






一、引言
随着深度学习技术的不断发展,目标检测算法在众多领域得到了广泛应用。Yolov4作为一种高效的目标检测算法,具有速度快、精度高等优点,因此备受关注。本文将介绍如何使用Yolov4训练自己标注的数据集,并对测试图片进行结果检测展示。
二、数据集准备
1.数据集标注
首先,我们需要准备一个包含目标物体的数据集,并使用标注工具(如LabelImg)对图片中的目标进行标注。但是数据集需要自己找(可以是各种类型的图片),然后放进图1,标注过程中,需要为每个目标物体绘制边界框,并为其指定类别标签。标注完成后,将生成XML格式的标注文件,如图3所示。


2.数据集格式转换
Yolov4需要TXT格式的标注文件进行训练。因此,我们需要将XML格式的标注文件转换为TXT格式。转换过程中,需要提取每个目标物体的边界框坐标、类别标签等信息,并按照Yolov4要求的格式进行保存。
3.处理数据集
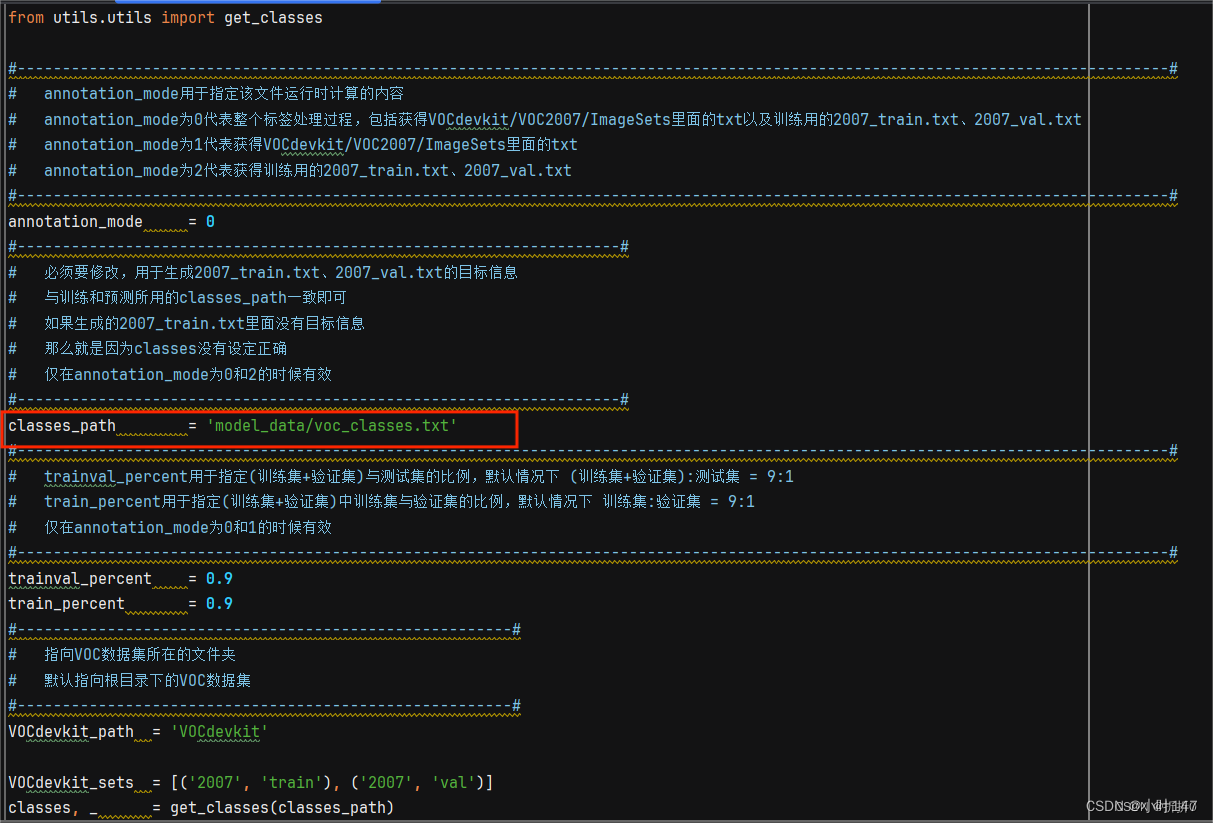
1)voc_annotation.py里面有一些参数需要设置,分别是annotation_mode、classes_path、trainval_percent、train_percent、VOCdevkit_path,第一次训练可以仅修改classes_path,如图6
2)classes_path用于指向检测类别所对应的txt,训练自己的数据集时,可以自己建立一个xxxxxx.txt(你自己想要的名字都可以),里面写自己所需要区分的类别。以我的数据集为例,我还是用voc_classes.txt:
就是想要检测的类别是什么就写什么,但要和数据集的类别一致,比如数据集的类别是动物的,voc_classes.txt里写类别是植物的,这样肯定是不合理的。
三、Yolov4模型训练
1.环境搭建
在开始训练之前,我们需要安装必要的深度学习框架(如PyTorch或TensorFlow)和相关依赖库。此外,还需要安装CMake、CUDA和cuDNN等支持GPU加速的工具。
2.模型配置
在PyTorch或TensorFlow框架下搭建Yolov4网络结构,并设置好学习率、优化器(如Adam)以及批次大小等参数。根据数据集的特点,调整模型的输入尺寸和锚点框大小等参数。
3.训练过程
启动训练过程后,模型将按照设定的参数进行迭代训练。通过反向传播计算梯度,并应用梯度下降法更新网络权重。在训练过程中,我们可以采用分阶段训练策略,先训练Backbone部分,然后逐步加入Neck和Head部分进行联合训练。此外,还可以采用余弦退火策略调整学习率,以加快模型收敛速度并提高精度。
4.早停策略与性能评估
在训练过程中,我们需要根据验证集上的性能指标(如mAP)来评估模型的性能。当模型性能不再显著提升时,可以采用早停策略提前终止训练,以避免过拟合。
四、训练数据
1. 运行voc_annotation.py
处理数据集修改了classes_path并对应自己的类别文件就可以直接运行。
这段代码的主要作用是从标注的XML文件中提取出目标检测任务所需的信息,并自动创建相应的训练、验证和测试划分文件,方便进行后续的模型训练和评估工作。
2. 运行train.py
1)这个train.py代码可以改的参数很多,第一次训练的话化繁为简,运行成功了再改进,classes_path参数修改为自己定义好类别的txt文件,跟之前的是需要保持一样的。

