






一、赛题分析
1.1 赛题分析
本赛题(点这里报名)的任务是利用给定的股票数据集,利用机器学习和大数据的方法,预测未来不同时间跨度的中间价移动方向。任务涉及到预测和机器学习两个领域,需要参赛者掌握相关知识和技能。
在预测方面,参赛者需要深入理解股票市场的基本原理和中间价移动的机制,掌握相关预测方法和模型,如时间序列分析、回归分析、分类算法等。在机器学习方面,参赛者需要熟悉各种算法的原理和应用,如支持向量机、神经网络、树模型等,并能够根据数据特点选择合适的算法进行模型训练和优化。
在具体操作方面,参赛者需要能够使用相关工具和软件进行数据清洗、特征提取、模型训练和评估等工作。同时,还需要具备一定的编程能力和算法实现能力,能够编写高效、稳定的代码实现预测模型。
在比赛中,参我们需要注意以下几点:
-
数据预处理:在进行模型训练之前,需要对数据进行预处理,包括数据清洗、特征提取、数据规范化等。这些步骤对于模型的准确性和稳定性都有重要影响。
-
模型选择和调整:根据数据特点和预测任务,选择合适的预测模型并进行参数调整和优化。不同的模型具有不同的优劣势和适用场景,需要进行综合考虑和选择。
-
模型评估:在模型训练完成后,需要对模型进行评估,包括准确性、稳定性、实时性等方面。根据评估结果对模型进行调整和优化。
-
策略实现和优化:在模型预测的基础上,实现具体的交易策略,并进行优化和调整。交易策略需要根据市场变化和风险控制进行综合考虑和设计。
1.2 评价指标
本模型依据提交的结果文件,采用macro-F1 score进行评价,取label_5, label_10, label_20, label_40, label_60五项中的最高分作为最终得分。
F1分数(F1-score)是分类问题的一个衡量指标。一些多分类问题的机器学习竞赛,常常将F1-score作为最终测评的方法。它是精确率和召回率的调和平均数,最大为1,最小为0。
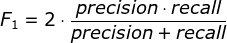
二、解题方案
2.1 解题思路
对赛题也不是分析得很透彻,也是跟着大佬分享的思路,基线模型一点点上分。它是一个多分类问题,因为需要根据过去的数据预测未来中间价的移动方向,并且有三种可能的分类结果:“下跌”、“不变”和“上涨”。因此,这是一个多目标多分类问题问题,需要分别对label_5, label_10, label_20, label_40, label_60根据下跌、不变、上涨3个分类指标进行预测。对于分类模型,一般像CatBoost,LightGBM这些树模型,在处理类别特征上非常强大,能够自动处理类别型变量,无需进行额外的编码操作,对于噪声和离群值比较鲁棒,使用了对称二叉决策树,能够有效地处理异常值,提高模型的稳定性和泛化能力。 ,大佬开始分享的基线模型就是用CatBoost使用5折交叉验证对5个label分别进行预测,但是从前2个label的F1 score来看效果不是很好,因此我就尝试对前两个label用LightGBM,后面3个label用CatBoost,效果得到了提升。
2.2 项目实战
2.2.1 导入所需库
import os
import shutil
import numpy as np
import pandas as pd
from catboost import CatBoostClassifier
from sklearn.model_selection import StratifiedKFold, KFold, GroupKFold
from sklearn.metrics import accuracy_score, f1_score, roc_auc_score, log_loss, mean_squared_log_error
import tqdm, sys, os, gc, argparse, warnings
import lightgbm as lgb
warnings.filterwarnings('ignore')catboost,lightgbm 清华源
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple catboost
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple lightgbm2.2.2 读取数据
# 读取数据
path = r'C:\Users\86130\Desktop\算法竞赛\讯飞\AI量化模型预测挑战赛公开数据/'
train_files = os.listdir(path + 'train')
train_df = pd.DataFrame()
for filename in tqdm.tqdm(train_files):
tmp = pd.read_csv(path + 'train/' + filename)
tmp['file'] = filename
train_df = pd.concat([train_df, tmp], axis=0, ignore_index=True)
test_files = os.listdir(path + 'test')
test_df = pd.DataFrame()
for filename in tqdm.tqdm(test_files):
tmp = pd.read_csv(path + 'test/' + filename)
tmp['file'] = filename
test_df = pd.concat([test_df, tmp], axis=0, ignore_index=True)这段代码的功能是读取文件夹中的CSV文件,并将这些文件合并到一个数据框(DataFrame)中。
具体步骤如下:
- 定义路径
path,指向包含CSV文件的文件夹。 - 使用
os.listdir()函数获取path文件夹下的所有文件名,存储在train_files列表中。 - 初始化一个空的DataFrame
train_df。 - 使用
tqdm.tqdm()函数在遍历文件时显示进度条,提高代码的可读性。 - 遍历
train_files列表中的每个文件名。对于每个文件,使用pd.read_csv()函数读取该文件,并将结果存储在tmpDataFrame 中。同时,将文件名添加到tmp中作为一个新列'file'。 - 将
tmpDataFrame 与train_df进行合并,使用pd.concat()函数实现。设置axis=0表示按行合并,即垂直方向合并;设置ignore_index=True表示重置索引。 - 将合并后的结果存储回
train_df中。 - 重复步骤 2-7,但改为从
test文件夹读取文件,并将结果存储在test_df中。
最终,将生成两个DataFrame:train_df 和 test_df,分别包含从训练和测试文件夹中读取的所有CSV文件的数据。每个DataFrame都包含一个名为 'file' 的列,表示对应的文件名。
