






模型融合
模型融合是一种通过结合多个模型的结果来提高预测性能和稳定性的方法。模型融合的主要目的是为了提高模型的预测准确性和鲁棒性。通过将多个模型的结果组合在一起,可以降低单个模型的随机性,从而得到更准确的结果。同时,模型融合也可以使得模型在处理复杂问题时更加鲁棒,即能够更好地处理各种不同的情况,提高模型的稳定性。
以下是一些模型融合的方法:
投票法(Voting):
投票法(voting)是集成学习里面针对分类问题的一种结合策略。是一种遵循少数服从多数原则的集成学习模型,通过多个模型的集成降低方差,从而提高模型的 鲁棒性 (算法对数据变化的容忍度有多高)。在理想情况下,投票法的预测效果应当优于任何一个基模型的预测效果。
投票法在回归模型与分类模型上均可使用:
- 回归投票法:预测结果是所有模型预测结果的平均值。
- 分类投票法:预测结果是所有模型种出现最多的预测结果。
分类投票法投票机制:
硬投票:所有投票结果出现最多的类
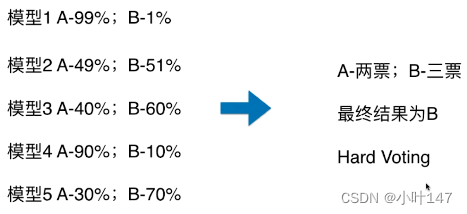
软投票:所有投票结果中概率和平均最大的类

平均法(Averaging):
在回归问题中,每个模型都会对输入样本进行预测,最终的结果是所有模型的预测值的平均值。
def cv_model(clf, train_x, train_y, test_x, clf_name, seed = 2023):
folds = 5
kf = KFold(n_splits=folds, shuffle=True, random_state=seed)
oof = np.zeros([train_x.shape[0], 3])
test_predict = np.zeros([test_x.shape[0], 3])
cv_scores = []
for i, (train_index, valid_index) in enumerate(kf.split(train_x, train_y)):
print('************************************ {} ************************************'.format(str(i+1)))
trn_x, trn_y, val_x, val_y = train_x.iloc[train_index], train_y[train_index], train_x.iloc[valid_index], train_y[valid_index]
if clf_name == "lgb":
train_matrix = clf.Dataset(trn_x, label=trn_y)
valid_matrix = clf.Dataset(val_x, label=val_y)
params = {
'boosting_type': 'gbdt',
'objective': 'multiclass',
'num_class':3,
'min_child_weight': 6,
'num_leaves': 2 ** 6,
'lambda_l2': 10,
'feature_fraction': 0.8,
'bagging_fraction': 0.8,
'bagging_freq': 4,
'learning_rate': 0.35,
'seed': 2023,
'nthread' : 16,
'verbose' : -1,
}
model = clf.train(params, train_matrix, 2000, valid_sets=[train_matrix, valid_matrix],
categorical_feature=[], verbose_eval=1000, early_stopping_rounds=100)
val_pred = model.predict(val_x, num_iteration=model.best_iteration)
test_pred = model.predict(test_x, num_iteration=model.best_iteration)