我这里展示的训练次数是20次,因为电脑配置问题,300次训练相对来说比较困难,所以我分别跑了50次、20次、10次和5次,输出的最终结果是差不多的,你可以选择性改变训练的次数。如果输出各项指标一直是0就可以直接结束,改进数据集了。
2)训练期间会输出模型性能的统计数据,包括不同类别(dragon fruit 和 snake fruit)的平均精度(AP)和平均精度均值(mAP),以及它们对应的分数阈值(score-threhold)、F1-分数、召回率(recall)和精确率(precision)。
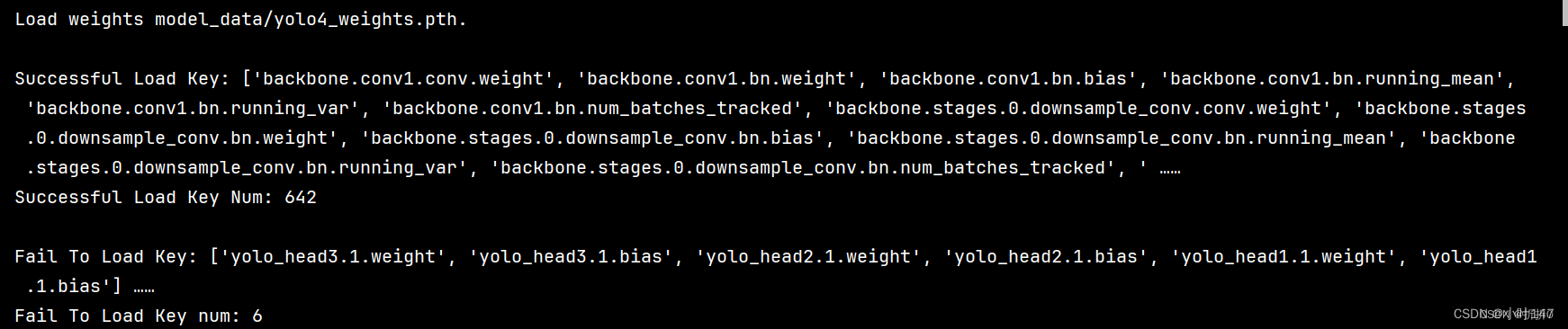


