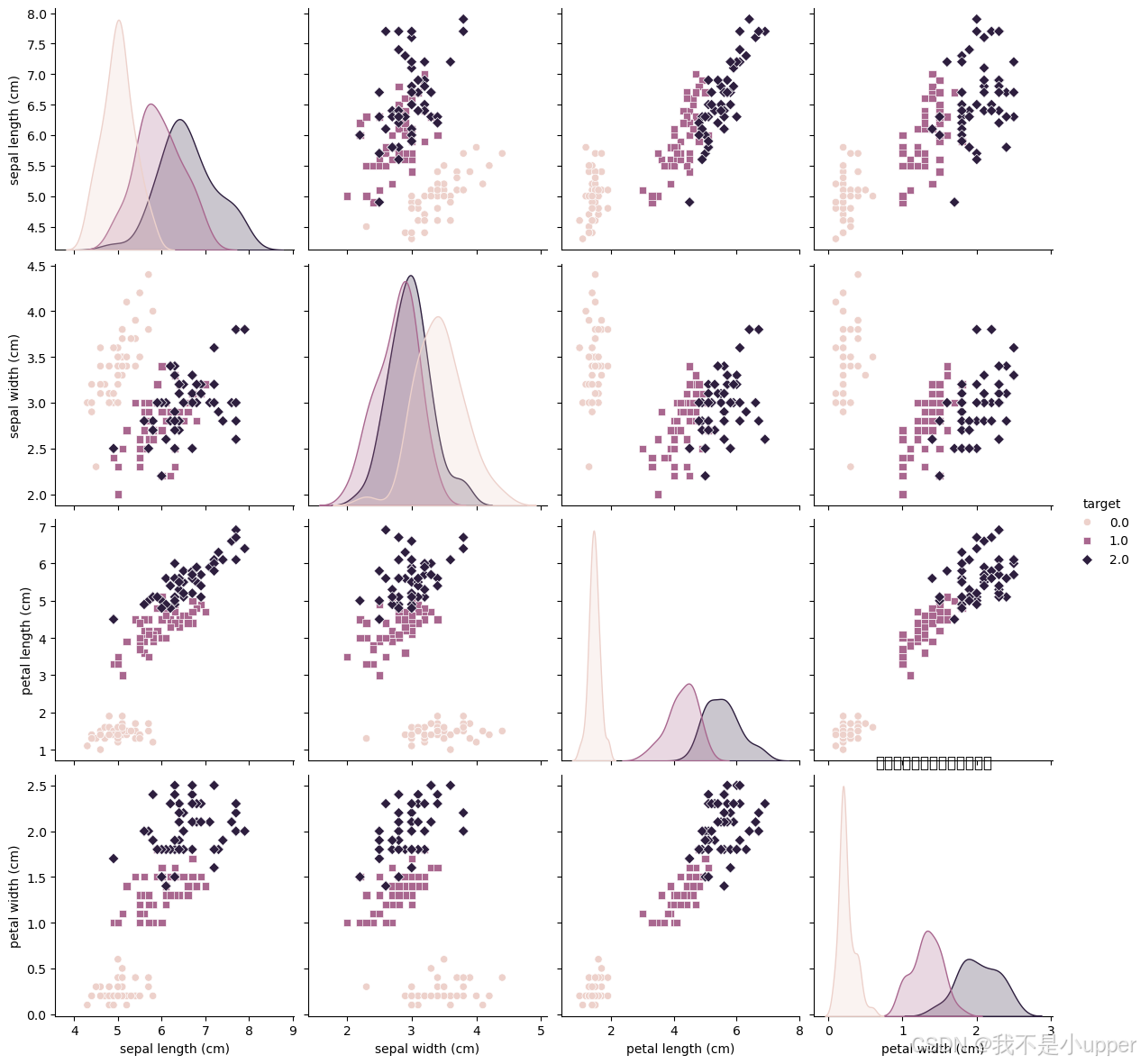
上图输出展示了鸢尾花数据集里不同特征的分布和关系。图中用不同颜色的点和曲线来区分鸢尾花的三个类别(0、1、2)。对角线的图是单个特征(如花萼长度、花萼宽度等)的密度分布,能看出不同类别在该特征上的分布情况,比如花萼长度这个特征上,不同类别的分布范围和形状有差异。非对角线的图是两个特征之间的散点图,比如花萼长度和花萼宽度的组合,通过点的分布可以看出不同类别在这两个特征上的关系,有些类别在某些特征组合上分布比较集中,有些则比较分散。整体来看,这张图帮助我们直观地了解鸢尾花不同类别在各个特征及其组合上的表现,方便判断哪些特征对区分不同类别更有帮助。
步骤 2:数据预处理
KNN 对特征量纲敏感(如花瓣长度单位为厘米,花萼宽度单位为毫米),需通过标准化消除量纲影响:
# 划分训练集与测试集(70%训练,30%测试)
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.3, random_state=42 # random_state固定随机种子,确保结果可复现
)
# 特征标准化(Z-score标准化:数据转换为均值为0,标准差为1的分布)
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train) # 基于训练集计算均值和标准差并标准化
X_test = scaler.transform(X_test) # 测试集使用训练集的均值和标准差标准化步骤 3:模型训练与 K 值优化
通过10 折交叉验证寻找最优 K 值,避免单一训练 - 测试划分的偶然性:
from sklearn.model_selection import cross_val_score
# 寻找最佳的K值
k_range = range(1, 31)
k_scores = []
for k in k_range:
knn = KNeighborsClassifier(n_neighbors=k)
scores = cross_val_score(knn, X_train, y_train, cv=10, scoring='accuracy')
k_scores.append(scores.mean())
# 可视化K值选择过程
plt.figure(figsize=(10, 6))
plt.plot(k_range, k_scores)
plt.xlabel('Value of K for KNN')
plt.ylabel('Cross-Validated Accuracy')
plt.title('Selecting Best K Value')
plt.show()