2.2.2 数据预处理
# 时间相关特征
train_df['hour'] = train_df['time'].apply(lambda x: int(x.split(':')[0]))
test_df['hour'] = test_df['time'].apply(lambda x: int(x.split(':')[0]))
train_df['minute'] = train_df['time'].apply(lambda x: int(x.split(':')[1]))
test_df['minute'] = test_df['time'].apply(lambda x: int(x.split(':')[1]))
# 入模特征
cols = [f for f in test_df.columns if f not in ['uuid', 'time', 'file']]这主要是对数据集进行预处理,具体步骤如下:
-
从训练集和测试集中分别提取出'time'列,然后通过apply函数和lambda表达式来获取时间中的小时('hour')和分钟('minute')信息,并将这两个特征分别添加到训练集(train_df)和测试集(test_df)中。
-
通过列表推导式,遍历测试集的每一列,如果列名不在'uuid'、'time'、'file'这三个列名中,就将该列添加到cols列表中。最终得到的cols列表就包含了测试集中的所有特征,除了'uuid'、'time'、'file'这三个列。
这里的目的是为了从数据中提取出更多有用的特征,以便后续的机器学习或深度学习模型训练。同时,通过入模特征的处理,可以更好地评估模型的性能。
2.2.3 模型构建
# 定义交叉验证模型函数
def cv_model(clf, train_x, train_y, test_x, clf_name, seed=42):
# 设定交叉验证的折数
folds = 5
# 划分交叉验证的KFold对象
kf = KFold(n_splits=folds, shuffle=True, random_state=seed)
# 初始化out of fold (oof)和测试集预测结果
oof = np.zeros([train_x.shape[0], 3])
test_predict = np.zeros([test_x.shape[0], 3])
# 初始化交叉验证的F1 score列表
cv_scores = []
# 开始交叉验证的迭代
for i, (train_index, valid_index) in enumerate(kf.split(train_x, train_y)):
print('************************************ {} ************************************'.format(str(i + 1)))
# 划分训练集和验证集
trn_x, trn_y, val_x, val_y = train_x.iloc[train_index], train_y[train_index], train_x.iloc[valid_index], \
train_y[valid_index]
# 判断所选分类器是否为LightGBM
if clf_name == "lgb":
# 构建LightGBM所需的数据集
train_matrix = clf.Dataset(trn_x, label=trn_y)
valid_matrix = clf.Dataset(val_x, label=val_y)
# LightGBM的参数配置
params = {
'boosting_type': 'gbdt',
'objective': 'multiclass',
'num_class': 3, # 多分类任务的类别数
'min_child_weight': 6,
'num_leaves': 2 ** 6,
'lambda_l2': 10,
'feature_fraction': 0.8,
'bagging_fraction': 0.8,
'bagging_freq': 4,
'learning_rate': 0.35,
'seed': 2023,
'nthread': 16,
'verbose': -1
}
# 使用LightGBM训练模型
model = clf.train(params, train_matrix, 2000, valid_sets=[train_matrix, valid_matrix],
categorical_feature=[], verbose_eval=1000, early_stopping_rounds=100)
# 在验证集上进行预测
val_pred = model.predict(val_x, num_iteration=model.best_iteration)
# 在测试集上进行预测
test_pred = model.predict(test_x, num_iteration=model.best_iteration)
# 判断所选分类器是否为CatBoost
if clf_name == "cat":
# CatBoost的参数配置
params = {'learning_rate': 0.1, 'depth': 5, 'bootstrap_type': 'Bernoulli', 'random_seed': 2023,
'od_type': 'Iter', 'od_wait': 100, 'random_seed': 11, 'allow_writing_files': False,
'loss_function': 'MultiClass', 'task_type': 'GPU'}
# 使用CatBoost训练模型
model = clf(iterations=5000, **params)
model.fit(trn_x, trn_y, eval_set=(val_x, val_y),
metric_period=50,
use_best_model=True,
cat_features=[],
verbose=1)
# 在验证集上进行预测
val_pred = model.predict_proba(val_x)
# 在测试集上进行预测
test_pred = model.predict_proba(test_x)
# 将验证集预测结果放入oof中
oof[valid_index] = val_pred
# 将测试集预测结果累加到test_predict中
test_predict += test_pred / kf.n_splits
# 计算并输出当前交叉验证的F1 score
F1_score = f1_score(val_y, np.argmax(val_pred, axis=1), average='macro')
