







前言
用Dify建立一个最简单知识库,只用了一份简历。主要是为了充分理解“知识库”的概念。为下一步的应用打好基础。
我觉得知识库的核心就是帮助自动构建了向量数据库,使得模糊的语义查询变得非常方便。
一、创建知识库
1.1、创建知识库
登录Dify,选择“知识库”选项:
点击“创建知识库”
1.2、导入已有文本
点击“下一步”
1.3、知识库的更多细节
更多的细节开始呈现,如下图:
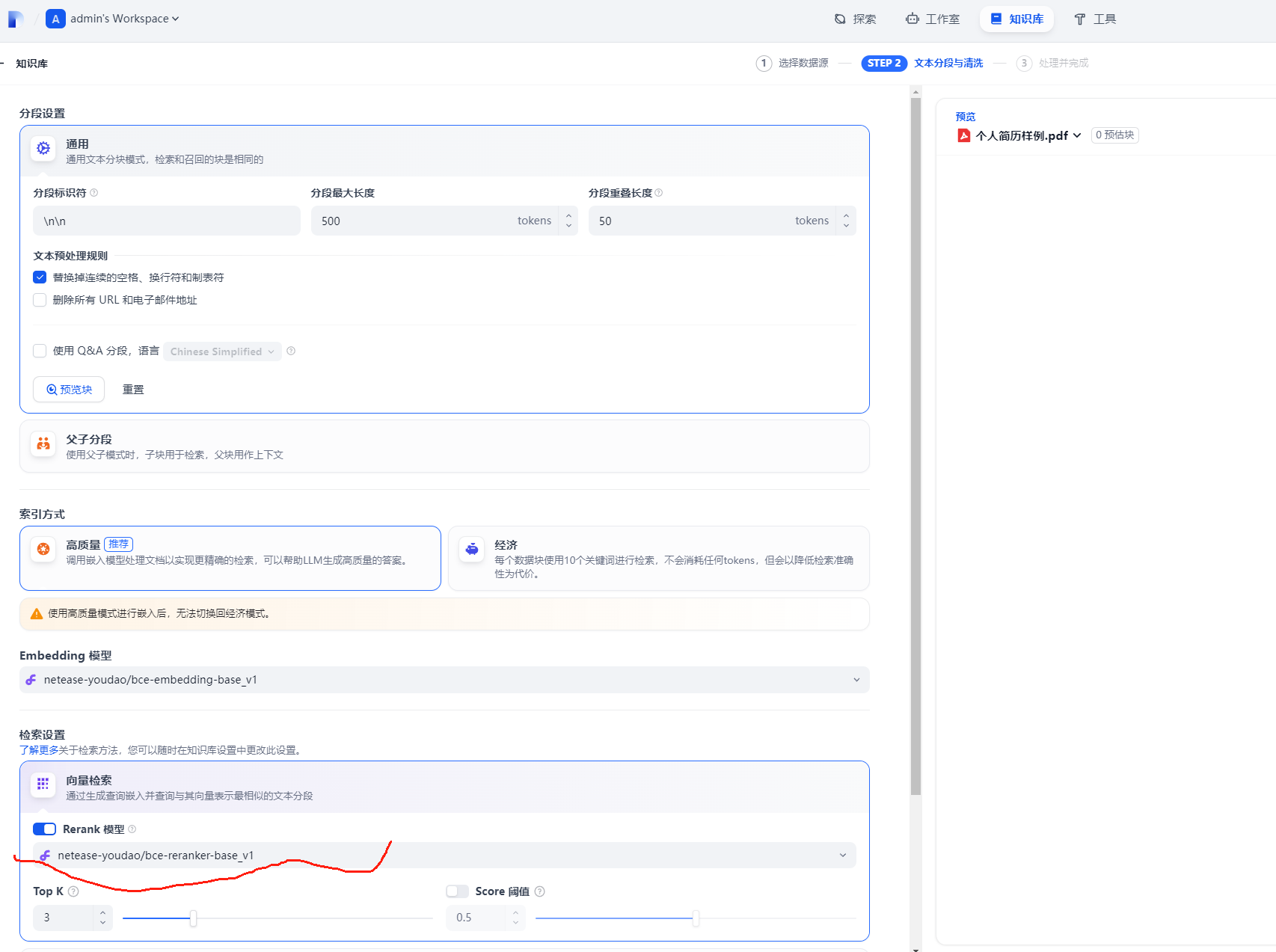