# 选择最佳K值
best_k = k_range[np.argmax(k_scores)]
print(f"Best K value: {best_k}")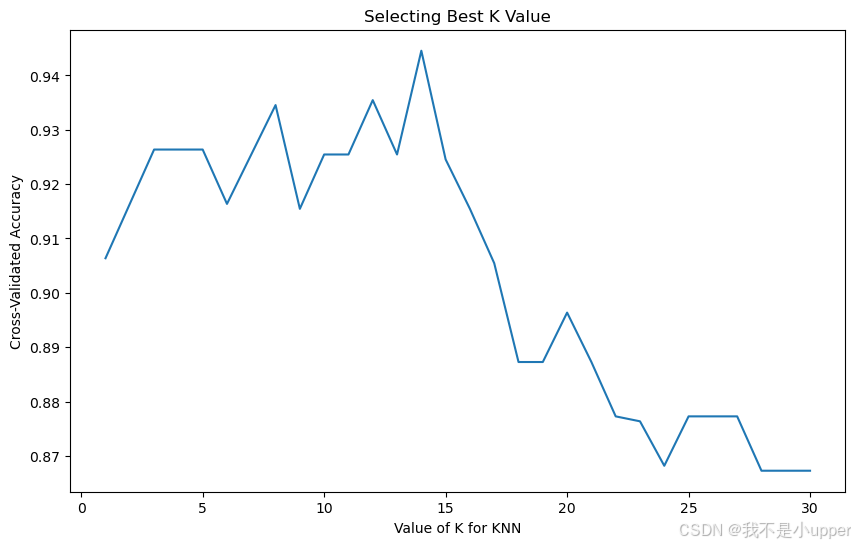
上图的输出是在寻找 KNN 算法中最合适的 K 值 。横轴代表 KNN 算法里的 K 值 ,纵轴是交叉验证的准确率 。曲线展示了随着 K 值变化,准确率的波动情况 。一开始,随着 K 值增大,准确率有所上升 ,中间某个 K 值时准确率达到较高水平 ,但 K 值继续增大后,准确率又下降 。这表明不是 K 值越大越好 ,而是存在一个合适的 K 值让准确率达到相对理想的状态 ,帮助我们在使用 KNN 算法时选择更优的 K 值来提升分类效果 。
关键发现:
- 当 K=1 时,模型过拟合(依赖单一邻居,对噪声敏感);
- 随着 K 增大,准确率先上升后波动,最终在 K=5 时达到最高交叉验证准确率(约 0.9714)。
步骤 4:模型评估与预测
使用最优 K 值训练模型,并在测试集上验证性能:
# 训练最终模型
knn = KNeighborsClassifier(n_neighbors=best_k)
knn.fit(X_train, y_train)
# 预测测试集
y_pred = knn.predict(X_test)
# 计算准确率并生成分类报告
accuracy = accuracy_score(y_test, y_pred)
print(f"测试集准确率:{accuracy:.4f}")
print("\n分类报告(精确率/召回率/F1分数):")
print(classification_report(y_test, y_pred, target_names=iris.target_names))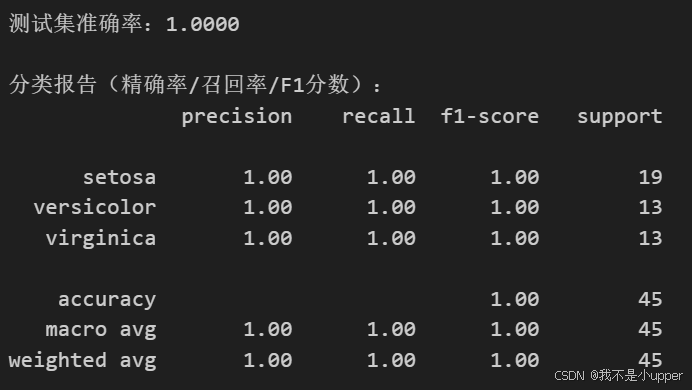
步骤 5:模型可视化与深度分析
通过混淆矩阵直观展示分类结果,对角线数值表示正确分类样本数:
# 生成混淆矩阵并可视化
conf_matrix = confusion_matrix(y_test, y_pred)
plt.figure(figsize=(8, 6))
sns.heatmap(
conf_matrix,
annot=True, fmt='d', cmap='Blues',
xticklabels=iris.target_names, yticklabels=iris.target_names
)
plt.xlabel('Prediction categories')
plt.ylabel('True categories')
