







决策树
决策树是机器学习最基本的模型,在不考虑其他复杂情况下,我们可以用一句话来描述决策树:如果得分大于等于60分,那么你及格了。
这是一个最最简单的决策树的模型,我们把及格和没及格分别附上标签,及格(1),没及格(0),那么得到的决策树是这样的
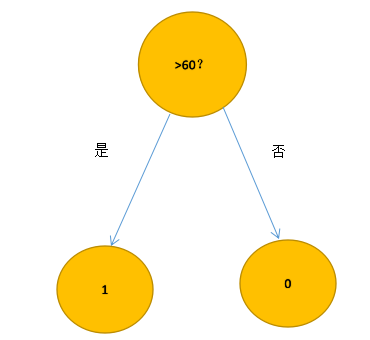
这种就根据成绩来判断是最简单的,并且只有一个特征,这一个特征就把结果分隔开了,形成了两个类目,那么多个特征会怎么样?
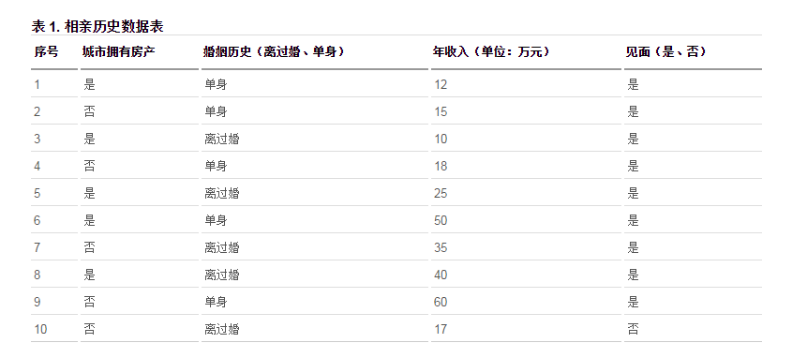
此表中拥有多个特征,其中每个特征作为唯一的一个特征是无法将数据区分开的,不能完全将数据分类,必须多个特征同时参与到分类中才可以讲数据分开,于是我们可以这么设想一下:
能否先用某一个特征来做一次分类,得到了一棵树的两个孩子节点,如果某一个节点中还包含分类的两种情况,再利用其它特征再分类,最终所有结果被分类到叶子节点上,不存在一个叶子节点同时有两个不同分类的数据,于是会形成一课二叉树,所有叶子节点都只是一个分类结果
那么问题来了:
- 这么多的特征中 哪一个作为第一个区分数据分类的特征? 我们注意到相亲表中有多个特征:“房产”、“婚姻历史”、“年收入”这三个特征,挑选哪一个特征作为第一个区分结果的特征呢?我们看一下Gini不纯度 #### Gini不纯度(基尼系数) Gini不纯度是对分类结果好坏的度量标准(还可以用信息熵和增益去表示,可自行了解),计算为:每个标签占总数的比例的平方和。也就是每个特征占总数的平方和。 我们假设用是否有房来作为为一的特征,那么区分的决策树就是:  对于上述的分类结果来讲,总的集合D被分为两个集合D1,D2,假设见面为1,不见面为0。
- 那么D1的不纯度为 1 − f 1 2 − f 0 2 1-f_{1}^{2}-f_{0}^{2} 1−f12−f02,总数为5,见面的占了全部,5个全部全是“见面”分类结果,则f1=5/5=1,f0=0/5=0,结果为0。
- D2的不纯度为1-f12-f02,f1=4/5=0.8,f0=1/5=0.2,结果为0.32。
那么整个分类结果的Gini不纯度就是D1/D与0的乘积 加上 D2/D与0.32的乘积,为0.16。
G i n i = D 0 D ∗ D 0 g i n i + D 1 D ∗ D 1 g i n i = 1 ∗ 0 + 1 ∗ 0.32 = 0.32 Gini=\frac{D_0}{D} *D_{0gini}+ \frac{D_1}{D}*D_{1gini}=1*0 + 1*0.32=0.32 Gini=DD0∗D0gini+DD1∗D1gini=1∗0+1∗0.32=0.32
Gini值代表了某一个分类结果的“纯度”,我们希望结果的纯度很高,从以上分析可以看出,Gini值越小,纯度越高,结果越好。。决策树的生成
我们利用Gini值来做区分,每次找一个使得分类结果Gini值最小的特征作为分裂节点:
- 1、对于多个特征,找到一个使得Gini值最小的分割点(这个分割点可以是>,<,>=这样的判断,也可以是=,!=),然后比较每个特征之间的Gini值,选取最小的Gini值的特征作为当前最优的特征的最优分割点(这实际上涉及到了两个步骤,选择最优特征以及选择最优分割点。
- 2、在第一步完成后,会生成两个叶节点,我们对这两个叶节点做判断,计算它的Gini值是否足够小(若是,就将其作为叶子不再分类)。
- 3、将上步得到的叶节点作为新的集合,进行步骤1的分类,延伸出两个新的叶子节点(当然此时该节点变成了父节点)。
- 4、循环迭代至不再有Gini值不符合标准的叶节点。
进过上述四个步骤后一个决策树就出来了,如下:


最后生成的决策树,取了四个分割点,在图上的显示如下,只要是落在中央矩形区域内默认是绿色,否则为红色。
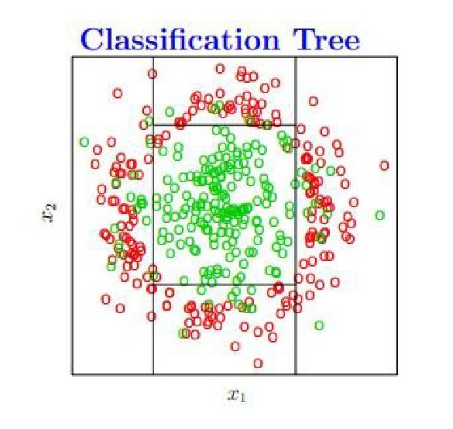
不过这种情况是分类参数选择比较合理的情况(它不介意某些绿色的点落在外围),但是当我们在训练的时候需要将所有的绿点无差错的分出来(即参数选择不是很合理的情况),决策树会产生过拟合的现象,导致泛化能力变弱。
优点决策树对训练属于有很好的分类能力缺点但对未知的测试数据未必有好的分类能力,泛化 能力弱,即可能发生过拟合现象随机森林
鉴于决策树容易过拟合的缺点,随机森林采用多个决策树的投票机制来改善决策树,我们假设随机森林使用了m棵决策树,那么就需要产生m个决策树,我们每次从全样本中挑选一定数量的样本集来训练每一棵树,如果用全样本去训练m棵决策树显然是不可取的,
全样本训练忽视了局部样本的规律,对于模型的泛化能力是有害的。于是产生n个样本的方法采用Bootstraping法,Bootstraping的名称来自成语“pull up by your own bootstraps”,意思是依靠你自己的资源,称为自助法,它是一种有放回的抽样方法, 从手上有限的资料, 产生不同的副本, 来模拟不一样的资料。这是一种有放回的抽样方法,产生n个样本,而最终结果采用Bagging的策略来获得,即多数投票机制。
随机森林的生成方法:- 1.从样本集中通过重采样(有放回)的方式产生n个样本
- 2.假设样本特征数目为a,对n个样本选择a中的k个特征,用建立决策树的方式获得最佳分割点
- 3.重复m次,产生m棵决策树
- 4.多数投票机制来进行预测
(需要注意的一点是,这里m是指循环的次数,n是指训练决策树样本的数目,n个样本构成训练的样本集,而m次循环中又会产生m个这样的样本集,每一个样本集对对应一个决策树)
随机森林的“随机”
这里随机我觉得主要是指两个方面:
1、随机选择样本(n个样本)
2、训练每棵树的特征是随机选取的(a个特征)
随机森林模型的总结
随机森林是一个比较优秀的模型,它对于多维特征的数据集分类有很高的效率,还可以做特征重要性的选择。运行效率和准确率较高,实现起来也比较简单。但是在数据噪音比较大的情况下会过拟合,过拟合的缺点对于随机森林来说还是较为致命的。
优点1、能够处理具有高维特征的输入样本,而且不需要降维。 2、能够评估各个特征在分类问题上的重要性。 3、在生成过程中,能够获取到内部生成误差的一种无偏估计。 4、对于缺省值问题也能够获得很好得结果 5、在估计推断映射方面特别好用,以致都不需要像SVM那样做很多参数的调试。 6、 在训练过程中,能够检测到feature间的互相影响。 7、训练速度快,容易做成并行化方法,训练时树与树之间是相互独立的。缺点1、随机森林已经被证明在某些噪音较大的分类或回归问题上会过拟。 2、对于有不同取值的属性的数据,取值划分较多的属性会对随机森林产生更大的影响,所以随机森林在这种数据上产出的属性权值是不可信的。参考博客















 1537
1537

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