这里有很多的细节参数,我们暂时都采用默认的不作任何的修改。
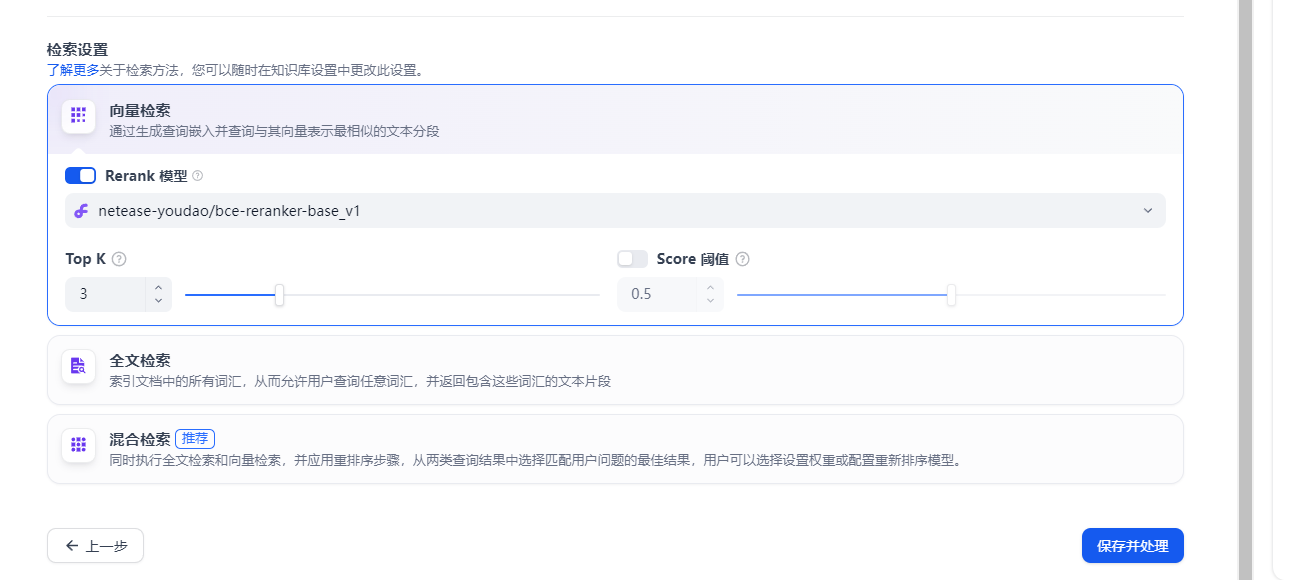
红线所画的是Rerank模型,这个模型应该是“硅基流动”提供的,用来给内容进行打分排序的。(这个后面还会提到的)
继续下拉,可以看到全部的参数,我们点击“保存并处理”,如下图:
1.4、知识库已创建
知识库已经创建,如下图:
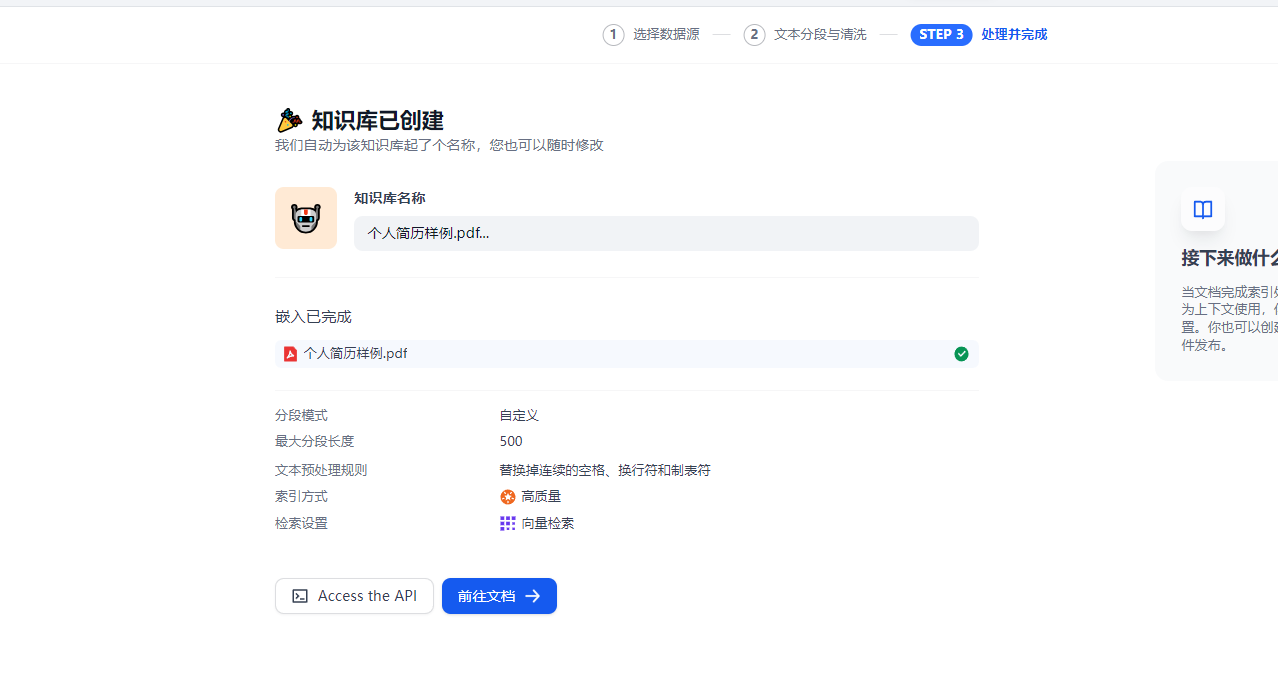
点击“前往文档”,进入下一个页面
