







内容来自Andrew老师课程Machine Learning的第九章内容的Multivariate Guassian Distribution(Optional)部分。
一、Multivariate Gaussian Distribution
(多元高斯分布)
使用高斯分布图,看一个数据中心的例子:

我们不再单独地将p(x1),p(x2),p(x3)训练模型,而是将这些参数都放在一个模型里,
- 参数:
- 公式:
,其中
表示∑的行列式,在MATLAB/OCTAVE中直接使用det(Sigma)命令即可。其中
,
。
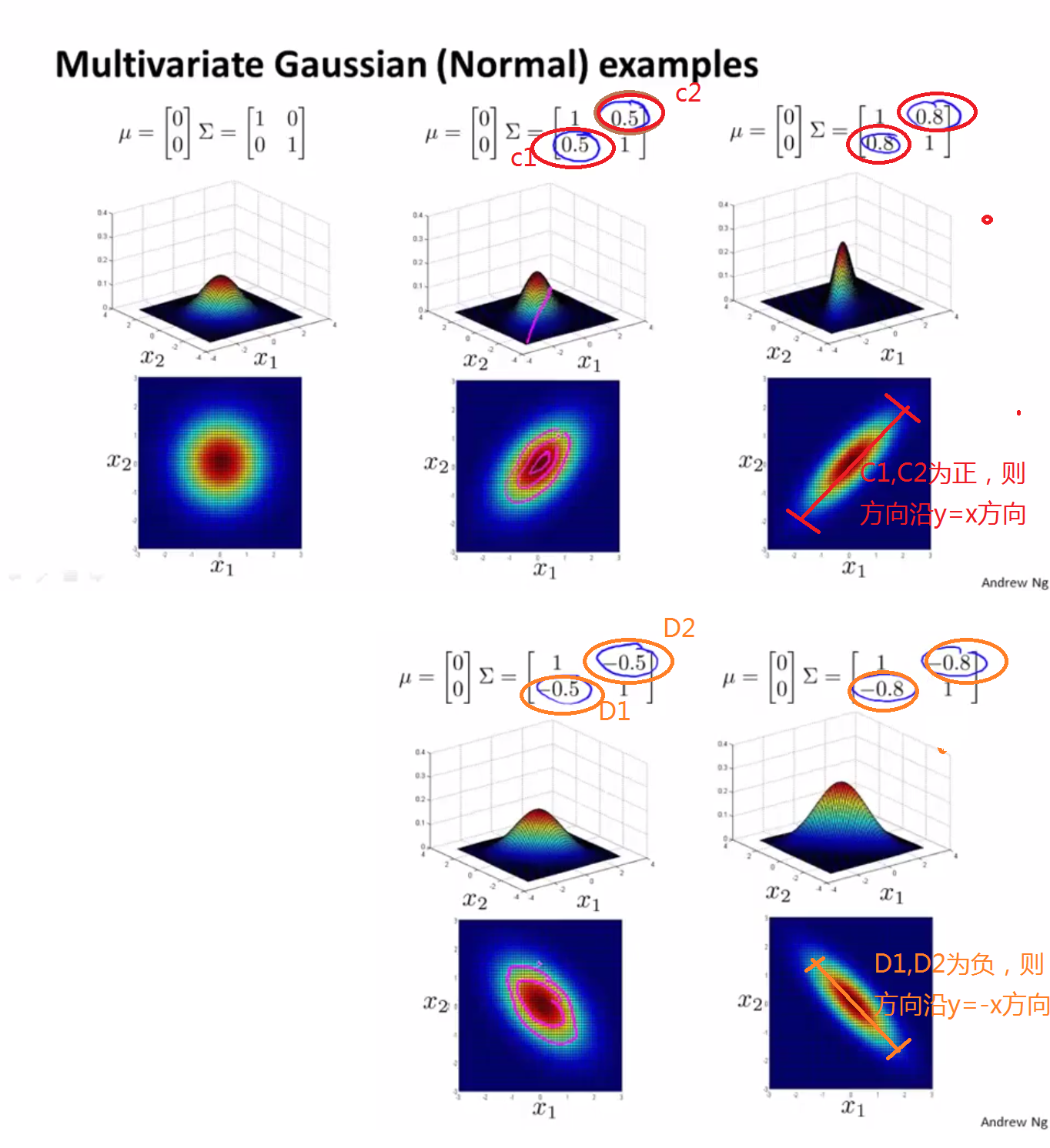
下面用几张图形象的看一下高斯分布:
图一:μ取在原点,改变 的值
的值