这段代码用于训练Yolo目标检测模型,涉及到了数据准备、数据增强、模型配置、训练流程以及性能评估等关键步骤。训练完的权值文件默认保存在log文件夹下,log文件夹下的best_epoch_weights.pth就是我们训练好的权值文件。
!!注意:train.py文件中有个重要参数,mode_path主干权值文件,一般是使用现成的训练好的权值文件yolo4_weights.pth和yolo4_voc_weights.pth
3. 运行predict.py
训练好我们要用的权值文件以后,先修改yolo.py代码,model_path换成自己训练好的权值文件。

model_path需要根据自己的数据集更改,如果你想要把自己的数据集训练之后的输出结果放进去的话,就需要把这个地方的路径改为你自己想要弄的文件里。如果不改的话,正常情况下输出的结果是存进上图中的路径里。这里的classes_path路径我用coco_classes.txt才能让我不会报错,因为原本的代码里面就是用这个路径,但是我个人建议coco_classes里面的内容要包含你要识别的类别。

图片输入这里的路径改与不改都是可以的,然后用找来的图片来测试训练好的数据集权值文件效果。
Input image filename后面是需要将经过标注的图片路径输入进去,查看训练好的数据集权值文件效果。
!!注意:yolo.py和get_map.py文件也是需要运行的,因为如果不运行的话,一般情况下会导致predict.py文件后面输出有问题,都是需要classes_path。
五、图片结果检测展示
训练完成后,我们可以使用训练好的模型对测试图片进行目标检测。将测试图片输入到模型中,模型将输出每个目标物体的边界框坐标、类别标签以及置信度等信息。我们可以将这些信息可视化到测试图片上,以展示检测结果。
1.图片检测


2.Epoch_Loss损失曲线

3.Epoch_Map 平均精度曲线

由于训练的次数较少,Map的精确度数据相对来说比较平缓,训练次数大概在30次后才会出现比较明显的变化
4.不同类别下的平均精度(mAP)
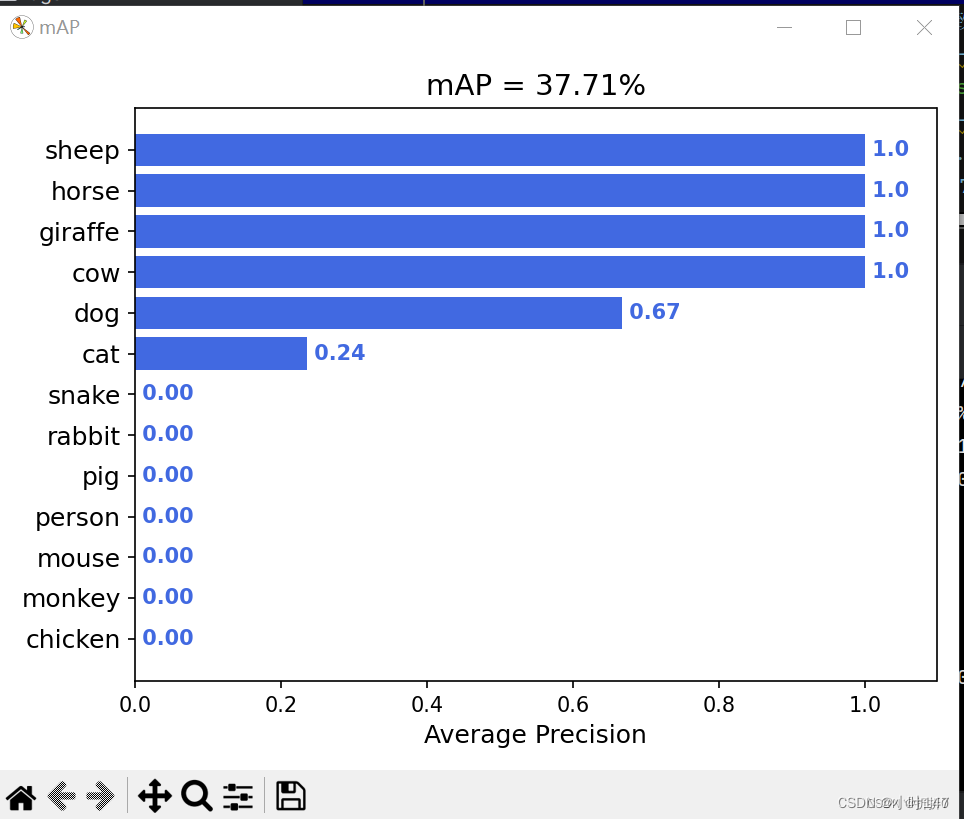
总结:由于类别太多了,而数据集相对来说有点少,以至于不同类别下的平均精度无法识别全部我















 3936
3936

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