二、文档和召回测试
2.1、进入知识库界面
2.2、召回测试
点进“召回测试”
2.3、问题1
进行召回测试,提了一个简单的问题(“这个人在哪些公司工作过?”),如下图:
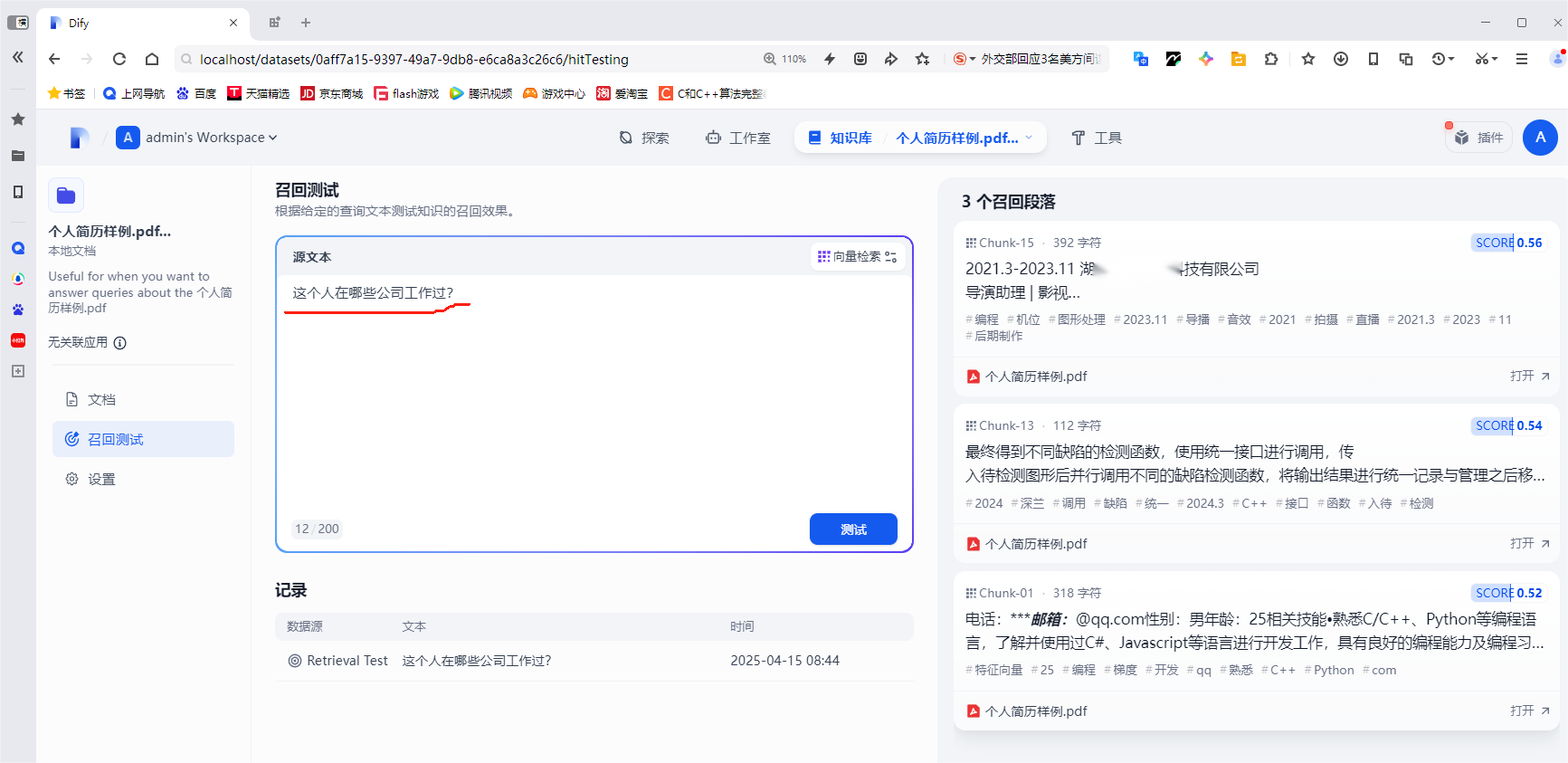
可见匹配还是比较准确的,特别注意右侧的打分
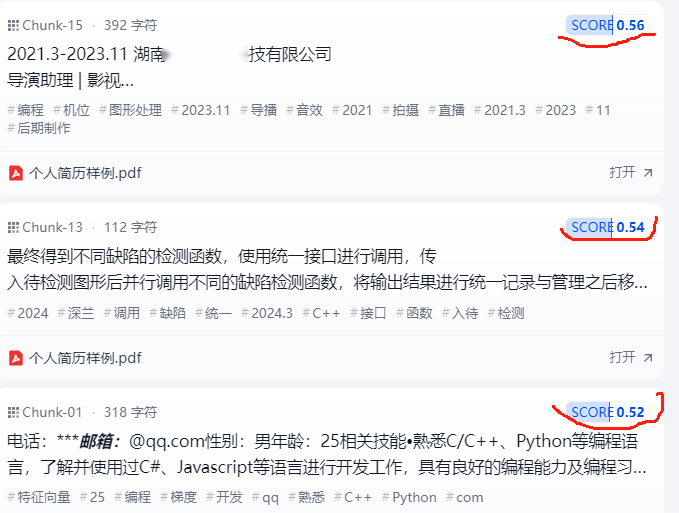
这就是大模型打分给出来的。很显然这是一种很模糊的,基于语义的查询。可以区别sql语句的精确查询。
2.4、问题2