if clf_name == "xgb":
xgb_params = {
'booster': 'gbtree',
'objective': 'multi:softprob',
'num_class':3,
'max_depth': 5,
'lambda': 10,
'subsample': 0.7,
'colsample_bytree': 0.7,
'colsample_bylevel': 0.7,
'eta': 0.35,
'tree_method': 'hist',
'seed': 520,
'nthread': 16
}
train_matrix = clf.DMatrix(trn_x , label=trn_y)
valid_matrix = clf.DMatrix(val_x , label=val_y)
test_matrix = clf.DMatrix(test_x)
watchlist = [(train_matrix, 'train'),(valid_matrix, 'eval')]
model = clf.train(xgb_params, train_matrix, num_boost_round=2000, evals=watchlist, verbose_eval=1000, early_stopping_rounds=100)
val_pred = model.predict(valid_matrix)
test_pred = model.predict(test_matrix)
if clf_name == "cat":
params = {'learning_rate': 0.35, 'depth': 5, 'bootstrap_type':'Bernoulli','random_seed':2023,
'od_type': 'Iter', 'od_wait': 100, 'random_seed': 11, 'allow_writing_files': False,
'loss_function': 'MultiClass'}
model = clf(iterations=2000, **params)
model.fit(trn_x, trn_y, eval_set=(val_x, val_y),
metric_period=1000,
use_best_model=True,
cat_features=[],
verbose=1)
val_pred = model.predict_proba(val_x)
test_pred = model.predict_proba(test_x)
oof[valid_index] = val_pred
test_predict += test_pred / kf.n_splits
F1_score = f1_score(val_y, np.argmax(val_pred, axis=1), average='macro')
cv_scores.append(F1_score)
print(cv_scores)
return oof, test_predict
# 参考demo,具体对照baseline实践部分调用cv_model函数
# 选择lightgbm模型
lgb_oof, lgb_test = cv_model(lgb, train_df[cols], train_df['label'], test_df[cols], 'lgb')
# 选择xgboost模型
xgb_oof, xgb_test = cv_model(xgb, train_df[cols], train_df['label'], test_df[cols], 'xgb')
# 选择catboost模型
cat_oof, cat_test = cv_model(CatBoostClassifier, train_df[cols], train_df['label'], test_df[cols], 'cat')