图二:μ取在原点,改变左下-右上方向的值。
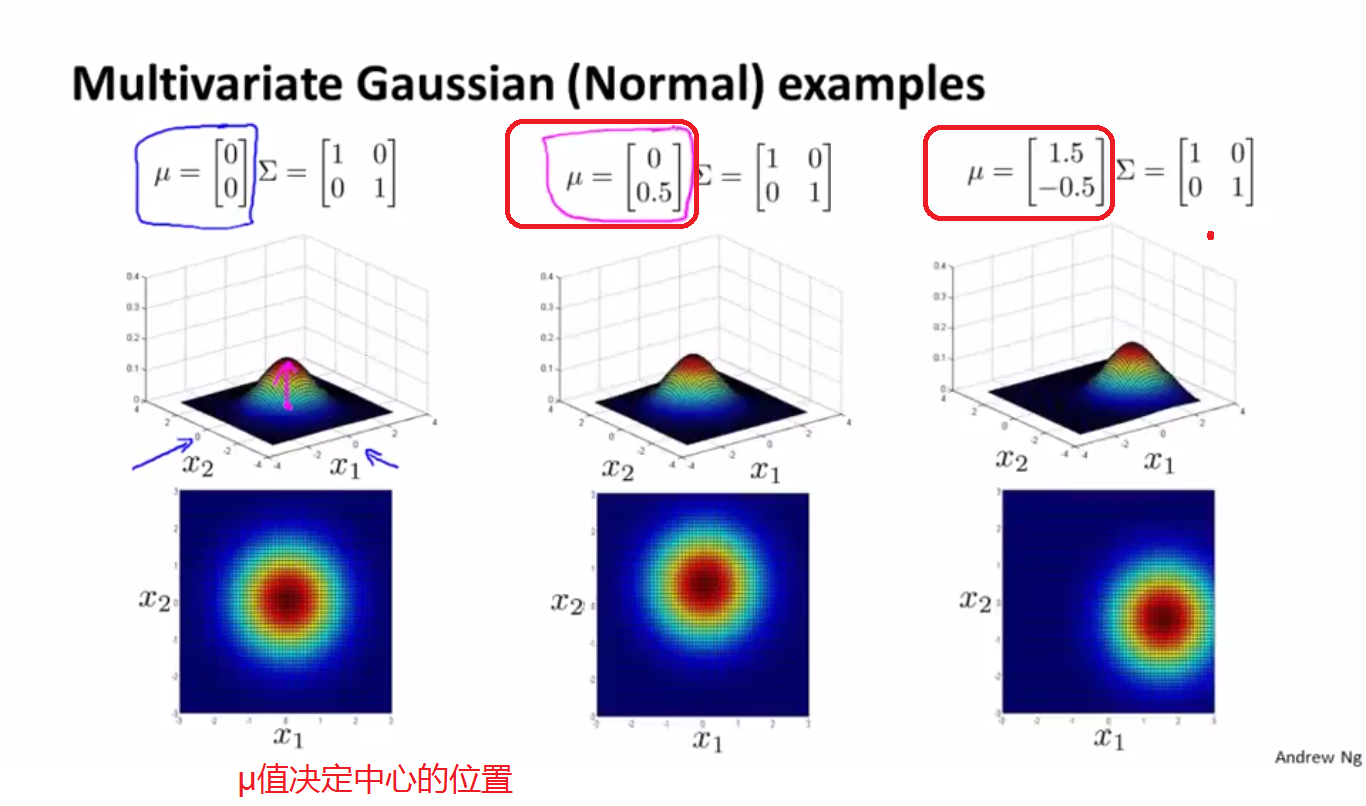
图三:改变μ的值,使其不在原点上:
二、Anomaly Detection using the Multivariate Gaussian Distribution
(使用多元高斯分布的异常检测)
使用多元高斯分布的异常检测:
(1)通过利用μ和Σ拟合模型p(x)
(2)给出测试样本,利用公式,若p<ε,则将其标记为异常样本。
多元高斯分布模型和之前模型的关系:
之前的模型:
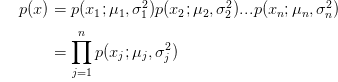
多元高斯分布模型:
原有的模型其图形方向是沿坐标轴方向,即不同特征之间不能建立相关性,若Σ只有对角线上有元素且其余元素为0,则多元高斯模型也可以用之前的模型表示,即若Σ是下面的形式,则二者等同:
下面是之前的模型和多元高斯模型的比较:
| 传统模型 | 高斯分布模型 |
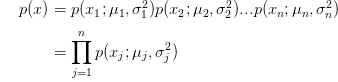 | |
| 对于x1,x2需要组合的特征,通过手动建立一些新的特征,比如x3=x1/x2=(CPU load)/Memory | 能够自动捕捉不同特征之间的关系 |
| 计算成本较低,对于n比较大的情况比较好(n=10000,n=100000) | 计算成本较高,因为需要计算Σ的逆矩阵,而Σ是n*n维 |
| 即使m(训练集大小)很小也适用 | 必须保证m>n,否则Σ不可逆--在平时中,我们一般满足m≥10n时才使用 |
| 注:Σ一般情况都是可逆的,若不可逆,可能是下面的可能:(1)不满足m>n。(2)有冗余特征,即存在线性相关的特征,可能x1=x2或者x3=x4+x5之类的 |
通常情况下,左边的模型比较常用,一般手动增加一些特征。但是若m很大,n很小,即能够很好地满足m≥10n,则右边的模型也是值得考虑的,使用右边的模型可以省去手动建立新特征的时间。















 381
381

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