又提了一个的问题,结果如下:

可见准确度依然是很高的,它的打分机制依赖于这一系列关键词。
三、模型设置分析
再看“设置”中的Rerank模型选定:
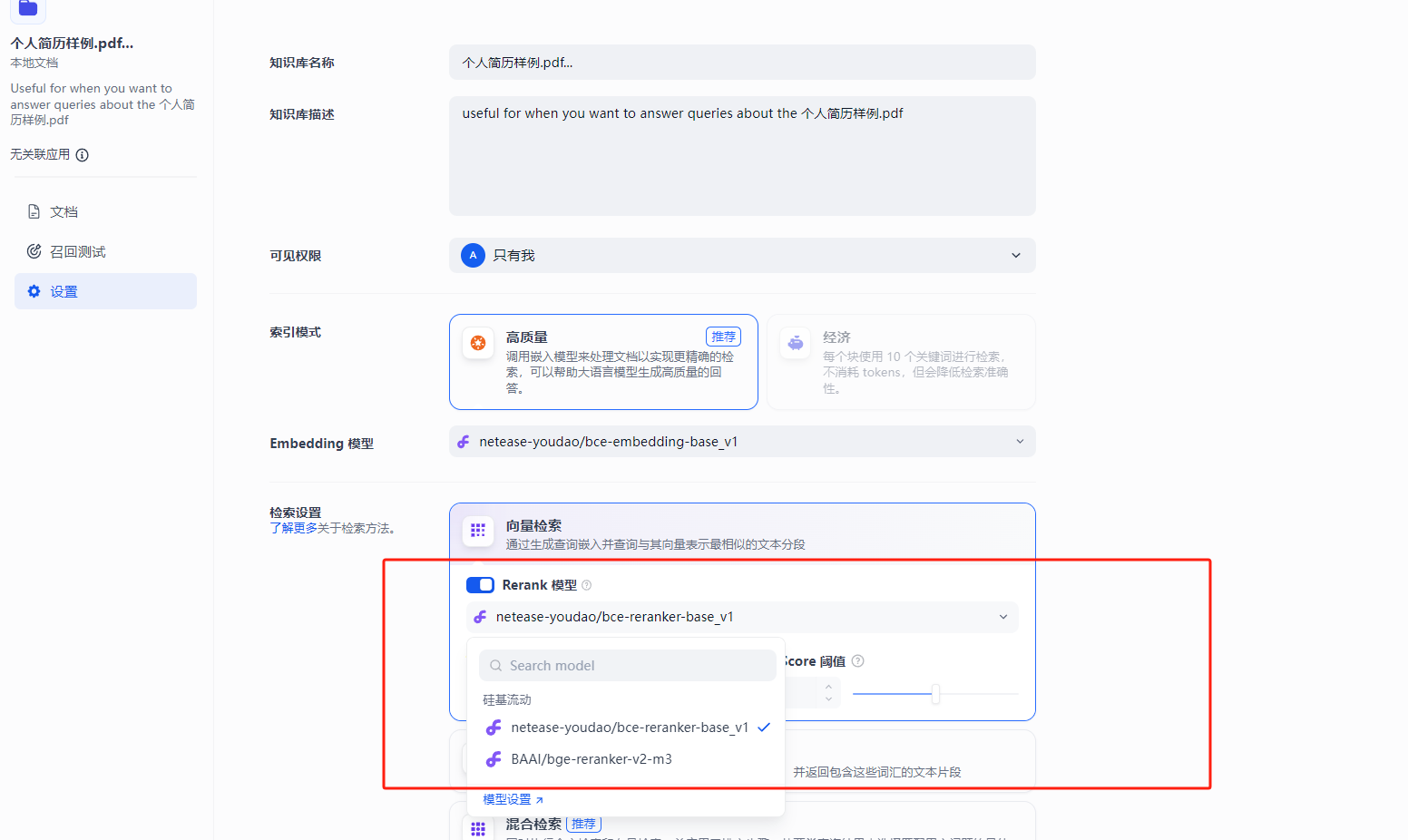
这两个可选模型分别是:
Netease-youdao/bce-reranker-base_v1 (网易有道中英文表征算法bce模型库)
BAAI/bge-reranker-v2-m3 (北京智源人工智能研究院的bge模型)
关于m3e、bge、bce三大知名文本检索向量化模型库的介绍,可以参考博客:
https://blog.csdn.net/hero272285642/article/details/140466752
对Rerank对应的模型的理解非常的关键。实际上本质的来讲,是模糊查询的核心技术,
这里还涉及到向量数据库,这些另外撰文再论述。



















 2313
2313

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