# 进行取平均融合
final_test = (lgb_test + xgb_test + cat_test) / 3Baseline中使用了三种不同的机器学习模型:LightGBM、XGBoost和CatBoost。这些模型在训练和测试数据上进行交叉验证,然后对测试集的预测结果进行融合。具体的融合方法是简单的平均。也就是将三个模型的预测结果取平均值,得到最终的预测结果。这种方法的好处在于,如果不同模型的预测结果存在差异,那么通过取平均值可以降低单个模型预测结果的偏差。然而,这种方法也有其局限性。如果某个模型的预测结果明显偏离其他模型,那么这可能会降低融合结果的准确性。值得注意的是,这个融合方法假设所有模型都在相同的特征空间中进行预测,且它们的预测结果是等权的。如果这些假设不成立,那么可能需要使用更复杂的融合方法,例如加权平均或者Stacking。
堆叠法(Stacking):
这是一种用于分类问题的模型融合方法,其中多个模型被训练以预测另一个模型的输入。在这种方法中,原始的输入数据被用于训练第一层模型(基模型),然后第一层模型的输出被用作第二层模型的输入,以此类推。
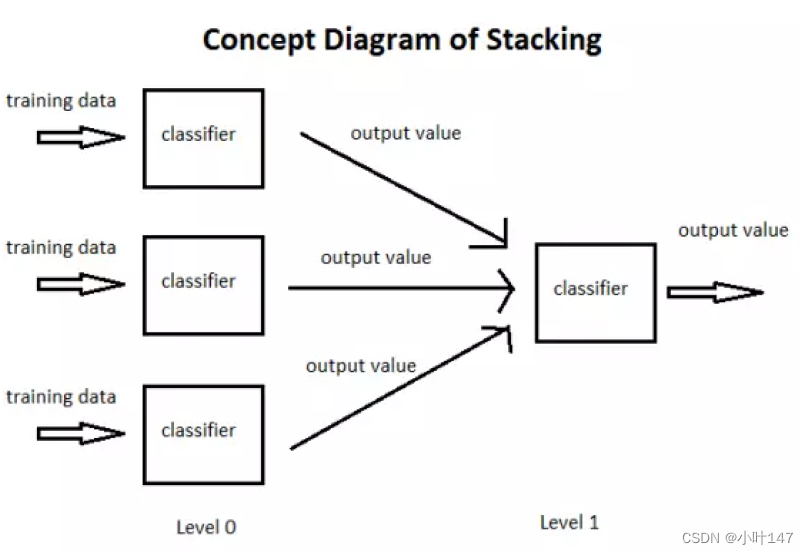
Stacking的两种思想
第一种思想:
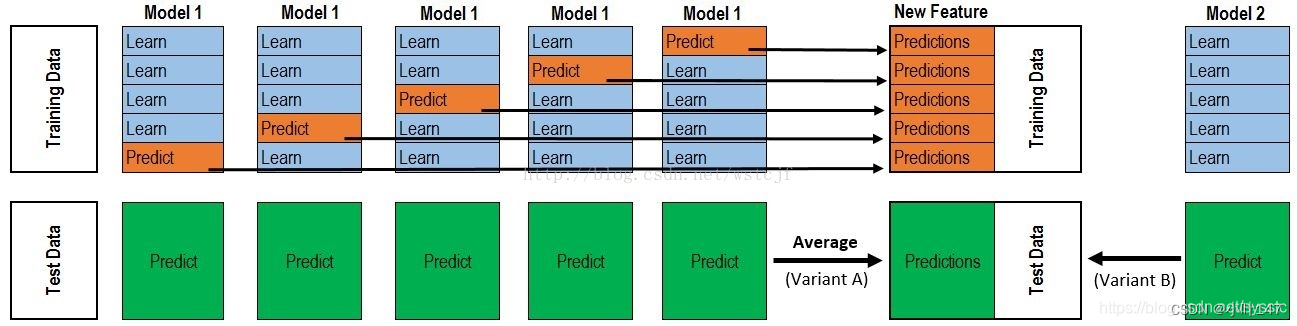
假设有12000条数据样本,将样本集分为训练集(training data)10000条和测试集(testing data)2000条。
第一层: 采用4个模型(假设其分别是RF、ET、GBDT、XGB),分别对训练集进行训练,然后将预测的结果作为下一层的输入。
Step1:将训练集分为5折
1. 分别用第2、3、4、5折训练一个RF,用训练好的RF直接预测第1折训练数据;
2. 分别用第1、3、4、5折训练一个新的RF,用训练好的RF直接预测第2折训练数据;
3. 分别用第1、2、4、5折训练一个新的RF,用训练好的RF直接预测第3折训练数据;
4. 分别用第1、2、3、5折训练一个新的RF,用训练好的RF直接预测第4折训练数据;
5. 分别用第1、2、3、4折训练一个新的RF,用训练好的RF直接预测第5折训练数据;
训练后,可以得到100001维的RF对training data的预测结果,对于testing data,用上面训练得到的5个RF,预测出20005维的预测结果,然后对其取平均,20001维的RF预测结果。
Step2:另外3个模型同理。
最终第一层中,training data会输出100004维的预测结果,将这个结果作为第二层训练集的输入。testing data 会输出2000*4维的结果,将这个结果作为第二层预测集的输入。
第二层: 将上一层的结果带入新的模型中,进行训练再预测,第二层的模型一般为了防止过拟合会采用简单的模型。
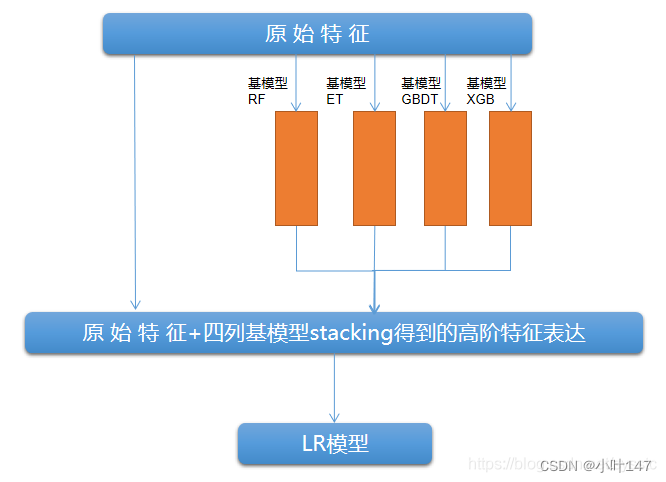
第二种思想: 第二层的输入数据,除了第一层的训练结果外,还包括了原始特征。
模型融合的主要目的是为了提高模型的预测准确性和鲁棒性。通过将多个模型的预测结果进行融合,可以综合利用不同模型的优点,相互弥补缺点,从而达到更好的预测效果。此外,模型融合也可以降低单个模型的随机性,提高模型的稳定性和可靠性。另外,模型融合还可以利用不同数据来源或不同算法的优点,使得模型能够更好地处理各种不同的情况,提高模型的适应性和泛化能力。总之,模型融合的目的是为了提高模型的预测准确性和鲁棒性,从而更好地解决实际问题。
参考链接:
机器学习(中)-投票法原理+思路+案例_集成学习 投票法_꧁ᝰ苏苏ᝰ꧂的博客-CSDN博客
机器学习之模型融合(详解Stacking,Blending)_异构模型融合_R3的博客-CSDN博客
数据挖掘终篇!一文学习模型融合!从加权融合到stacking, boosting_Datawhale的博客-CSDN博客
















 2998
2998











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