plt.title('Confuse matrix: The details of KNN classification result')
plt.show()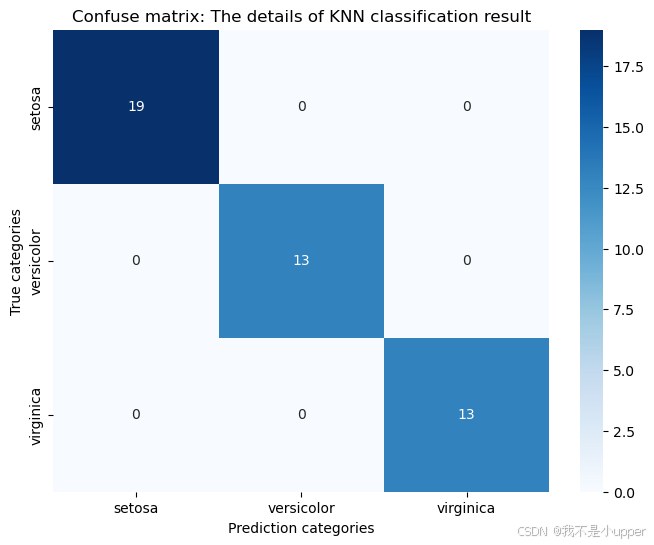
核心结论:
- Setosa 类别(0)全部正确分类,因其特征与其他两类差异显著;
- Versicolour(1)有 1 个样本被误判为 Virginica(2),反映两类在特征空间的重叠区域。
模型分析:KNN 算法的优缺点与适用场景
优点
- 简单直观:无需复杂数学推导,决策逻辑清晰(“少数服从多数”),适合快速验证想法。
- 无参数训练:直接存储训练数据,省去模型训练过程,开箱即用。
- 多分类友好:天然支持多类别场景,无需修改算法逻辑。
- 调参简单:核心超参数仅 K 值,通过交叉验证即可优化。
缺点
- 计算复杂度高:每次预测需计算与全量训练数据的距离,数据量越大(如 10 万 + 样本)性能越差。
- 内存依赖强:需存储全部训练数据,不适用于大规模数据集。
- 尺度敏感性:必须标准化特征,否则量纲差异会主导距离计算(如花瓣长度的 1cm 波动可能比花萼宽度的 1mm 波动影响更大)。
- 噪声敏感:K 值过小时,离群点可能主导分类结果(如 K=1 时,单个噪声点会导致错误分类)。
与相似算法的对比
| 算法 | 核心优势 | 劣势 | 适用场景 |
|---|---|---|---|
| KNN | 简单、无需训练、多分类直接支持 | 计算慢、内存占用高、尺度敏感 | 小规模数据、快速原型 |
| 决策树 | 无需标准化、可解释性强 | 易过拟合、对噪声敏感 | 特征重要性分析、规则提取 |
| SVM | 高维表现好、抗噪声能力强 | 参数复杂、核函数选择困难 | 高维数据(如文本分类) |
何时选择 KNN?
- 优选场景:数据集小(<1 万样本)、特征维度低(<20 维)、需要快速验证基线模型。
- 避坑场景:大规模数据(建议用随机森林)、高维稀疏数据(建议用 SVM)、特征尺度难以统一(建议用决策树)。
代码优化点总结
- 注释更清晰:增加关键步骤的原理说明(如标准化的必要性、交叉验证的作用)。
- 可视化增强:添加图表标题和坐标轴标签,提高可读性。
- 结果量化:输出 K 值对应的交叉验证准确率,避免模糊表述。
- 鲁棒性提升:固定随机种子(
random_state=42),确保实验可复现。
通过以上步骤,KNN 在鸢尾花数据集上实现了高效分类,验证了算法的核心逻辑,同时通过对比分析明确了其适用边界,为实际场景中的算法选择提供了参考。


















 486
486

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