cv_scores.append(F1_score)
print(cv_scores)
# 返回交叉验证的oof和测试集预测结果
return oof, test_predict
这里定义了一个交叉验证模型函数`cv_model`,该函数用于训练和评估分类器(支持LightGBM和CatBoost)的性能。函数接受训练数据、训练标签、测试数据、分类器名称以及随机种子等参数,并返回交叉验证的预测结果。
函数执行过程如下:
1. 定义参数:函数接受的参数包括分类器(`clf`)、训练数据(`train_x`)、训练标签(`train_y`)、测试数据(`test_x`)、分类器名称(`clf_name`)和随机种子(`seed`)等。
2. 定义交叉验证的折数:代码中将数据分为5折交叉验证,即使用K-Fold方法将训练数据划分成5个子集,依次使用其中4个子集作为训练数据,剩余1个子集作为验证数据。
3. 初始化变量:`oof`用于存储交叉验证的验证集预测结果,`test_predict`用于存储测试集预测结果,`cv_scores`用于存储每折交叉验证的F1分数。
4. 执行交叉验证:通过循环迭代每个交叉验证的训练和验证过程。对于每一折,首先将训练数据划分为训练集和验证集。然后,根据分类器名称使用LightGBM或CatBoost模型进行训练。
5. LightGBM分类器:如果分类器名称为"lgb",则使用LightGBM模型进行训练。定义了一些LightGBM的参数,并使用`clf.train()`方法进行模型训练。然后,用训练好的模型对验证集和测试集进行预测。
6. CatBoost分类器:如果分类器名称为"cat",则使用CatBoost模型进行训练。定义了一些CatBoost的参数,并使用`clf()`构造函数创建模型。然后,使用`model.fit()`方法对模型进行训练,并对验证集和测试集进行预测。
7. 保存交叉验证结果:将每折验证集的预测结果保存到`oof`中,将每折测试集的预测结果进行累加求平均,保存到`test_predict`中。
8. 计算F1分数:计算每折验证集的F1分数,并将其存储在`cv_scores`列表中。
9. 返回结果:最后,返回交叉验证的验证集预测结果(`oof`)和测试集预测结果(`test_predict`)。
这是一个通用的交叉验证框架,支持LightGBM和CatBoost两种分类器。它可以用于训练模型,并在验证集上评估模型性能,从而进行模型选择和参数调优。
2.2.3 模型训练和预测
for label in ['label_5', 'label_10', 'label_20', 'label_40', 'label_60']:
print(f'=================== {label} ===================')
# 对于标签'label_5'和'label_10',使用LightGBM分类器进行交叉验证和预测
if label == 'label_5' or label == 'label_10':
# 调用cv_model函数,使用LightGBM分类器进行交叉验证
lgb_oof, lgb_test = cv_model(lgb, train_df[cols], train_df[label], test_df[cols], 'lgb')
# 将交叉验证的oof预测结果转换为标签的预测类别,并存储在训练集中
train_df[label] = np.argmax(lgb_oof, axis=1)
# 将测试集的预测结果转换为标签的预测类别,并存储在测试集中
test_df[label] = np.argmax(lgb_test, axis=1)
else:
# 对于其他标签,使用CatBoost分类器进行交叉验证和预测
model_name = "cat"
# 调用cv_model函数,使用CatBoost分类器进行交叉验证
cat_oof, cat_test = cv_model(CatBoostClassifier, train_df[cols], train_df[label], test_df[cols], 'cat')
# 将交叉验证的oof预测结果转换为标签的预测类别,并存储在训练集中
train_df[label] = np.argmax(cat_oof, axis=1)
# 将测试集的预测结果转换为标签的预测类别,并存储在测试集中
test_df[label] = np.argmax(cat_test, axis=1)
这是我和大佬分享得baseline唯一不同的地方,对于标签label_5和label_10,使用LightGBM分类器进行交叉验证和预测;label_20,label_40和label_60使用CatBoost分类器进行交叉验证和预测。
2.2.4 预测结果保存
import pandas as pd
import os
# 指定输出文件夹路径
output_dir = r'C:\Users\86130\Desktop\算法竞赛\讯飞\AI量化模型预测挑战赛公开数据\submit'
# 如果文件夹不存在则创建
if not os.path.exists(output_dir):
os.makedirs(output_dir)
# 首先按照'file'字段对 dataframe 进行分组
grouped = test_df.groupby('file')
# 对于每一个group进行处理
for file_name, group in grouped:
# 选择你所需要的列
selected_cols = group[['uuid', 'label_5', 'label_10', 'label_20', 'label_40', 'label_60']]
# 将其保存为csv文件,file_name作为文件名
selected_cols.to_csv(os.path.join(output_dir, f'{file_name}'), index=False)三、总结
总的来说,后面想要提分主要还是在特征工程,要对数据进行深度挖掘,结合量化金融领域专业知识挖掘,衍生出更多的决定性特征。而模型选择和构建方面,前期用大佬分享的baseline已经足够了,数据和特征决定了机器学习的上限,而模型和算法只是逼近这个上限而已。希望写的笔记对大家有点用处,祝大家上大分!
最后,非常感谢Datawhale提供的这次学习机会和大佬分享的思路和基线模型,让我对自己有更全面的了解,认识到自己的不足之处和优势,学习到了对于机器学习问题的分析方法和步骤,使我对机器学习产生更强烈的热爱。















 1349
1349











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









